Java面试系列第3篇-HashMap相关面试题
HashMap是非线程安全的,如果想要用线程安全的map,可使用同步的HashTable或通过Collections.synchronizeMap(hashMap)让HashMap变的同步,或者使用并发集合ConcurrentHashMap。下面来介绍一些常见的HashMap面试题目。
1、为何HashMap的数组长度一定是2的次幂?
我们知道,HashMap的存储对于JDK1.7来说,是通过数组加链表的方式实现的。通过hash值获取数组下标存储索引,通过链表来解决冲突。下面看一下调用hash()方法获取hash值的源代码实现,如下:
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
在HashMap中得到hash值后会调用indexFor()计算数组中的索引位置,实现如下:
static int indexFor(int h, int length) {
return h & (length-1); // 保证获取的索引是数组的合法索引
}
通过hashcode与length-1进行与运算,之前已经说过,数组长度length一定是2的幂次,所以减去1之后,结果用二进制表示时,其右边的log2(length)个二进制位都为1,也就是说,hashcode的log2(length)个低二进制位决定最终的存储索引位置,如果数组长度length不为2的幂次,那么length-1的结果用二进制表示时,右边的log2(length)个二进制位会含有0,导致hashcode的log2(length)个低二进制位中的部分数据不起作用,会增加索引位置冲突的机率。
2、为什么Map桶中个数超过8才转为红黑树
在 JDK 1.7 中,是用链表存储的,这样如果碰撞很多的话,就变成了在链表上的查找;在 JDK 1.8 进行了优化,当链表长度较大时(超过 8),会采用红黑树来存储,这样大大提高了查找效率。针对JDK 1.8版本的冲突解决,经常会被问到为什么是超过8才用红黑树的问题。
当桶中个数达到8就转成红黑树,当长度降到6就转成普通链表存储,而7就是为了防止链表和树频繁转换。至于选择8的原因,根据源代码的解析,是因为一个桶中存储8个或以上的概率非常小,这样小的事件都发生了,说明产生了严重的冲突,需要更高效的查找方式。
3、为什么HashMap链表会形成死循环
JDK1.7 的 HashMap 链表会有死循环的可能,因为JDK1.7是采用的头插法,在多线程环境下有可能会使链表形成环状,从而导致死循环。JDK1.8做了改进,用的是尾插法,不会产生死循环。
因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生,那么就死造成死循环。简书中https://www.jianshu.com/p/1e9cf0ac07f4给了一个非常生动的例子,如下:
假设HashMap初始化大小为4,插入个3节点,不巧的是,这3个节点都hash到同一个位置,如果按照默认的负载因子的话,插入第3个节点就会扩容,为了验证效果,假设负载因子是1。
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
下面进行图示说明。
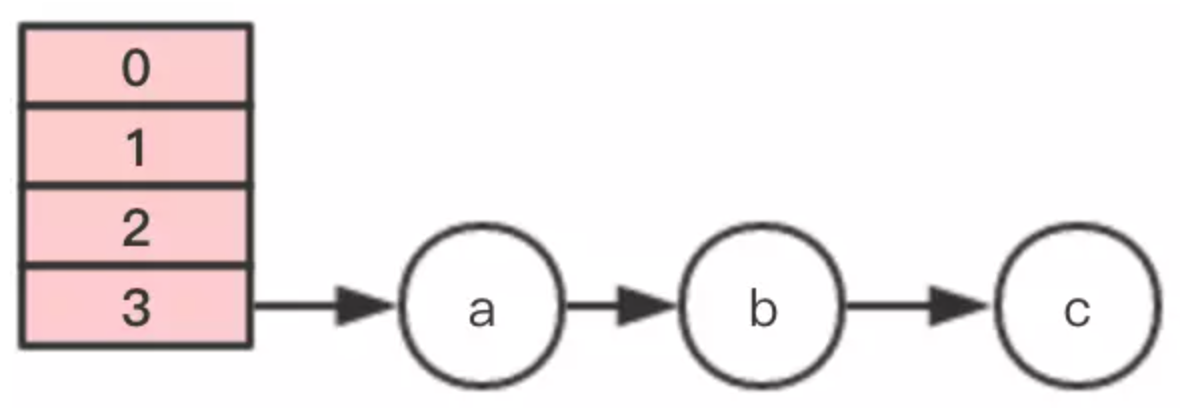
插入第4个节点时,发生rehash,假设现在有两个线程同时进行,线程1和线程2,两个线程都会新建新的数组。
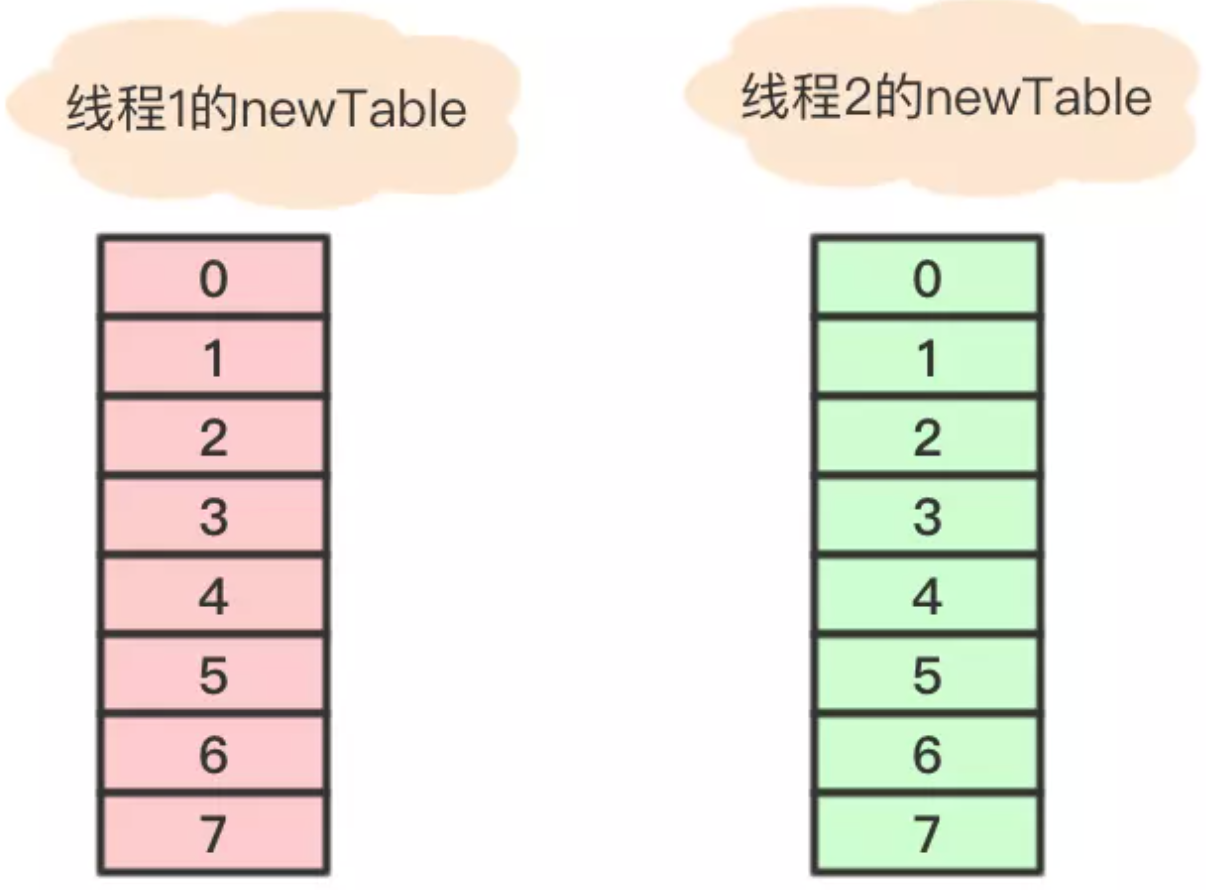
假设 线程2 在执行到Entry<K,V> next = e.next;之后,cpu时间片用完了,这时变量e指向节点a,变量next指向节点b。
线程1继续执行,很不巧,a、b、c节点rehash之后又是在同一个位置7,开始移动节点
第一步,移动节点a
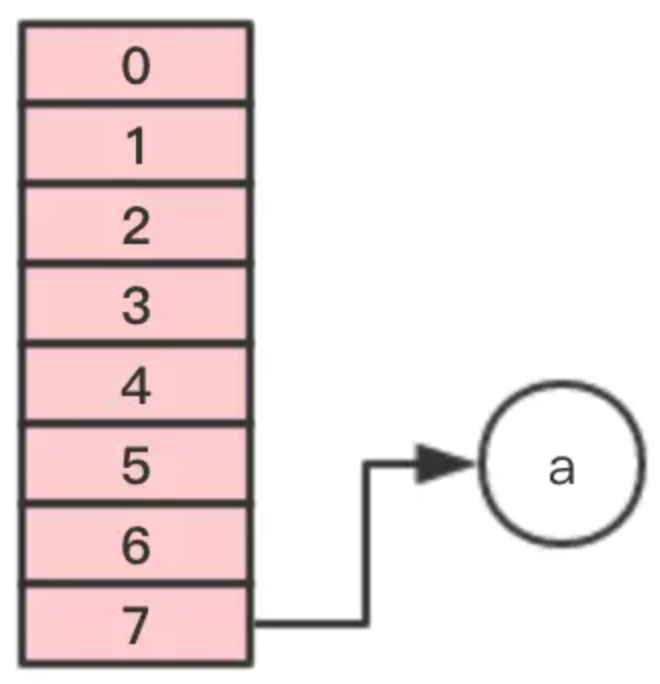
第二步,移动节点b
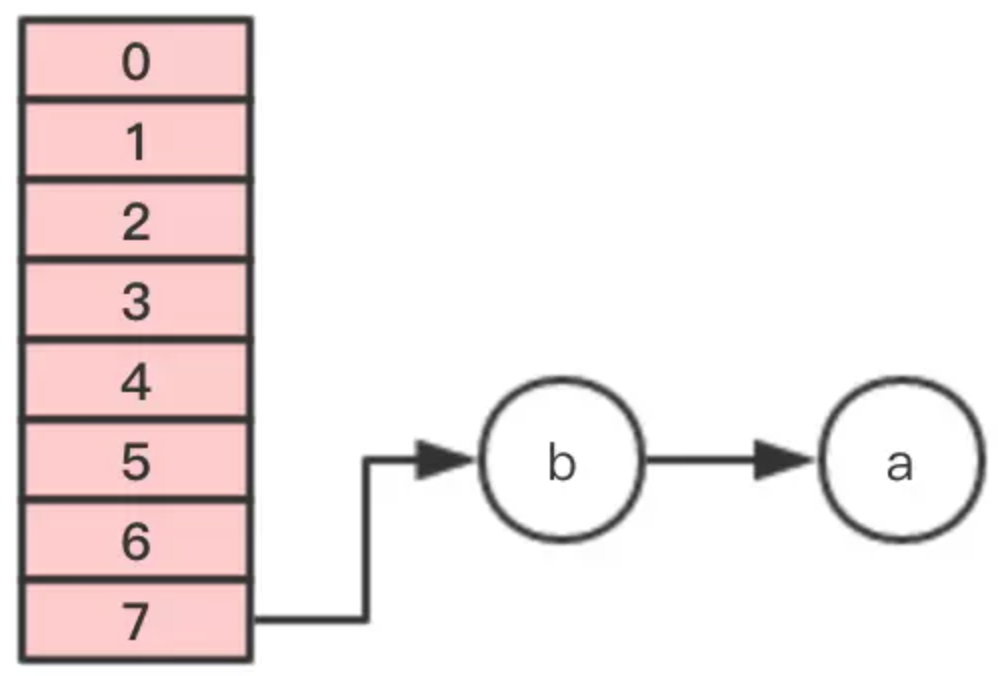
注意,这里的顺序是反过来的,继续移动节点c
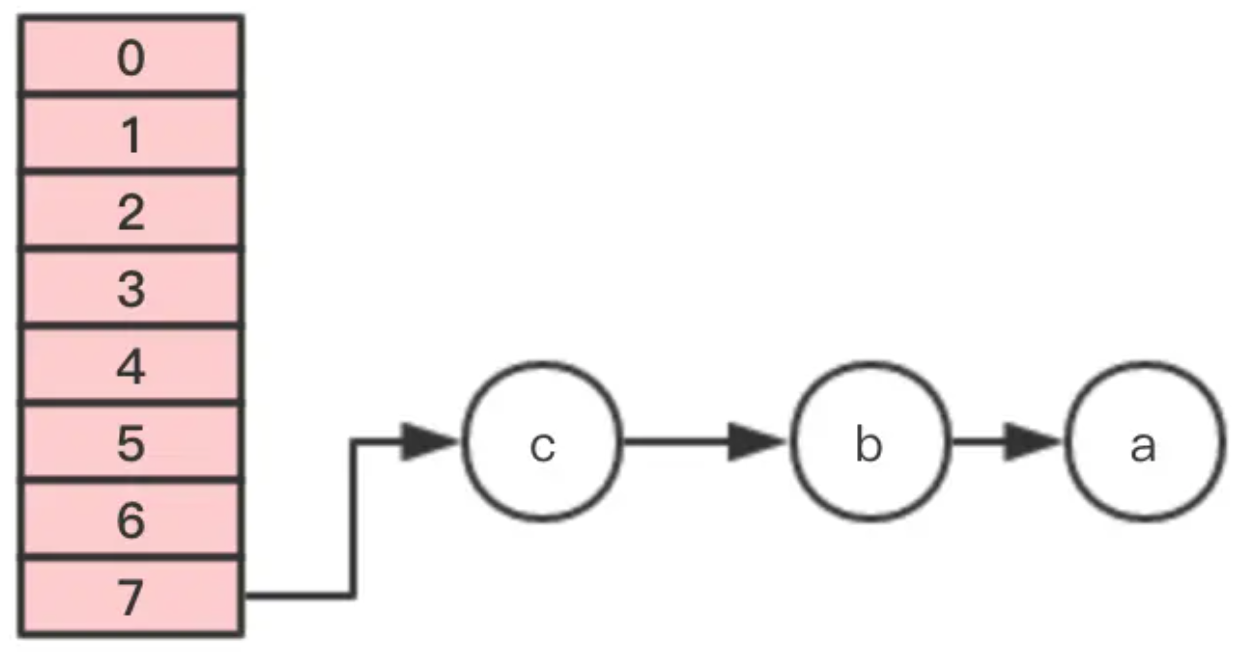
这个时候 线程1 的时间片用完,内部的table还没有设置成新的newTable, 线程2 开始执行,这时内部的引用关系如下:
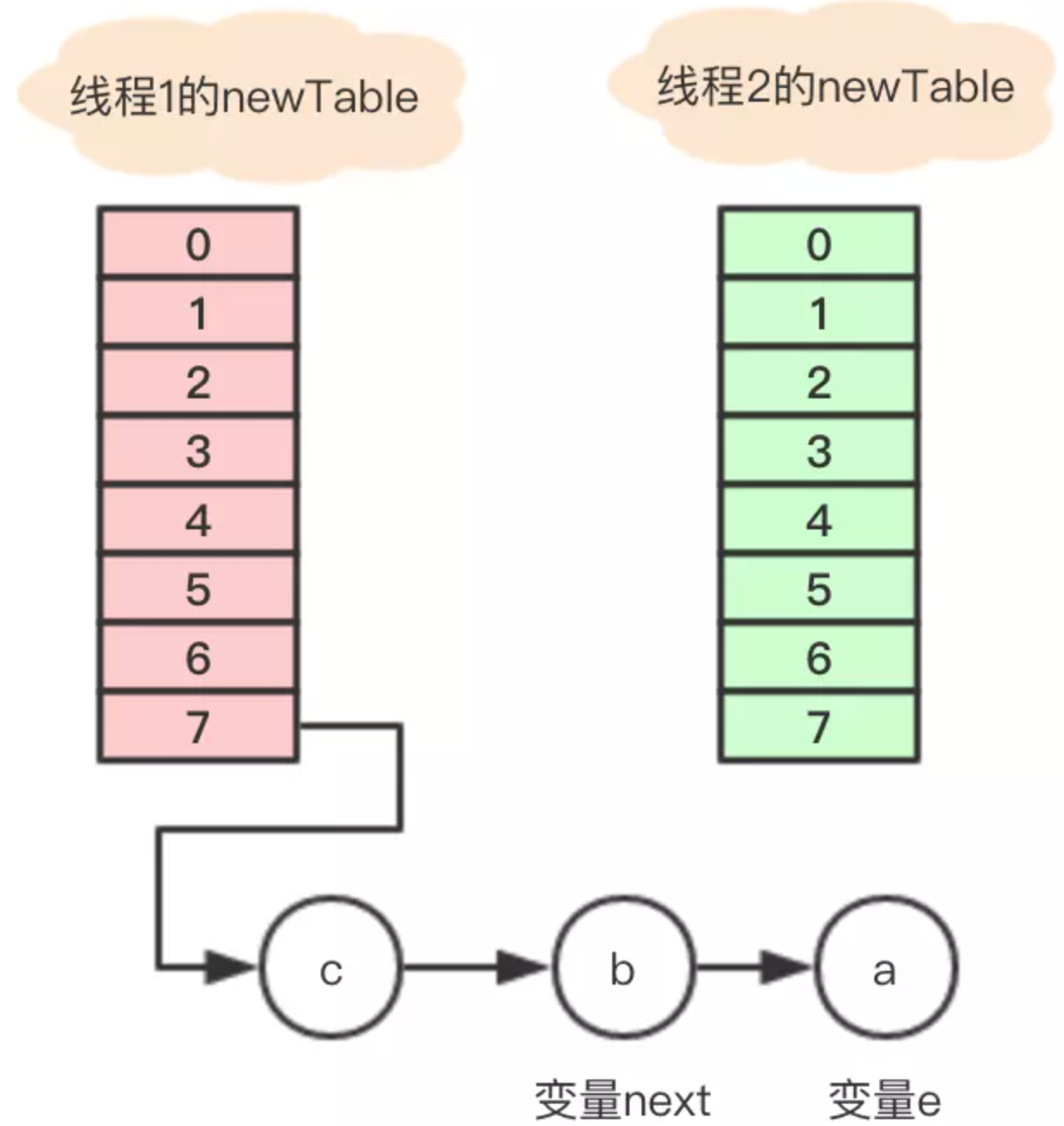
这时,在 线程2 中,变量e指向节点a,变量next指向节点b,开始执行循环体的剩余逻辑。
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
执行之后的引用关系如下图。
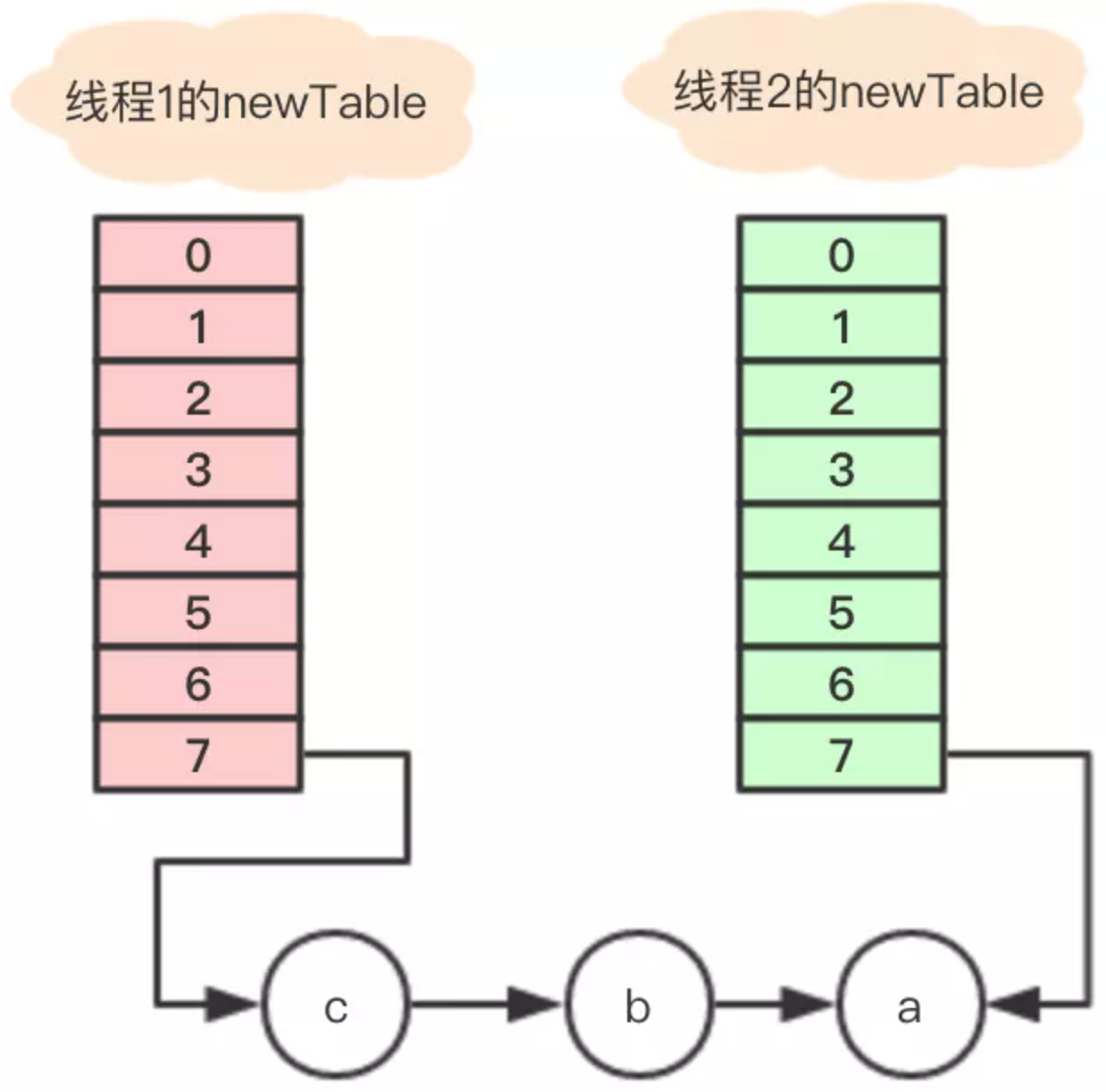
执行后,变量e指向节点b,因为e不是null,则继续执行循环体,执行后的引用关系
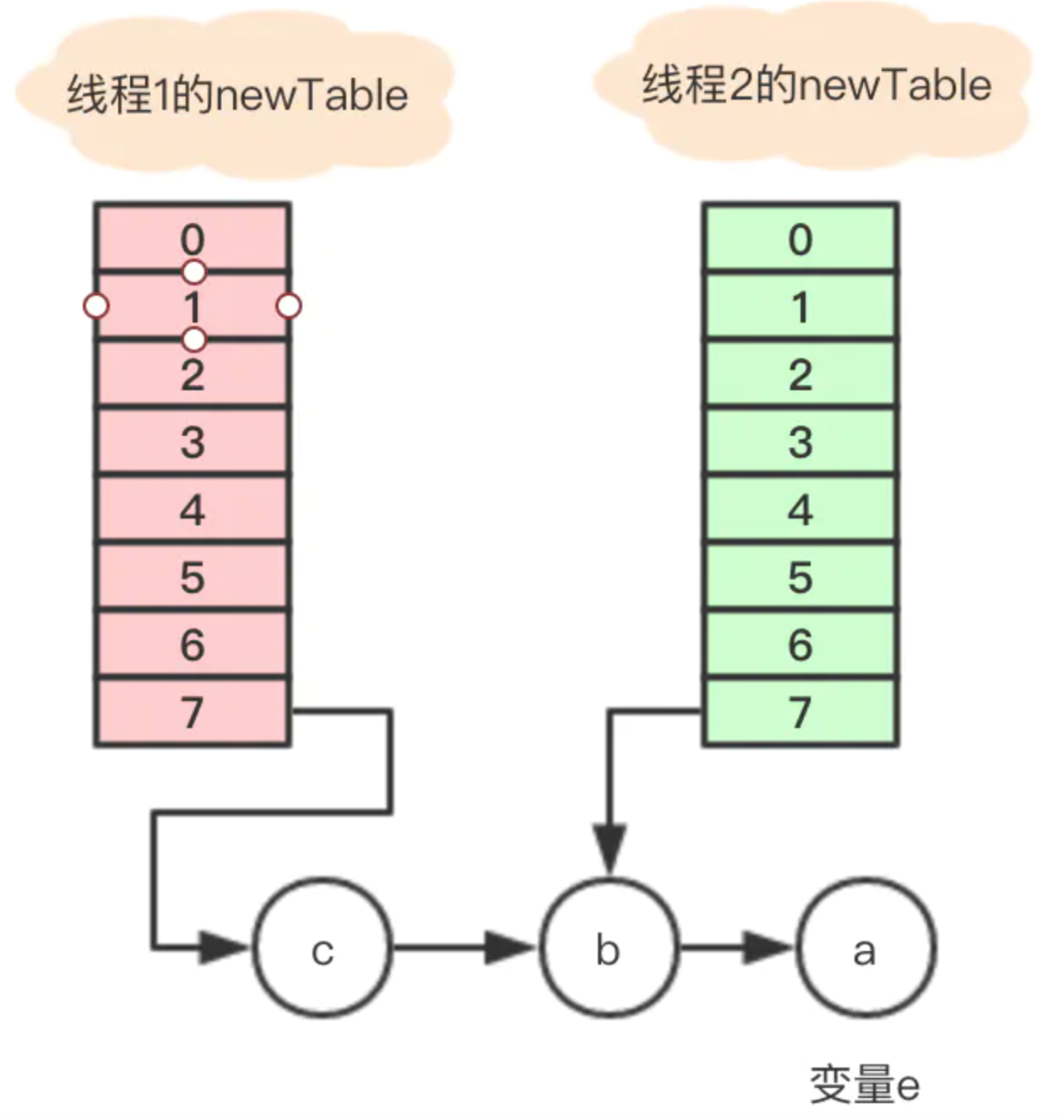
1、执行完Entry<K,V> next = e.next;,目前节点a没有next,所以变量next指向null;
2、e.next = newTable[i]; 其中 newTable[i] 指向节点b,那就是把a的next指向了节点b,这样a和b就相互引用了,形成了一个环;
3、newTable[i] = e 把节点a放到了数组i位置;
4、e = next; 把变量e赋值为null,因为第一步中变量next就是指向null;
所以最终的引用关系是这样的:
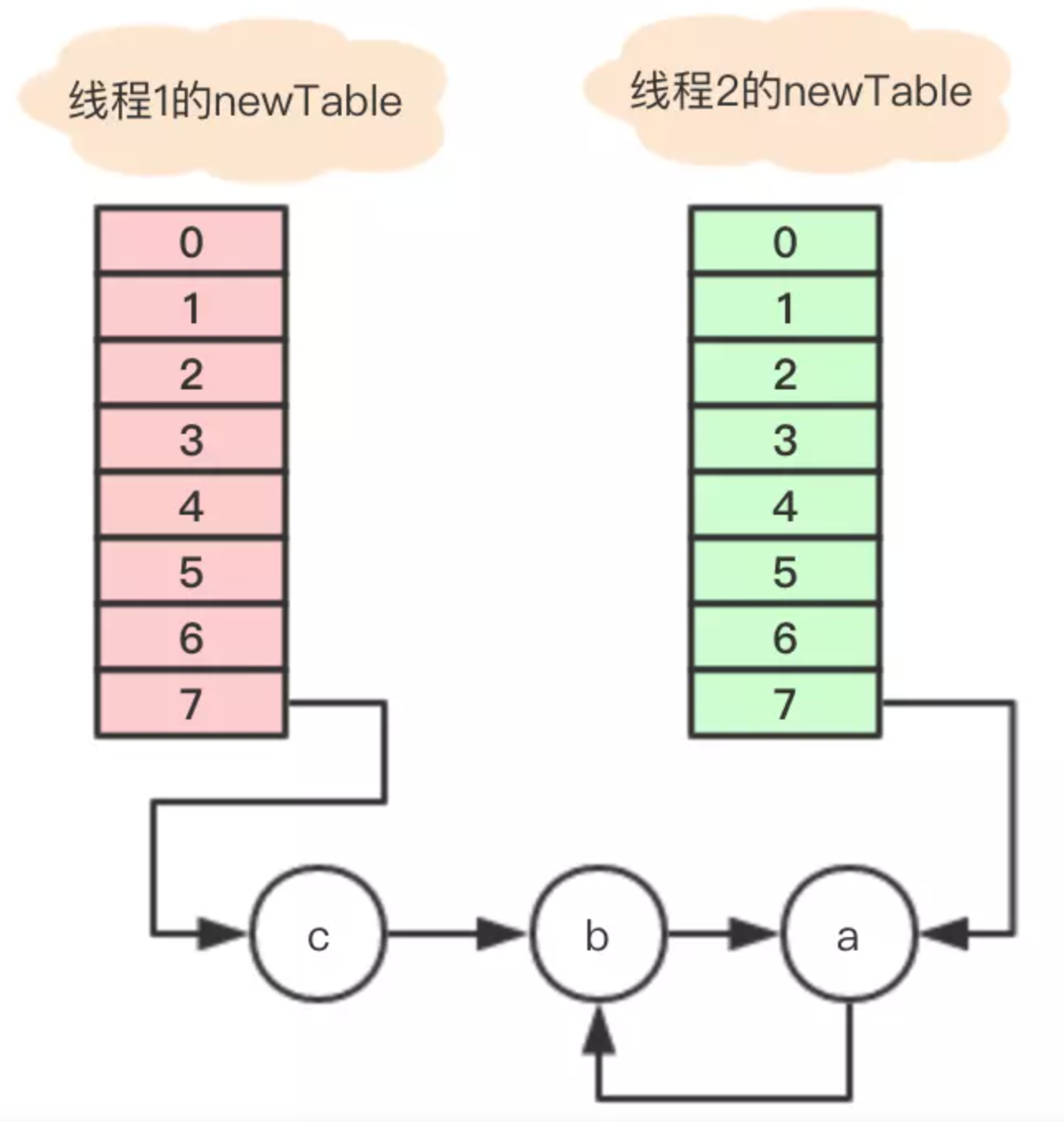
节点a和b互相引用,形成了一个环,当在数组该位置get寻找对应的key时,就发生了死循环。
另外,如果线程2把newTable设置成到内部的table,节点c的数据就丢了,看来还有数据遗失的问题。
4、HashMap在并发环境下为什么会丢失数据?
在多线程下put操作时,执行addEntry(hash, key, value, i),如果有产生哈希碰撞,导致两个线程得到同样的bucketIndex去存储,就可能会出现覆盖丢失的情况,源代码实现如下:
void addEntry(int hash, K key, V value, int bucketIndex) {
//多个线程操作数组的同一个位置
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
5、为什么重写 equals() 方法,一定要重写 hashCode() 呢?
一般情况下,任何两个Object的hashCode在默认情况下都是不同的,如果有两个Object相等,在不重写 hashCode()方法的情况下,那么很可能存储到数组中不同的索引位置,而Java为了加快查找速度,通常对以散列表做为存储结构的集合进行查找时,首先要通过hash来定位查询的索引位置,如果存储到其它索引位置,则没有办法查找。
6、rehashing的时机
通过负载因子来判断,即用元素数量除以索引的数量,也就是平均每个索引处存储多少个元素。Java 中默认值是 0.75f,如果超过了这个值就会 rehashing。
7、HashMap 1.7与1.8的区别
分别有以下几点:
- 数组+链表改成了数组+链表或红黑树,防止发生hash冲突,链表长度过长,将时间复杂度由
O(n)降为O(logn); - 链表的插入方式从头插法改成了尾插法,简单说就是插入时,如果数组位置上已经有元素,1.7将新元素放到数组中,原始节点作为新节点的后继节点,1.8遍历链表,将元素放置到链表的最后。因为1.7头插法扩容时,头插法会使链表发生反转,多线程环境下会产生环;
- 扩容的时候1.7需要对原数组中的元素进行重新hash定位在新数组的位置,1.8采用更简单的判断逻辑,位置不变或索引+旧容量大小;
- 在插入时,1.7先判断是否需要扩容,再插入,1.8先进行插入,插入完成再判断是否需要扩容;
8、 为什么要用扰动函数?

扰动函数就是解决碰撞问题。若不使用扰动函数,则直接将key.hashCode()和下面的步骤2做与运算,则会有以下情景。
以初始长度16为例,16-1=15。2进制表示是00000000 00000000 00001111。和某散列值做“与”操作如下,结果就是截取了最低的四位值。

这样就算散列值分布再松散,要是只取最后几位的话,碰撞也会很严重。如果散列本身做得不好,分布上成等差数列的漏洞,恰好使最后几个低位呈现规律性重复,则碰撞会更严重。
由扰动函数源码可知,会有以下步骤:
①使用key.hashCode()计算hash值并赋值给变量h;
②将h向右移动16位;
③将变量h和向右移16位的h做异或运算(二进制位相同为0,不同为1)。此时得到经过扰动函数后的hansh值。

右移16位正好为32bit的一半,自己的高半区和低半区做异或,是为了混合原始哈希吗的高位和低位,来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,使高位的信息也被保留下来。

若直接使用key.hashCode()计算出hash值,则范围为:-2147483648到2147483648,大约40亿的映射空间。若映射得比较均匀,是很难出现碰撞的。但是这么大范围无法放入内存中,况且HashMap的 初始容量为16。所以必须要进行与运算取模。
Java面试系列第3篇-HashMap相关面试题的更多相关文章
- Java面试系列第2篇-Object类中的方法
Java的Object是所有引用类型的父类,定义的方法按照用途可以分为以下几种: (1)构造函数 (2)hashCode() 和 equals() 函数用来判断对象是否相同 (3)wait().wai ...
- 【Java面试】基础知识篇
[Java面试]基础知识篇 Java基础知识总结,主要包括数据类型,string类,集合,线程,时间,正则,流,jdk5--8各个版本的新特性,等等.不足的地方,欢迎大家补充.源码分享见个人公告.Ja ...
- Java面试知识点之线程篇(三)
前言:这里继续对java线程相关知识点进行总结,不能间断. 1.yield()方法 yield()的作用是让步.它能让当前线程由“运行状态”进入到“就绪状态”,从而让其它具有相同优先级的等待线程获取执 ...
- Java面试知识点之线程篇(二)
前言:接上篇,这里继续对java线程相关知识点进行总结. 1.notify和notifyall的区别 notify()方法能够唤醒一个正在等待该对象的monitor的线程,当有多个线程都在等待该对象的 ...
- Java面试知识点之线程篇(一)
前言:在Java面试中,一定会遇到线程相关问题,因此笔者在这里总结Java中有关线程方面知识点,多数从网上得来(文中会贴出主要参考链接),有些也是笔者在面试中所遇到的问题,如有错误,请不吝指正.主要参 ...
- Java面试系列第一篇-基本类型与引用类型
这篇文章总结一下我认为面试中最应该掌握的关于基本类型和引用类型的面试题目. 面试题目1:值传递与引用传递 对于没有接触过C++这类有引用传递的Java程序员来说,很容易误将引用类型的参数传递理解为引用 ...
- 死磕 java同步系列之终结篇
简介 同步系列到此就结束了,本篇文章对同步系列做一个总结. 脑图 下面是关于同步系列的一份脑图,列举了主要的知识点和问题点,看过本系列文章的同学可以根据脑图自行回顾所学的内容,也可以作为面试前的准备. ...
- 死磕 java线程系列之终篇
(手机横屏看源码更方便) 简介 线程系列我们基本就学完了,这一个系列我们基本都是围绕着线程池在讲,其实关于线程还有很多东西可以讲,后面有机会我们再补充进来.当然,如果你有什么好的想法,也可以公从号右下 ...
- Java面试系列
如果你的面试简历是如下这样写的,请务必准备回答下面的所有问题. 面试职位:Java高级工程师 专业技能: (1)牢固掌握Java基础知识,如集合.并发.I/O等,并对Java源码有一定的研究. (2) ...
随机推荐
- VBScript - 动态 Array 实现方法大全!
记录一些方法,关于 VBScript 中,动态 Array 的实现 ,也适用于 VBA, 很久以前,写 VBA 的时候,就觉得使用 Array 很不方便,因为大小固定, 当时想的是,要是 Array ...
- 深入理解Java AIO(一)—— Java AIO的简单使用
深入理解Java AIO(一)—— Java AIO的简单使用 深入理解AIO系列分为三个部分 第一部分也就是本节的Java AIO的简单使用 第二部分是AIO源码解析(只解析关键部分)(待更新) 第 ...
- Python——Matplotlib库入门
1.Matplotlib库简介 优秀的可视化第三方库 Matplotlib库由各种可视化类构成,内部结构复杂,受Matlab启发 matplotlib.pyplot是绘制各类可视化图形的命令子库,相当 ...
- Unity引擎入门——制作第一个2D游戏(2)角色移动与动画
在上一节的内容里,我们已经创建出了一个主角,也搭建了一个简单的场景. 传送门:https://www.cnblogs.com/zny0222/p/12653088.html 既然有了主角,要怎样才能让 ...
- Vertica的这些事(四)——-vertica加密数据
通过创建 Secure Access Policies可以对vertica中的某一列数据进行加密: CREATE ACCESS POLICY ON [schema][tablename] FOR CO ...
- html 中video标签视频不自动播放的问题
有个需求,客户想做个打开官网自动播放一段视频,楼主使用了video标签,即下面的代码::于是我在video标签上添加了属性 autoplay=“autoplay” loop=“loop”然而通过地址栏 ...
- Redis 笔记(六)—— ZSET 常用命令
常用命令 命令 用例和描述 ZADD ZADD key-name score member [score member ...] —— 将带有分值的成员添加到 HSET 中 ZREM ZREM key ...
- Vim中实现PHP函数tags跳转
编译安装ctags 下载地址:http://ctags.sourceforge.net/ 下载文件:ctags-5.8.tar.gz 解压ctags:tar -zxcf ctags-5.8.tar.g ...
- C语言一行语句太长的换行处理方法
[toc] 1.C语言中代码的多行书写 对C语言初学者来说,编写的程序的功能很简单,一句代码很短,但是在实际开发中,参数往往很长很多,一句代码可能会很长,需要用多行才能书写. 如果我们在一行代码的行尾 ...
- .Net Core MVC 基于Cookie进行用户认证
在打代码之前先说一下思路. 登录的的时候服务端生成加密的字符串(用户名.id.当前时间)并且存入客户端cookie中,服务端的缓存中.对客户端的每次请求进行拦截,解密保存在cookie中的加密字符串. ...