ConcurrentHashMap(锁分段技术)
线程不安全的HashMap
效率低下的HashTable容器
HashMap,HashTable,ConcurrentHashMap
先说这三个Map的区别:
HashTable
- 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
- 初始size为11,扩容:newsize = olesize*2+1
- 计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length
HashMap
- 底层数组+链表实现,可以存储null键和null值,线程不安全
- 初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂
- 扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入
- 插入元素后才判断该不该扩容,有可能无效扩容(插入后如果扩容,如果没有再次插入,就会产生无效扩容)
- 当Map中元素总数超过Entry数组的75%,触发扩容操作,为了减少链表长度,元素分配更均匀
- 计算index方法:index = hash & (tab.length – 1)
HashMap的初始值还要考虑加载因子:
- 哈希冲突:若干Key的哈希值按数组大小取模后,如果落在同一个数组下标上,将组成一条Entry链,对Key的查找需要遍历Entry链上的每个元素执行equals()比较。
- 加载因子:为了降低哈希冲突的概率,默认当HashMap中的键值对达到数组大小的75%时,即会触发扩容。因此,如果预估容量是100,即需要设定100/0.75=134的数组大小。
- 空间换时间:如果希望加快Key查找的时间,还可以进一步降低加载因子,加大初始大小,以降低哈希冲突的概率。
HashMap和Hashtable都是用hash算法来决定其元素的存储,因此HashMap和Hashtable的hash表包含如下属性:
- 容量(capacity):hash表中桶的数量
- 初始化容量(initial capacity):创建hash表时桶的数量,HashMap允许在构造器中指定初始化容量
- 尺寸(size):当前hash表中记录的数量
- 负载因子(load factor):负载因子等于“size/capacity”。负载因子为0,表示空的hash表,0.5表示半满的散列表,依此类推。轻负载的散列表具有冲突少、适宜插入与查询的特点(但是使用Iterator迭代元素时比较慢)
除此之外,hash表里还有一个“负载极限”,“负载极限”是一个0~1的数值,“负载极限”决定了hash表的最大填满程度。当hash表中的负载因子达到指定的“负载极限”时,hash表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,这称为rehashing。
HashMap和Hashtable的构造器允许指定一个负载极限,HashMap和Hashtable默认的“负载极限”为0.75,这表明当该hash表的3/4已经被填满时,hash表会发生rehashing。
“负载极限”的默认值(0.75)是时间和空间成本上的一种折中:
- 较高的“负载极限”可以降低hash表所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的操作(HashMap的get()与put()方法都要用到查询)
- 较低的“负载极限”会提高查询数据的性能,但会增加hash表所占用的内存开销
程序猿可以根据实际情况来调整“负载极限”值。
ConcurrentHashMap
- 底层采用分段的数组+链表实现,线程安全
- 通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)
- Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术
- 有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁
- 扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容
Hashtable和HashMap都实现了Map接口,但是Hashtable的实现是基于Dictionary抽象类的。Java5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
HashMap基于哈希思想,实现对数据的读写。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,然后找到bucket位置来存储值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞时,对象将会储存在链表的下一个节点中。HashMap在每个链表节点中储存键值对对象。当两个不同的键对象的hashcode相同时,它们会储存在同一个bucket位置的链表中,可通过键对象的equals()方法来找到键值对。如果链表大小超过阈值(TREEIFY_THRESHOLD,8),链表就会被改造为树形结构。
在HashMap中,null可以作为键,这样的键只有一个,但可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示HashMap中没有该key,也可以表示该key所对应的value为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个key,应该用containsKey()方法来判断。而在Hashtable中,无论是key还是value都不能为null。
Hashtable是线程安全的,它的方法是同步的,可以直接用在多线程环境中。而HashMap则不是线程安全的,在多线程环境中,需要手动实现同步机制。
Hashtable与HashMap另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。
先看一下简单的类图:

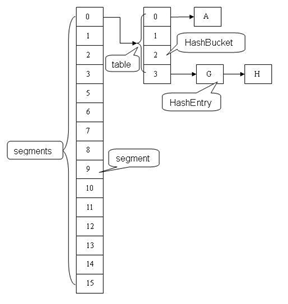
从类图中可以看出来在存储结构中ConcurrentHashMap比HashMap多出了一个类Segment,而Segment是一个可重入锁。
ConcurrentHashMap是使用了锁分段技术来保证线程安全的。
锁分段技术:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap提供了与Hashtable和SynchronizedMap不同的锁机制。Hashtable中采用的锁机制是一次锁住整个hash表,从而在同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶。
ConcurrentHashMap默认将hash表分为16个桶,诸如get、put、remove等常用操作只锁住当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
===========================================>
锁分段技术
二、应用场景
三、源码解读
/**
* The segments, each of which is a specialized hash table
*/
final Segment<K,V>[] segments;
不变(Immutable)和易变(Volatile)
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
其它
定位操作:
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
数据结构

static final class Segment<K,V> extends ReentrantLock implements Serializable {
/**
* The number of elements in this segment's region.
*/
transient volatileint count;
/**
* Number of updates that alter the size of the table. This is
* used during bulk-read methods to make sure they see a
* consistent snapshot: If modCounts change during a traversal
* of segments computing size or checking containsValue, then
* we might have an inconsistent view of state so (usually)
* must retry.
*/
transient int modCount;
/**
* The table is rehashed when its size exceeds this threshold.
* (The value of this field is always <tt>(int)(capacity *
* loadFactor)</tt>.)
*/
transient int threshold;
/**
* The per-segment table.
*/
transient volatile HashEntry<K,V>[] table;
/**
* The load factor for the hash table. Even though this value
* is same for all segments, it is replicated to avoid needing
* links to outer object.
* @serial
*/
final float loadFactor;
}
删除操作remove(key)
public V remove(Object key) {
hash = hash(key.hashCode());
return segmentFor(hash).remove(key, hash, null);
}
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
*for (HashEntry<K,V> p = first; p != e; p = p.next)
*newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}


get操作
V get(Object key, int hash) {
if (count != 0) { // read-volatile 当前桶的数据个数是否为0
HashEntry<K,V> e = getFirst(hash); 得到头节点
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
returnnull;
}
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
put操作
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
- 是否需要扩容。在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阀值,数组进行扩容。值得一提的是,Segment的扩容判断比HashMap更恰当,因为HashMap是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容。
- 如何扩容。扩容的时候首先会创建一个两倍于原容量的数组,然后将原数组里的元素进行再hash后插入到新的数组里。为了高效ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。
boolean containsKey(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key))
returntrue;
e = e.next;
}
}
returnfalse;
}
size()操作
ConcurrentHashMap(锁分段技术)的更多相关文章
- Java:ConcurrentHashMap的锁分段技术
术语定义 术语 英文 解释 哈希算法 hash algorithm 是一种将任意内容的输入转换成相同长度输出的加密方式,其输出被称为哈希值. 哈希表 hash table 根据设定的哈希函数H(ke ...
- java多线程 -- ConcurrentHashMap 锁分段 机制
hashtable效率低ConcurrentHashMap 线程安全,效率高 Java 5.0 在 java.util.concurrent 包中提供了多种并发容器类来改进同步容器 的性能. Conc ...
- 3.ConcurrentHashMap 锁分段机制 Copy-On-Write
/*ConcurrentHashMap*/ Java 5.0 在 java.util.concurrent 包中提供了 多种 并发容器来改进同步容器的性能 ConcurrentHashMap 同步容器 ...
- 四、ConcurrentHashMap 锁分段机制
回顾: HashMap与Hashtable的底层都是哈希表,但是 HashMap:线程不安全 Hashtable:线程安全,但是效率非常低,且存在[复合操作](如"若存在则删除") ...
- Java进阶知识点6:并发容器背后的设计理念 - 锁分段、写时复制和弱一致性
一.背景 容器是Java编程中使用频率很高的组件,但Java默认提供的基本容器(ArrayList,HashMap等)均不是线程安全的.当容器和多线程并发编程相遇时,程序员又该何去何从呢? 通常有两种 ...
- 3、JUC--ConcurrentHashMap 锁分段机制
ConcurrentHashMap Java 5.0 在 java.util.concurrent 包中提供了多种并发容器类来改进同步容器的性能. ConcurrentHashMap 同步容器 ...
- 【JAVA并发编程实战】9、锁分段
package cn.study.concurrency.ch11; /** * 锁分段 * @author xiaof * */ public class StripedMap { //同步策略:就 ...
- Java精通并发-锁粗化与锁消除技术实例演示与分析
在上一次https://www.cnblogs.com/webor2006/p/11446473.html中对锁的升级进行了一个比较详细的理论化的学习,先回忆一下: 编译器对于锁的优化措施: 锁消除技 ...
- 记录ConcurrentHashMap的锁分离技术
对比上图,HashTable实现锁的方式是锁整个hash表,而ConcurrentHashMap的实现方式是锁桶(简单理解就是将整个hash表想象成一大缸水,现在将这大缸里的水分到了几个水桶里,has ...
随机推荐
- matlab调试技巧
Matlab的调试总体分为,直接调试和间接调试. 1.直接调试: (1)去掉句末的分号: (2)单独调试一个函数:将第一行的函数声明注释掉,并定义输入量,以脚本方式执行 M 文件: (3)适当地方添加 ...
- 17-正交矩阵和Gram-Schmidt正交化
一.视频链接 1)正交矩阵 定义:如果一个矩阵,其转置与自身的乘积等于单位向量,那么该矩阵就是正交矩阵,该矩阵一般用Q来表示,即$Q^TQ=QQ^T=I$,也就是$Q^T=Q^{-1}$,即转置=逆 ...
- Django 使用简单笔记
1. Django项目的启动: 1. 命令行启动 在项目的根目录下(也就是有manage.py的那个目录),运行: python3 manage.py runserver IP:端口--> 在指 ...
- URAL - 1486 二维字符串HASH
题目链接:http://acm.timus.ru/problem.aspx?space=1&num=1486 题意:给定一个n*m的字符矩阵,问你是否存在两个不重合(可以有交集)的正方形矩阵完 ...
- shell脚本检索所有mysql数据库中没有primary key的表
1.mkdir -p /root/scripts/ 2. cd /root/scripts/ vim query.sql,代码如下: SELECT CONCAT(t.table_schema,&quo ...
- 9.Markdown语法(自用)——2019年12月12日
title: markdown语法说明 date: "2018-12-26 20:17:16" tags: 技术指令 categories: 技术驿站 markdown语法说明 2 ...
- 2.xml约束技术----------dtd约束
1.xml的约束 (1)为什么需要定义约束了 比如现在定义一个person的xml文件,只想要这个文件里面保存人的信息,比如name age等,但是如果在xml文件中写了一个元素<猫>,发 ...
- C#高级编程42章 MVC
42.1 ASP.NET MVC 路由机制 网络介绍链接 按照传统,在很多Web框架中(如经典的ASP.JSP.PHP.ASP.NET等之类的框架),URL代表的是磁盘上的物理文件.例如,当看到请求h ...
- python2和python3同时存在电脑时,安装包时的的命令行
若是在Python2中使用pip操作时,用pip2或是pip2.7相关命令. 例:给Python2安装selenium,在cmd中输入 pip2 install selenium 或是 pip2.7 ...
- mybatis的Date类型。
在写select的时候,里面的查询语句.where后面如果jdbcType=DATE没有写的话是 这个形式的. <select id="selectPhoto" parame ...