2019基于python的网络爬虫系列,爬取糗事百科
**因为糗事百科的URL改变,正则表达式也发生了改变,导致了网上许多的代码不能使用,所以写下了这一篇博客,希望对大家有所帮助,谢谢!**
废话不多说,直接上代码。
为了方便提取数据,我用的是beautifulsoup库和requests
``## 具体代码如下
```
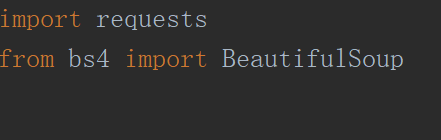
import requests
from bs4 import BeautifulSoup
def download_page(url):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0"}
r = requests.get(url, headers=headers)
return r.text
def get_content(html):
soup = BeautifulSoup(html, 'html.parser')
con = soup.find(id='main')
con_list = con.find_all('div', class_="cat_llb")
for i in con_list:
author = i.find('h3').string # 获取名字
content = i.find('div', id="endtext").get_text() # 获取内容
save_txt(author, content)
def save_txt(*args):
for i in args:
with open('qiubai.txt', 'a', encoding='utf-8') as f:
f.write(i+'\n'+'\n')
# def save_txt(str):
# for i in str:
#
# with open('qiubai.txt', 'a', encoding='utf-8') as f:
# f.write(str + '\n')
# f.write(i)
def main():
# 可以构造如下 url,
for i in range(1, 20):
url = 'http://www.lovehhy.net/Joke/Detail/QSBK/{}'.format(i)
html = download_page(url)
get_content(html)
if __name__ == '__main__':
main()
```
哦 ,对了,新网站的地址是http://www.lovehhy.net/Joke/Detail/QSBK/
有什么不懂得欢迎留言
2019基于python的网络爬虫系列,爬取糗事百科的更多相关文章
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- python爬虫之爬取糗事百科并将爬取内容保存至Excel中
本篇博文为使用python爬虫爬取糗事百科content并将爬取内容存入excel中保存·. 实验环境:Windows10 代码编辑工具:pycharm 使用selenium(自动化测试工具)+p ...
- python+正则提取+ip代理爬取糗事百科文字信息
很多网站都有反爬措施,最常见的就是封ip,请求次数过多服务器会拒绝连接,如图: 在程序中设置一个代理ip,可有效的解决这种问题,代码如下: # 需要的库 import requests import ...
- Python爬虫:爬取糗事百科
网上看到的教程,但是是用正则表达式写的,并不能运行,后面我就用xpath改了,然后重新写了逻辑,并且使用了双线程,也算是原创了吧#!/usr/bin/python# -*- encoding:utf- ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- 8.Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- [爬虫]用python的requests模块爬取糗事百科段子
虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Humans”,说明使用更 ...
随机推荐
- LightOJ 1030 Discovering Gold (概率/期望DP)
题目链接:LightOJ - 1030 Description You are in a cave, a long cave! The cave can be represented by a \(1 ...
- Mysql 主从同步(转载)
第一步: 在master上创建用于同步的用户 GRANT FILE,REPLICATION SLAVE,REPLICATION CLIENT,SUPER ON *.* TObackup@'192.16 ...
- Spring Boot集成Mybatis双数据源
这里用到了Spring Boot + Mybatis + DynamicDataSource配置动态双数据源,可以动态切换数据源实现数据库的读写分离. 添加依赖 加入Mybatis启动器,这里添加了D ...
- C# 网络编程 TcpListener
1.服务断代码 public partial class Server : Form { private bool lk = true; public Server() { InitializeCom ...
- spring security 学习二
doc:https://docs.spring.io/spring-security/site/docs/ 基于表单的认证(个性化认证流程): 一.自定义登录页面 1.在securityConfigy ...
- 【目录】ASP.NET Core 基础教程
ASP.NET Core 基础教程 ASP.NET Core 基础教程 ASP.NET Core 简介 ASP.NET Core Windows 环境配置 ASP.NET Core macOS 环境配 ...
- webpack 集成 Typescript && Less
webpack 集成 Typescript && Less TypeScript是JavaScript的一个类型化的超集,可以编译成纯JavaScript,在本指南中,我们将学习如何将 ...
- 喜讯!联诚发创始人龙平芳荣获2019LED行业优秀女企业家称号!联诚发横揽三项大奖!
2019年12月20日,在深圳大梅沙京基喜来登度假酒店隆重举行“蝶变跨越”慧聪LED显示屏行业品牌盛会颁奖典礼!在来自全国各地的LED显示屏行业协会领导,企业领袖,精英代表以及来自全国各 ...
- python制作坦克对战
创建子弹类 import pygame class Bullet(pygame.sprite.Sprite): def __init__(self): pygame.sprite.Sprite.__i ...
- Java之JDBC操作数据库
DBC JDBC就是一套接口,真正执行的是jar包里得实现类,通过泛型对象来执行实现类里的方法. 步骤: ###1.导入驱动jar包到工程中 ###2.编写代码注册驱动,我们要让程序知道用的是哪个驱动 ...