Storm之WordCount初探
刚接触Strom,记录下执行过程
1、pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>org.toda.demo</groupId>
<artifactId>demo</artifactId>
<version>1.0-SNAPSHOT</version> <name>demo</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency> <dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.6</version>
<!-- <scope>provided</scope>-->
</dependency> <dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libthrift</artifactId>
<version>0.9.3</version>
</dependency>
</dependencies> <build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
<plugins>
<!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle -->
<plugin>
<artifactId>maven-clean-plugin</artifactId>
<version>3.1.0</version>
</plugin>
<!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging -->
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.1</version>
</plugin>
<plugin>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-install-plugin</artifactId>
<version>2.5.2</version>
</plugin>
<plugin>
<artifactId>maven-deploy-plugin</artifactId>
<version>2.8.2</version>
</plugin>
<!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle -->
<plugin>
<artifactId>maven-site-plugin</artifactId>
<version>3.7.1</version>
</plugin>
<plugin>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.0.0</version>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
2、WordCountSpout.java文件
package org.toda.demo.wordcout; import java.util.Map;
import java.util.Random;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
//执行顺序:open() --> nextTuple() -->declareOutputFields()
public class WordCountSpout extends BaseRichSpout {
private Map map;
private TopologyContext context;
private SpoutOutputCollector collector; String text[]={
"你好 谢谢 再见",
"哈哈 再见 吃饭",
"再见 你好 睡觉",
"上班 谢谢 辛苦",
"开心"
};
Random random=new Random();
@Override
public void nextTuple() {
Values line = new Values(text[random.nextInt(text.length)]);
//发送tuple消息,并返回起发送任务的task的序列号集合
collector.emit(line);
Utils.sleep(1000);
System.err.println("splot----- emit------- "+line);
} @Override
public void open(Map map, TopologyContext context, SpoutOutputCollector collector) {
//数据初始化
this.map=map;
this.context=context;
this.collector=collector;
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//定义元组中变量结构的名字
declarer.declare(new Fields("newFields"));
}
}
3\WordCountBolt.java文件
package org.toda.demo.wordcout; import java.util.List;
import java.util.Map; import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
//执行顺序: prepare() --> execute() --> declareOutputFields()
public class WordCountBolt extends BaseRichBolt {
private OutputCollector collector; @Override
public void execute(Tuple input) {
//随机获取单行数据,
//String line = input.getString(0);
//也可以用下面的代码通过field获取,这里0是返回这个String的0号位置
String line=input.getStringByField("newFields");
//切分字符串单词
String[] words = line.split(" ");
//向后发送tuple
for(String word : words){
List w=new Values(word);
collector.emit(w);
}
} @Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
//数据初始化
this.collector=collector;
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
} }
4\WordFinalBolt.java文件
package org.toda.demo.wordcout; import java.util.HashMap;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Tuple; public class WordFinalBolt extends BaseRichBolt {
private OutputCollector collector;
Map<String, Integer> map=new HashMap<String,Integer>(); @Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector){
this.collector=collector;
} @Override
public void execute(Tuple input) {
int count =1;
//获取切分后的每一个单词
String word = input.getStringByField("word");
if(map.containsKey(word)) {
count=(int) map.get(word)+1;
}
map.put(word, count);
//输出
System.err.println(word+"============="+count);
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
} }
5、Test.java文件(main函数)
package org.toda.demo.wordcout; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields; public class Test { public static void main(String[] args) {
//创建一个拓扑
TopologyBuilder tb=new TopologyBuilder();
//拓扑设置 喷嘴以及个数
tb.setSpout("ws", new WordCountSpout());
//拓扑设置 Bolt以及个数,shuffleGrouping表示随机分组
tb.setBolt("wordcountbolt", new WordCountBolt(),3).shuffleGrouping("ws");
//fieldsGrouping表示按照字段分组,即是同一个单词只能发送给一个Bolt
tb.setBolt("wc", new WordFinalBolt(),3).fieldsGrouping("wordcountbolt",new Fields("word") );
//本地模式,测试
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("wordconut",new Config(), tb.createTopology());
}
}
总结:
从代码可看出,Spout是将数据源封装成Tuple,而Bolt主要是对Tuple进行逻辑处理,可以有多个Bolt执行,最后一个Bolt是最后所需数据。
执行过程:
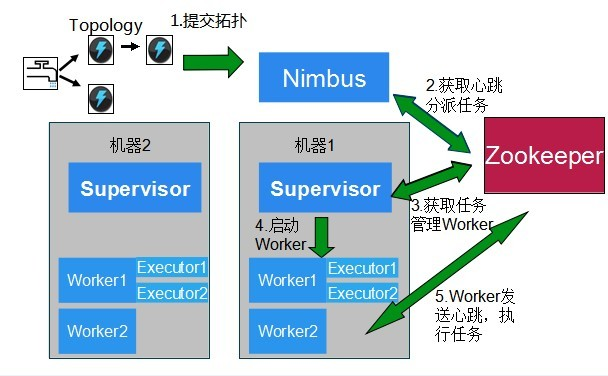
Storm之WordCount初探的更多相关文章
- 基于Storm的WordCount
Storm WordCount 工作过程 Storm 版本: 1.Spout 从外部数据源中读取数据,随机发送一个元组对象出去: 2.SplitBolt 接收 Spout 中输出的元组对象,将元组中的 ...
- Storm系列(三):创建Maven项目打包提交wordcount到Storm集群
在上一篇博客中,我们通过Storm.Net.Adapter创建了一个使用Csharp编写的Storm Topology - wordcount.本文将介绍如何编写Java端的程序以及如何发布到测试的S ...
- 3、SpringBoot 集成Storm wordcount
WordCountBolt public class WordCountBolt extends BaseBasicBolt { private Map<String,Integer> c ...
- STORM_0002_在做好的zookeeper集群上搭建storm的开发环境
参考文献http://www.cnblogs.com/panfeng412/archive/2012/11/30/how-to-install-and-deploy-storm-cluster.htm ...
- storm的数据源编程单元Spout学习整理
Spout呢,是Topology中数据流的源头,也是Storm针对数据源的编程单元.一般数据的来源,是通过外部数据源来读取数据项(Tuple),并读取的数据项传输至作业的其他组件.编程人员一般可通过O ...
- storm安装以及简单操作
storm的安装比较简单,下面以storm的单节点为例说明storm的安装步骤. 1.storm的下载 进入storm的官方网站http://storm.apache.org/,点击download按 ...
- Storm 运行例子
1.建立Java工程 使用idea,添加lib库,拷贝storm中lib到工程中 2.拷贝wordcount代码 下载src包,解压找到 apache-storm-0.9.4-src\apache-s ...
- Storm的并行度
在Storm集群中,运行Topolopy的实体有三个:工作进程,executor(线程),task(任务),下图可以形象的说明他们之间的关系. 工作进程 Storm集群中的一台机器会为一个或则多个To ...
- 三:Storm设计一个Topology用来统计单词的TopN的实例
Storm的单词统计设计 一:Storm的wordCount和Hadoop的wordCount实例对比
随机推荐
- dede_arctype|栏目表
dede_arctype|栏目表: 字段 类型 整理 属性 Null 默认 额外 id smallint(5) UNSIGNED 是 NULL 栏目ID reid smallint(5) UNSIGN ...
- shell条件嵌套(if条件语句)
[注意1]:和Java.PHP等语言不一样,sh的流程控制不可为空,如: 代码如下: <?php if (isset($_GET["q"])) { search(q); } ...
- golang time json mongodb 时间处理
golang 中解决前端time 输出,后端mongodb中时间存储. package mask import ( "fmt" "time" "go. ...
- Linux SUID SGID SBIT 简介和权限设定
SUID :Set UID 1 SUID 权限仅对二进制程序(binary program)有效 2 执行者对于该程序需要具有x的可执行权限 3 本权限仅在执行该程序的过程中有效(run-time) ...
- [牛客] [# 1108 E] Grid
2019牛客国庆集训派对day3 链接:https://ac.nowcoder.com/acm/contest/1108/E来源:牛客网 题意 在一个$10 ^ 9 * 10 ^ 9$ 的方格中,每次 ...
- Idea发布项目到Docker
一.Docker开启远程访问 [root@local host ~]# vi /lib/systemd/system/docker.service #修改ExecStart这行 ExecStart=/ ...
- C#调用C++的dll各种传参
1. 如果函数只有传入参数,比如: //C++中的输出函数 int __declspec(dllexport) test(const int N) { ; } 对应的C#代码为: [DllImport ...
- printf计算参数是从右到左压栈的(a++和++a的压栈的区别)
一.问题 c++代码: #include <iostream> #include <stdio.h> using namespace std; int main(){ ; co ...
- (转载)Ant自动编译打包android项目
1 Ant自动编译打包android项目 1.1 Ant安装 ant的安装比较简单,下载ant压缩包 http://ant.apache.org (最新的为1.9.3版本),下载之后将其解压 ...
- 创建本地repo源
1,保留rpm包 yum 安装时保留包至指定目录 编辑/etc/yum.conf 将keepcache的值设置为1: 2,使用插件 1,yum-plugin-downloadonly插件 sudo y ...