ELK-全文检索技术-lucene
ELK : ELK是ElasticSearch,LogStash以及Kibana三个产品的首字母缩写
一.倒排索引
学习elk,必须先掌握倒排索引思想,
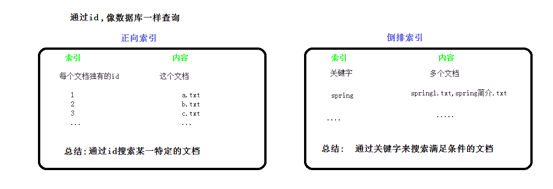
参考文档: https://www.cnblogs.com/zlslch/p/6440114.html
二.什么是全文检索?
诸如传统的正序查询(数据库查询),如果用到京东或淘宝上,用户输入关键字进行查询,无论是标题还是描述只要有关键字就会被查到,很伤!倒排索引能很好的实现电商搜索功能
结构化数据:有固定格式和有限长度 比如 关系型数据库中的数据
查询的方式:sql
如果数据量特别大时:可以使用全文检索技术
非结构化数据:没有固定格式和没有规定长度 比如电脑上的文档 txt word
查询的方式:肉眼查找
如果数据量特别大时:可以使用全文检索技术
三.什么是全文检索技术
3.1全文检索技术:
这种先建立索引,再对索引进行搜索的过程就叫做全文检索
3.2 那些场景用到全文检索技术?
1、搜索引擎 谷歌 百度 360 搜狗 搜搜
2、站内搜索 京东 天猫 微博 天涯 猫扑
3、垂直搜索 视频网站的搜索 优酷,( 在优酷可以搜索到其他视频网站的视频)
四.引入lucene
lucene可以实现全文检索,
Lucene是Apache提供用来实现全文检索的一套类库 jar
五.lucene的使用
5.1需要的坐标
第一步:导入jar
必须的包:lucene-core-4.10.3.jar
lucene-analyzers-common-4.10.3.jar 分词器
commons-io.jar
junit.jar
|
<dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>4.10.3</version> </dependency> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.6</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> |
5.2创建索引
- 获取原始文档
- 构建索引文档对象
- 分析文档(分词)
- 创建索引
具体代码示例:
|
/*** //通过document对象展示出所有结果信息 // 7. 关闭indexReader对象 |
5.3 查询索引
1. 创建用户查询接口,提供一个输入关键字的地方
2. 创建查询
3. 执行查询
4. 渲染结果
具体代码示例:
|
/*** //通过document对象展示出所有结果信息 // 7. 关闭indexReader对象 |
六.分词器
如果检索的是英文,分词器使用标准的就可以,但是外国人编写的中文分词器总是不成功,
这里使用IK-analyzer
StandardAnalyzer:一个字一个字的
CJKAnalyzer:两个字两个字 需要添加
lucene-analyzers-smartcn依赖
SmartChineseAnalyzer:对中文的支持还算可以,但是英文有缺失字母的情况
第三方分词器:IK-analyzer
依赖是:
|
<dependency> <groupId>com.janeluo</groupId> <artifactId>ikanalyzer</artifactId> <version>2012_u6</version> <exclusions> <exclusion> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> </exclusion> </exclusions> </dependency> |
需要三个配置文件
IKAnalyzer.cfg.xml 核心配置文件
ext.dic 扩展词典
stopword.dic 停用词典
七. 使用分词器进行查询
public static void selectIndex(String keywords) throws IOException, ParseException {
|
八. 打分
关键字占的比重及权重
举例说明
关键字占的比例即权重
spring.txt 分词后的结果:spring txt 50%
spring_README.txt 分词后的结果:spring README txt 33%
spring的简介.txt 分词后的结果:spring 简介 简 介 txt 20%
spring是个非常流行的框架.txt
spring是个开发中非常流行的框架.txt
问题
为什么百度搜索时权重较低的广告可以排在最前面?
设置权重
可以设置boost值 默认是1.0
在添加索引的时候设置权重
Field fileContentField=new TextField("filecontent",fileContent,Field.Store.YES);
|
ELK-全文检索技术-lucene的更多相关文章
- 全文检索技术---Lucene
1 Lucene介绍 1.1 什么是Lucene Lucene是apache下的一个开源的全文检索引擎工具包.它为软件开发人员提供一个简单易用的工具包(类库),以方便的在目标系统中实现 ...
- (转)全文检索技术学习(一)——Lucene的介绍
http://blog.csdn.net/yerenyuan_pku/article/details/72582979 本文我将为大家讲解全文检索技术——Lucene,现在这个技术用到的比较多,我觉得 ...
- Lucene全文检索技术
Lucene全文检索技术 今日大纲 ● 搜索的概念.搜索引擎原理.倒排索引 ● 全文索引的概念 ● 使用Lucene对索引进行CRUD操作 ● Lucene常用API详解 ● ...
- Lucene全文检索技术学习
---------------------------------------------------------------------------------------------------- ...
- JAVAEE——Lucene基础:什么是全文检索、Lucene实现全文检索的流程、配置开发环境、索引库创建与管理
1. 学习计划 第一天:Lucene的基础知识 1.案例分析:什么是全文检索,如何实现全文检索 2.Lucene实现全文检索的流程 a) 创建索引 b) 查询索引 3.配置开发环境 4.创建索引库 5 ...
- 全文搜索技术—Lucene
1. 内容安排 实现一个文件的搜索功能,通过关键字搜索文件,凡是文件名或文件内容包括关键字的文件都需要找出来.还可以根据中文词语进程查询,并且支持多种条件查询. 本案例中的原始内容就是磁盘上的文件 ...
- 全文检索(Lucene&Solr)
全文检索(Lucene&Solr) 1)什么是全文检索?为什么需要全文检索? 结构化数据(mysql等)方便查询,而非结构化数据(如多篇文章)是难以查询到自己需要的,所以要使用全文检索. 全文 ...
- 全文检索框架---Lucene
一.什么是全文检索 1.数据分类 我们生活中的数据总体分为两种:结构化数据和非结构化数据. 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等. 非结构化数据:指不定长或无固定格式 ...
- (转)全文检索技术学习(二)——配置Lucene的开发环境
http://blog.csdn.net/yerenyuan_pku/article/details/72589380 Lucene下载 Lucene是开发全文检索功能的工具包,可从官方网站http: ...
随机推荐
- sqli-labs(39)
0X01 这关和38关一样 ?id= and =1 正确 ?id=1 and 1=2 错误 不需要闭合 构造语法 0X02 ?id=;insert into users values(,"z ...
- C++入门经典-例3.20-使用continue跳出循环
1:continue不是立即跳出循环体,而是跳过本次循环结束前的语句,回到循环的条件测试部分.代码如下: // 3.20.cpp : 定义控制台应用程序的入口点. // #include " ...
- java期末课程总结
期末课程总结 转眼间,这个学期就要过去了,我们Java的学习也接近了尾声,回想到这个学期刚开始接触到Java的时候,感觉什么都不懂,但现在似乎有了门路,不会载懵懵懂懂, 虽然本学期面向对象与Java程 ...
- HTML控件 隐藏
div的visibility可以控制div的显示和隐藏,但是隐藏后页面显示空白: style="visibility: none;" document.getElementById ...
- Servlet基础总结
1.Servlet概念: Java Servlet 是运行在 Web 服务器或应用服务器上的程序,它是作为来自 Web 浏览器或其他 HTTP 客户端的请求和 HTTP 服务器上的数据库或应用程序之间 ...
- Git-Runoob:Git 服务器搭建
ylbtech-Git-Runoob:Git 服务器搭建 1.返回顶部 1. Git 服务器搭建 上一章节中我们远程仓库使用了 Github,Github 公开的项目是免费的,但是如果你不想让其他人看 ...
- 代码实现:一个数如果恰好等于它的因子之和,这个数就称为"完数"。例如6=1+2+3.第二个完全数是28, //它有约数1、2、4、7、14、28,除去它本身28外,其余5个数相加, //编程找出1000以内的所有完数。
import java.util.ArrayList; import java.util.List; //一个数如果恰好等于它的因子之和,这个数就称为"完数".例如6=1+2+3. ...
- Python Module_sys/random
目录 目录 前言 软件环境 Python标准库初识 Python常用的标准库模块 dir 函数使用方法 sys操作系统功能模块 sysstdinsysstdoutsysstderr标准IOError流 ...
- Arouter核心思路和源码
前言 阅读本文之前,建议读者: 对Arouter的使用有一定的了解. 对Apt技术有所了解. Arouter是一款Alibaba出品的优秀的路由框架,本文不对其进行全面的分析,只对其最重要的功能进行源 ...
- 【BW系列】SAP 讲讲BW/4 HANA和BW on HANA的区别
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[BW系列]SAP 讲讲BW/4 HANA和BW ...