scrapy项目1:爬取某培训机构老师信息(spider类)
1、scrapy爬虫的流程,可简单该括为以下4步:
1).新建项目---->scrapy startproject 项目名称(例如:myspider)
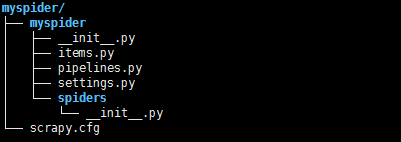
>>scrapy.cfg为项目配置文件
>>myspider:项目的Python模块,将会从这里引用代码
>>mySpider/items.py :项目的目标文件
>>mySpider/pipelines.py :项目的管道文件
>>mySpider/settings.py :项目的设置文件
>>mySpider/spiders/ :存储爬虫代码目录
2).编写items.py文件,可以理解为要爬取的内容,后边在案例中说明
3).编写爬虫文件,在spiders中自己创建,或者通过命令:scrapy genspider 爬虫名 爬虫允许访问的域
4).存储内容(pipelines.py)
案例:爬取黑马培训的老师信息
第一步:创建项目 scrapy startproject ItcastSpider
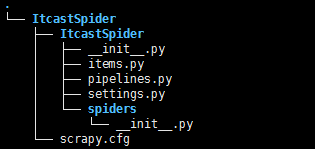
第二步:解析网页,明确要爬取的内容,并编写item文件,代码如下:
- # -*- coding: utf-8 -*-
- # Define here the models for your scraped items
- # See documentation in:
- # http://doc.scrapy.org/en/latest/topics/items.html
- import scrapy
- class ItcastspiderItem(scrapy.Item):
- # define the fields for your item here like:
- # name = scrapy.Field()
- # 老师姓名
- name = scrapy.Field()
- # 职位
- level = scrapy.Field()
- # 介绍信息
- info = scrapy.Field()
第三步:编写爬虫文件 切入spiders文件夹,通过scrapy genspider itcast 'itcast.cn' 来创建
- # -*- coding: utf-8 -*-
- import scrapy
- # 导入之前已经写好的items文件中的类
- from ItcastSpider.items import ItcastspiderItem
- class ItcastSpider(scrapy.Spider):
- name = "itcast" #爬虫名
- allowed_domains = ["http://www.itcast.cn"] #爬虫允许访问的域
- start_urls = ['http://www.itcast.cn/channel/teacher.shtml#apython'] # 要爬取的第一个url
- def parse(self, response):
- # 通过scrapy内置的xpath规则解析网页,返回一个包含selector对象的列表
- teacher_list = response.xpath('//div[@class="li_txt"]')
- # 实例化类
- item = ItcastspiderItem()
- for each in teacher_list:
- # 通过xpath解析后返回该表达式所对应的所有节点的selector list列表,利用extract()可将该节点序列化为Unicode字符串并返回列表
- # 老师名称
- item['name'] = each.xpath('./h3/text()').extract()[0]
- # 老师的职称
- item['level'] = each.xpath('./h4/text()').extract()[0]
- # 信息
- item['info'] = each.xpath('./p/text()').extract()[0]
- yield item
第四步:编辑管道文件pipelines,将爬取内容存贮到本地
- # -*- coding: utf-8 -*-
- # Define your item pipelines here
- #
- # Don't forget to add your pipeline to the ITEM_PIPELINES setting
- # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
- import json
- class ItcastspiderPipeline(object):
- def __init__(self):
- # 在本地创建teacher.json文件
- self.filename = open('teacher.json','w')
- def process_item(self, item, spider):
- # python类型转化为json字符串
- text = json.dumps(dict(item),ensure_ascii = False) + '\n'
- # 写入
- self.filename.write(text.encode('utf-8'))
- return item
- def close_spider(self,spider):
- self.filename.close()
第五步:在settings.py中配置管道文件

第六步:启动爬虫 命令 scrapy crawl itcast
scrapy项目1:爬取某培训机构老师信息(spider类)的更多相关文章
- 使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...
- scrapy爬取全部知乎用户信息
# -*- coding: utf-8 -*- # scrapy爬取全部知乎用户信息 # 1:是否遵守robbots_txt协议改为False # 2: 加入爬取所需的headers: user-ag ...
- [转]使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...
- 爬虫系列5:scrapy动态页面爬取的另一种思路
前面有篇文章给出了爬取动态页面的一种思路,即应用Selenium+Firefox(参考<scrapy动态页面爬取>).但是selenium需要运行本地浏览器,比较耗时,不太适合大规模网页抓 ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 十三 web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多网站,当你浏览器访问时看到的信息,在html源文件里却找不到,由得信息还是滚动条滚动到对应的位置后才显示信息, ...
- [Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息
[Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息 2018-07-21 23:53:02 larger5 阅读数 4123更多 分类专栏: 网络爬虫 版权声明: ...
- 爬虫学习(二)--爬取360应用市场app信息
欢迎加入python学习交流群 667279387 爬虫学习 爬虫学习(一)-爬取电影天堂下载链接 爬虫学习(二)–爬取360应用市场app信息 代码环境:windows10, python 3.5 ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
随机推荐
- mavn Nexus Repository Manager漏洞
https://www.secpulse.com/archives/112290.html
- web框架 Spring+SpringMvc+Jpa 纯注解搭建
0.jar包依赖 maven pom.xml <properties> <spring_version>4.3.25.RELEASE</spring_version&g ...
- zk ui安装 (选装,页面查看zk的数据)
# 使用WEB UI查看监控集群-zk ui安装 cd /usr/local git clone https://github.com/DeemOpen/zkui.git yum install -y ...
- MySQL数据表操作命令
mysql语句: 1.修改表名: rename table 旧表名 to 新表名; 2.修改字段类型: alter table 表名 modify column 字段名 字段类型(长度) 3.修改字段 ...
- 腾讯万亿级分布式消息中间件TubeMQ正式开源
TubeMQ是腾讯在2013年自研的分布式消息中间件系统,专注服务大数据场景下海量数据的高性能存储和传输,经过近7年上万亿的海量数据沉淀,目前日均接入量超过25万亿条.较之于众多明星的开源MQ组件,T ...
- [转载]Jupyter Notebook中自动补全代码
原文地址:https://yq.aliyun.com/articles/667928 在公众号之前的文章中,已经介绍了在Jupyter Notebook中设置主题以及输出代码文件到pdf文件中,本文来 ...
- HTTPS到底是什么
Http存在的问题 上过网的朋友都知道,网络是非常不安全的.尤其是公共场所很多免费的wifi,或许只是攻击者的一个诱饵.还有大家平时喜欢用的万能钥匙,等等.那我们平时上网可能会存在哪些风险呢? ...
- $id(id)函数
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- xml发post请求
# python3字符串换行,在右边加个反斜杠 body = '<?xml version="1.0" encoding = "UTF-8"?>' ...
- JVM运行时的内存划分--JDK1.8
对比JDK1.7,JDK1.8在运行时的内存分配上进行了调整.本篇对JDK1.8版本进行简要介绍. 先以一张图片描述运行时内存: 程序计数器 记录当前线程执行的字节码行号.如果执行的是native方法 ...