Python 变量类型 Ⅱ
Python字符串
字符串或串(String)是由数字、字母、下划线组成的一串字符。
一般记为 :
它是编程语言中表示文本的数据类型。
python的字串列表有2种取值顺序:
- 从左到右索引默认0开始的,最大范围是字符串长度少1
- 从右到左索引默认-1开始的,最大范围是字符串开头
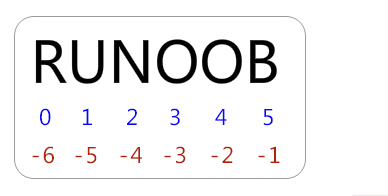
如果你要实现从字符串中获取一段子字符串的话,可以使用 [头下标:尾下标] 来截取相应的字符串,其中下标是从 0 开始算起,可以是正数或负数,下标可以为空表示取到头或尾。
[头下标:尾下标] 获取的子字符串包含头下标的字符,但不包含尾下标的字符。
比如:

当使用以冒号分隔的字符串,python 返回一个新的对象,结果包含了以这对偏移标识的连续的内容,左边的开始是包含了下边界。
上面的结果包含了 s[1] 的值 b,而取到的最大范围不包括尾下标,就是 s[5] 的值 f。

加号(+)是字符串连接运算符,星号(*)是重复操作。如下实例:

以上实例输出结果:

Python 列表截取可以接收第三个参数,参数作用是截取的步长,以下实例在索引 1 到索引 4 的位置并设置为步长为 2(间隔一个位置)来截取字符串:
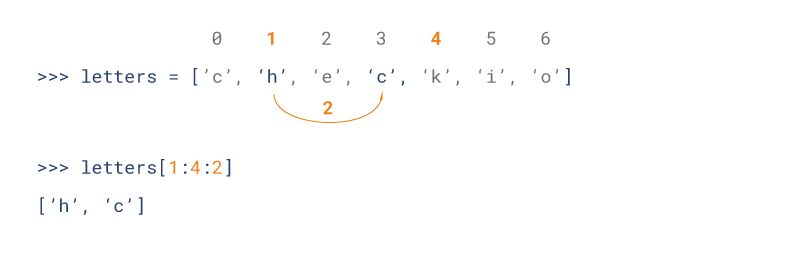
Python列表
List(列表) 是 Python 中http://www.xuanhe.net/使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)。
列表用 [ ] 标识,是 python 最通用的复合数据类型。
列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。

加号 + 是列表连接运算符,星号 * 是重复操作。如下实例:
实例(Python 2.0+)
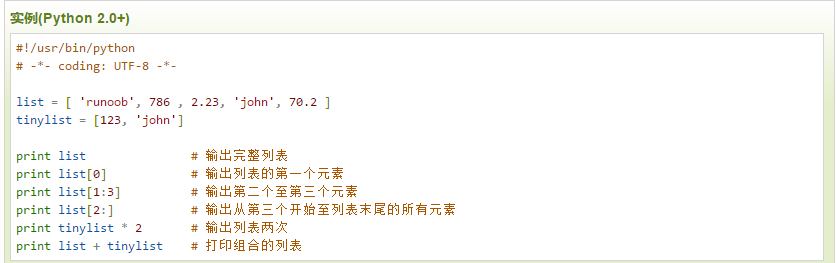
以上实例输出结果:

Python 变量类型 Ⅱ的更多相关文章
- Python 变量类型
Python 变量类型 变量存储在内存中的值.这就意味着在创建变量时会在内存中开辟一个空间. 基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中. 因此,变量可以指定不同的数据 ...
- Python变量类型
Python变量类型 变量是存储在内存中的值,因此在创建变量时会在内存中开辟一个空间. 基于变量的数据类型,解释器会分配指定的内存,并决定什么数据可以被存储在内存中. 因此变量可以指定不同的数据类型, ...
- Python变量类型(l整型,长整形,浮点型,复数,列表,元组,字典)学习
#coding=utf-8 __author__ = 'Administrator' #Python变量类型 #Python数字,python支持四种不同的数据类型 int整型 long长整型 flo ...
- [Python]基础教程(4)、Python 变量类型
Python 变量类型 变量存储在内存中的值.这就意味着在创建变量时会在内存中开辟一个空间. 基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中. 因此,变量可以指定不同的数据 ...
- 【Python笔记】Python变量类型
Python 变量类型 变量存储在内存中的值.这就意味着在创建变量时会在内存中开辟一个空间. 基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中. 因此,变量可以指定不同的数据 ...
- 记住 Python 变量类型的三种方式
title: 记住变量类型的三种方式 date: 2017-06-11 15:25:03 tags: ['Python'] category: ['Python'] toc: true comment ...
- Python变量类型说明
Python中的变量不需要声明,直接赋值便是声明和定义的过程 每个变量在内存中创建,都包括变量的标识.名称和数据这些信息 每个变量在使用前必须赋值 counter = 100 #正数变量 miles ...
- Python 变量类型及变量赋值
在 Python 中,变量不一定占用内存变量.变量就像是对某一处内存的引用,可以通过变量访问到其所指向的内存中的值,并且可以让变量指向其他的内存.在 Python 中,变量不需要声明,但是使用变量之前 ...
- Python学习--Python变量类型
变量存储在内存中的值.这就意味着在创建变量时会在内存中开辟一个空间. 基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中. 因此,变量可以指定不同的数据类型,这些变量可以存储整 ...
- Python变量类型及变量
python是解释性语言 什么是解释性语言 就相当于你去饭店,你点了10道菜,他做好1道给你上1道.解释一行,执行一行.速度上不如编译性语言快. 什么是编译性语言 就相当于去饭店吃饭,你点了10道菜, ...
随机推荐
- Unity中的动画系统和Timeline(5) Timeline
在前面的动画,都是控制单独的物体,比如说控制一个角色的运动.而Timeline,可以对多个物体实施动画,形成过场动画,或者电影效果.比如,很多赛车游戏比赛开始前都会播放一段开场动画,围绕自己车的几个方 ...
- GIS学习之栅格数据
栅格数据用一个规则格网来描述与每一个格网单元位置相对应的空间现象特征的位置和取值.在概念上,空间现象的变化由格网单元值的变化来反映.地理信息系统中许多数据都用栅格格式来表示.栅格数据在许多方面是矢量数 ...
- 基于高斯分布的异常检测(Anomaly Detection)算法
记得在做电商运营初期,每每为我们频道的促销活动锁取得的“超高”销售额感动,但后来随着工作的深入,我越来越觉得这里面水很深.商家运营.品类运营不断的通过刷单来获取其所需,或是商品搜索排名,或是某种kpi ...
- 【VS开发】windows注册ActiveX控件
ActiveX控件是一个动态链接库,是作为基于COM服务器进行操作的,并且可以嵌入在包容器宿主应用程序中,ActiveX控件的前身就是OLE控件.由于ActiveX控件与开发平台无关,因此,在一种编程 ...
- for循环实现九九乘法表
<!--for循环实现九九乘法表--> <table border="> <tbody> {% for x in range(1,10) %} <t ...
- BATJ的常见java面试题
JAVA基础 JAVA中的几种基本数据类型是什么,各自占用多少字节. String类能被继承吗,为什么. 不可以,因为String类有final修饰符,而final修饰的类是不能被继承的,实现细节不允 ...
- Ubuntu 19.04 下使用Remmina连接window服务器部署maven项目
先将打包好的war包上传到tomcat的webapps目录下 如果配置了tomcat的虚拟路径,那就放进虚拟路径的webapps文件李 修改tomcat安装目录下的conf/server.xml文件 ...
- [codeforces940E]Cashback
题目链接 题意是说将$n$个数字分段使得每段贡献之和最小,每段的贡献为区间和减去前$\left \lfloor \frac{k}{c}\right \rfloor$小的和. 仔细分析一下可以知道,减去 ...
- ubuntu 安装 Gurobi 的tips
要跑的一个深度学习框架用到了gurobi 安装在ubuntu上栽了两天时间,我安装的是ubuntu16.04的版本 自己去官网下载gurobi,我安装的是gurobi8.1.1 然后申请相应的lice ...
- java多图片上传
2017-09-16 <script type="text/javascript" src="http://apps.bdimg.com/libs/jquery/2 ...