主题模型值LDA
主题模型(topic model)是以非监督学习的方式对文集的隐含语义结构(latent semantic structure)进行聚类(clustering)的统计模型。
主题模型主要被用于自然语言处理(Natural language processing)中的语义分析(semantic analysis)和文本挖掘(text mining)问题,例如按主题对文本进行收集、分类和降维;也被用于生物信息学(bioinfomatics)研究 [2] 。隐含狄利克雷分布(Latent Dirichlet Allocation, LDA)是常见的主题模型。
1. LDA贝叶斯模型
LDA是基于贝叶斯模型的,涉及到贝叶斯模型离不开“先验分布”,“数据(似然)”和"后验分布"三块。在朴素贝叶斯算法原理小结中我们也已经讲到了这套贝叶斯理论。在贝叶斯学派这里:
先验分布 + 数据(似然)= 后验分布
这点其实很好理解,因为这符合我们人的思维方式,比如你对好人和坏人的认知,先验分布为:100个好人和100个的坏人,即你认为好人坏人各占一半,现在你被2个好人(数据)帮助了和1个坏人骗了,于是你得到了新的后验分布为:102个好人和101个的坏人。现在你的后验分布里面认为好人比坏人多了。这个后验分布接着又变成你的新的先验分布,当你被1个好人(数据)帮助了和3个坏人(数据)骗了后,你又更新了你的后验分布为:103个好人和104个的坏人。依次继续更新下去。
2. 二项分布与Beta分布
对于上一节的贝叶斯模型和认知过程,假如用数学和概率的方式该如何表达呢?
对于我们的数据(似然),这个好办,用一个二项分布就可以搞定,即对于二项分布:
$Binom(k|n,p)=\binom{n}{k}p^{k}(1-p)^{n-k}$
其中$p$我们可以理解为好人的概率,$k$为好人的个数,$n$为好人坏人的总数。
虽然数据(似然)很好理解,但是对于先验分布,我们就要费一番脑筋了,为什么呢?因为我们希望这个先验分布和数据(似然)对应的二项分布集合后,得到的后验分布在后面还可以作为先验分布!就像上面例子里的“102个好人和101个的坏人”,它是前面一次贝叶斯推荐的后验分布,又是后一次贝叶斯推荐的先验分布。也即是说,我们希望先验分布和后验分布的形式应该是一样的,这样的分布我们一般叫共轭分布。在我们的例子里,我们希望找到和二项分布共轭的分布。
和二项分布共轭的分布其实就是Beta分布。Beta分布的表达式为:
$Beta(p|\alpha ,\beta )= \frac{\Gamma (\alpha +\beta )}{\Gamma (\alpha \Gamma (\beta ))}p^{\alpha -1}(1-p)^{\beta -1}$
其中$\Gamma$是Gamma函数,满足$\Gamma (x)=(x-1)!$
仔细观察Beta分布和二项分布,可以发现两者的密度函数很相似,区别仅仅在前面的归一化的阶乘项。那么它如何做到先验分布和后验分布的形式一样呢?后验分布$P(p|n,k,\alpha ,\beta )$推导如下:
$P(p|n,k,\alpha ,\beta )\propto P(k|n,p)P(p|\alpha ,\beta )=P(k|n,p)P(p|\alpha ,\beta )=Binom(k|n,p)Beta(p|\alpha ,\beta )=\binom{n}{k}p^{k}(1-p)^{n-k}\times \frac{\Gamma (\alpha +\beta )}{\Gamma (\alpha )\Gamma (\beta )}p^{\alpha -1}(1-p)^{\beta -1}\propto p^{k+\alpha -1}(1-p)^{n-k+\beta -1}$
将上面最后的式子归一化以后,得到我们的后验概率为:
$P(p|n,k,\alpha ,\beta )=\frac{\Gamma (\alpha +\beta +n)}{\Gamma (\alpha+k) \Gamma (\beta+n-k)}p^{k+\alpha -1}(1-p)^{n-k+\beta -1}$
可见我们的后验分布的确是Beta分布,而且我们发现:
$Beta(p|\alpha ,\beta )+BinomCount(k,n-k)=Beta(p|\alpha+k ,\beta+n-k )$
这个式子完全符合我们在上一节好人坏人例子里的情况,我们的认知会把数据里的好人坏人数分别加到我们的先验分布上,得到后验分布。
我们在来看看Beta分布$Beta(p|\alpha ,\beta )$的期望:
$E(Beta(p|\alpha ,\beta ))=\int_{0}^{1}tBeta(p|\alpha ,\beta )dt=\int_{0}^{1}\frac{\Gamma (\alpha +\beta )}{\Gamma (\alpha )\Gamma (\beta )}t^{\alpha -1}(1-t)^{\beta -1}dt=\int_{0}^{1}\frac{\Gamma (\alpha +\beta )}{\Gamma (\alpha )\Gamma (\beta )}t^{\alpha}(1-t)^{\beta -1}dt$
由于上式最右边的乘积对应Beta分布$Beta(p|\alpha+1 ,\beta )$,因此有:
$\int_{0}^{1}\frac{\Gamma (\alpha +\beta +1)}{\Gamma (\alpha+1 )\Gamma (\beta )}p^{\alpha}(1-p)^{\beta -1}dp=1$
这样我们的期望可以表达为:
$E(Beta(p|\alpha ,\beta ))=\frac{\Gamma (\alpha +\beta )}{\Gamma (\alpha )\Gamma (\beta )}\frac{\Gamma (\alpha +1)\Gamma (\beta )}{\Gamma (\alpha+\beta +1 )}=\frac{\alpha }{\alpha +\beta }$
这个结果也很符合我们的思维方式。
3. 多项分布与Dirichlet 分布
现在我们回到上面好人坏人的问题,假如我们发现有第三类人,不好不坏的人,这时候我们如何用贝叶斯来表达这个模型分布呢?之前我们是二维分布,现在是三维分布。由于二维我们使用了Beta分布和二项分布来表达这个模型,则在三维时,以此类推,我们可以用三维的Beta分布来表达先验后验分布,三项的多项分布来表达数据(似然)。
三项的多项分布好表达,我们假设数据中的第一类有$m_{1}$个好人,第二类有$m_{2}$个坏人,第三类为$m_{3}=n-m_{1}-m_{2}$个不好不坏的人,对应的概率分别为$p_{1}$,$m_{2}$,$m_{3}=n-m_{1}-m_{2}$,则对应的多项分布为:
$multi(m_{1},m_{2},m_{3}|n,p_{1},p_{2},p_{3})=\frac{n!}{m_{1}!m_{2}!m_{3}!}p_{1}^{m_{1}}p_{2}^{m_{2}}p_{3}^{m_{3}}$
那三维的Beta分布呢?超过二维的Beta分布我们一般称之为狄利克雷(以下称为Dirichlet )分布。也可以说Beta分布是Dirichlet 分布在二维时的特殊形式。从二维的Beta分布表达式,我们很容易写出三维的Dirichlet分布如下:
$Dirichlet(p_{1},p_{2},p_{3}|\alpha _{1},\alpha _{2},\alpha _{3})=\frac{\Gamma (\alpha _{1}+\alpha _{2}+\alpha _{3})}{\Gamma(\alpha _{1} )\Gamma (\alpha _{2})\Gamma (\alpha _{3})}p_{1}^{\alpha _{1}-1}p_{2}^{\alpha _{2}-1}p_{3}^{\alpha _{3}-1}$
同样的方法,我们可以写出4维,5维,。。。以及更高维的Dirichlet 分布的概率密度函数。为了简化表达式,我们用向量来表示概率和计数,这样多项分布可以表示为:$Dirichlet(\overrightarrow{p}|\overrightarrow{\alpha})$,而多项分布可以表示为:$multi(\overrightarrow{m}|n,\overrightarrow{p})$
一般意义上的K维Dirichlet 分布表达式为:
$Dirichlet(\overrightarrow{p}|\overrightarrow{\alpha})=\frac{\Gamma (\sum_{k=1}^{K}\alpha _{k})}{\prod_{k=1}^{K}\Gamma (\alpha _{k})}\prod_{k=1}^{K}p_{k}^{\alpha _{k}-1}$
而多项分布和Dirichlet 分布也满足共轭关系,这样我们可以得到和上一节类似的结论:
$Dirichlet(\overrightarrow{p}|\overrightarrow{\alpha})+MultiCount(\overrightarrow{m})=Dirichlet(\overrightarrow{p}|\overrightarrow{\alpha}+\overrightarrow{m})$
对于Dirichlet 分布的期望,也有和Beta分布类似的性质:
$E(Dirichlet(\overrightarrow{p}|\overrightarrow{\alpha}))=(\frac{\alpha _{1}}{\sum_{k=1}^{K}},\frac{\alpha _{2}}{\sum_{k=1}^{K}},\cdots ,\frac{\alpha _{K}}{\sum_{k=1}^{K}})$
4. LDA主题模型
前面做了这么多的铺垫,我们终于可以开始LDA主题模型了。
我们的问题是这样的,我们有M篇文档,对应第d个文档中有有Nd个词。即输入为如下图:
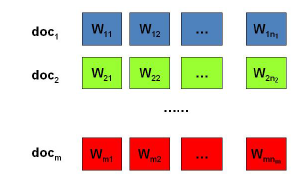
我们的目标是找到每一篇文档的主题分布和每一个主题中词的分布。在LDA模型中,我们需要先假定一个主题数目K,样所有的分布就都基于K个主题展开。那么具体LDA模型是怎么样的呢?具体如下图:
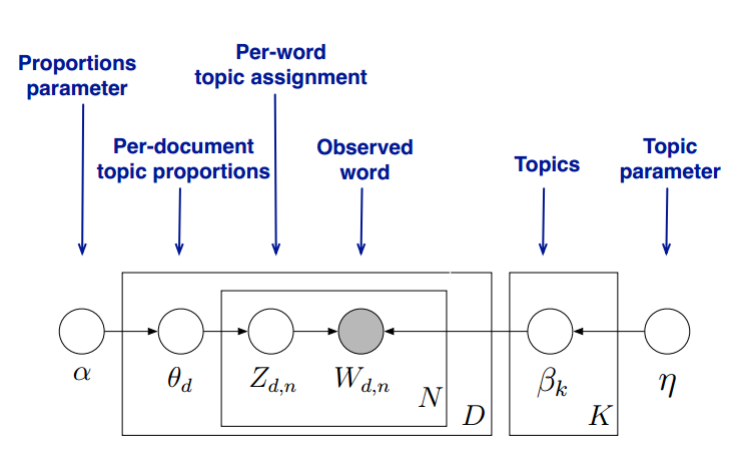 LDA假设文档主题的先验分布是Dirichlet分布,即对于任一文档d,其主题分布$\theta _{d}$为:
LDA假设文档主题的先验分布是Dirichlet分布,即对于任一文档d,其主题分布$\theta _{d}$为:
$\theta _{d}=Dirichlet(\overline{\alpha })$
其中,$\alpha $为分布的超参数,是一个K维向量。
LDA假设主题中词的先验分布是Dirichlet分布,即对于任一主题k,其词分布$\beta _{k}$为:
$\beta _{k}=Dirichlet(\overline{\eta })$
其中,$\eta$为分布的超参数,是一个V维向量。V代表词汇表里所有词的个数。
对于数据中任一一篇文档d中的第n个词,我们可以从主题分布$\theta _{d}$中得到它的主题编号$z_{dn}$的分布为:
$z_{dn}=multi(\theta _{d})$
而对于该主题编号,得到我们看到的词$\omega z_{dn}$的概率分布为:
$\omega z_{dn}=multi(\beta _{zdn})$
理解LDA主题模型的主要任务就是理解上面的这个模型。这个模型里,我们有M个文档主题的Dirichlet分布,而对应的数据有M个主题编号的多项分布,这样($\alpha \rightarrow \theta _{d}\rightarrow \overrightarrow{{z}_{d}}$)就组成了Dirichlet-multi共轭,可以使用前面提到的贝叶斯推断的方法得到基于Dirichlet分布的文档主题后验分布。
如果在第d个文档中,第k个主题的词的个数为:$n_{d}^{k}$,则对应的多项分布的计数可以表示为:
$\overrightarrow{n}_{d}=(n_{d}^{1},n_{d}^{2},\cdots ,n_{d}^{K})$
利用Dirichlet-multi共轭,得到$\theta _{d}$的后验分布为:
$Dirichlet(\theta _{d}|\overrightarrow{\alpha}+\overrightarrow{n}_{d})$
同样的道理,对于主题与词的分布,我们有
主题模型值LDA的更多相关文章
- 文本主题模型之LDA(二) LDA求解之Gibbs采样算法
文本主题模型之LDA(一) LDA基础 文本主题模型之LDA(二) LDA求解之Gibbs采样算法 文本主题模型之LDA(三) LDA求解之变分推断EM算法(TODO) 本文是LDA主题模型的第二篇, ...
- 文本主题模型之LDA(一) LDA基础
文本主题模型之LDA(一) LDA基础 文本主题模型之LDA(二) LDA求解之Gibbs采样算法 文本主题模型之LDA(三) LDA求解之变分推断EM算法(TODO) 在前面我们讲到了基于矩阵分解的 ...
- 文本主题模型之LDA(三) LDA求解之变分推断EM算法
文本主题模型之LDA(一) LDA基础 文本主题模型之LDA(二) LDA求解之Gibbs采样算法 文本主题模型之LDA(三) LDA求解之变分推断EM算法 本文是LDA主题模型的第三篇,读这一篇之前 ...
- 机器学习入门-文本特征-使用LDA主题模型构造标签 1.LatentDirichletAllocation(LDA用于构建主题模型) 2.LDA.components(输出各个词向量的权重值)
函数说明 1.LDA(n_topics, max_iters, random_state) 用于构建LDA主题模型,将文本分成不同的主题 参数说明:n_topics 表示分为多少个主题, max_i ...
- 主题模型(LDA)(一)--通俗理解与简单应用
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/qq_39422642/article/de ...
- display 表格模型值
display:inline-table 此元素会作为内联表格来显示(类似 <table>),表格前后没有换行符.display:inline-table 可以使文字和表格在同一行显示 d ...
- 文本主题抽取:用gensim训练LDA模型
得知李航老师的<统计学习方法>出了第二版,我第一时间就买了.看了这本书的目录,非常高兴,好家伙,居然把主题模型都写了,还有pagerank.一路看到了马尔科夫蒙特卡罗方法和LDA主题模型这 ...
- LDA( Latent Dirichlet Allocation)主题模型 学习报告
1 问题描述 LDA由Blei, David M..Ng, Andrew Y..Jordan于2003年提出,是一种主题模型,它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一 ...
- 主题模型-LDA浅析
(一)LDA作用 传统判断两个文档相似性的方法是通过查看两个文档共同出现的单词的多少,如TF-IDF等,这种方法没有考虑到文字背后的语义关联,可能在两个文档共同出现的单词很少甚至没有,但两个文档是相似 ...
随机推荐
- IDEA 2020.3 更新了,机器学习都整上了
Hello,大家好,我是楼下小黑哥~ 上周 Java 开发申请神器 IDEA 2020.3 新版正式发布: 小黑哥第一时间就在开发机上更新了新版本,并且完整体验了两周了. 下面介绍一下这个版本的主要功 ...
- Vue3 使用 svg-sprite-loader 实现 svg 图标按需加载
前面文章有讲到 svg 图标按需加载的优势以及 Vue 如何使用 vue-svg-icon 实现 svg 图标按需载入: https://www.cnblogs.com/Leophen/p/13201 ...
- 记一次 oracle 数据库在宕机后的恢复
系统:redhat 6.6 oracle版本: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production 问题描述: ...
- Web服务器-正则表达式-小例子(3.1.2)
@ 目录 1.邮箱 2.手机号码 关于作者 1.邮箱 import re def main(): email = input("请输入一个邮件地址:") ret = re.matc ...
- 工具-效率工具-listary快速打开文件,win+R使用(99.1.1)
@ 目录 1.使用WIN+R打开软件 2.使用listary软件 1.使用WIN+R打开软件 添加环境变量 找到需要打开应用的目录 如我的桌面(C:\Users\Public\Desktop) 添加p ...
- 如何在Ubuntu Server 18.04 LTS中配置静态IP地址
安装Ubuntu Server 18.04后需要分配一个的静态IP地址.先前的LTS版本Ubuntu 16.04使用/etc/network/interfaces文件配置静态IP地址,但是Ubuntu ...
- 5分钟完全掌握Python协程
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 1. 协程相关的概念 1.1 进程和线程 进程(Process)是应用程序启动的实例,拥有代码.数据 ...
- 使用CDN后如何配置Apache使其记录访客真实IP
今天想看看哪些地区的人访问过我的网站,于是打开Apache网站响应日志,把访客IP复制到百度,发现搜到的全部都是我是用的CDN的节点IP,真实的访客IP并没有被记录. 如图所示,上面的103.45.7 ...
- Word2Vec和LDA的区别与联系
Word2vec是目前最常用的词嵌入模型之一.是一种浅层的神经网络模型,他有2种网络结构,分别是CBOW(continues bag of words)和 skip-gram.Word2vec 其实是 ...
- Guns自动化生成代码使用
一.Guns简介 Guns基于Spring Boot2,致力于做更简洁的后台管理系统.包含系统管理,代码生成,多数据库适配,SSO单点登录,工作流,短信,邮件发送,OAuth2登录,任务调度,持续集成 ...