python学习第五天 ----- 函数
1. 内置函数
2.自定义函数:
def funcname(parameter_list):
pass
import sys
sys.setrecursionlimit(100000)
def damage(skill1, skill2):
damage1 = skill1 * 3
damage2 = skill2 * 2 + 10
return damage1, damage2 damages = damage(3, 6)
print(type(damages))
//<class 'tuple'>
def damage(skill1, skill2):
damage1 = skill1 * 3
damage2 = skill2 * 2 + 10
return damage1, damage2 skill1_damage, skill2_damage = damage(3, 6)
print(skill1_damage, skill2_damage) //9 22
3.序列解包与链式赋值:
d = 1,2,3
print(d)
# (1, 2, 3)
# <class 'tuple'>
d = 1,2,3
a, b, c = d
a, b, c = 1,2,3
print(a, b, c)
# 1 2 3
a, b = [1, 2, 3]
#Traceback (most recent call last):
# File ".\c4.py", line 12, in <module>
# a, b = [1, 2, 3]
#ValueError: too many values to unpack (expected 2)
#a, b = [1, 2]
#print(a, b)
## 1 2 a, b = [1]
Traceback (most recent call last):
File ".\c4.py", line 12, in <module>
a, b = [1]
ValueError: not enough values to unpack (expected 2, got 1)
a = b = c = 1
print(a, b, c)
#1 1 1
4.必须参数与关键字参数:
必须参数:
def add(x, y):
result = x + y
return result
add(1)
# Traceback (most recent call last):
# File ".\c1.py", line 12, in <module>
add(1)
# TypeError: add() missing 1 required positional argument: 'y'
关键字参数:
可以指明我传入参数是谁,此时就不需要按照顺序去传入参数。
def add(x, y):
print(x, y) c = add(y = 3, x = 2)
# 2 3
默认参数:
def print_student_files(name, gender='男', age=22, college="华北水利水电大学"):
print('我叫' + name)
print('我今年' + str(age) + '岁了')
print('我是' + gender + '生')
print('我在' + college + '上学') print_student_files('鸡小萌', '男', 18, '人民路小学')
print('_______________________________________________')
print_student_files('五六七')
print('_______________________________________________')
print_student_files('果果', age = 17)
我叫鸡小萌
我今年18岁了
我是男生
我在人民路小学上学
_______________________________________________
我叫五六七
我今年22岁了
我是男生
_______________________________________________
我叫果果
我今年17岁了
我是男生
我在华北水利水电大学上学
print_student_files('果果', gender = '女', 17, college='牛津中学')
File "c6.py", line 13
print_student_files('果果', gender = '女', 17, college='牛津中学')
^
SyntaxError: positional argument follows keyword argument
可变参数:
def demo(*param):
print(param)
print(type(param)) demo(1,2,3,4,5,6)
#结果:
#(1, 2, 3, 4, 5, 6)
#<class 'tuple'>
def demo(*param):
print(param)
print(type(param)) a = (1, 2, 3, 4, 5, 6)
demo(*a)
def demo(param1, *param, param2 = 2):
print(param1)
print(param2)
print(param) demo('a', 1,2,3, param2 = '3') #a
#3
#(1, 2, 3)
关键字可变参数:
def city_temp(**param):
print(param)
print(type(param))
pass city_temp(bj = '32', xm = '23', sh = '31') #{'bj': '32', 'xm': '23', 'sh': '31'}
#<class 'dict'>
def city_temp(**param):
for key, value in param:
print(key, ':', value) city_temp(bj = '32', xm = '23', sh = '31') #b : j
#x : m
#s : h
def city_temp(**param):
for key, value in param.items():
print(key, ':', value) city_temp(bj = '32', xm = '23', sh = '31') #bj : 32
#xm : 23
#sh : 31
def city_temp(**param):
for key, value in param.items():
print(key, ':', value) a = {'bj': '32c', 'sh':'31c'}
city_temp(**a) #PS F:\pythonlearn\Demo\eight> python .\c8.py
# bj : 32c
#sh : 31c
5.变量作用域:
此处可以看到与javascript中的作用域有很大的不同。先来看代码:
c = 50 def add(x, y):
c = x + y
print(c) add(1, 2)
print(c)
#3
#50
c = 10 def demo():
print(c) demo() #10
def demo():
c = 50 for i in range(0, 9):
a = 'a'
c += 1
print(c)
print(a) demo() #59
#a
6.作用域链:
c = 1 def func1():
c = 2
def func2():
c = 3
print(c)
func2() func1() //依次将 c = 3, c = 2这两行代码注释,得到打印的结果分别是3, 2, 1
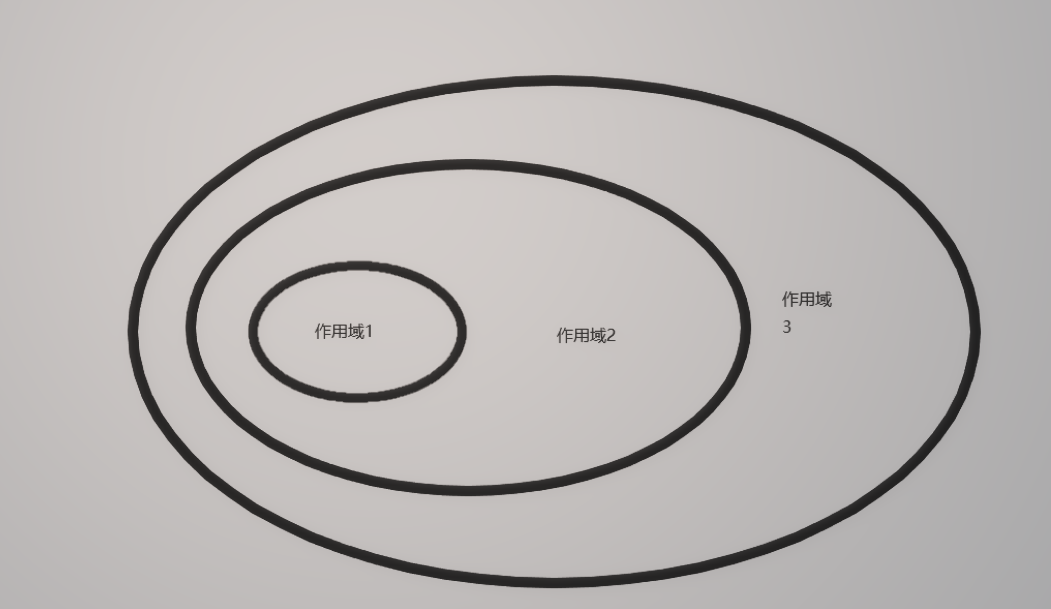
7.global关键字:
def demo():
global c
c = 2 demo() print(c)
#2
import c10
print(c10.c) //2
import c10
print(c) //c是未定义,因此,这个c并不是在项目中全局
python学习第五天 ----- 函数的更多相关文章
- Python学习(五)函数 —— 内置函数 lambda filter map reduce
Python 内置函数 lambda.filter.map.reduce Python 内置了一些比较特殊且实用的函数,使用这些能使你的代码简洁而易读. 下面对 Python 的 lambda.fil ...
- Python学习笔记五,函数及其参数
在Python中如何自定义函数:其格式为 def 函数名(函数参数): 内容
- Python学习(五)函数 —— 自定义函数
Python 自定义函数 函数能提高应用的模块性,和代码的重复利用率.Python提供了许多内建函数,比如print()等.也可以创建用户自定义函数. 函数定义 函数定义的简单规则: 函数代码块以de ...
- python学习第五天--函数进阶
局部变量与全局变量下面代码中,old_price,rite为全局变量,final_price为局部变量 globals() 声明全局变量,在函数内可修改函数外的变量 内嵌函数:函数当中嵌套函数 闭包: ...
- python学习第五次笔记
python学习第五次笔记 列表的缺点 1.列表可以存储大量的数据类型,但是如果数据量大的话,他的查询速度比较慢. 2.列表只能按照顺序存储,数据与数据之间关联性不强 数据类型划分 数据类型:可变数据 ...
- Python学习第五堂课
Python学习第五堂课推荐电影:华尔街之狼 被拯救的姜哥 阿甘正传 辛德勒的名单 肖申克的救赎 上帝之城 焦土之城 绝美之城 #上节内容: 变量 if else 注释 # ""& ...
- Python学习笔记之常用函数及说明
Python学习笔记之常用函数及说明 俗话说"好记性不如烂笔头",老祖宗们几千年总结出来的东西还是有些道理的,所以,常用的东西也要记下来,不记不知道,一记吓一跳,乖乖,函数咋这么多 ...
- python学习交流 - 内置函数使用方法和应用举例
内置函数 python提供了68个内置函数,在使用过程中用户不再需要定义函数来实现内置函数支持的功能.更重要的是内置函数的算法是经过python作者优化的,并且部分是使用c语言实现,通常来说使用内置函 ...
- Python学习(六) —— 函数
一.函数的定义和调用 为什么要用函数:例如,计算一个数据的长度,可以用一段代码实现,每次需要计算数据的长度都可以用这段代码,如果是一段代码,可读性差,重复代码多: 但是如果把这段代码封装成一个函数,用 ...
随机推荐
- html关键字高亮
/** * @id 父节点id * @key 关键字 */ function keyLight(id, key, bgColor){ var oDiv = document.getElementByI ...
- 我的第三次C语言作业
我的第三次C语言作业 这个作业属于哪个课程 https://edu.cnblogs.com/campus/zswxy/SE2020-2 这个作业要求在哪里 https://edu.cnblogs.co ...
- php 之 excel导出导入合并
<?php class Excel extends Controller { //直属高校 public function __construct() { parent::Controller( ...
- 深度探秘.NET 5.0
今年11月10号 .NET 5.0 如约而至.这是.NET All in one后的第一个版本,虽然不是LTS(Long term support)版本,但是是生产环境可用的. 有微软的背书,微软从. ...
- python之路 《四》 字典
python中的字典使得python来解决问题变得更方便,顾名思义,就是当我知道关键字(key)那么我就可以通过key来找到与之对应的信息. 简单的来说字典是另一种可变容器模型,且可存储任意类型对象. ...
- php大文件上传失败的解决方法
1.打开php.ini 2.查找post_max_size:(修改上传大小限制) 表单提交最大数值,此项不是限制上传单个文件的大小,而是针对整个表单的提交数据进行限制的默认为8m,设置为自己需要的值, ...
- logback怎么写?分类输出日志到不同的文件
此appender有顺序,最好不要乱调顺序,输出日志如下: drwxr-xr-x 2 root root 4096 Dec 3 00:00 2019-12-02drwxr-xr-x 2 root ro ...
- HDU100题简要题解(2050~2059)
HDU2050 折线分割平面 题目链接 Problem Description 我们看到过很多直线分割平面的题目,今天的这个题目稍微有些变化,我们要求的是n条折线分割平面的最大数目.比如,一条折线可以 ...
- Weevely使用方法以及通信流量分析
Weevely简介 weevely项目地址:点击查看 weevely是一款针对PHP的webshell的自由软件,可用于模拟一个类似于telnet的连接shell,weevely通常用于web程序的漏 ...
- python-基础入门-7基础
1.语法和语句 Python中有一些基本规则和特殊字符 1)#符号之后的表示注释 2)\n符号表示换行 3)\继续上一行的内容 推荐使用括号,这样可读性更好 4):将两个语句链接在一行中 类似于c语言 ...