聊一聊mycat数据库集群系列之双主双重实现
最近在梳理数据库集群的相关操作,现在花点时间整理一下关于mysql数据库集群的操作总结,恰好你又在看这一块,供一份参考。本次系列终结大概包括以下内容:多数据库安装、mycat部署安装、数据库之读写分离主从复制、数据库之双主多重、数据库分库分表。每一个点,有可能会对应一篇或者多篇文章,由于还要继续上班工作,所以本系列分享预计持续时间需要10天左右,有兴趣的您可以持续关注。我是一个菜鸟,如果写的不好的地方,望多多指点和包涵。
好了,不逼逼了,直接进入本次的主题:mycat双主双重实现。在前的几篇文章中,我们已经完整的介绍了主从备份,读写分离实现。但是在实际生产中,为了系统的高可用,主从备份是远远不够用的,比如:要是主挂了,那么整个系统的写数据都挂了,如果读数据库挂了,那怎么整个系统的读操作也就挂了,为了实现系统的高可用,在实际项目中,我们会搭建至少搭建双主多重。
一、简介
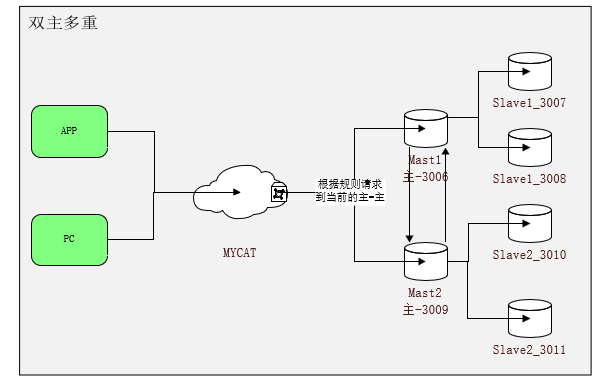
数据库集群的方式有多种 ,前面的介绍的一种是主从复制,读写分离,这一种方式在一般的系统已经够用了,但是对系统可用性要求很高的系统,这样是会有缺陷的,原因是:主只有一个,万一主挂了呢?那系统的所有读操作都将被中断,系统不能提供写服务,当重挂了,系统不同提高读服务,所以无论那一台数据库挂了,系统都会受到影响。对于高可用的系统,那是不行的,比如:电商系统等等。不急不急,其实也很简单,一台不够,那就多台就解决问题了:双主多重,双主:主要指的是两台主机(一主一备),两台主机相互间要同步数据,其中一台挂了另外一台可以正常运行。这样能够大大提升系统的高可用。
本次以双主4重来做实例练习,在同一台服务器上,通过不同端口来区分不同的数据库,具体的数据配置如下:
|
服务器名称 |
端口 |
备注 |
|
Master_3306 |
3306 |
第一台主机,需要和第二台主机(主备机)同步数据 |
|
Slave1_3307 |
3307 |
第一台主机对应的第一台重机 |
|
Slave1_3308 |
3308 |
第一台主机对应的第二台重机 |
|
Master_3309 |
3309 |
第二台主机(主备机),需要和第一台主同步数据 |
|
Slave1_3310 |
3310 |
第二台主机对应的第一台重机 |
|
Slave1_3311 |
3311 |
第二台主机对应的第二台重机 |
二、数据库环境准备
双主多重的在原理上,和上一篇说的主从备份的原理都是一样的,双主双从只是在原来的基础上,针对主机和重机都增加了对于的备机。主机的有两个数据库实例,其实两个的主备的角色是相互的,当一台机器挂了,另外一台机器就充当了主机。所以最终数据的体现效果就是,所有主机和从机都要保持数据一致。为了达到这一目录,在备份上需要策略如下:两台主机间都要相互同步、每一台主机对于的重机都需要同步对应的主机数据。最终的数据同步关系为:
3306 与 3307 相互数据同步
3308、3309 都要同步3306的数据
3310、3311 都要同步3307的数据
在配置文件上和上一篇的配置原理一样,只是针对两个主机需要新增一个配置节点:log-slave-updates:在作为从库的时候,有写入操作也要更新二进制文件。
下面简单罗列每一个数据库的my.ini的配置文件
3306配置文件
[Client]
port =
[mysqld]
#设置3306端口
port =
# 设置mysql的安装目录
basedir=C:\Program Files (x86)\MySQL\MySQL Server .0_3306
# 设置mysql数据库的数据的存放目录
datadir=C:\Program Files (x86)\MySQL\MySQL Server .0_3306\data
# 允许最大连接数
max_connections=
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 主从复制设置
# 设置服务id,注意改id值在同一个数据库集群中要保持唯一
server-id =
# 写入磁盘策略 该参数的有效值有 、、
# 默认值为1,在实际使用过程中,为了效率,我们一般会在设置为2
innodb_flush_log_at_trx_commit=
# 开启binlog日志同步功能
# 这个参数直接影响mysql的性能和完整性。
sync_binlog=
# 在作为从库的时候,有写入操作也要更新二进制文件
log-slave-updates
# 二进制日志保留天数
expire_logs_days=
# binlog日志文件名(可以任意命名)
log-bin=mysql-bin
# 表示自增长字段每次递增的量,其默认值是1,取值范围是1 ..
auto_increment_increment=
# 表示自增长字段从那个数开始,他的取值范围是1 ..
auto_increment_offset=
# 在主主同步配置时,需要将两台服务器的auto_increment_increment增长量都配置为2,而要把auto_increment_offset分别配置为1和2.
# 这样才可以避免两台服务器同时做更新时自增长字段的值之间发生冲突。
# 同步的数据库设置方式有两种:
# binlog_do_db:设置需要同步的数据库
# binlog-ignore-db:设置不需要同步的数据库
#同步的数据库,除此之外别的不同步(和下面binlog-ignore-db二选一)
# binlog_do_db=testdb
#不同步数据库,除此之外都同步
binlog-ignore-db = information_schema
binlog-ignore-db = mysql
binlog-ignore-db = performance_schema
binlog-ignore-db = sys
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
3307置文件
[Client]
port =
[mysqld]
#设置3307端口
port =
# 设置mysql的安装目录
basedir=C:\Program Files (x86)\MySQL\MySQL Server .0_3307
# 设置mysql数据库的数据的存放目录
datadir=C:\Program Files (x86)\MySQL\MySQL Server .0_3307\data
# 允许最大连接数
max_connections=
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 主从复制设置
# 设置服务id,注意改id值在同一个数据库集群中要保持唯一
server-id =
# 写入磁盘策略 该参数的有效值有 、、
# 默认值为1,在实际使用过程中,为了效率,我们一般会在设置为2
innodb_flush_log_at_trx_commit=
# 开启binlog日志同步功能
# 这个参数直接影响mysql的性能和完整性。
sync_binlog=
# 表示自增长字段每次递增的量,其默认值是1,取值范围是1 ..
auto_increment_increment=
# 表示自增长字段从那个数开始,他的取值范围是1 ..
auto_increment_offset=
# 在主主同步配置时,需要将两台服务器的auto_increment_increment增长量都配置为2,而要把auto_increment_offset分别配置为1和2.
# 这样才可以避免两台服务器同时做更新时自增长字段的值之间发生冲突。
# 在作为从库的时候,有写入操作也要更新二进制文件
log-slave-updates
# 二进制日志保留天数
expire_logs_days=
# binlog日志文件名(可以任意命名)
log-bin=mysql-bin
# 同步的数据库设置方式有两种:
# binlog_do_db:设置需要同步的数据库
# binlog-ignore-db:设置不需要同步的数据库
#同步的数据库,除此之外别的不同步(和下面binlog-ignore-db二选一)
# binlog_do_db=testdb
#不同步数据库,除此之外都同步
binlog-ignore-db = information_schema
binlog-ignore-db = mysql
binlog-ignore-db = performance_schema
binlog-ignore-db = sys
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
3308配置文件
[Client] port = [mysqld] #设置3308端口 port = # 该id主要要保持唯一,后面在设置主从同步的时候会用到 server-id = # 设置mysql的安装目录 basedir=C:\Program Files (x86)\MySQL\MySQL Server 8.0.21_3308 # 设置mysql数据库的数据的存放目录 datadir=C:\Program Files (x86)\MySQL\MySQL Server 8.0.21_3308\data # 允许最大连接数 max_connections= # 服务端使用的字符集默认为8比特编码的latin1字符集 character-set-server=utf8 # 创建新表时将使用的默认存储引擎 default-storage-engine=INNODB [mysql] # 设置mysql客户端默认字符集 default-character-set=utf8
3309配置文件
[Client]
port = [mysqld]
#设置3309端口
port =
# 该id主要要保持唯一,后面在设置主从同步的时候会用到
server-id =
# 设置mysql的安装目录
basedir=C:\Program Files (x86)\MySQL\MySQL Server 8.0.21_3309
# 设置mysql数据库的数据的存放目录
datadir=C:\Program Files (x86)\MySQL\MySQL Server 8.0.21_3309\data
# 允许最大连接数
max_connections=
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB [mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
3310配置文件
[Client]
port = [mysqld]
#设置3310端口
port =
# 该id主要要保持唯一,后面在设置主从同步的时候会用到
server-id =
# 设置mysql的安装目录
basedir=C:\Program Files (x86)\MySQL\MySQL Server 8.0.21_3310
# 设置mysql数据库的数据的存放目录
datadir=C:\Program Files (x86)\MySQL\MySQL Server 8.0.21_3310\data
# 允许最大连接数
max_connections=
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB [mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
3311配置文件
[Client]
port = [mysqld]
#设置3311端口
port =
# 该id主要要保持唯一,后面在设置主从同步的时候会用到
server-id =
# 设置mysql的安装目录
basedir=C:\Program Files (x86)\MySQL\MySQL Server 8.0.21_3311
# 设置mysql数据库的数据的存放目录
datadir=C:\Program Files (x86)\MySQL\MySQL Server 8.0.21_3311\data
# 允许最大连接数
max_connections=
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB [mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
三、数据库配置验证
数据库双主多重配置验证,主要验证两个主机数据更新是否所有集群中的是所有数据是否都发送对应的改变,如果发送说明配置成功。
1、 在3306中创建一个数据test和一个表user
查看其它的库是否都创建了一个库test和一个表user
2、 在3307中对表user插入一条数据
查看其余所有库对于的表是否也新增了该数据
四、mycat双主多从配置
Mycat的使用配置,我们先从最简单的模式(主从复制)开始配置起走。Mycat主从复制主要配置文件有如下两个文件,两个文件都在mycat目录\conf下。
- server.xml: 配置文件包含了mycat的系统配置信息
- schema.xml:涵盖了mycat的逻辑库,表,分片规则,分片节点及数据源。
server.xml配置文件
server.xml主要涉及到两个标签的配置,和上一篇的主重复制一样:
- system标签:主要配置系统相关的配置,在此不在做详细的描述,根据实际需要在去配置;
- user标签:主要用于定义登录mycat的用户和权限,这也是本次需要介绍的配置节点。user标签可以同时配置多个节点。
<!--配置mycat连接用户信息-->
<!--name:用户名-->
<user name="root" defaultAccount="true">
<!--password:用户登录密码-->
<property name="password">xuyuanhong</property>
<!--password:mysql对应的逻辑库名称,如果有多个库,那么不同的库之间通过,连接-->
<property name="schemas">test</property>
</user>
schema.xml配置文件
schema配置相对上一篇的主从复制的配置节点,只是将负载均衡节点balance的值改为1,同时在服务上新增一个主节点,同时新增一个从节点,其余配置不变,如下:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"> <!--schema:mycat整个数据库的映射框架配置,每一个mycat逻辑库需要一个对于的配置节点-->
<!--name:mycat的逻辑库名称,和sercer.xml中的逻辑库名称保持一致-->
<!--checkSQLschema:是否检测SQL,如果设置为 true,那么mycat会对传递的SQL做优化,主要去掉指定库名称,反之则不做任何处理,一般情况下设置false-->
<!--sqlMaxLimit:最大连接数-->
<!--dataNode:主要配置逻辑库和实际库的映射关系,会有一个专门的节点来配置,此处指需要绑定对于的映射关系名称即可-->
<schema name="test" checkSQLschema="false" sqlMaxLimit="" dataNode="dntest">
</schema> <!--dataNode:配置mycat逻辑库和实际库的映射关系-->
<!--name:映射关系名称,要和上面的schema对应的dataNode节点名称保持一致-->
<!--database:实体库映射的真实数据库名称-->
<!--dataHost:具体的数据库连接属性节点名称-->
<dataNode name="dntest" database="test" dataHost="hosttest" /> <!--dataHost:配置数据库的连接信息和路由规则信息-->
<!--name:数据连接地址信息名称,语上面的dataNode节点中的dataHost名称对应-->
<!--maxCon:指定每个读写实例连接池的最大连接-->
<!--minCon:指定每个读写实例连接池的最小连接,初始化连接池的大小-->
<!--balance:查询操作负载均衡类型,目前的取值有以下4种
balance=: 不开启读写分离,所有读操作都发送到当前可用的writeHost上。
balance=: 全部的readHost与Stand by writeHost都参与select语句的负载均衡,
简而言之,当双主双从模式(M1->S1, M2->S2,并且M1与M2互为主备)时,在正常情况下,M2,S1和S2都参与select的负载均
balance=: 所有的读操作都随机在writeHost,readHost上分发。
balance=: 所有的读请求都随机分配到writeHost对应的readHost上执行,writeHost不负担读压力,注意balance=3只在mycat1.4之后版本中有效。
在实际使用中,针对读写分离模式,我们一般都配置为3
-->
<!--writeType:写操作负载均衡类型,目前的取值有3种:
writeType=“”, 所有写操作都发送到可用的writeHost上。
writeType=“”,所有写操作都随机的发送到readHost。
writeType=“”,所有写操作都随机的在writeHost、readhost分上发。
毫无疑问,在实际使用过中,都会配置为0
-->
<!--dbType:指定后端连接的数据库类型,目前支持二进制的mysql协议,还有其他使用JDBC连接的数据库。如mongodb,spark等-->
<!--dbDriver:指定连接后端数据库使用的Driver,目前可选的值有native和JDBC。
使用native的话,因为这个值执行的是二进制的mysql协议,所以可以使用mysql和maridb。
其他类型的数据库则需要使用JDBC驱动来支持
-->
<!--switchType:切换方式:
-1:表示不自动切换。
1:默认值,表示自动切换
2:表示基于MySQL主从同步状态决定是否切换,心跳语句: show slave status.
3:表示基于mysql galary cluster的切换机制,适合mycat1.4之上的版本,心跳语句show status like "%esrep%";
-->
<dataHost name="hosttest" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!--心跳检测语句,mycat也是要实时的去检测每一个映射数据库的状态,通过执行该语句的返回来判断数据库是否在线-->
<heartbeat>select user()</heartbeat>
<!-- writeHost:写服务器映射关系配置 -->
<!-- url:数据库地址(ip+端口号) -->
<!-- user:数据库连接用户名(注意改账号一定要授权可以远程访问改数据库) -->
<!-- password:数据库连接密码 -->
<writeHost host="hostM1" url="192.168.101.191:3306" user="root"
password="xuyuanhong">
<!-- readHost:读服务器映射关系配置,可以配置多个节点,多个节点就代表多个从数据库 -->
<readHost host="hostS11" url="192.168.101.191:3308" user="root" password="xuyuanhong">
</readHost>
<readHost host="hostS12" url="192.168.101.191:3309" user="root" password="xuyuanhong">
</readHost>
</writeHost>
<writeHost host="hostM2" url="192.168.101.191:3307" user="root"
password="xuyuanhong">
<!-- readHost:读服务器映射关系配置,可以配置多个节点,多个节点就代表多个从数据库 -->
<readHost host="hostS21" url="192.168.101.191:3310" user="root" password="xuyuanhong">
</readHost>
<readHost host="hostS22" url="192.168.101.191:3311" user="root" password="xuyuanhong">
</readHost>
</writeHost>
</dataHost>
</mycat:schema>
五、mycat启动及其常用操作命令
- 首先需要进入到mycat安装目录的bin目录下
cd E:\Program Files\mycat\bin
- 开启mycat
mycat.bat start
- 停止mycat
mycat.bat stop
- 重启mycat
mycat.bat restart
- 查看mycat状态
mycat.bat status
六、mycat中遇到的问题解决
其实在实际mycat配置时,我也不是一次配置成功的,也遇到了两个小问题,现在罗列出来,如果刚刚你也遇到了正好可以解决掉。
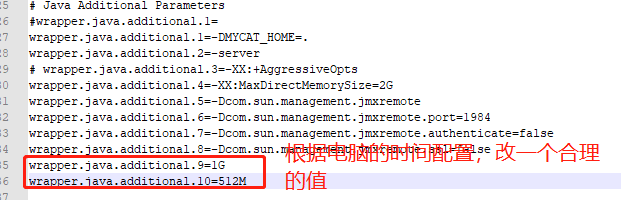
1、Unrecognized VM option 'AggressiveOpts'
解决方式:打开wrapper.conf配置文件,找到AggressiveOpts并将整行注释掉即可,如下图所示:

2、Could not create the Java Virtual Machine.
该问题有可能是设置才内存超出本地环境实际内存,处理方式也简单,直接将wrapper.conf对应的内存改小即可。如下图位置:
有关mycat的部署安装、读写分离就分享到这儿了,下一篇将和大家一起分享mycat的多主多重配置,有兴趣的小伙伴,可以持续关注,谢谢!
好了,到目前为止,针对数据库的主从复制、算主多重的部署从头到尾的每一步都做了一个总结。在后续的文章中就要开始对数据库的分库分表进行梳理回顾。有兴趣的朋友,可以持续关注,谢谢支持。
END
为了更高的交流,欢迎大家关注我的公众号,扫描下面二维码即可关注,谢谢:

聊一聊mycat数据库集群系列之双主双重实现的更多相关文章
- mycat数据库集群系列之数据库多实例安装
mycat数据库集群系列之数据库多实例安装 最近在梳理数据库集群的相关操作,现在花点时间整理一下关于mysql数据库集群的操作总结,恰好你又在看这一块,供一份参考.本次系列终结大概包括以下内容:多数据 ...
- mycat数据库集群系列之mysql主从同步设置
最近在梳理数据库集群的相关操作,现在花点时间整理一下关于mysql数据库集群的操作总结,恰好你又在看这一块,供一份参考.本次系列终结大概包括以下内容:多数据库安装.mycat部署安装.数据库之读写分离 ...
- mycat数据库集群系列之mycat读写分离安装配置
最近在梳理数据库集群的相关操作,现在花点时间整理一下关于mysql数据库集群的操作总结,恰好你又在看这一块,供一份参考.本次系列终结大概包括以下内容:多数据库安装.mycat部署安装.数据库之读写分离 ...
- MySQL集群搭建(6)-双主+keepalived高可用
双主 + keepalived 是一个比较简单的 MySQL 高可用架构,适用于中小 MySQL 集群,今天就说说怎么用 keepalived 做 MySQL 的高可用. 1 概述 1.1 keepa ...
- Centos6.9下RocketMQ3.4.6高可用集群部署记录(双主双从+Nameserver+Console)
之前的文章已对RocketMQ做了详细介绍,这里就不再赘述了,下面是本人在测试和生产环境下RocketMQ3.4.6高可用集群的部署手册,在此分享下: 1) 基础环境 ip地址 主机名 角色 192. ...
- 企业级Nginx+Keepalived集群实战(双主架构)
随着Nginx在国内的发展潮流,越来越多的互联网公司都在使用Nginx,Nginx高性能.稳定性成为IT人士青睐的HTTP和反向代理服务器.Nginx负载均衡一般位于整个网站架构的最前端或者中间层,如 ...
- 数据库集群 MySQL主从复制
MySQL主从复制 本节内容我们联系使用MySQL的主从复制功能配置Master和Slave节点,验证数据MySQL的数据同步功能. 因为要使用多个MySQL数据库,所以不建议在电脑上安装多个MySQ ...
- docker应用-6(mysql+mycat 搭建数据库集群)
上一节,通过使用overlay网络,搭建了跨主机的docker容器集群.下面,在这个跨主机的docker容器集群环境下,搭建mysql 数据库集群. mysql主从自动备份和自动切换 从数据安全性考虑 ...
- mongo 3.4分片集群系列之六:详解配置数据库
这个系列大致想跟大家分享以下篇章: 1.mongo 3.4分片集群系列之一:浅谈分片集群 2.mongo 3.4分片集群系列之二:搭建分片集群--哈希分片 3.mongo 3.4分片集群系列之三:搭建 ...
随机推荐
- matplotlib示例
plt.plot 内只有一个列表示例 import matplotlib.pyplot as plt lst = [4.53,1.94,4.75,0.43,2.02,1.22,2.13,2.77] p ...
- PHP array_combine() 函数
------------恢复内容开始------------ 实例 通过合并两个数组来创建一个新数组,其中的一个数组元素为键名,另一个数组元素为键值: <?php$fname=array(&qu ...
- Python学习手册第4版 中文PDF版|网盘下载内附地址
本书是学习Python编程语言的入门书籍.Python是一种很流行的开源编程语言,可以在各种领域中用于编写独立的程序和脚本.Python免费.可移植.功能强大,而且使用起来相当容易.来自软件产业各个角 ...
- P4274 [NOI2004]小H的小屋 dp 贪心
LINK:小H的小屋 尽管有论文 但是 其证明非常的不严谨 结尾甚至还是大胆猜测等字样... 先说贪心:容易发现m|n的时候此时均分两个地方就是最优的. 关于这个证明显然m在均分的时候的分点一定是n的 ...
- idea查看类继承关系图
找到对应的类 查看类关系图
- JS&ES6学习笔记(持续更新)
ES6学习笔记(2019.7.29) 目录 ES6学习笔记(2019.7.29) let和const let let 基本用法 let 不存在变量提升 暂时性死区 不允许重复声明 块级作用域 级作用域 ...
- IntelliJ IDEA 控制台输出中文乱码
IntelliJ IDEA 控制台输出中文乱码部分如图所示: 解决方法一: 1.打开IntelliJ IDEA本地安装目录中bin文件夹下的idea.exe.vmoptions和idea64.exe. ...
- 当面试官问我ArrayList和LinkedList哪个更占空间时,我这么答让他眼前一亮
前言 今天介绍一下Java的两个集合类,ArrayList和LinkedList,这两个集合的知识点几乎可以说面试必问的. 对于这两个集合类,相信大家都不陌生,ArrayList可以说是日常开发中用的 ...
- Chrome划词翻译-Saladict
Saladict 沙拉查词是一款专业划词翻译扩展,为交叉阅读而生.大量权威词典涵盖中英日韩法德西语,支持复杂的 划词操作.网页翻译.生词本.PDF,以及 Vimium 全键盘操作 . 迄今为止最好用的 ...
- Linux系统中玩到让你停不下来的命令行游戏!
大家好,我是良许. 在使用 Linux 系统时,命令行不仅可以让我们在工作中提高效率,它还可以在生活上给我们提供各种娱乐活动,因为你可以使用它玩许多非常有意思的游戏,这些游戏可都不需要使用专用显卡. ...