where / having / group by / order by / limit 简单查询
目录
- 1.基础查询 —— where
- 2. group by 与 统计函数
- 3. having
- 4.where + group by + having + 函数 综合查询
- 5. order by + limit
- 五种子句总结:
一个重要的概念:将字段当做变量看,无论是条件,还是函数,或者查出来的字段。
select五种子句
where 条件查询
group by 分组
having 筛选
order by 排序
limit 限制结果条数
为了练习上面5种子句,先建立一张goods表,主要用于查询操作,表结构如下:

所有数据:

1.基础查询 —— where
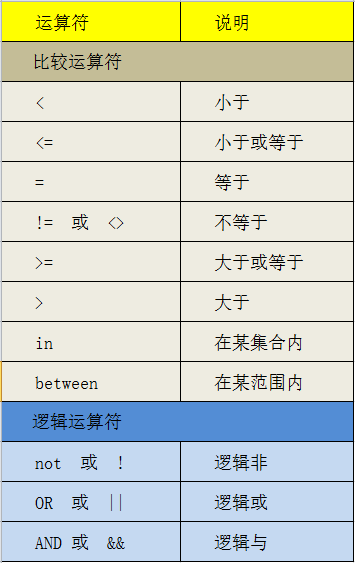
where常用运算符:
1.1 查出主键为20的商品
:mysql> SELECT goods_id,cat_id,goods_sn,goods_name,goods_number,is_hot FROM goods WHERE goods_id = 20;

1.2 查出不属于第三类的所有商品
:mysql> SELECT goods_id,cat_id,goods_sn,goods_name,click_count,is_best FROM goods WHERE cat_id != 3;
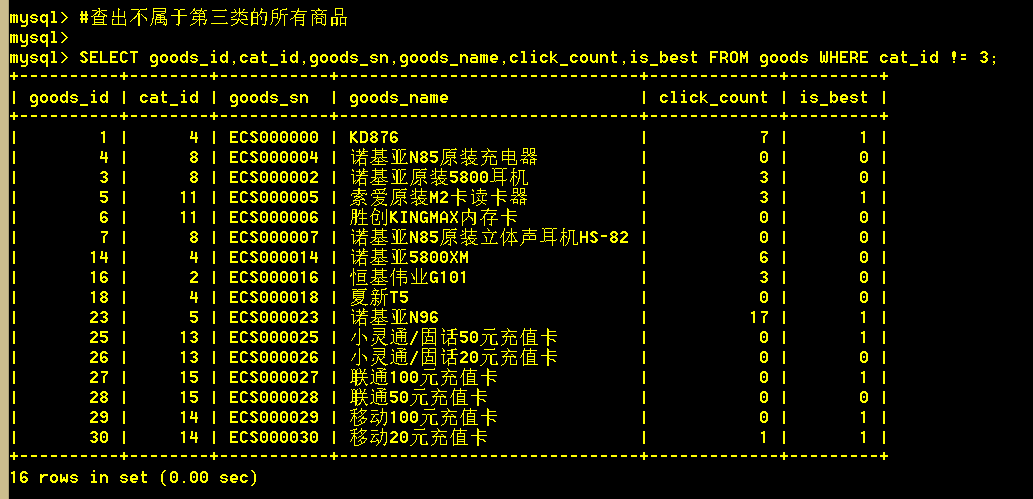
:mysql> SELECT goods_id,cat_id,goods_sn,goods_name,click_count,is_best FROM goods WHERE cat_id <> 3;

1.3 查询高于3000元的商品
:mysql> SELECT goods_id,cat_id,goods_name,shop_price,is_new FROM goods WHERE shop_price > 3000;

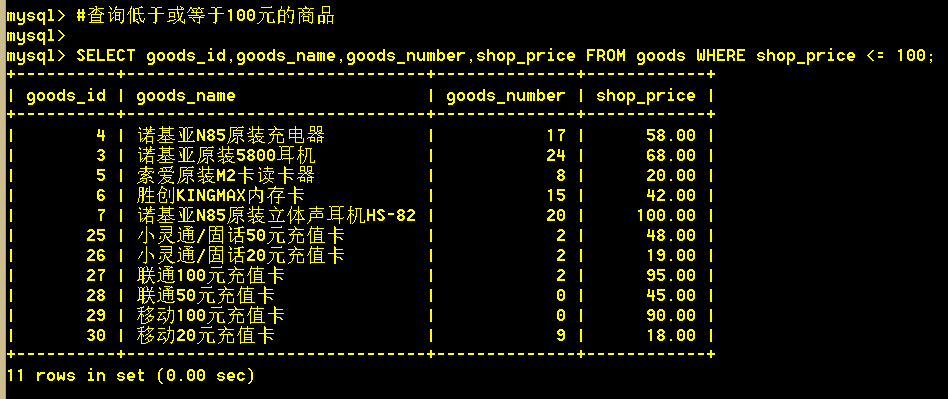
1.4 查询低于或等于100元的商品
:mysql> SELECT goods_id,goods_name,goods_number,shop_price FROM goods WHERE shop_price <= 100;
1.5 取出第4类和第11类的商品
:mysql> SELECT cat_id,goods_name,shop_price FROM goods WHERE cat_id IN (4,11);

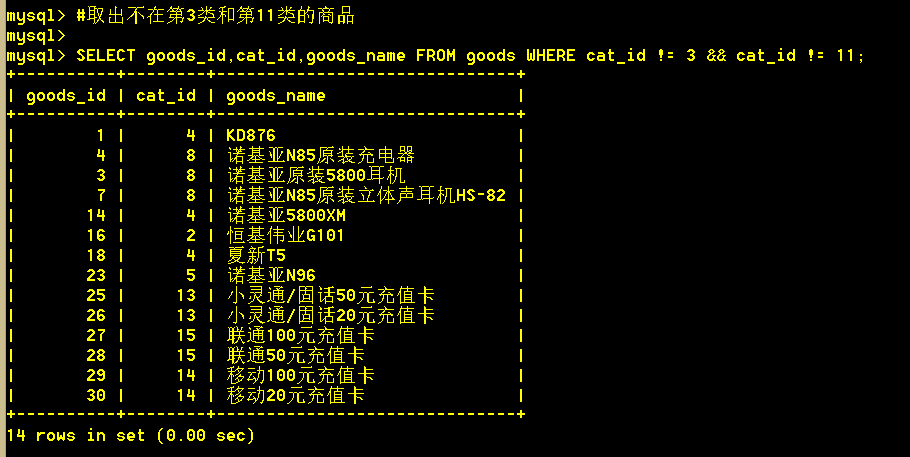
1.6 取出不在第3类和第11类的商品
:mysql> SELECT goods_id,cat_id,goods_name FROM goods WHERE cat_id != 3 && cat_id != 11;
not in 方式实现
:mysql> SELECT goods_id,cat_id,goods_name FROM goods WHERE cat_id NOT IN (3,11);

1.7 取出 100 <= 价格 <= 500 的商品
:mysql> SELECT goods_id,cat_id,goods_name,shop_price FROM goods WHERE shop_price >= 100 && shop_price <= 500;
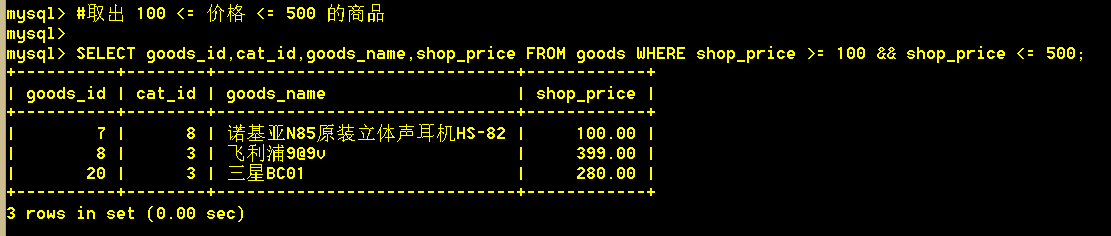
使用between,可以看出是包括边界值的
:mysql> SELECT goods_id,cat_id,goods_name,shop_price FROM goods WHERE shop_price between 100 AND 500;

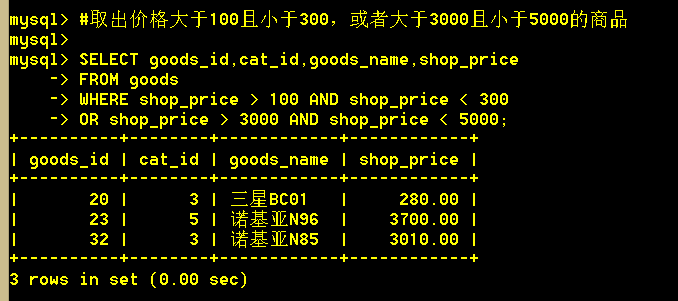
1.8 取出价格大于100且小于300,或者大于3000且小于5000的商品
:mysql> SELECT goods_id,cat_id,goods_name,shop_price
-> FROM goods
-> WHERE shop_price > 100 AND shop_price < 300
-> OR shop_price > 3000 AND shop_price < 5000;
取出价格大于100且小于300,或者大于4000且小于5000的商品
:mysql> SELECT goods_id,goods_name,shop_price FROM goods WHERE shop_price between 100 AND 300 OR shop_price between 4000 AND 5000;

like模糊查询
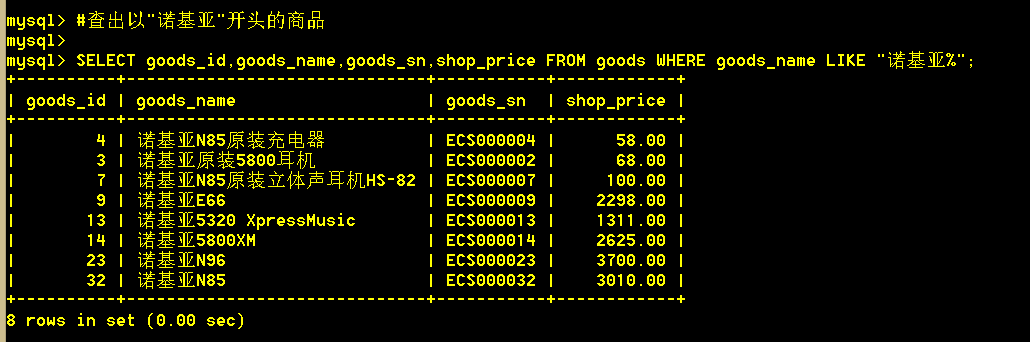
1.9 查出以"诺基亚"开头的商品; "%"通配任意字符
:mysql> SELECT goods_id,goods_name,goods_sn,shop_price FROM goods WHERE goods_name LIKE "诺基亚%";
1.10 取出以"诺基亚N"开头,且后面有两个字符的商品; "_"通配单一字符
:mysql> SELECT goods_id,goods_name,shop_price FROM goods WHERE goods_name LIKE "诺基亚N__";

1.11 取出第三个栏目下面价格在1000到3000之间,并且点击量 > 5 "诺基亚"开头的系列商品
:mysql> SELECT goods_id,goods_name,click_count,shop_price FROM goods WHERE shop_price BETWEEN 1000 AND 3000 AND click_count > 5 AND goods_name LIKE "诺基亚%";

1.12 取出本店价格比市场价格省的钱
:mysql> SELECT goods_name AS '商品名', shop_price AS '本店价格', market_price AS '市场价格', market_price - shop_price AS '省钱' FROM goods WHERE goods_name LIKE "诺基亚%"

1.13 取出省钱200以上的商品;注意where后还是用的运算表达式。
:mysql> SELECT goods_name AS name, shop_price AS shopPrice, market_price AS marketPrice, (market_price-shop_price) AS discount FROM goods WHERE(market_price-shop_price) >= 200;

## where后面不能直接用别名进行表达式判断,会报错,因为where查询是根据表中字段进行查询;查询出来的是一个结果集(可以包含表中没有的字段),如果想对结果集再筛选,可以用having筛选!
:mysql> SELECT goods_name AS '商品名', shop_price AS '本店价格', market_price AS '市场价格', market_price - shop_price AS '省钱' FROM goods WHERE discount >= 200; 错误!
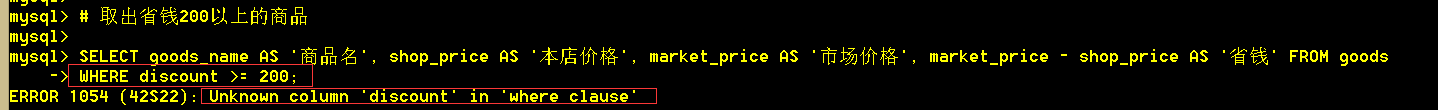
#having再次筛选
:mysql> SELECT goods_name AS name, shop_price AS shopPrice, market_price AS marketPrice, (market_price - shop_price) AS discount FROM goods having discount >= 200;

2. group by 与 统计函数
max:求最大
min:求最小
sum:求和
avg:求平均
count: 求总行数
2.1 查出最贵的商品
:mysql> SELECT max(shop_price) FROM goods;

2.2. 查出最便宜的商品价格
:mysql> SELECT min(shop_price) FROM goods;

2.3 查询总库存量
:mysql> SELECT sum(goods_number) FROM goods;

2.4 查看所有商品的平均价格
:mysql> SELECT avg(shop_price) FROM goods;

2.5 统计共有多少个商品
:mysql> SELECT count(1) FROM goods;

:mysql> select count(name) from test1;
如果count()的字段为NULL是不会计数的
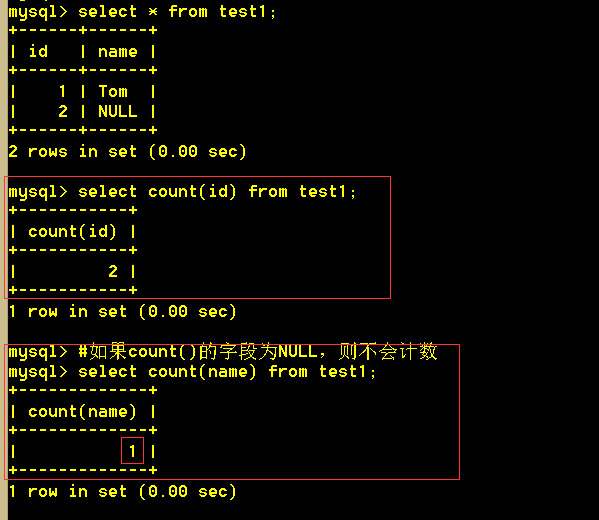
:mysql> select count(*) from test1;
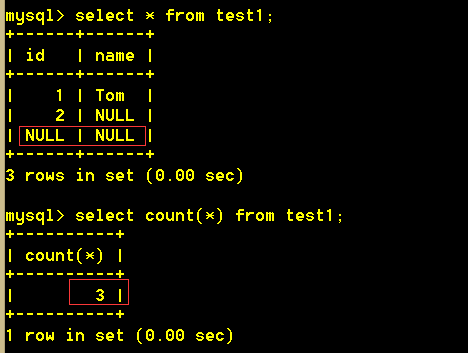
select count(*) 查询的是绝对的行数,就算某行全为NULL,也计算在内。
select count(列名) 查询的是该列不为NULL的所有行的行数。
count(*)和count(1)的区别:对于MyIsam引擎的表,是没有区别的,这种引擎内部有一计数器在维护着行数;如果是InnoDB的表,用count(*) 直接读行数,效率很低,因为会一行行数!
2.6 查询第三类下商品总数
:mysql> select sum(goods_number) from goods where cat_id = 3;

2.7 查询每个类别下的商品总量
:mysql> SELECT cat_id, sum(goods_number) FROM goods GROUP BY cat_id;
group by 有多少个类别,就有多少行
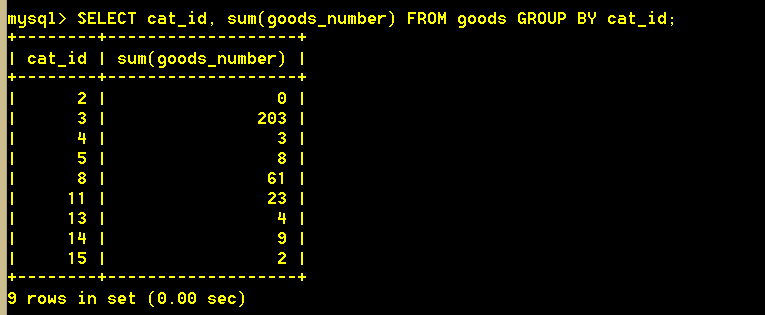
:mysql> SELECT sum(goods_number) FROM goods GROUP BY cat_id;

对于SQL标准来说,下面两个语句是错误的,不能执行。但是在MySql中可以这么干。只是默认查出第一个值而已,但是并没能一一对应。出于可移植性和规范性,不推荐这样写!
严格来说,使用group by a,b,c 时,则select查询的列,只能在a,b,c里选择,语义上才没有矛盾,才能一一对应起来!!!
:mysql> SELECT goods_id, sum(goods_number) FROM goods;(非SQL标准)
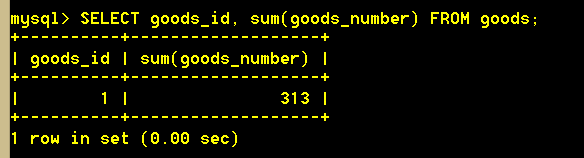
:mysql> SELECT goods_name, sum(goods_number), cat_id FROM goods GROUP BY cat_id; (非SQL标准)
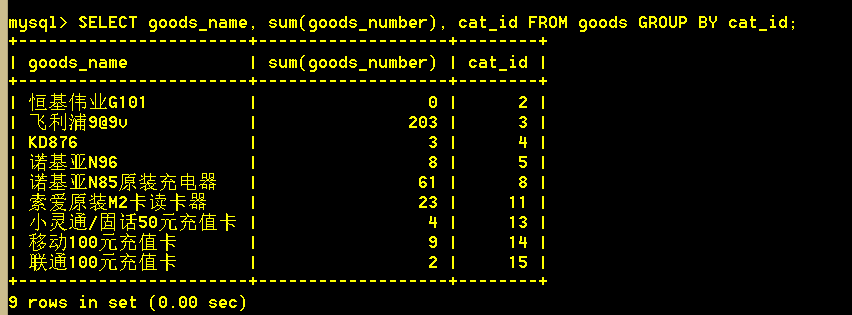
2.8 查询每个类别下商品的平均价格
:mysql> SELECT cat_id, avg(shop_price) FROM goods GROUP BY cat_id;

3. having
3.1 查询每个商品所积压的货款
:mysql> SELECT goods_id,goods_name,goods_number,shop_price, (goods_number * shop_price) AS 'total_price' FROM goods;

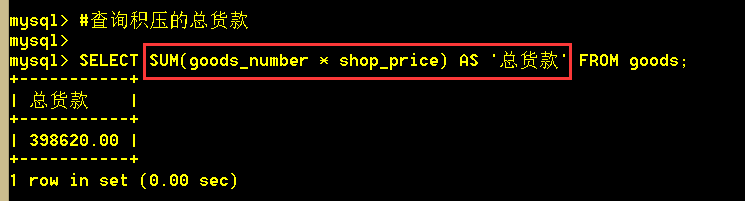
3.2 查询积压的总货款
:mysql> SELECT SUM(goods_number * shop_price) AS '总货款' FROM goods;
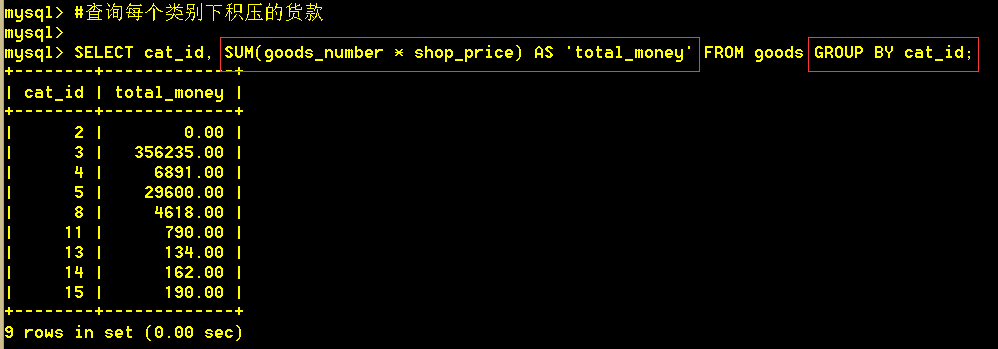
3.3 查询每个类别下积压的货款
:mysql> SELECT cat_id, SUM(goods_number * shop_price) AS 'total_money' FROM goods GROUP BY cat_id;
3.4 查询某个类别下积压的货款大于20000的
:mysql> SELECT cat_id, SUM(goods_number * shop_price) AS 'total_money' FROM goods GROUP BY cat_id HAVING total_money >= 20000;

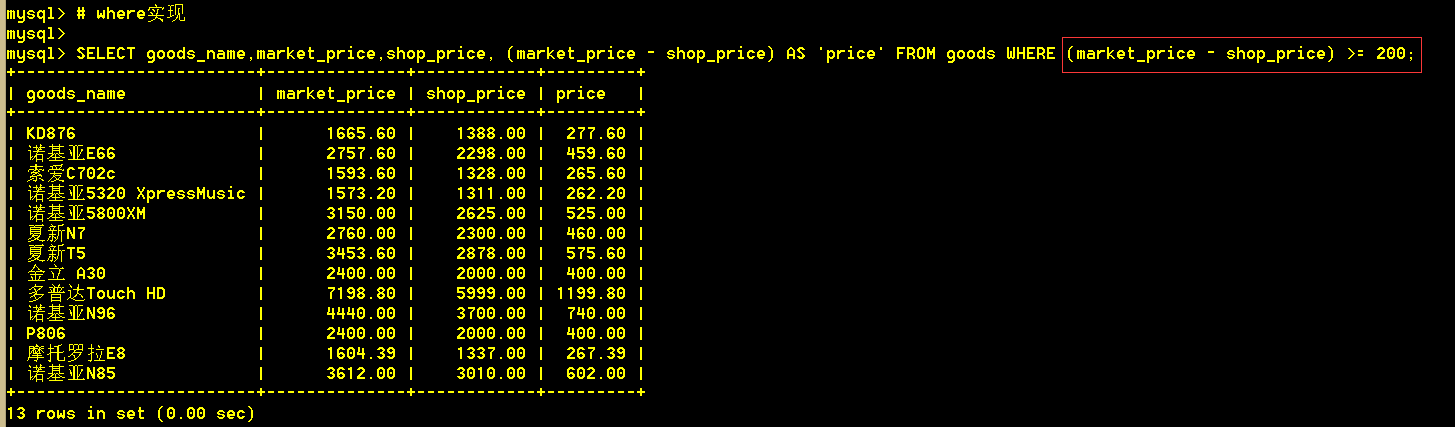
3.5 查询比市场价省200以上的商品,以及该商品所省的钱
:mysql> SELECT goods_name,market_price,shop_price, (market_price - shop_price) AS 'price' FROM goods WHERE (market_price - shop_price) >= 200;
where方式造成计算浪费,所以可以使用having进行结果集筛选。
:mysql> SELECT goods_name,market_price,shop_price, (market_price - shop_price) AS 'price' FROM goods HAVING price >= 200;
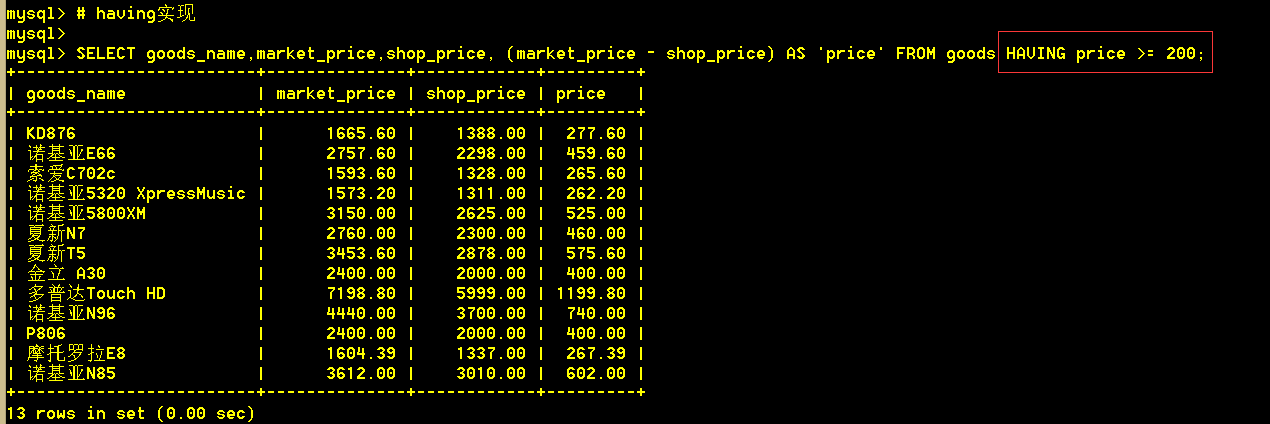
4.where + group by + having + 函数 综合查询
练习表:
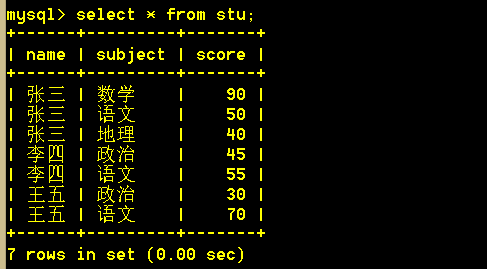
4.1 查询出两门及两门以上不及格者的平均成绩(注意是所有科目的平均成绩)
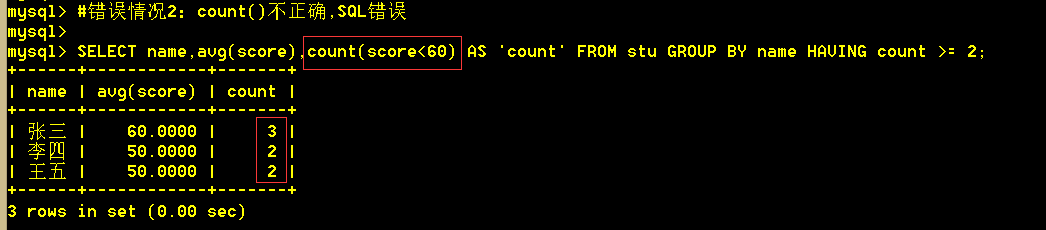
:mysql> SELECT name, avg(score) FROM stu WHERE score < 60 GROUP BY name having count(1) >= 2; 错误!

:mysql> SELECT name,avg(score),count(score<60) AS 'count' FROM stu GROUP BY name HAVING count >= 2;错误!
count(a),无论a是什么,都只是数一行;count时,每遇到一行,就数一个a,跟条件无关!
:mysql> SELECT name,avg(score), sum(score<60) as 'gk' FROM stu GROUP BY name having gk >= 2;
解析:count(score<60)达不到想要的结果,并不是条件的问题,而是无论count()里的表达式是什么都会数一行。
score<60 返回 1 或 0;所以可以用sum(score<60)来计算不及格的科目数!

sum()和count()在某种程度上可以互换。

5. order by + limit
5.1 取出第四类的商品,并按价格由高到低
:mysql> SELECT goods_name,cat_id,shop_price FROM goods WHERE cat_id = 4 ORDER BY shop_price DESC;
order by(排序) 是针对最终结果集,所以order by 要放在where/group by/having 后面。降序:desc; 升序:asc.

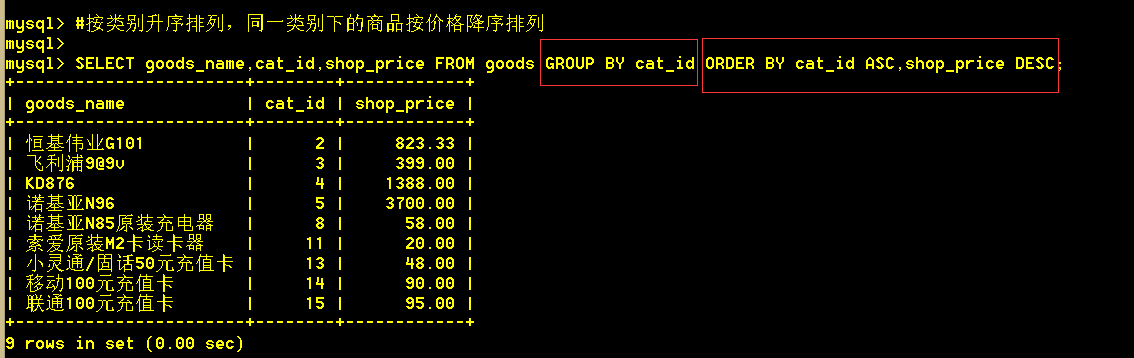
5.2 按类别升序排列,同一类别下的商品按价格降序排列
:mysql> SELECT goods_name,cat_id,shop_price FROM goods GROUP BY cat_id ORDER BY cat_id ASC,shop_price DESC;
若有多个列需要排序,首先按第一个排序,再按后面的列排序
5.3 按类别降序排列,同一类别下的商品按价格升序排列(使用别名)
:mysql> SELECT goods_name AS 'name', cat_id AS 'catId', shop_price AS 'price' FROM goods GROUP BY catId ORDER BY catId DESC, shop_price ASC;
order by 查询是针对结果集查询的。

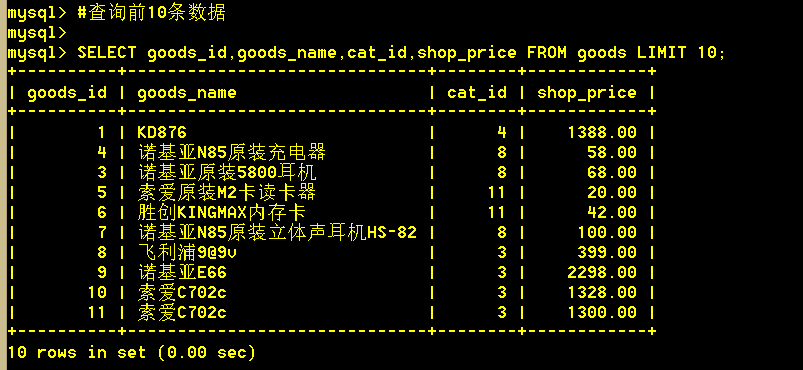
5.4 查询前10数据
:mysql> SELECT goods_id,goods_name,cat_id,shop_price FROM goods LIMIT 10;
limit放在最后,用于限制查出的记录数。
5.5 查询价格最高的前三件商品
:mysql> SELECT goods_name,cat_id,goods_number,shop_price FROM goods ORDER BY shop_price DESC LIMIT 3;

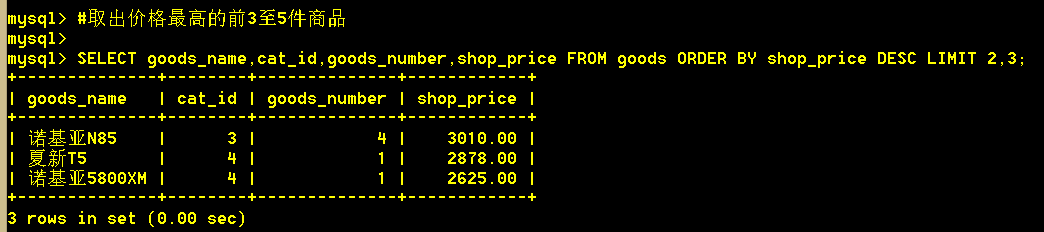
5.6 取出价格最高的前3至5件商品
:mysql> SELECT goods_name,cat_id,goods_number,shop_price FROM goods ORDER BY shop_price DESC LIMIT 2,3;
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
五种子句总结:
1.select a,b,c from table where x = 1; ==》》 where条件的 变量x 必须在表中存在;where是针对表做操作。
2.select a, b, c AS x having x = 1; ==》》 having 后的变量 x 可以是表中的列,也可以是别名,having是对查询结果集进行再筛选。这点区别于where,如果where使用别名,则会报"unknown column"错误;having是针对结果集做操作。
3.select count(*) 查询的是绝对的行数,就算某行全为NULL,也计算在内。
select count(列名) 查询的是该列不为NULL的所有行的行数。
count(*)和count(1)的区别:对于MyIsam引擎的表,是没有区别的,这种引擎内部有一计数器在维护着行数;如果是InnoDB的表,用count(*) 直接读行数,效率很低,因为会一行行数!
count(a<60),a<60返回值要么为1,要么为0,所以count()都会数一行,达不到根据条件数行数的目的;换一种思维,如果想计算a<60的行数,可以用sum(a < 60),满足a<60的返回 1,不满足返回 0。
sum()在某种程度上可以替换count()!
4.group by 有多少个类别,查出来就有多少行数据。
group by是针对where查询的结果集做操作!
使用group by a,b,c 时,则select查询的列,只能在a,b,c里选择,语义上才没有矛盾,才能一一对应起来。
group by a desc:这是一种错误的写法,group by 是没有排序功能的。
5.order by 是针对最终结果集进行排序的!所以放在where/group by/having 后面。降序:DESC; 升序:ASC。
若有多个列需要排序,首先按第一个排序,再按后面的列排序;多个列排序用","隔开。
6.limit [offset,] N :offset 偏移量,如果不写则为0(从0开始);N取出条目;
7.where是针对表做操作;having / group by / order by / limit 是针对结果集做操作,且先后顺序固定;where查询列只能是表字段,其余的查询列既可以是表字段,也可以是别名。
where / having / group by / order by / limit 简单查询的更多相关文章
- MySql学习(二) —— where / having / group by / order by / limit 简单查询
注:该MySql系列博客仅为个人学习笔记. 这篇博客主要记录sql的五种子句查询语法! 一个重要的概念:将字段当做变量看,无论是条件,还是函数,或者查出来的字段. select五种子句 where 条 ...
- sql 基础练习 计算7天各个时间点的总和 group by order mysql一次查询多个表
SQL 基础练习 -- 创建数据库 CREATE DATABASE school CHARACTER SET UTF8; -- 使用数据库 USE school; -- id: 学生的id -- na ...
- MySQL分组条件,group by order by limit 顺序
having 中如果没有用聚合函数(必须sum,min),涉及到的字段名称必须在select 中有对应字段名称才可以,用到聚合函数可以不必在select中有相应字段名称的 limit 2,3:2表示从 ...
- (5)MySQL的查询:模糊查询(通配符查询like)、限制符查询(limit)、排序查询(order by)、分组查询(group by)、(子查询)
注意事项 指令语法的优先级: where > group by >order by > limit 例:select count(id) as cnt,age from tablen ...
- MySQL之单表查询 一 单表查询的语法 二 关键字的执行优先级(重点) 三 简单查询 四 WHERE约束 五 分组查询:GROUP BY 六 HAVING过滤 七 查询排序:ORDER BY 八 限制查询的记录数:LIMIT 九 使用正则表达式查询
MySQL之单表查询 阅读目录 一 单表查询的语法 二 关键字的执行优先级(重点) 三 简单查询 四 WHERE约束 五 分组查询:GROUP BY 六 HAVING过滤 七 查询排序:ORDER B ...
- select的5中子句where,group by, havaing, order by, limit的使用顺序及实例
-- 语法: SELECT select_list FROM table_name [ WHERE search_condition ] [ GROUP BY group_by_expression ...
- MongoDB聚合运算之group和aggregate聚集框架简单聚合(10)
聚合运算之group 语法: db.collection.group( { key:{key1:1,key2:1}, cond:{}, reduce: function(curr,result) { ...
- 一次 group by + order by 性能优化分析
一次 group by + order by 性能优化分析 最近通过一个日志表做排行的时候发现特别卡,最后问题得到了解决,梳理一些索引和MySQL执行过程的经验,但是最后还是有5个谜题没解开,希望大家 ...
- SQL中的Where,Group By,Order By和Having
说到SQL语句,大家最开始想到的就是他的查询语句: select * from tableName: 这是最简单的一种查询方式,不带有任何的条件. 当然在我们的实际应用中,这条语句也是很常用到的,当然 ...
随机推荐
- Leetcode(870)-优势洗牌
给定两个大小相等的数组 A 和 B,A 相对于 B 的优势可以用满足 A[i] > B[i] 的索引 i 的数目来描述. 返回 A 的任意排列,使其相对于 B 的优势最大化. 示例 1: 输入: ...
- 线程同步之信号量(sem_init,sem_post,sem_wait)
信号量和互斥锁(mutex)的区别:互斥锁只允许一个线程进入临界区,而信号量允许多个线程同时进入临界区. 不多做解释,要使用信号量同步,需要包含头文件semaphore.h. 主要用到的函数: int ...
- 【原】无脑操作:Centos 7.6 + MariaDB + Rsyslog + LogAnalyzer环境搭建
背景: 网络安全法第三章第二十一条明确规定"采取监测.记录网络运行状态.网络安全事件的技术措施,并按照规定留存相关的网络日志不少于六个月". 为了满足合规性的要求,应当建设相应的日 ...
- Python对excel的基本操作
Python对excel的基本操作 目录 1. 前言 2. 实验环境 3. 基本操作 3.1 安装openpyxl第三方库 3.2 新建工作簿 3.2.1 新创建工作簿 3.2.2 缺省工作表 3.2 ...
- 阅文集团 招聘官网 bug
阅文集团 招聘官网 bug https://join.yuewen.com/ 前端开发 zxx.jpg 张鑫旭 https://qidian.gtimg.com/yuewen/join/css/ima ...
- C++ 0LL
C++ 0LL C plus plus L / l means long LL === long long int countDigitOne(int n) { int countr = 0; for ...
- GreenSock & SVG Animation
GreenSock & SVG Animation refs https://greensock.com/ https://greensock.com/learning/ GSAP https ...
- 钉钉 & URL Scheme & Universal Link & Deep Link
钉钉 & URL Scheme & Universal Link & Deep Link DD link https://www.cnblogs.com/xgqfrms/p/1 ...
- qt char与code的相互转换
QString str = "A"; QChar c = str.at(0); // int v_latin = c.toLatin1(); // 不能转中文 int v_lati ...
- Flutter 使用p5
p5 工作示例 install dependencies: p5: ^0.0.5 main.dart import 'package:flutter/material.dart'; import &q ...