爬虫入门二 beautifulsoup
title: 爬虫入门二 beautifulsoup
date: 2020-03-12 14:43:00
categories: python
tags: crawler
使用beautifulsoup解析数据
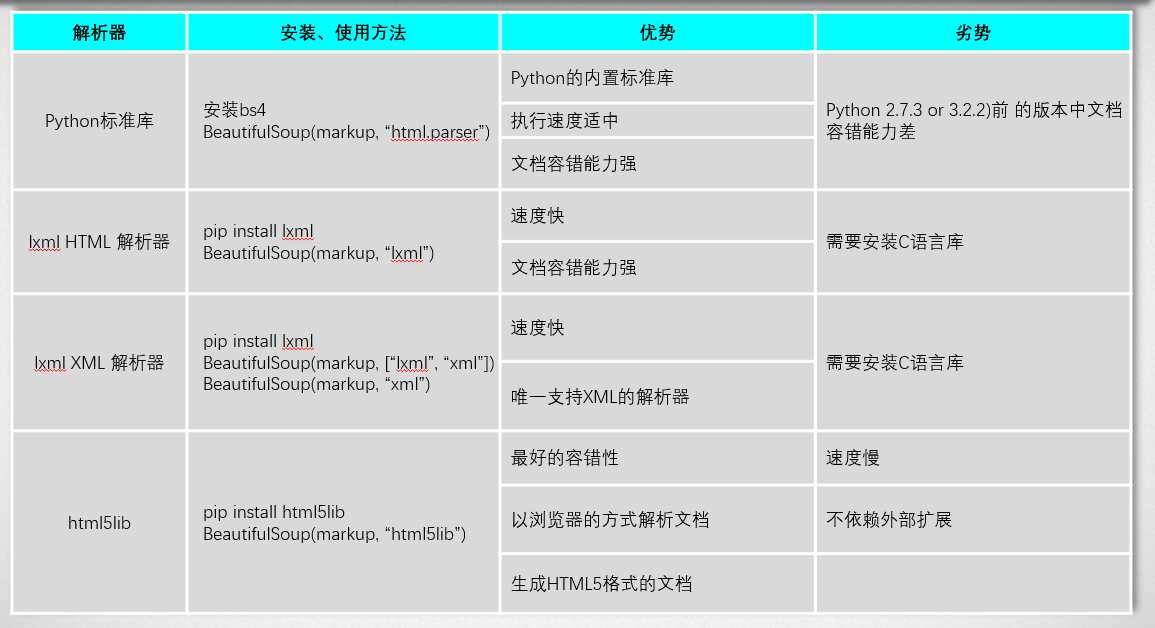
1 beautifulsoup简介
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过转换器实现文档导航、查找、修改。
pip install beautifulsoup4
http://beautifulsoup.readthedocs.io/zh_CN/latest/
2 前端知识
HTTP:HyperText Markup Language 超文本标记语言
CSS:Cascading Style Sheets 层叠样式表
JAVASCRIPT:一种脚本语言,其源代码在发往客户端运行之前不需经过编译,而是将文本格式的字符代码发送给浏览器由浏览器解释运行
XML:Extensible Markup Language可扩展标记语言
XML是被设计用来描述数据的,HTML是被设计用来显示数据的。与HTML相比,XML支持动态更新,标准性更强
3 beautifulsoup解析器
比如BeautifulSoup(demo, 'html.parser') 中的html.parser
4 html结构
<></>构成所属关系。树形结构。下行,上行,平行遍历。

5 使用beautifulsoup解析HTML
注意B和S大写,Python对大小写敏感
from bs4 import BeautifulSoup
import requests
def html():
# 得到未解析的HTML网页内容
r = requests.get("https://whu.edu.cn/coremail/common/index_cm40.jsp")
print(r.text)
# 得到解析的HTML网页内容
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
print(soup.prettify())
6 BeautifulSoup 类的基本元素与操作
Tag,标签<></>开始结束
name,标签名,
的name是p。.name
attributes,标签属性(字典形式组织)。.attr
navigablestring,标签内非属性字符串..string
comment,标签内字符串的注释部分
下面是例子:
可以看到,web中有很多a标签,,而这里只返回了第一个
from bs4 import BeautifulSoup
import requests
def html():
# 得到未解析的HTML网页内容
r = requests.get("https://whu.edu.cn/coremail/common/index_cm40.jsp")
print(r.text)
# 得到解析的HTML网页内容
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
#print(soup.prettify())
print(soup.title)
print(soup.a)
#<title>武汉大学邮件系统</title>
#<a class="MTLinks">设为首页</a>
HTML中a锚文本A超链接标签格式: 被链接内容
6.1 BeautifulSoup标签操作
#查看标签a的属性
tag=soup.a
tag.attrs
#查看标签a的属性中class的值
tag.attrs['class']
#查看标签a的属性 的类型
type(tag.attrs)
#查看标签a的非属性字符串
soup.a.string
#查看标签a的非属性字符串属性 的类型
type(tag.a.string)
#返回值为bs4.element.NavigableString (可以遍历的字符串)
from bs4 import BeautifulSoup
import requests
def html():
# 得到未解析的HTML网页内容
r = requests.get("https://whu.edu.cn/coremail/common/index_cm40.jsp")
print(r.text)
# 得到解析的HTML网页内容
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
#print(soup.prettify())
print(soup.title)
print(soup.a)
# 查看标签a的属性
tag = soup.a
print(tag.attrs)
# 查看标签a的属性中class的值
tag.attrs['class']
# 查看标签a的属性 的类型
print(type(tag.attrs))
# 查看标签a的非属性字符串
print(tag.string)
# 查看标签a的非属性字符串属性 的类型
print(type(tag.string))
# 返回值为bs4.element.NavigableString (可以遍历的字符串)
7 html遍历
上行,下行,平行。
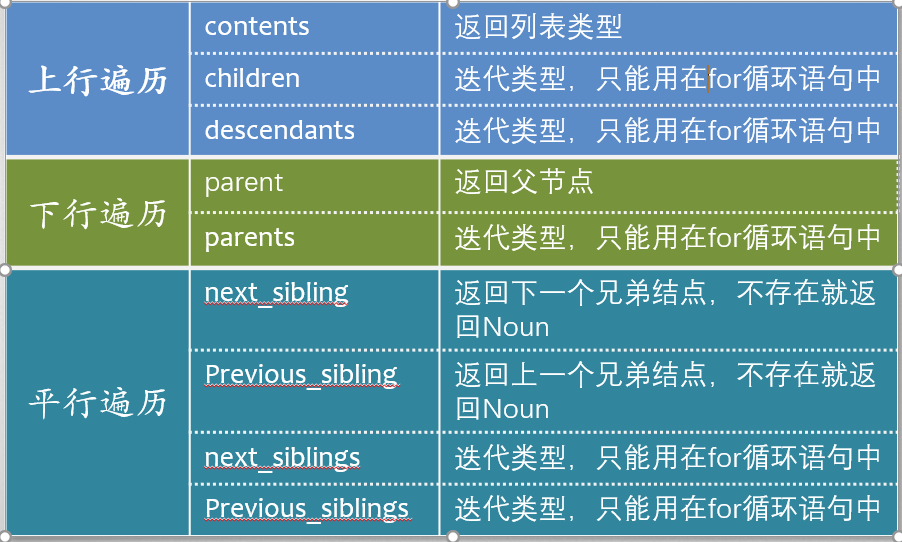
7.1 标签树下行遍历 .content .children .descendants
7.1.1 .content
.contents 子节点的列表,将所有儿子节点存入列表
soup.body.contents
#获得孩子节点的个数
len(soup.body.contents)
#分别输出各个子节点
soup.body.contents[0]
soup.body.contents[2]
#标号 由0开始
7.1.2 .children/.descendants
.contents 和 .children 属性仅包含tag的直接子节点,.descendants 属性可以对所有tag的子孙节点进行递归循环
需要遍历获取其中的内容。
for child in soup.body.children:
print(child)
for child in soup.body.descendants:
print(child)
def htmlergodic():
# 得到未解析的HTML网页内容
r = requests.get("https://whu.edu.cn/coremail/common/index_cm40.jsp")
#print(r.text)
# 得到解析的HTML网页内容
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
# 子节点的列表,将<tag>所有儿子节点存入列表
#print(soup.body.contents)
# 获得孩子节点的个数
print(len(soup.body.contents))
# 分别输出各个子节点
print(soup.body.contents[0])
print(soup.body.contents[2])
# 标号 由0开始
for child in soup.body.children:
print(child)
for child in soup.body.descendants:
print(child)
7.2 标签树上行遍历 .parent/.parents
# a的父节点
soup.a.parent.name
# 遍历
for parent in soup.a.parents: #注意 s
print(parent.name)
7.3 标签树平行遍历 next_sibling/Previous_sibling
#获得a节点的上一个节点和下一个节点
soup.a.next_sibling
soup.a.previous_sibling
for sibling in soup.a.next_siblings: #注意s
print(sibling)
8 bs4的库的prettify()方法
BeautifulSoup 是bs4库的类,prettify()是方法。
.prettify()为HTML文本<>及其内容增加换行符
可以用于整个HTML文本,也可以用于单个标签
方法:
.prettify()
bs4库将任何HTML输入都变成utf‐8编码Python 3.x默认支持编码是utf‐8,解析无障碍
print(soup.body.prettify())
9 BeautifulSoup信息检索 注意find标签名要加''表示字符串
9.1 .find_all() 搜索并返回全部结果
<>.find_all(name,attrs,recursive,string,**kwargs)
def jiansuo():
r = requests.get("http://www.baidu.com/")
r.encoding = r.apparent_encoding
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
print(soup.find_all('a'))
9.2 参数
name: 对标签名称的检索字符串
attrs: 对标签属性值的检索字符串,可标注属性检索
recursive: 是否对子孙全部检索,默认True
string: <>…</>中字符串区域的检索字符串
#搜索 class=“mnav” 的全部a标签
print(soup.find_all('a','mnav'))
# 搜索字符串为新闻的全部标签
print(soup.find_all(string='新闻'))
如果要部分匹配,则需要导入正则表达式库
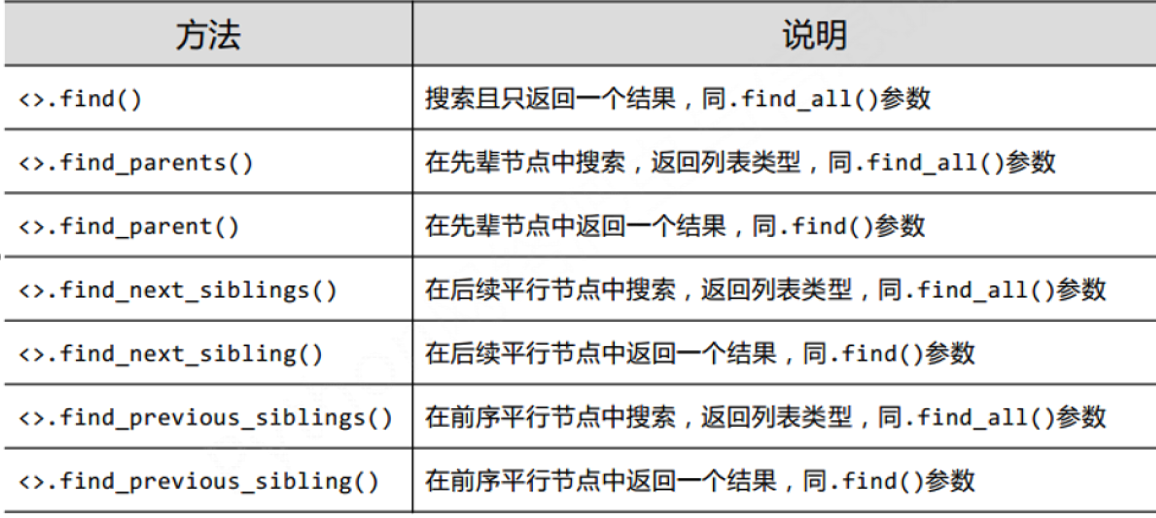
9.3 扩展方法
<>.find()
<>.find_parents()
<>.find_parent()
<>.find_next_sibling()
<>.find_next_siblings()
<>.find_previous_sibling()
<>.find_previous_siblings()
10 实例
10.1 爬取武汉大学官方网站,含'樱'的新闻链接标题
导入requests库、BeautifulSoup类、re库
使用for循环,查找条件string=re.compile('樱'))
搜索类型为新闻链接,因此类型为‘a’
输出满足条件的tag的字符串
import re
import requests
from bs4 import BeautifulSoup
def sakura():
r = requests.get("http://www.whu.edu.cn/")
r.encoding = r.apparent_encoding
demo = r.text
soup = BeautifulSoup(demo,'html.parser')
for tag in soup.find_all('a', string=re.compile('樱')):
print(tag.string)
10.2 爬取 百度互联网热门人物排行
访问百度搜索风云榜
人物--互联网人物
http://top.baidu.com/buzz?b=257&c=9&fr=topcategory_c9
右键点击 “马云”--检查,查看对应的HTML代码
<a class="list-title" target="_blank" href="http://www.baidu.com/baidu?cl=3&tn=SE_baiduhomet8_jmjb7mjw&rsv_dl=fyb_top&fr=top1000&wd=%C2%ED%D4%C6" href_top="./detail?b=257&c=9&w=%C2%ED%D4%C6">马云</a>
分析可知人物连接标签名为a,class为list-title
使用soup.find_all(‘a’, ‘list-title’ ) 输出class为list-title
的a标签的字符串,即可书序得到排行榜的人物名单。
同时在前面加上他们索引序号index(tag.string)+1
即可得到今日互联网人物排行榜
def fyrw():
r=requests.get("http://top.baidu.com/buzz?b=257&fr=topboards")
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo, 'html.parser')
ulist = []
for tag in soup.find_all('a', 'list-title' ):
ulist.append(tag.string)
print(ulist.index(tag.string)+1,ulist[ulist.index(tag.string)])
10.3 爬取 中国大学排行榜2016
从网络上获取大学排名网页内容
getHTMLText()
提取网页内容中信息到合适的数据结构
fillUnivList()
利用数据结构展示并输出结果
printUnivList()
http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
检查网页代码看到结构是
<tbody>
<tr>
<td> 排位
<td> 大学名...
<tr>
...
这样就遍历标签的每个标签,提取前三个标签的string保存即可
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children: #提取tbody的每个tr标签
if isinstance(tr,bs4.element.Tag): #判断tr是否是tag类型
tds = tr('td') #tds[0] <td>1</td>.简写,等价于下一行代码
#tds = tr.find_all('td')
# ,然后用.string取string
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名", "学校名称", "总分"))
for i in range(num):
u = ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0], u[1], u[2]))
def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
上面的问题是并没有对齐。
原因是当中文字符宽度不够时,采用西文字符填充;中西文字符占用宽度不同。
解决是采用中文字符的空格填充chr(12288)
def printUnivList(ulist, num):
tplt = "{0:^4}\t{1:{3}^12}\t{2:^10}"
print(tplt.format("排名", "学校名称", "总分", chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], chr(12288)))
tplt为定义的输出格式模板变量,^代表居中,4/12/10代表输出宽度(当输出数据超过该数字时,以实际输出为准),
{3}代表打印输出时,我们使用format中的第3个变量(由0起始),也就是 chr(12288)
chr(12288)代表全角Unicode空格(即中文空格)
# :是引导符号
# : <填充><对齐><宽度>,<精度><类型> 这里的 ','是千位分隔符
# 拿上面的代码举例
#tply:0,1,2对应输出的第0,1,2个数据。^表示居中,然后第0个数据宽4.中间{3}表示填充用format第3个变量也就是chr(12288)
10.4 最好大学2017.遇坑
同样的代码爬
http://www.zuihaodaxue.cn/zuihaodaxuepaiming2017.html
报错
TypeError: unsupported format string passed to NoneType.format
#2016
<tr class="alt"><td>1</td>
<td><div align="left">清华大学</div></td>
#2017
<tr class="alt"><td>1<td><div align="left">清华大学</div></
注意这里有坑,chrome检查,在console看到是没区别的(2017也是1)
检查页面源代码发现和2016比不同之处在于子节点“1”所对应的地方并非是一个完整的子节点,“1”并没有被一对完整的标签所包围,所以tds[0]实际上是被第一个标签所包围的所有内容,而这相当于把后续所有内容全给装进去了。
由于字符1仍是第一的标签下的第一个子节点,通过bs4库的contents方法来获得这个排名,由于是第一个子节点,tds[0].contents[0]就排名。
重新修改的代码如下
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children: #提取tbody的每个tr标签
if isinstance(tr,bs4.element.Tag): #判断tr是否是tag类型
tds = tr('td') #tds[0] <td>1</td>.简写,等价于下一行代码
#tds = tr.find_all('td')
# ,然后用.string取string
ulist.append([tds[0].contents[0].string, tds[1].string, tds[3].string])
10.5 2016世界大学排名,遇坑
http://www.zuihaodaxue.cn/ARWU2016.html
先用了2016中国排名的方法,然后报错,然后看源码,没看出来不同。
就把爬的内容打印一下
发现大学名字打印的是none
然后对比2016中国和2016大学.
<td class="align-left">
<a href="World-University-Rankings/Harvard-University.html" target="_blank">哈佛大学</a>
</td>
<td><div align="left">清华大学</div></td>
不明白就去查,
https://blog.csdn.net/github_36669230/article/details/66973617
用 .string 属性来提取标签里的内容时,该标签应该是只有单个节点的。比如上面的 1 标签那样。也就是说世界大学的标签影响了
那就直接提取.string就行了
0.北理工课程https://www.bilibili.com/video/av9784617?from=search&seid=12715531491861423376
1.廖雪峰官方网站
http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
2.Python 知识库
http://lib.csdn.net/python/node/68
- Python网络爬虫与信息提取(MOOC)
http://www.icourse163.org/course/BIT-1001870001#/info
4.W3School 网页前端学习及在线编辑
http://www.w3school.com.cn/h.asp
5.BeautifulSoup 官方文档
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
爬虫入门二 beautifulsoup的更多相关文章
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- 转 Python爬虫入门二之爬虫基础了解
静觅 » Python爬虫入门二之爬虫基础了解 2.浏览网页的过程 在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以 ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- 【爬虫入门手记03】爬虫解析利器beautifulSoup模块的基本应用
[爬虫入门手记03]爬虫解析利器beautifulSoup模块的基本应用 1.引言 网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率.Bea ...
- 【网络爬虫入门04】彻底掌握BeautifulSoup的CSS选择器
[网络爬虫入门04]彻底掌握BeautifulSoup的CSS选择器 广东职业技术学院 欧浩源 2017-10-21 1.引言 目前,除了官方文档之外,市面上及网络详细介绍BeautifulSoup ...
随机推荐
- kubectl命令管理
kubectl命令管理 查看更多帮助命令 [root@k8s-master ~]# kubectl --help 创建一个命名空间 [root@k8s-master ~]# kubectl creat ...
- HTML&CSS:构建网站不能不说的那些事儿
很高兴你能看到这个专栏!俗话说得好,相逢即是缘分,没准你和我在上一世也曾有过五百次的回眸,才得此一面.说的有点恶心了,咱还是书归正传,说说这个专栏吧. 这个专栏主要讲的是 HTML 和 CSS 的页面 ...
- [java]文件上传下载删除与图片预览
图片预览 @GetMapping("/image") @ResponseBody public Result image(@RequestParam("imageName ...
- AQS之ReentrantReadWriteLock写锁
用法 1.1 定义一个安全的list集合 public class LockDemo { ArrayList<Integer> arrayList = new ArrayList<& ...
- 编年史:OI算法总结
目录(按字典序) A --A* D --DFS找环 J --基环树 S --数位动规 --树形动规 T --Tarjan(e-DCC) --Tarjan(LCA) --Tarjan(SCC) --Ta ...
- 入门OJ:郭嘉的消息传递
题目描述 我们的郭嘉大大在曹操这过得逍遥自在,但是有一天曹操给了他一个任务,在建邺城内有N(<=1000)个袁绍的奸细 将他们从1到N进行编号,同时他们之间存在一种传递关系,即若C[i,j]=1 ...
- 5V 升压 8.4V,5V 转 8.4V 做两节锂电池充电芯片
5V 升压 8.4V SOT23-6 封装的六脚升压 IC PW5300 是一颗 DC-DC 异步整流升压转换器芯片,输入电压范围 2.6V-5.5V.最高输出 电压 12V, PW5300 是一种电 ...
- 输入5V,输出5V限流芯片,4A限流,短路保护
USB限流芯片,5V输入,输出5V电压,限流值可以通过外围电阻进行调节,PWCHIP产品中可在限流范围0.4A-4.8A,并具有过压关闭保护功能. 过压关闭保护: 如芯片:PW1555,USB我们一半 ...
- Java面试官经验谈:如何甄别候选人真实的能力,候选人如何展示值钱技能
我做Java方面的面试官也有些年头了,从校招学生到初级开发到架构师我都面试过.从技术上来讲,候选人通过面试的标准可能千差万别,但归结成一句话,就是候选人达到了职位介绍的要求,且相关项目经验达到足量的年 ...
- 显示HDFS中指定的文件读写权限、大小、创建时间、路径等信息。
1 import org.apache.hadoop.fs.*; 2 import java.text.SimpleDateFormat; 3 public class D_ReadFileStatu ...