sop服务治理
一,为什么需要服务治理:
我们最先接触的单体架构, 整个系统就只有一个工程, 打包往往是打成了 war 包, 然后部署
到单一 tomcat 上面, 这种就是单体架构, 如图:

假如系统按照功能划分了, 商品模块, 购物车模块, 订单模块, 物流模块等等模块。 那么所
有模块都会在一个工程里面, 这就是单体架构。
单体架构优点
1、 结构简单, 部署简单
2、 所需的硬件资源少
3、 节省成本
缺点
1、 版本迭代慢, 往往改动一个代码会影响全局
2、 不能满足一定并发的访问
3、 代码维护困难, 所有代码在一个工程里面, 存在被其他人修改的风险
随着业务的拓展, 公司的发展, 单体架构慢慢的不能满足我们的需求, 我们需要对架构进行
变动, 我们能够想到的最简单的办法就是加机器, 对应用横向扩展。
如图:
这种架构貌似暂时解决了我们的问题, 但是用户量慢慢增加后, 我们只能通过横向加机器来
解决, 还是会存在版本迭代慢, 代码维护困难的问题。 而且用户请求往往是读多写少的情况,
所以可能真正需要扩容的只是商品模块而已, 而现在是整个工程都扩容了, 这无形中是一种
资源的浪费, 因为其他模块可能根本不需要扩容就可以满足需求。 所以我们有必要对整个工
程按照模块进行拆分, 拆分后的架构图如下:
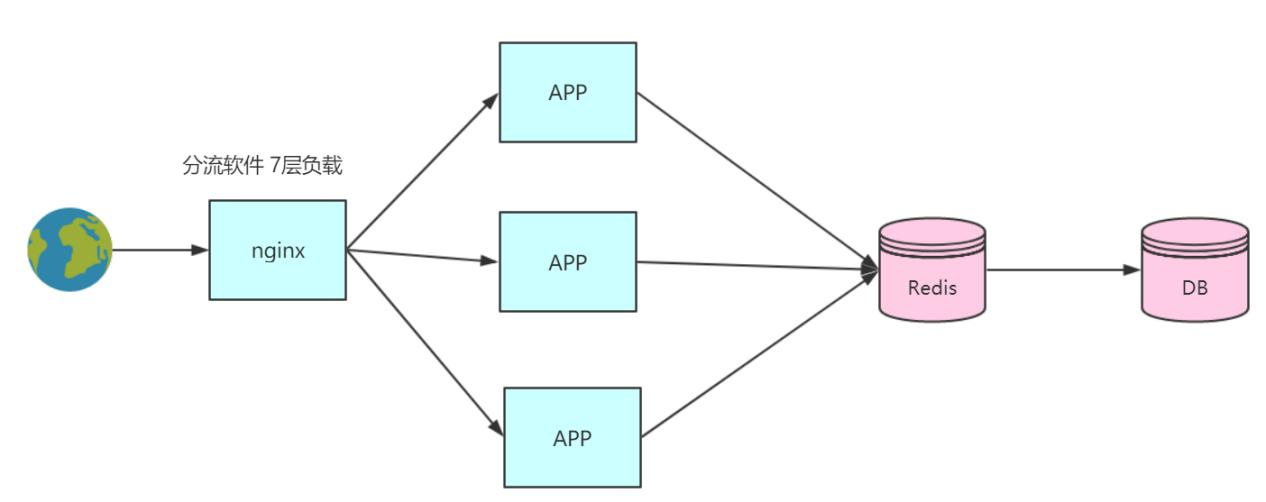
模块拆分后, 模块和模块之间是需要通过接口调用的方式进行通信, 模块和模块之间通过分
流软件进行负载均衡。 这个架构解决前面的资源浪费问题和代码管理问题, 因为我们是对系
统拆分了, 各个模块都有单独的工程, 比如我修改商品模块, 就不需要担心会不会影响购物
车模块。 但是这种架构扩展非常麻烦, 一旦需要横向加机器, 或者减机器都需要修改 nginx
配置, 一旦机器变多了以后, nginx 的配置量就是一个不能完成的工作。 OK, 这时候 SOA 服
务治理框架就应运而生, 架构图如下:
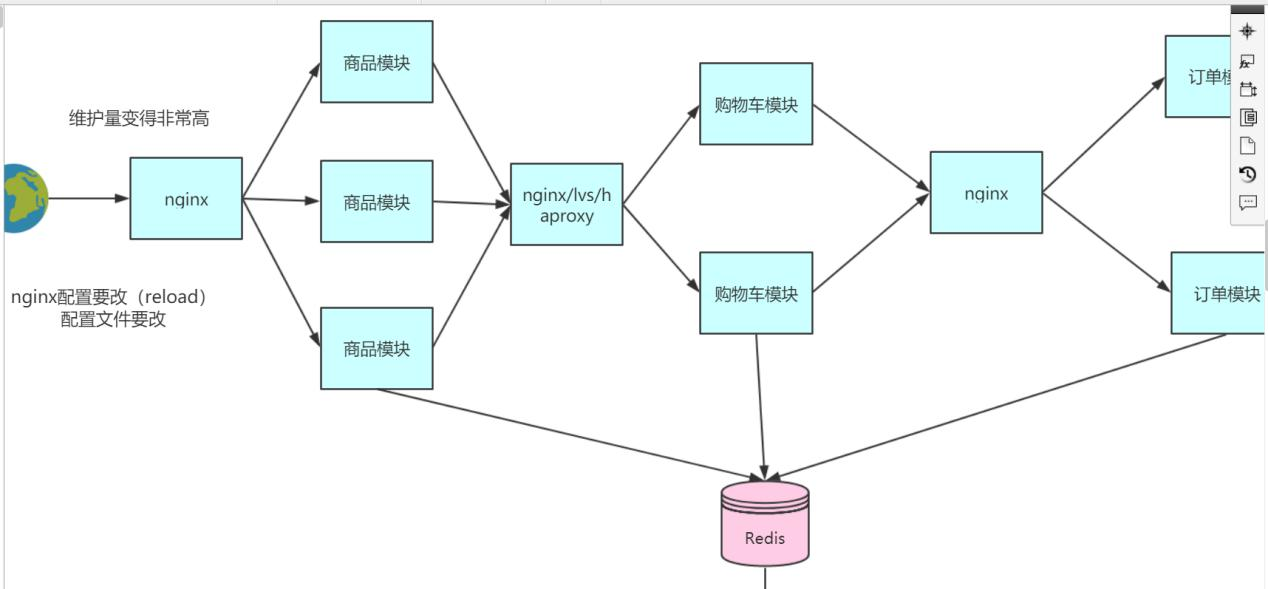
基于注册中心的 SOA 框架, 扩展是非常方便的, 因为不需要维护分流工具, 但我们启动应
用的时候就会把服务通过 http 的方式注册到注册中心。
在 SOA 框架中一般会有三种角色: 1、 注册中心 2、 服务提供方 3、 服务消费方
1、 注册中心
在注册中心维护了服务列表
2、 服务提供方
服务提供方启动的时候会把自己注册到注册中心
3、 服务消费方
服务消费方启动的时候, 把获取注册中心的服务列表, 然后调用的时候从这个服务列表中选
择某一个去调用。
微服务工程的特点:
1、 扩展灵活
2、 每个应用都规模不大
3、 服务边界清晰, 各司其职
4、 打包应用变多, 往往需要借助 CI 持续集成工具
二,Eureka 用户认证
服务续约保活
当客户端启动想 eureka 注册了本身服务列表后, 需要隔段时间发送一次心跳给 eureka 服务
端来证明自己还活着, 当 eureka 收到这个心跳请求后才会知道客户端还活着, 才会维护该
客户端的服务列表信息。 一旦因为某些原因导致客户端没有按时发送心跳给 eureka 服务端,
这时候 eureka 可能会认为你这个客户端已经挂了, 它就有可能把该服务从服务列表中删除
掉。
Eureka 健康检测
Eureka 默认的健康检测只是你校验服务连接是否是 UP 还是 DOWN 的, 然后客户端只会调用
状态为 UP 状态的服务, 但是有的情况下, 虽然服务连接是好的, 但是有可能这个服务的某
些接口不是正常的, 可能由于需要连接 Redis, mongodb 或者 DB 有问题导致接口调用失败,
所以理论上服务虽然能够正常调用, 但是它不是一个健康的服务。 所以我们就有必要对这种
情况做自定义健康检测。
服务下线
比如有些情况是服务主机意外宕机了, 也就意味着服务没办法给 eureka 心跳信息了, 但是
eureka 在没有接受到心跳的情况下依赖维护该服务 90s, 在这 90s 之内可能会有客户端调用
到该服务, 这就可能会导致调用失败。 所以我们必须要有一个机制能手动的立马把宕机的服
务从 eureka 服务列表中清除掉, 避免被服务调用方调用到。
三 服务隔离,降级,熔断
服务雪崩
雪崩是系统中的蝴蝶效应导致其发生的原因多种多样, 有不合理的容量设计, 或者是高并发
下某一个方法响应变慢, 亦或是某台机器的资源耗尽。 从源头上我们无法完全杜绝雪崩源头
的发生, 但是雪崩的根本原因来源于服务之间的强依赖, 所以我们可以提前评估。 当整个微
服务系统中, 有一个节点出现异常情况, 就有可能在高并发的情况下出现雪崩, 导致调用它
的上游系统出现响应延迟, 响应延迟就会导致 tomcat 连接本耗尽, 导致该服务节点不能正
常的接收到正常的情况, 这就是服务雪崩行为。
服务隔离
如果整个系统雪崩是由于一个接口导致的, 由于这一个接口响应不及时导致问题, 那么我们
就有必要对这个接口进行隔离, 就是只允许这个接口最多能接受多少的并发, 做了这样的限
制后, 该接口的主机就会空余线程出来接收其他的情况, 不会被哪个坏了的接口占用满。
Hystrix 就是一个不错的服务隔离框架
Hystrix 服务隔离策略
1、 线程池隔离
THREAD 线程池隔离策略 独立线程接收请求 默认的
默认采用的就是线程池隔离
2、 信号量隔离
信号量隔离是采用一个全局变量来控制并发量, 一个请求过来全局变量加 1, 单加到跟配置
中的大小相等是就不再接受用户请求了。
Hystrix 服务降级
服务降级是对服务调用过程的出现的异常的友好封装, 当出现异常时, 我们不希
望直接把异常原样返回, 所以当出现异常时我们需要对异常信息进行包装, 抛一
个友好的信息给前端。
定义降级方法, 降级方法的返回值和业务方法的方法值要一样
Hystrix 数据监控
Hystrix 进行服务熔断时会对调用结果进行统计, 比如超时数、 bad 请求数、 降
级数、 异常数等等都会有统计, 那么统计的数据就需要有一个界面来展示,
hystrix-dashboard 就是这么一个展示 hystrix 统计结果的服务。
Hystrix 熔断
熔断就像家里的保险丝一样, 家里的保险丝一旦断了, 家里就没点了, 家里用电
器功率高了就会导致保险丝端掉。 在我们 springcloud 领域也可以这样理解, 如
果并发高了就可能触发 hystrix 的熔断。
熔断发生的三个必要条件:
1、 有一个统计的时间周期, 滚动窗口
相应的配置属性
metrics.rollingStats.timeInMilliseconds
默认 10000 毫秒
2、 请求次数必须达到一定数量
相应的配置属性
circuitBreaker.requestVolumeThreshold
默认 20 次
3、 失败率达到默认失败率
相应的配置属性
circuitBreaker.errorThresholdPercentage
默认 50%
上述 3 个条件缺一不可, 必须全部满足才能开启 hystrix 的熔断功能。
熔断器的三个状态:
1、 关闭状态
关闭状态时用户请求是可以到达服务提供方的
2、 开启状态
开启状态时用户请求是不能到达服务提供方的, 直接会走降级方法
3、 半开状态
当 hystrix 熔断器开启时, 过一段时间后, 熔断器就会由开启状态变成半开状态。
半开状态的熔断器是可以接受用户请求并把请求传递给服务提供方的, 这时候如果远程调用
返回成功, 那么熔断器就会有半开状态变成关闭状态, 反之, 如果调用失败, 熔断器就会有
半开状态变成开启状态。
Hystrix 功能建议在并发比较高的方法上使用, 并不是所有方法都得使用的。
分布式配置中心
分布式配置中心解决了什么问题
1、 抽取出各模块公共的部分, 做到一处修改各处生效的目标
2、 做到系统的高可用, 修改了配置文件后可用在个模块动态刷新, 不需要重启服务器
3、 分布式配置中心配置规则
分布式配置中心服务端是需要远程连接代码仓库的, 比如 GitHub, gitlab 等, 把需要管理的
配置文件放到代码仓库中管理, 所以服务端就需要有连接代码仓库的配置:
spring.cloud.config.server.git.uri=https://github.com/zgjack/zg-config-repo
spring.cloud.config.server.git.search-paths=config-repo
spring.cloud.config.server.git.username=zg-jack
spring.cloud.config.server.git.password=zg0001jack
4、 客户端使用配置中心
客户端只需要指定连接的服务端就行了, 从服务端拉取配置信息
6、 配置动态加载刷新
这个是一个革命性的功能, 在运行期修改配置文件后, 我们通过这个动态刷新功能可以不重
启服务器, 这样我们系统理论上可以保证 7*24 小时的工作
1、 Environment 的动态刷新
动态刷新其实要有一个契机, 其实这个契机就是手动调用刷新接口, 如果你想刷新哪台主机
的配置, 就调用哪台注解的刷新接口
刷新接口为: http://localhost:8088/actuator/refresh
2、 @Value 注入的属性动态刷新
其实前面在调用刷新接口后, @Value 注入的属性是没有刷新的还是老的配置, 这个也好理
解, @Value 注入的属性是项目启动就已经定了的。 如果要使@Value 属性也刷新, 就必须要
在类上面加上: @RefreshScope 注解。
但是调用每台主机的刷新接口显然太麻烦了, 如果需要刷新的集群机器有几百台, 是不是就
需要手动调用几百次呢, 这几乎是一个不能完成的工作量。
Springcloud 中也提供了消息总线的东西, 借助 mq 来完成消息的广播, 当需要刷新时我们就
只要调用一次刷新接口即可。
消息总线
消息总线其实很简单, 就是为了解决一点刷新的功能, 在一个点调用请求刷新接口, 然后所
有的在消息总线中的端点都能接到刷新的消息, 所有我们必须把每一个端点都拉入到消息总
线中来。
消息总线
消息总线其实很简单, 就是为了解决一点刷新的功能, 在一个点调用请求刷新接口, 然后所
有的在消息总线中的端点都能接到刷新的消息, 所有我们必须把每一个端点都拉入到消息总
线中来。
Zuul 服务网关
Zuul 是分布式 springcloud 项目的流量入口, 理论上所有进入到微服务系统的请求都要经过
zuul 来过滤和路由。
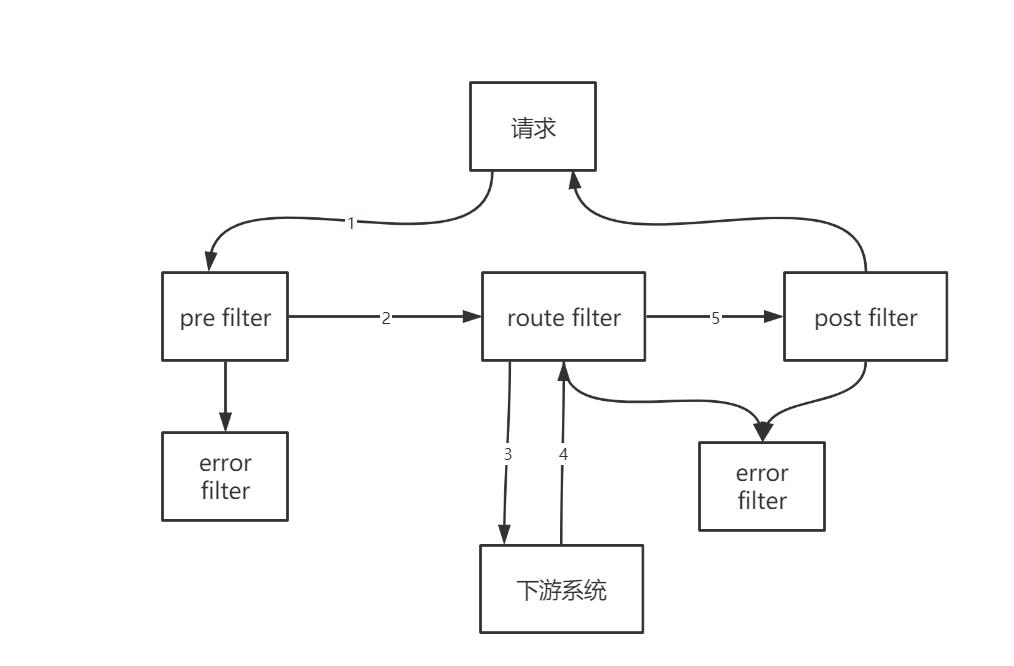
zuul 过滤器
Zuul 大部分功能都是通过过滤器来实现的, Zuul 定义了 4 种标准的过滤器类型, 这些过滤器
类型对应于请求的典型生命周期。
a、 pre: 这种过滤器在请求被路由之前调用。 可利用这种过滤器实现身份验证、 在集群中选
择请求的微服务, 记录调试信息等。
b、 routing: 这种过滤器将请求路由到微服务。 这种过滤器用于构建发送给微服务的请求, 并
使用 apache httpclient 或 netflix ribbon 请求微服务。
c、 post: 这种过滤器在路由到微服务以后执行。 这种过滤器可用来为响应添加标准的 http
header、 收集统计信息和指标、 将响应从微服务发送给客户端等。
e、 error: 在其他阶段发送错误时执行该过滤器。
微服务系统的权限校验
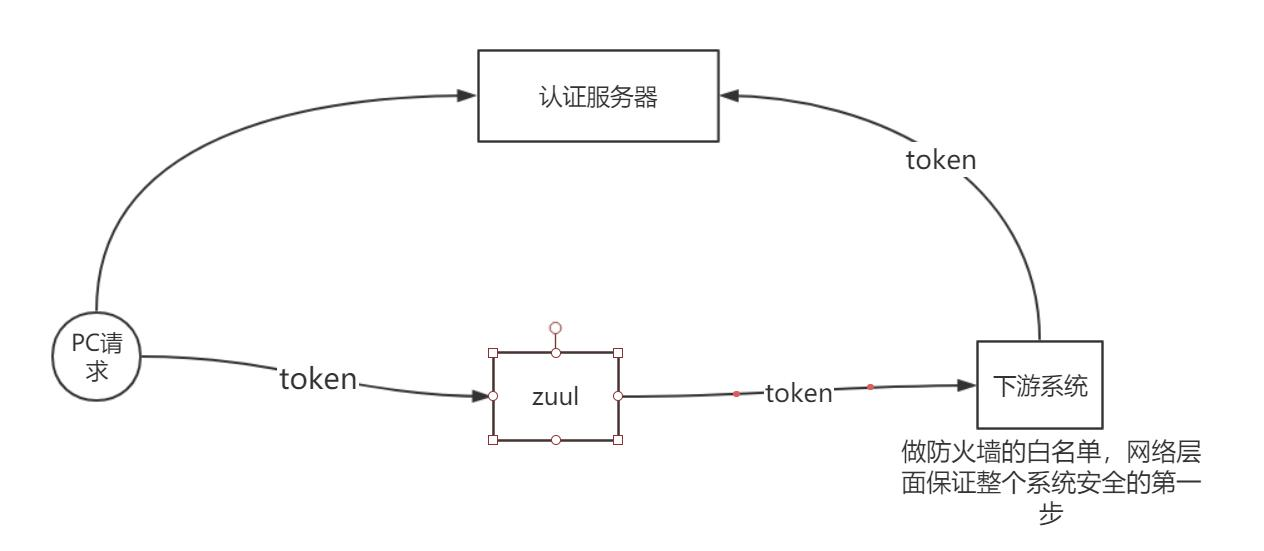
采用 token 认证的方式校验是否有接口调用权限, 然后在下游系统设置访问白名单只允许
zuul 服务器访问。 理论上 zuul 服务器是不需要进行权限校验的, 因为 zuul 服务器没有接口,
不需要从 zuul 调用业务接口, zuul 只做简单的路由工作。 下游系统在获取到 token 后, 通过
过滤器把 token 发到认证服务器校验该 token 是否有效, 如果认证服务器校验通过就会携带
这个 token 相关的验证信息传回给下游系统, 下游系统根据这个返回结果就知道该 token 具
有的权限是什么了。 所以校验 token 的过程, 涉及到下游系统和认证服务器的交互, 这点不
好。 占用了宝贵的请求时间。
获取 token 的过程
Token 是通过一个单独的认证服务器来颁发的, 只有具备了某种资质认证服务器才会把 token
给申请者。
2、 获取 token
获取 token 在 oauth2.0 里面有 4 中模式, 这里我们讲三种
1、 客户端模式
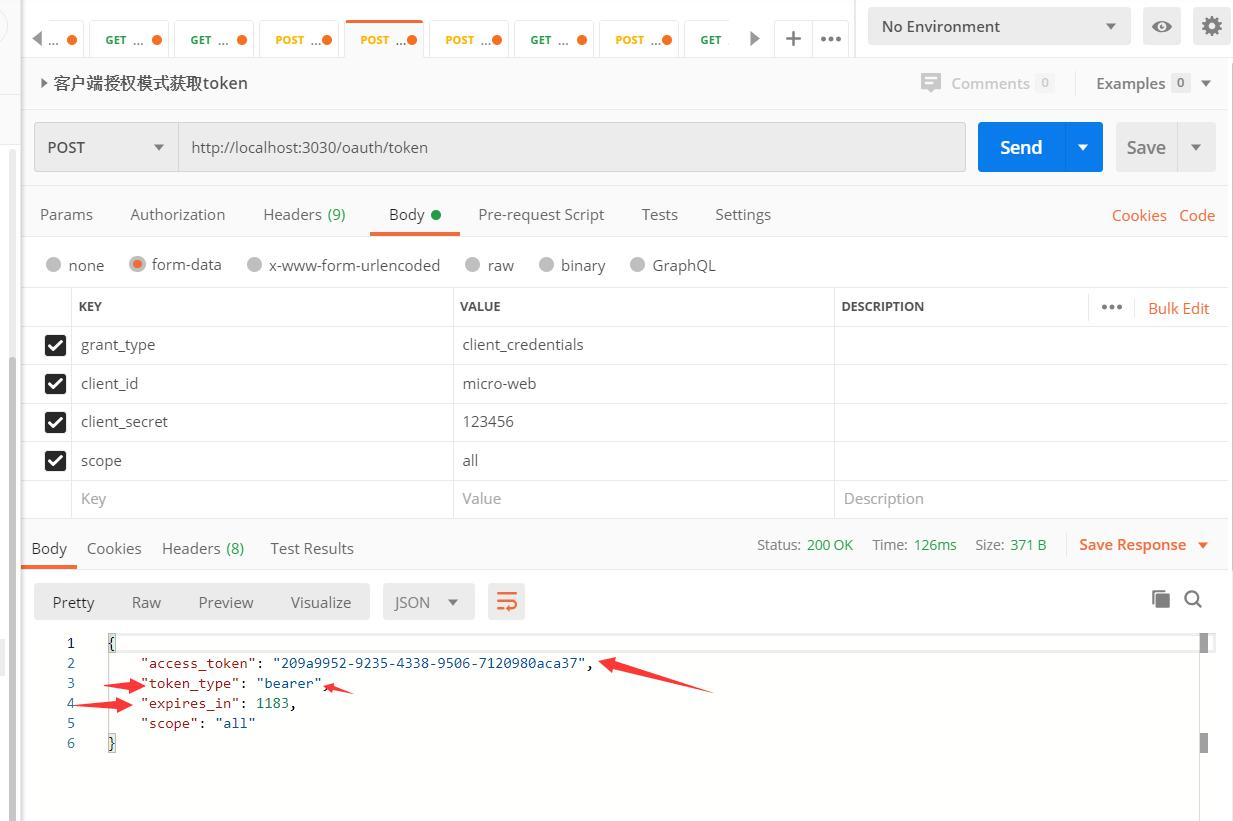
我们可以看到客户端模式申请 token, 只要带上有平台资质的客户端 id、 客户端密码、 然后
带上授权类型是客户端授权模式, 带上 scope 就可以了。 这里要注意的是客户端必须是具有
资质的。
密码模式获取 token
密码模式获取 token, 也就是说在获取 token 过程中必须带上用户的用户名和密码, 获取到
的 token 是跟用户绑定的。
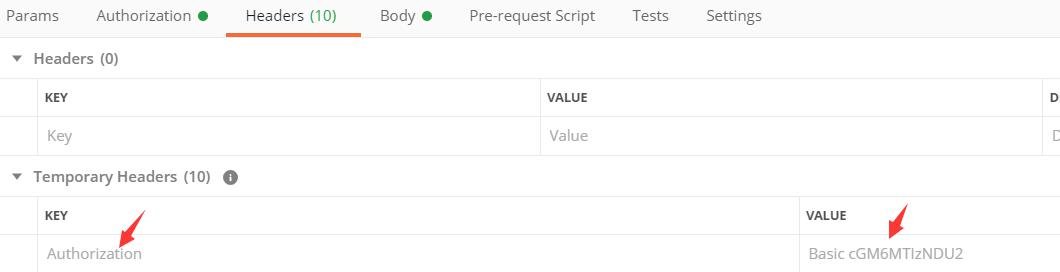
密码模式获取 token:
客户端 id 和客户端密码必须要经过 base64 算法加密, 并且放到 header 中, 加密模式为
Base64(clientId:clientPassword),如下:


认证服务器和下游系统权限校验流程

1、 zuul 携带 token 请求下游系统, 被下游系统 filter 拦截
2、 下游系统过滤器根据配置中的 user-info-uri 请求到认证服务器
3、 请求到认证服务器被 filter 拦截进行 token 校验, 把 token 对应的用户、 和权限从数据库
查询出来封装到 Principal
4、 认证服务器 token 校验通过后过滤器放行执行 security/check 接口, 把 principal 对象返回
5、 下游系统接收到 principal 对象后就知道该 token 具备的权限了, 就可以进行相应用户对
应的 token 的权限执行
授权码模式获取 token
授权码模式获取 token, 在获取 token 之前需要有一个获取 code 的过程。
1、 获取 code 的流程如下:

1、 客户端模式
一般用在无需用户登录的系统做接口的安全校验, 因为 token 只需要跟客户端绑定, 控制粒
度不够细
2、 密码模式
密码模式, token 是跟用户绑定的, 可以根据不同用户的角色和权限来控制不同用户的访问
权限, 相对来说控制粒度更细
3、 授权码模式
授权码模式更安全, 因为前面的密码模式可能会存在密码泄露后, 别人拿到密码也可以照样
的申请到 token 来进行接口访问, 而授权码模式用户提供用户名和密码获取后, 还需要有一
个回调过程, 这个回调你可以想象成是用户的手机或者邮箱的回调, 只有用户本人能收到这
个 code, 即使用户名密码被盗也不会影响整个系统的安全。
29、 链路追踪
其实链路追踪就是日志追踪, 微服务下日志跟踪, 微服务系统之间的调用变得非常复杂, 往
往一个功能的调用要涉及到多台微服务主机的调用, 那么日志追踪也就要在多台主机之间进
行, 人为的去每台主机查看日志这种工作几乎是不能完成的工作,原理详见:https://www.cnblogs.com/dw-haung/p/13751030.html
sop服务治理的更多相关文章
- 服务治理要先于SOA
讲在前面的话: 若企业缺乏对服务变更的控制和规则,那么一个服务在经过几个项目之后,就很有可能被随意更改成多个版本,将来变成什么样更是无法预测.久而久之,降低了服务重用的可能性,提高了服务利用的成本 ...
- 简述我的SOA服务治理
SOA服务治理 1.解决业务部门服务冲突和纠纷2.版本定义与版本管理3.服务备案与服务管理4.业务监督与服务监控 SOA的战略目的 一.业务价值胜过技术策略 二.战略目标胜过具体项目的效益 三.内置的 ...
- 基于Nginx dyups模块的站点动态上下线并实现简单服务治理
简介 今天主要讨论一下,对于分布式服务,站点如何平滑的上下线问题. 分布式服务 在分布式服务下,我们会用nginx做负载均衡, 业务站点访问某服务站点的时候, 统一走nginx, 然后nginx根据一 ...
- Dubbo框架中的应用(两)--服务治理
Dubbo服务治理了看法 watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvbGlzaGVoZQ==/font/5a6L5L2T/fontsize/400/fi ...
- 手把手教你使用spring cloud+dotnet core搭建微服务架构:服务治理(-)
背景 公司去年开始使用dotnet core开发项目.公司的总体架构采用的是微服务,那时候由于对微服务的理解并不是太深,加上各种组件的不成熟,只是把项目的各个功能通过业务层面拆分,然后通过nginx代 ...
- 1 Spring Cloud Eureka服务治理
注:此随笔为读书笔记.<Spring Cloud微服务实战> 什么是微服务? 微服务是将一个原本独立的系统拆分成若干个小型服务(一般按照功能模块拆分),这些小型服务都在各自独立的进程中运行 ...
- 1 Spring Cloud Eureka服务治理(下)
注:此随笔为读书笔记.<Spring Cloud微服务实战> 上篇主要介绍了什么是微服务以及微服务治理的简单实现,如微服务注册中心的实现.微服务注册的实现.微服务的发现和消费的实现.微服务 ...
- 笔记:Spring Cloud Eureka 服务治理
Spring Cloud Eureka 是 Spring Cloud Netflix 微服务套件的一部分,基于 Netflix Eureka 做了二次封装,主要负责完成微服务架构中的服务治理功能,服务 ...
- spring cloud 入门系列二:使用Eureka 进行服务治理
服务治理可以说是微服务架构中最为核心和基础的模块,它主要用来实现各个微服务实例的自动化注册和发现. Spring Cloud Eureka是Spring Cloud Netflix 微服务套件的一部分 ...
随机推荐
- datattable循环读取数据用于循环遍历checkboxlist里的项目
DataTable dt = bptb.GetList("Pro_ID="+id).Tables[0]; foreach (ListItem li in from DataRow ...
- 常用Linux Shell命令,了解一下!
目录 1 前言 2 正文 2.1 关机/重启 2.2 echo 2.3 vim文本编辑器 2.3.1 最基本用法 2.3.2 常用快捷键 2.3.3 查找/替换 2.4 拷贝/删除/移动/重命名 2. ...
- 【盗墓笔记】图解使用fat-aar方式在AndroidStudio中打包嵌套第三方aar的aar
将一些项目中的一些独立功能打包成aar,不仅能于项目解耦,还能够提供给其它项目使用相同的功能,可谓是为项目开发带来了很大的便利.最近第一次做sdk,碰到一些问题,花了不少时间才解决,所以这里做一下简单 ...
- Odoo10中calendar视图点击事件
有个需求,需要根据该条记录的状态字段来控制点击calendar时是否需要打开form视图,解决方案如下:重写了web_calendar的get_fc_init_options()方法中的eventCl ...
- ASP.NET Core整合Zipkin链路跟踪
前言 在日常使用ASP.NET Core的开发或学习中,如果有需要使用链路跟踪系统,大多数情况下会优先选择SkyAPM.我们之前也说过SkyAPM设计确实比较优秀,巧妙的利用Diagnosti ...
- sql注入--bool盲注,时间盲注
盲注定义: 有时目标存在注入,但在页面上没有任何回显,此时,我们需要利用一些方法进行判断或者尝试得到数据,这个过程称之为盲注. 布尔盲注: 布尔盲注只有true跟false,也就是说它根据你的注入信息 ...
- 向你的C语言项目中加入多线程
C语言在标准库<pthread.h>中为程序员提供了多线程操作接口. 先从简单操作入手 int pthread_create(pthread_t *thread, pthread_attr ...
- 常用的CSS命名规范大总结
转载: http://www.php.cn/toutiao-417563.html 文本命名规范 index.css: 一般用于首页建立样式 head.css: 头部样式,当多个页面头部设计风格相同时 ...
- 深入了解几种IO模型(阻塞非阻塞,同步异步)
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/zk3326312/article/details/79400805一般来说,Linux下系统IO主要 ...
- Mybatis快速逆向生成代码
先下载生成器的文件, 并在eclipse或者IDEA里面打开这个工程 热乎乎的链接 然后配置一下 选择你需要生成的数据的ip和端口 点击运行入口函数 运行成功 接着在浏览器输入localhost: 这 ...