ElasticSearch结合Logstash(三)
一、Logstash简介
1,什么是Logstash
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
2,为什么使用Logstash
如果某台服务器部署了多个实例,则需要去每个应用实例的日志目录下去找日志文件。每个应用实例还会设置日志滚动策略(如:每天生成一个文件),还有日志压缩归档策略等。
如果我们能把这些日志集中管理,并提供集中检索功能,不仅可以提高诊断的效率,同时对系统情况有个全面的理解,避免事后救火的被动。所以日志集中管理功能就可以使用ELK技术栈进行实现。Elasticsearch只有数据存储和分析的能力,Kibana就是可视化管理平台。还缺少数据收集和整理的角色,这个功能就是Logstash负责的。
3,Logstash工作原理
a)Data Source
Logstash 支持的数据源有很多。例如对于日志功能来说只要有日志记录和日志传递功能的日志都支持,Spring Boot中默认推荐logback支持日志输出功能(输出到数据库、数据出到文件)。
b)Logstash Pipeline
在Logstash中包含非常重要的三个功能:
- Input:输入源,一般配置为自己监听的主机及端口。DataSource向指定的ip及端口输出日志,Input 输入源监听到数据信息就可以进行收集。
- Filter:过滤功能,对收集到的信息进行过滤(额外处理),也可以省略这个配置(不做处理)
- Output:把收集到的信息发送给谁。在ELK技术栈中都是输出给Elasticsearch,后面数据检索和数据分析的过程就给Elasticsearch了。
最终效果:通过整体步骤就可以把原来一行日志信息转换为Elasticsearch支持的Document形式(键值对形式)的数据进行存储。
二、采用Logstash收集SpringBoot日志
1,安装logstash
- 解压logstash-6.8.4.tar.gz(与当前es的版本匹配)
- 创建一个conf配置文件
#输入采用tcp监控 ,当前监控端口为5044
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 5044
}
}
#输出到es中,配置index索引为my-es-log-年月日
output {
elasticsearch {
hosts => ["http://hadoop208:9200","http://hadoop209:9200"]
index => "my-es-log-%{+YYYY.MM.dd}"
}
}
启动:./logstash -f /usr/local/logstash/config/mylogstash.conf
2,在Springboot添加logback
a)添加maven
<!-- 使用logback往logstash中写入日志 -->
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>6.3</version>
</dependency>
b)配置logback.xml(在resource目录下)


<?xml version="1.0" encoding="UTF-8"?>
<!--
小技巧: 在根pom里面设置统一存放路径,统一管理方便维护
<properties>
<log-path>/Users/lengleng</log-path>
</properties>
1. 其他模块加日志输出,直接copy本文件放在resources 目录即可
2. 注意修改 <property name="${log-path}/log.path" value=""/> 的value模块
-->
<configuration debug="false" scan="false">
<property name="log.path" value="logs/${project.artifactId}"/>
<!-- 彩色日志格式 -->
<property name="CONSOLE_LOG_PATTERN"
value="${CONSOLE_LOG_PATTERN:-%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/>
<!-- 彩色日志依赖的渲染类 -->
<conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter"/>
<conversionRule conversionWord="wex"
converterClass="org.springframework.boot.logging.logback.WhitespaceThrowableProxyConverter"/>
<conversionRule conversionWord="wEx"
converterClass="org.springframework.boot.logging.logback.ExtendedWhitespaceThrowableProxyConverter"/>
<!-- Console log output -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
</encoder>
</appender> <!-- Log file debug output -->
<appender name="debug" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}/debug.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${log.path}/%d{yyyy-MM, aux}/debug.%d{yyyy-MM-dd}.%i.log.gz</fileNamePattern>
<maxFileSize>50MB</maxFileSize>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder>
<pattern>%date [%thread] %-5level [%logger{50}] %file:%line - %msg%n</pattern>
</encoder>
</appender> <!-- Log file error output -->
<appender name="error" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}/error.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${log.path}/%d{yyyy-MM}/error.%d{yyyy-MM-dd}.%i.log.gz</fileNamePattern>
<maxFileSize>50MB</maxFileSize>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder>
<pattern>%date [%thread] %-5level [%logger{50}] %file:%line - %msg%n</pattern>
</encoder>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level>
</filter>
</appender> <!--输出到logstash的appender-->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!--可以访问的logstash日志收集端口-->
<destination>hadoop208:3116</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender> <logger name="org.activiti.engine.impl.db" level="DEBUG">
<appender-ref ref="debug"/>
</logger> <!--nacos 心跳 INFO 屏蔽-->
<logger name="com.alibaba.nacos" level="OFF">
<appender-ref ref="error"/>
</logger>
<!-- Level: FATAL 0 ERROR 3 WARN 4 INFO 6 DEBUG 7 -->
<root level="INFO">
<appender-ref ref="console"/>
<appender-ref ref="debug"/>
<appender-ref ref="LOGSTASH"/>
</root>
</configuration>
c)启动并查看

3,使用kibana查看
创建索引规则
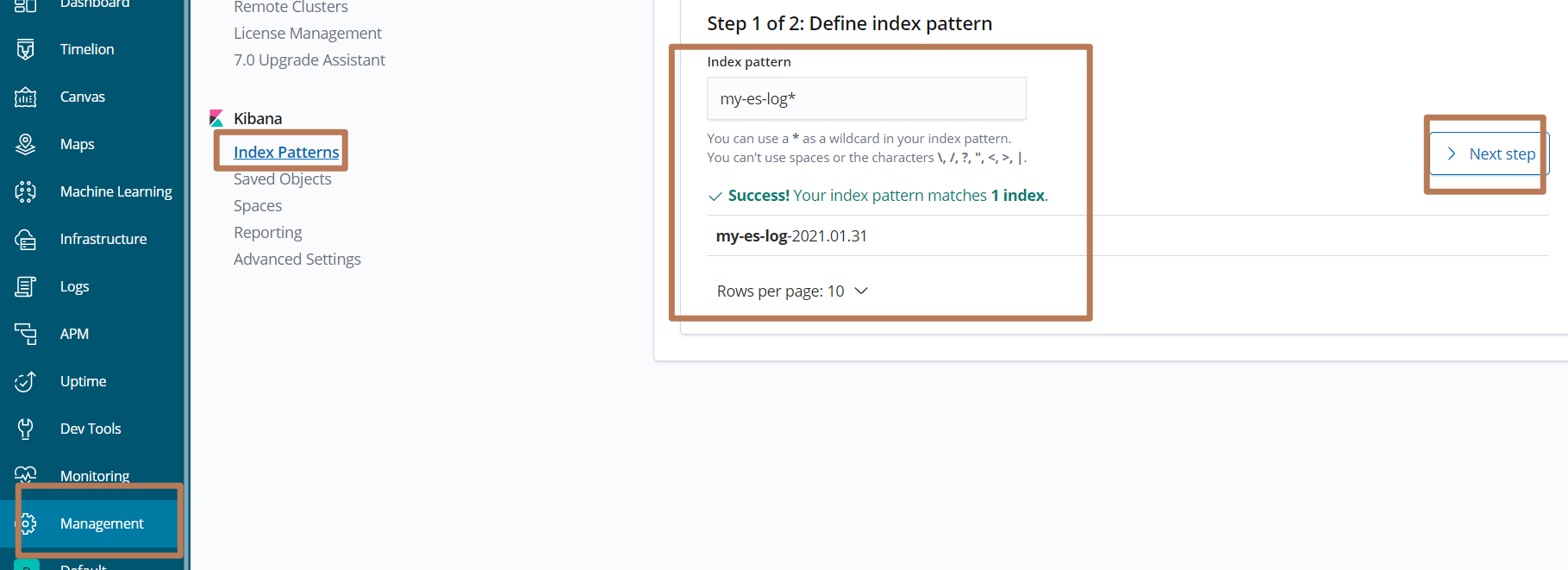
查看Discover
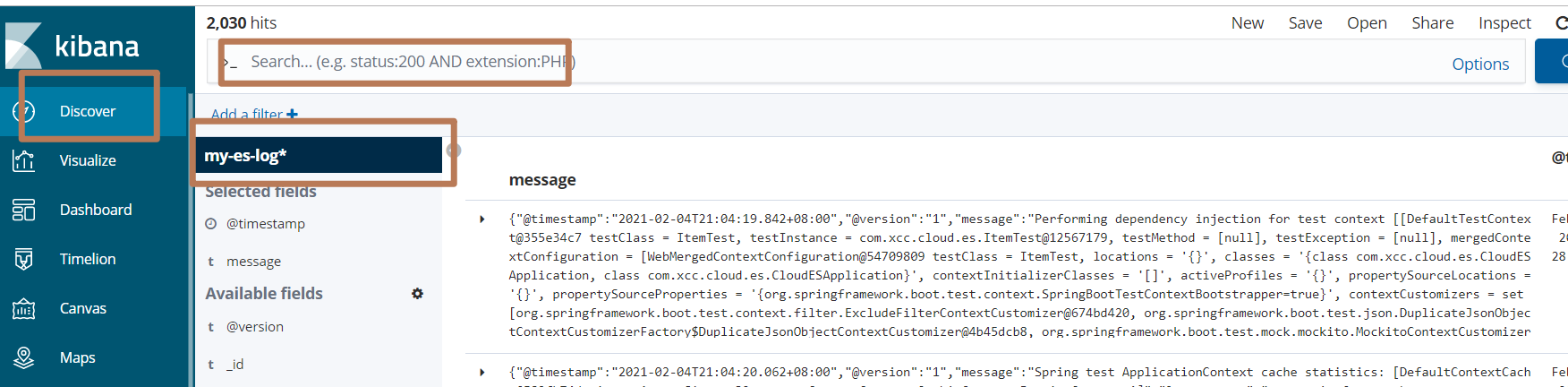
三、Logstash完成MySQL数据增量导入es
1 ,上传jdbc连接jar
上传到:$LogStash_HOME/logstash_core/lib/jars/
2,创建mysql
CREATE TABLE `tb_item` (
`id` bigint(20) NOT NULL COMMENT '商品id,同时也是商品编号',
`title` varchar(100) NOT NULL COMMENT '商品标题',
`sell_point` varchar(500) DEFAULT NULL COMMENT '商品卖点',
`price` bigint(20) NOT NULL COMMENT '商品价格,单位为:分',
`num` int(10) NOT NULL COMMENT '库存数量',
`barcode` varchar(30) DEFAULT NULL COMMENT '商品条形码',
`image` varchar(500) DEFAULT NULL COMMENT '商品图片',
`cid` bigint(10) NOT NULL COMMENT '所属类目,叶子类目',
`status` tinyint(4) NOT NULL DEFAULT '1' COMMENT '商品状态,1-正常,2-下架,3-删除',
`created` datetime NOT NULL COMMENT '创建时间',
`updated` datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `cid` (`cid`),
KEY `status` (`status`),
KEY `updated` (`updated`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='商品表';
LogStash实现增量导入,需要有一个定位字段,这个字段的数据,可以表示数据的新旧,代表这个数据是否是一个需要导入到ES中的数据。案例中使用表格的updated字段作为定位字段,每次读取数据的时候,都会记录一个最大的updated时间,每次读取数据的时候,都读取updated大于等于记录的定位字段数据。每次查询的就都是最新的,要导入到ES中的数据。
3,编写logstash配置
在$LogStash_home/config/目录中,编写配置文件ego-items-db2es.conf
input {
jdbc {
# 连接地址
jdbc_connection_string => "jdbc:mysql://hadop202:3306/ego?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC"
# 数据库用户名和密码
jdbc_user => "root"
jdbc_password => "123456"
# 驱动类,如果使用低版本的logstash,需要再增加配置 jdbc_driver_library,配置驱动包所在位置
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
# 是否开启分页逻辑
jdbc_paging_enabled => true
# 分页的长度是多少
jdbc_page_size => "2000"
# 时区
jdbc_default_timezone => "Asia/Shanghai"
# 执行的SQL
statement => "select id, title, sell_point, price, image, updated from tb_item where updated >= :sql_last_value order by updated asc"
# 执行SQL的周期, [秒] 分钟 小时 天 月 年
schedule => "* * * * *"
# 是否使用字段的值作为比较策略
use_column_value => true
# 作为比较策略的字段名称
tracking_column => "updated"
# 作为比较策略的字段类型,可选为numberic和timestamp
tracking_column_type => "timestamp"
# 记录最近的比较策略字段值的文件是什么,相对寻址路径是logstash的安装路径
last_run_metadata_path => "./ego-items-db2es-last-value"
# 是否每次执行SQL的时候,都删除last_run_metadata_path文件内容
clean_run => false
# 是否强制把ES中的字段名都定义为小写。
lowercase_column_names => false
}
}
output {
elasticsearch {
hosts => ["http://hadoop208:9200", "http://hadoop209:9200"]
index => "ego-items-index"
action => "index"
#指定document_id为数据库主键,保证更新
document_id => "%{id}"
}
}
4,安装logstash-input-jdbc插件
$Logstash_HOME/bin/logstash-plugin install logstash-input-jdbc
5,启动测试
bin/logstash -f 配置文件
ElasticSearch结合Logstash(三)的更多相关文章
- Elasticsearch、Logstash、Kibana搭建统一日志分析平台
// // ELKstack是Elasticsearch.Logstash.Kibana三个开源软件的组合.目前都在Elastic.co公司名下.ELK是一套常用的开源日志监控和分析系统,包括一个分布 ...
- ELK 之二:ElasticSearch 和Logstash高级使用
一:文档 官方文档地址:1.x版本和2.x版本 https://www.elastic.co/guide/en/elasticsearch/guide/index.html 硬件要求: 1.内存,官方 ...
- 如何在 Ubuntu 14.04 上安装 Elasticsearch,Logstash 和 Kibana
介绍 在本教程中,我们将去的 Elasticsearch 麋鹿堆栈安装 Ubuntu 14.04 — — 那就是,Elasticsearch 5.2.x,Logstash 2.2.x 和 Kibana ...
- (转)如何在CentOS / RHEL 7上安装Elasticsearch,Logstash和Kibana(ELK)
原文:https://www.howtoing.com/install-elasticsearch-logstash-and-kibana-elk-stack-on-centos-rhel-7 如果你 ...
- Ubuntu 16.04安装Elasticsearch,Logstash和Kibana(ELK)Filebeat
https://www.howtoing.com/how-to-install-elasticsearch-logstash-and-kibana-elk-stack-on-ubuntu-16-04 ...
- Stamus Networks的产品SELKS(Suricata IDPS、Elasticsearch 、Logstash 、Kibana 和 Scirius )的下载和安装(带桌面版和不带桌面版)(图文详解)
不多说,直接上干货! SELKS是什么? SELKS 是Stamus Networks的产品,它是基于Debian的自启动运行发行,面向网络安全管理.它基于自己的图形规则管理器提供一套完整的.易于使 ...
- ELK搭建(filebeat、elasticsearch、logstash、kibana)
ELK部署(文章有点儿长,搭建时请到官网将tar包下载好,按步骤可以完成搭建使用) ELK指的是ElasticSearch.LogStash.Kibana三个开源工具 LogStash是负责数据的收集 ...
- Elastic Stack核心产品介绍-Elasticsearch、Logstash和Kibana
Elastic Stack 是一系列开源产品的合集,包括 Elasticsearch.Kibana.Logstash 以及 Beats 等等,能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地 ...
- Elasticsearch 、 Logstash以及Kibana 分布式日志
搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群 ELK简介: ELK是三个开源软件的缩写,分别为:Elasticsearch . Logstash以及Kib ...
- elasticsearch kibana logstash(ELK)的安装集成应用
官网关于kibana的学习指导网址是:https://www.elastic.co/guide/en/kibana/current/index.html Kibana是一个开源的分析和可视化平台,设计 ...
随机推荐
- 一些php文件函数
当读入一个巨大的字符串的时候不能使用file_get_contents('文件名') 应该 使用fopen('文件名','r') feof('文件名') //判断是否读到了文件结尾 ******** ...
- String -- 从源码剖析String类
几乎所有的 Java 面试都是以 String 开始的,String 源码属于所有源码中最基础.最简单的一个,对 String 源码的理解也反应了你的 Java 基础功底. String 是如何实现的 ...
- 原生redis命令
一. redis-cli 连接 redis 进入redis安装目录 cd /usr/local/bin 进入redis客户端 ./redis-cli -p 6379 -h 用于指定 ip -p 用于指 ...
- day121:MoFang:植物的状态改动(幼苗→成长期)&植物的浇水功能
目录 1.当果树种植以后在celery的异步任务中调整浇水的状态 2.客户端通过倒计时判断时间,显示浇水道具 3.客户端判断当前种植物状态控制图标的显示和隐藏 4.当用户单击浇水图标, 则根据当前果树 ...
- VRay for SketchUp渲染图黑原因及解决方案
很多人都遇到用Vray for SketchUp云渲染的时候,渲染出来的图片是全黑或者是局部是黑色, 这是什么原因呢? 1.有一种情况是,SketchUp的文件储存机制和其他的软件有些不同,它是把模型 ...
- Head First 设计模式 —— 13. 代理 (Proxy) 模式
思考题 如何设计一个支持远程方法调用的系统?你要怎样才能让开发人员不用写太多代码?让远程调用看起来像本地调用一样,毫无瑕疵? P435 已经接触过 RPC 了,所以就很容易知道具体流程:客户端调用目标 ...
- Payment Spring Boot 1.0.4.RELEASE 发布,最易用的微信支付 V3 实现
Payment Spring Boot 是微信支付V3的Java实现,仅仅依赖Spring内置的一些类库.配置简单方便,可以让开发者快速为Spring Boot应用接入微信支付. 欢迎ISSUE,欢迎 ...
- Linux 中软链接和硬链接的使用
Linux 链接分两种,一种被称为硬链接(Hard Link),另一种被称为符号链接(Symbolic Link). 硬链接和软链接 硬链接 --- ln 要链接的文件 新硬链接名 软连接 --- l ...
- MySQL全面瓦解17:触发器相关
关于触发器 现实开发中我们经常会遇到这种情况,比如添加.删除和修改信息的时候需要记录日志,我们就要在完成常规的数据库逻辑操作之后再去写入日志表,这样变成了两步操作,更复杂了. 又比如删除一个人员信息的 ...
- 前端面试之JavaScript中this的指向【待完善!】
JavaScript中this的指向问题! 另一个特殊的对象是 this,它在标准函数和箭头函数中有不同的行为. 在标准函数中, this 引用的是把函数当成方法调用的上下文对象,这时候通常称其为 t ...