FPT: Feature Pyramid Transfomer
导言:
本文介绍了一个在空间和尺度上全活跃特征交互(fully active feature interaction across both space and scales)的特征金字塔transformer模型,简称FPT。该模型将transformer和Feature Pyramid结合,可用于像素级的任务,在论文中作者进行了目标检测和实力分割,都取得了比较好的效果。为了讲解清楚,若有transformer不懂的读者,关于transformer可以在公众号中看另一篇文《Transformer解读》。
背景内容
图像中在空间和尺度上隐藏着丰富的视觉语义信息,对于一个CNN模型来说要获取这些语义信息,需要通过卷积操作不断提取,但每次的感受野都比较小,每次仅能提取3x3 或5x5等小范围的信息,如果需要获取全局信息,需要将堆积多层卷积层。对此,有研究人员提出了Non-Local Neural Network, 简称NLN,在将卷积层中非局部的信息匹配起来(注:NLN在后续将会给出论文解读文章,后续看到本文的读者在公众号中模型总结部分将能看到)。但本文认为NLN没有跨尺度,而只进行了跨空间提取信息。基于此,本文应运而生。FPT将特征金字塔的每层与其他同大小但有不同丰富语义信息的层进行交互融合,提出了三种交互方式,分别是self-level,top-down 和bottom-up。
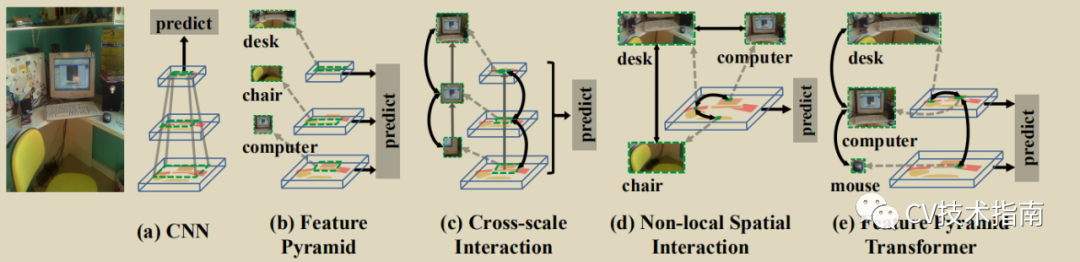
作者认为通过使用不同level的feature map可以识别目标的不同尺度。例如,小物体(电脑)应该在比较低的level下识别,大的物体(桌椅)应该在更高的level识别。因此我们需要去结合局部信息和来自于higher level的全局信息,这是因为电脑显示屏的局部外观是接近于电视机的,我们应该使用场景信息例如鼠标,键盘来辅助识别电视机和电脑。此外,作者认为电脑更可能是在桌子上,而不是大马路上,因此局部信息和全局信息的结合是有助于互相识别的。而且,作者认为非局部交互应该是在物体相应的尺度上,而不是一个统一的尺度。如鼠标跟电脑大小相差太大,在同尺度下信息不一样。
Overall structure of FPT
FPT网络由四个部分组成:特征提取的backbone, 特征金字塔构造模块,用于特征交互的FPT,以及具体任务的head网络。该模型可用于语义分割,实例分割和目标检测,因此,这个head 网络都是对应到具体任务中的最后处理部分。
Non Local Block
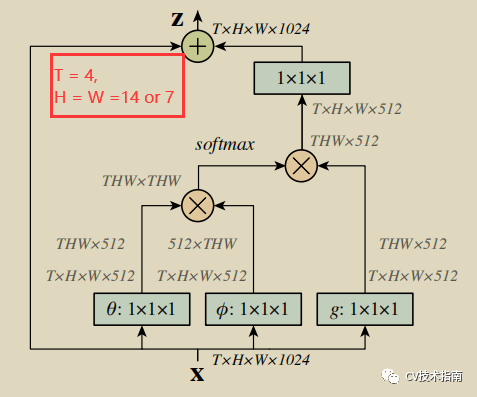
这里略微介绍一下Non Local Neural Network,过几天会给出这篇文章的论文解读,将放在公众号中的模型总结部分。

在transformer中最重要的是attention机制的灵活运用,在NLN中将图像经过特征提取网络将图像大小降低到14x14或7x7,再通过如下Non Local Block结构进行非局部信息的提取,使得模型会将注意力放在有利于识别任务的像素位置上,具体如上图所示。
Feature Pyramid Transformer
在non-local 交互操作中,其使用feature map作为values (V), keys (K), queries (Q),用公式表示如下:
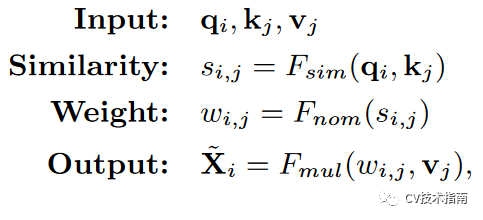
先使用点积计算q 和 k的相似度,再进行归一化(softmax),再与values进行相乘。
在FPT中提出了三种操作方式,分别以self-level, higher-level, lower-level作为其他level的queries,这样使得每一level都是一个跨空间和尺度交互的richer feature map。下面将介绍这三种方式。先提一句,这三种方式最主要的区别就是Q不同,还有个别细节不同。
注意下面给出的三种方式下给出的图中的纹理区别。
01 Self Transformer (ST)
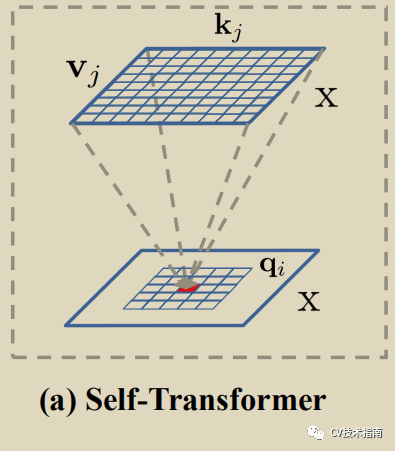
如上左图所示,输出为#字形纹理的图,所谓self-transformer即使用self-attention的交互操作,Q = K = V。
具体公式如上方所示,不同的是,作者使用Mixture of Softmaxes (Mos)代替softmax归一化,MoS公式如下,原因是实践证明在图像上MoS比标准softmax更有效。
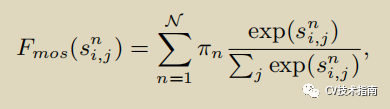
因此其公式如下:
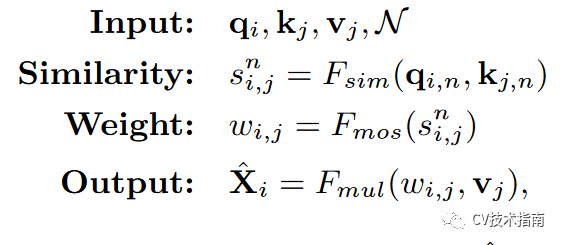
02 Grounding Transformer (GT)
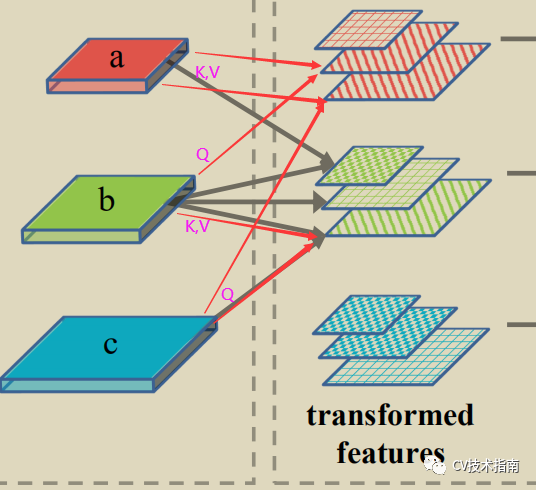
以higher-level为k, v , 以lower-level为 Q, 输出为\\形纹理。
具体公式仍如上方所示,与ST中一样归一化函数使用MoS,不同的是相似度函数从点积改为了欧式距离(euclidean distance),原因是当两张feature map的语义信息不同时,欧式距离比点积计算更有效。,欧式距离公式如下。
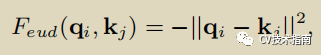
其公式如下:
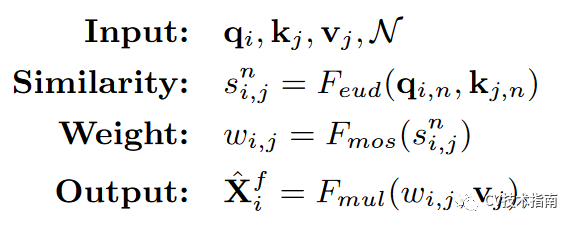
注:当具体任务为语义分割时,作者认为没必要计算全局的相似性,只需要计算局部相似性即可,因此在前面的基础上提出了Locality-constrained Grounding Transformer (LGT)。局部的大小为square_size, 对于k,v中超过索引位置,使用0代替。
03 Rending Transformer (RT)
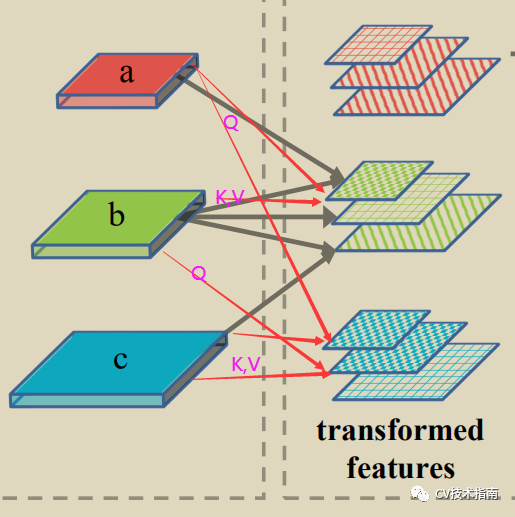
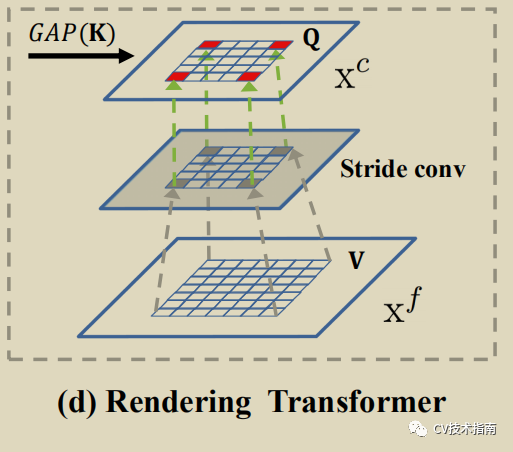
如上图所示,使用lower-level作为k,v 使用higher-level作为Q, 输出纹理为//形的图。
与前两者基于像素级别不同的是RT是基于整个feature map,做法类似于SE注意模块,k先使用全局平均池化(GAP)得到加权值w, w再与Q以通道注意方式进行加权得到Qatt, V使用含步长的3x3卷积 feature map进行降采样处理, 这是为了缩小特征图大小,最后改进版的Qatt与降采样的V进行summed-up, 即使用3x 3卷积进行feature map summation。
具体公式如下所示:
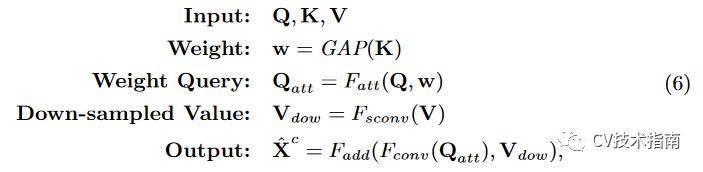
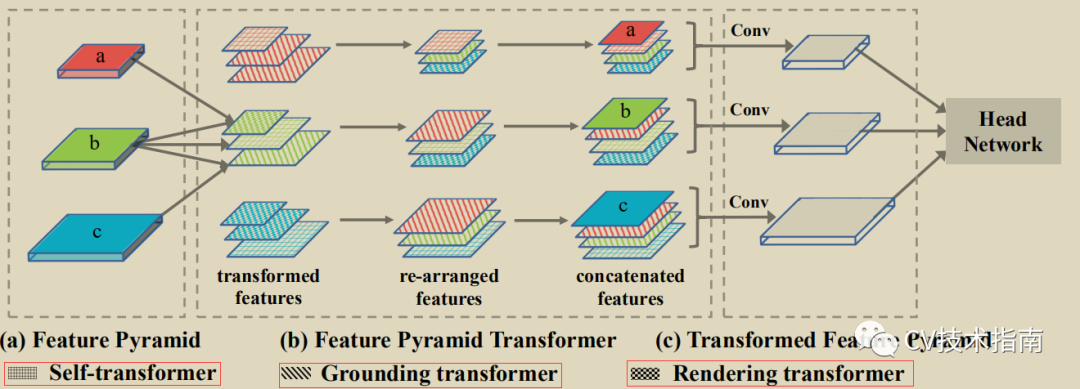
以上就是三种方式的具体细节。在看回到模型的整体结构图
再经过三种方式处理后得到了transformed feature, 再进行re-arranged ,就是将尺寸大小相同的放到一起concat,得到concatenated feature, 最后经过卷积层处理,再接上跟具体任务有关的Head Network部分。
如有错误,欢迎留言指出.
本文来源于微信公众号“ CV技术指南 ”的模型总结部分 。更多内容与最新技术动态尽在公众号发布。

FPT: Feature Pyramid Transfomer的更多相关文章
- Feature Pyramid Networks for Object Detection比较FPN、UNet、Conv-Deconv
https://vitalab.github.io/deep-learning/2017/04/04/feature-pyramid-network.html Feature Pyramid Netw ...
- 论文阅读笔记三十三:Feature Pyramid Networks for Object Detection(FPN CVPR 2017)
论文源址:https://arxiv.org/abs/1612.03144 代码:https://github.com/jwyang/fpn.pytorch 摘要 特征金字塔是用于不同尺寸目标检测中的 ...
- 『计算机视觉』FPN:feature pyramid networks for object detection
对用卷积神经网络进行目标检测方法的一种改进,通过提取多尺度的特征信息进行融合,进而提高目标检测的精度,特别是在小物体检测上的精度.FPN是ResNet或DenseNet等通用特征提取网络的附加组件,可 ...
- FPN(feature pyramid networks)
多尺度的object detection算法:FPN(feature pyramid networks). 原来多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征 ...
- 【Network Architecture】Feature Pyramid Networks for Object Detection(FPN)论文解析(转)
目录 0. 前言 1. 博客一 2.. 博客二 0. 前言 这篇论文提出了一种新的特征融合方式来解决多尺度问题, 感觉挺有创新性的, 如果需要与其他网络进行拼接,还是需要再回到原文看一下细节.这里 ...
- Feature Pyramid Networks for Object Detection
Feature Pyramid Networks for Object Detection 特征金字塔网络用于目标检测 论文地址:https://arxiv.org/pdf/1612.03144.pd ...
- Parallel Feature Pyramid Network for Object Detection
Parallel Feature Pyramid Network for Object Detection ECCV2018 总结: 文章借鉴了SPP的思想并通过MSCA(multi-scale co ...
- 特征金字塔网络Feature Pyramid Networks
小目标检测很难,为什么难.想象一下,两幅图片,尺寸一样,都是拍的红绿灯,但是一副图是离得很近的拍的,一幅图是离得很远的拍的,红绿灯在图片里只占了很小的一个角落,即便是对人眼而言,后者图片中的红绿灯也更 ...
- FPN(feature pyramid networks)
多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确:高层的特征语义信息比较丰富,但是目标位置比较粗略.另外虽然也有些算法采用多尺度 ...
随机推荐
- JZOJ2020年9月12日提高B组反思
CSP第1轮倒计时:29天 JZOJ2020年9月12日提高B组反思 T1 放在T1却是最难的一题 明显需要高精度 但是我小学奥数没学好,不知道怎么把正有理数转化成分数 T2 明显的DP 可惜的是我文 ...
- Spring Boot系列:七、 实现Mybatis多数据源切换
一.引入相关maven配置 mybatis; mysql驱动:jdbc <dependency> <groupId>org.mybatis.spring.boot</g ...
- MongoDB去重
db.集合.aggregate([ { $group: { _id: {字段1: '$字段1',字段2: '$字段2'},count: {$sum: 1},dups: {$addToSet: '$_i ...
- python装饰器基础及应用
一.简介 装饰器是是修改其它函数功能的函数:其意义是让其他函数在不修改任何代码的前提下增加额外功能 二.数据类型 首先我们来看一段简单的代码: from types import MethodType ...
- Mybatis学习-配置、作用域和生命周期
核心配置文件:Mybatis-config.xml Mybatis的配置文件包含了会深深影响Mybatis行为的设置和属性信息 配置(configuration) 在mybatis-config.xm ...
- 超详细讲解mysql存储过程中的in/out/inout
存储过程 大概定义:用一个别名来描述多个sql语句的执行过程. 最简单 delimiter // create PROCEDURE p1() begin select * from userinfo; ...
- 漫话docker的衰落与kubernetes的兴起
本文首发在OPPO互联网公众号,欢迎点击转载 https://mp.weixin.qq.com/s/wBC4CgAzXeTNURa1YdYmIQ. 伴随着kubernetes 1.20中对于docke ...
- FHQ简要笔记
前言 原文写于 XJ 集训day2 2020.1.19. 现在想想那时候连模板都还没写,只是刚刚理解就在那里瞎yy--之前果然还是太幼稚了. 今天刷训练指南发现全是 Treap 和 Splay ,不想 ...
- 阿里云服务器搭建java环境(jdk+tomcat+oracle11g)
一.JDK配置 1.在centos 7的更新源中有JDK,使用yum即可下载安装 查看库中版本 [root@localhost ~]# yum search java|grep jdk 选择需要版本进 ...
- sql注入之双查询注入
双查询注入前需要了解什么是子查询 子查询可以理解在一个select语句中再插入一个select 里面的select语句就是子查询 例子:select concat((select database() ...