Redis缓存篇(四)缓存异常
这一节,我们来学习一下缓存异常。缓存异常有四种类型,分别是缓存和数据库的数据不一致、缓存雪崩、缓存击穿和缓存穿透。
下面通过了解这四种缓存异常的原理和应对方法。
缓存和数据库的数据不一致
缓存和数据库的数据一致性包含两种情况:
- 缓存中有数据,缓存的数据值需要和数据库中的值相同;
- 缓存中没有数据,数据库中的值必须是最新值。
数据不一致是如何发生的?
在第1讲中关于缓存的类型那节,介绍了缓存有两种不同类型,分别是只读缓存和读写缓存。不同类型的缓存数据不一致的发生情况不一样,应对方法也不一样。
读写缓存:有两种写回策略,同步直写和异步写回。如果要保证数据一致,就要采用同步直写策略。但需要保证缓存和数据库的更新具有原子性,即要么都成功,要么都失败。
只读缓存:分新增数据和删改数据两种情况说明。
新增数据
数据直接写到数据库中,不对缓存做任何操作,符合一致性的第2种情况。
删改数据
发生删改操作时,既要更新数据库,也要在缓存里删除数据。因为缓存和数据库是不同的系统,这里分两种情况:
- 先删除缓存,再更新数据库:数据库更新失败,导致请求再次访问缓存时,发现缓存失败,再读数据库时,从数据库中读取旧值。
- 先更新数据库,再删除缓存:缓存删除失败,导致请求再次访问缓存时,发现缓存命中,并从缓存中读取到旧值。
如何解决数据不一致?
使用重试机制,指把删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用Kafka消息队列)。
当应用没有能够成功地删除缓存值或者是更新数据库值时,从消息队列中重新读取这些值,然后再次进行删除或更新。
如果成功删除,就从消息队列中删除,以免重复操作。否则就要进行重试,如果重试超过一定次数,就要向业务层发送报错信息。
具体情况如下图所示:
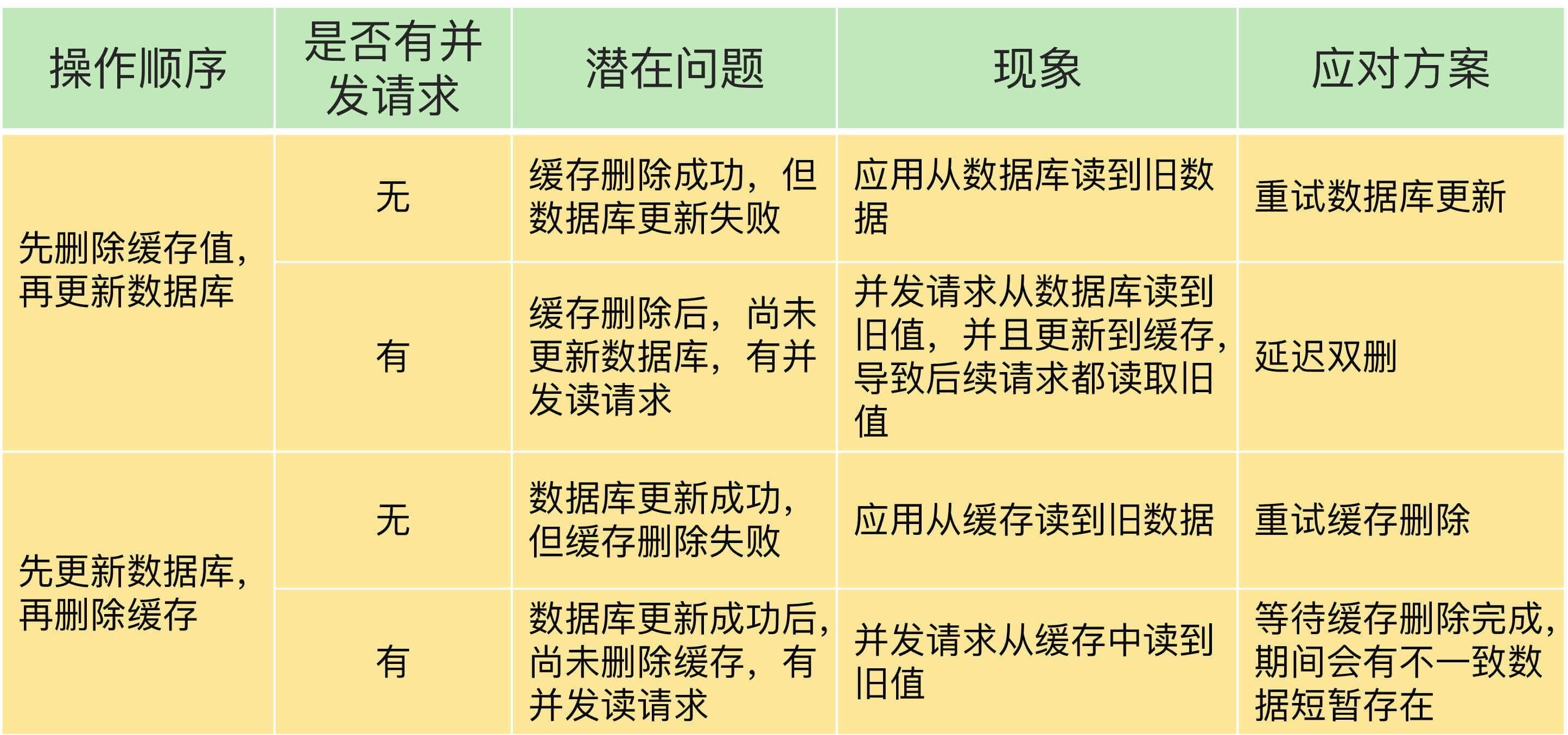
总结一下,对于只读缓存来说,建议优先使用先更新数据库,再删除缓存。
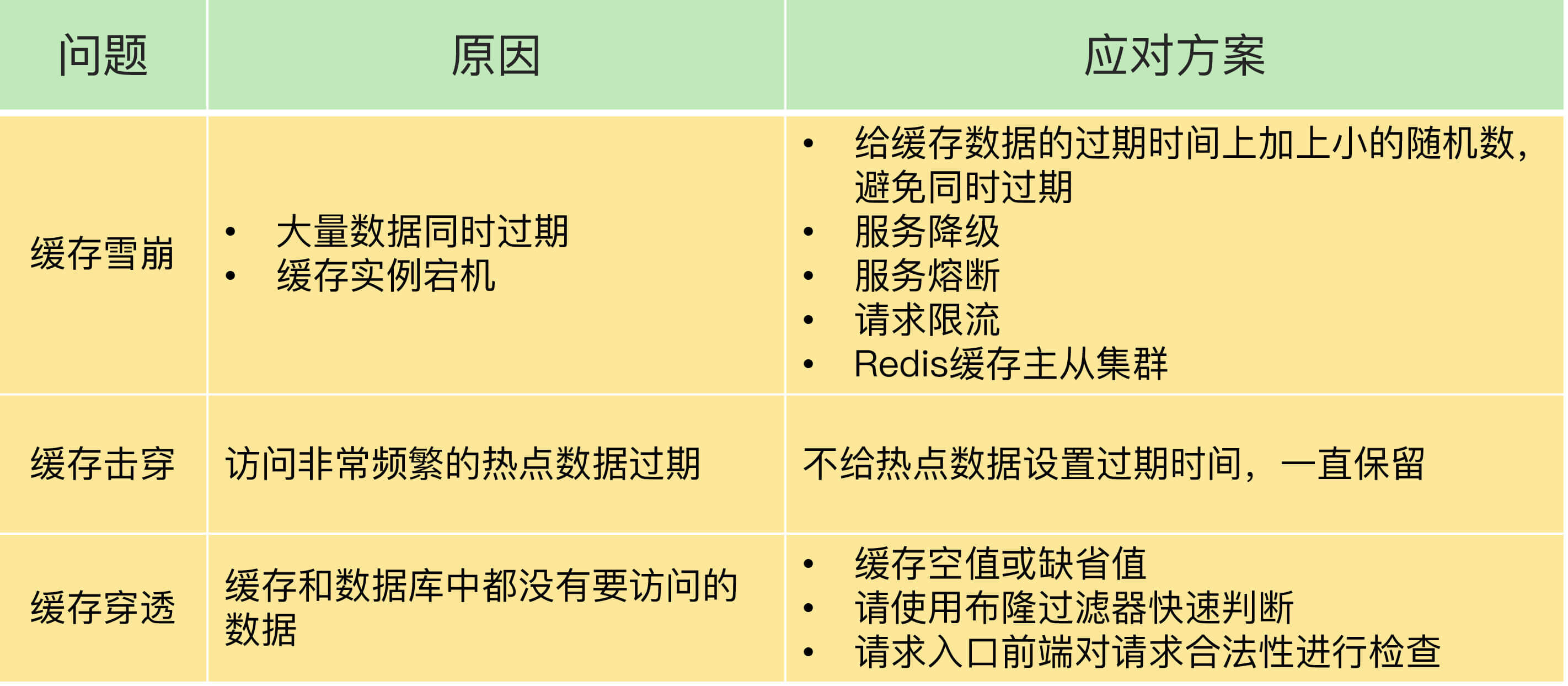
缓存雪崩
缓存雪崩,指大量的应用请求无法在Redis缓存中进行处理,然后应用将大量请求发送到数据库层,导致数据库层的压力激增。
导致缓存雪崩的两个原因:
1. 缓存中有大量数据同时过期,导致大量请求无法得到处理。
解决方案有两个,一是避免给大量的数据设置相同的过期时间,增加一个较小的随机数(例如,随机增加1~3分钟)。
另一个是服务降级,服务降级指发生缓存雪崩时,针对不同的数据采取不同的处理方式:
- 非核心数据,暂时停止从缓存中查询,直接返回预定义信息、空值或者错误信息;
- 核心数据,允许查询缓存,如果缓存缺失,继续通过数据库读取。
2. Redis缓存实例发生故障宕机了,无法处理请求。
有两个建议,一是在业务系统中实现服务熔断或请求限流机制。
服务熔断是指在发生缓存雪崩时,为了防止引发连锁的数据库雪崩,暂停业务应用对缓存系统的接口访问。
具体点,就是业务应用调用缓存接口时,缓存客户端并不把请求发给Redis缓存实例,而是直接返回,等Redis缓存实例重新恢复服务后,再允许发送。
服务熔断会暂停了整个缓存系统的访问,对业务应用的影响范围大。而请求限流相比服务熔断造成的影响没那么大。
请求限流是指业务系统的请求入口前端控制每秒进入系统的请求数,避免过多的请求被发送到数据库。
二是事前预防,通过主从节点构建Redis缓存高可靠集群。
缓存击穿
缓存击穿,指针对某个访问非常频繁的热点数据的请求,无法在缓存中进行处理,大量请求发送到后端数据库,导致数据库压力激增,影响数据库处理其他请求。
解决方案是,对于访问特别频繁的热点数据,不设置过期时间。
缓存穿透
缓存穿透,指要访问的数据既不在Redis缓存中,也不在数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,也发现没有数据。
如果有大量请求访问数据,就会同时给缓存和数据库带来巨大压力。
发生缓存穿透有两种情况:
- 业务层误操作:缓存中的数据和数据库中的数据被误删除;
- 恶意攻击:专门访问数据库中没有的数据。
为了避免缓存穿透,有三种应对方案。
第一种方案是,缓存空值或缺省值
一旦发生缓存穿透,就针对查询的数据,在Redis中缓存一个空值或是和业务层协商确定的缺省值。
第二种方案是,使用布隆过滤器快速判断数据是否存在,避免从数据库中查询数据是否存在,减轻数据库压力
布隆过滤器由一个初值都为0的bit数组和N个哈希函数组成,可以用来快速判断某个数据是否存在。
通过三个操作完成标记:
- 使用N个哈希函数,分别计算这个数据的哈希值,得到N个哈希值
- 把这N个哈希值对bit数组的长度取模,得到每个哈希值的位置
- 把对应的位置的bit位设置为1
这样一来,即使发生缓存穿透,大量请求只会查询Redis和布隆过滤器。
第三种方案是,在请求入口的前端进行请求检测
例如对请求进行合法性检测,把恶意的请求(例如请求参数不合理、请求参数是非法值、请求字段不存在)直接过滤掉
总结
另外还有三个建议:
- 针对缓存雪崩,合理地设置数据过期时间,以及搭建高可靠缓存集群。
- 针对缓存击穿,在缓存访问非常频繁的热点数据时,不要设置过期时间。
- 针对缓存穿透,提前在入口前端实现恶意请求检测,或者规范数据库的数据删除操作,避免误删除。
参考资料
Redis缓存篇(四)缓存异常的更多相关文章
- (转)高性能网站架构之缓存篇—Redis集群搭建
看过 高性能网站架构之缓存篇--Redis安装配置和高性能网站架构之缓存篇--Redis使用配置端口转发 这两篇文章的,相信你已经对redis有一定的了解,并能够安装上,进行简单的使用了,但是在咱们的 ...
- Spring Boot 揭秘与实战(二) 数据缓存篇 - Redis Cache
文章目录 1. Redis Cache 集成 2. 源代码 本文,讲解 Spring Boot 如何集成 Redis Cache,实现缓存. 在阅读「Spring Boot 揭秘与实战(二) 数据缓存 ...
- 缓存篇~第八回 Redis实现基于方法签名的数据集缓存~续(优化缓存中的key)
返回目录 上一讲主要是说如何将数据集存储到redis服务器里,而今天主要说的是缓存里的键名,我们习惯叫它key. redis或者其它缓存组件实现的存储机制里,它将很多方法对应的数据集存储在一个公共的空 ...
- [redis] -- 缓存雪崩和缓存穿透、缓存击穿问题解决方案篇
缓存雪崩 缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉 解决方案 事前:尽量保证整个redis集群的高可用性,发现机器宕机尽快补上.选择合适的内存淘 ...
- Redis缓存篇(一)Redis是如何工作的
Redis提供了高性能的数据存取功能,所以广泛应用在缓存场景中,既能有效地提升业务应用的响应速度,还可以避免把高并发压力发送到数据库层. 因为Redis用作缓存的普遍性以及它在业务应用中的重要作用,所 ...
- Redis缓存篇(三)缓存污染
上一讲介绍了缓存满了,通过内存淘汰机制来淘汰掉数据.如果有的数据一直滞留在缓存中,但又没有应用使用,时间长了,就可能会占据大部分的缓存空间. 今天我们来学习一下缓存污染,以及如何解决缓存污染. 缓存污 ...
- Redis面试篇 -- 如何保证缓存与数据库的双写一致性?
如果不是严格要求“缓存和数据库”必须保证一致性的话,最好不要做这个方案:即 读请求和写请求串行化,串到一个内存队列里面去.串行化可以保证一定不会出现不一致的情况,但会导致系统吞吐量大幅度降低. 解决这 ...
- nopCommerce 3.9 大波浪系列 之 使用Redis主从高可用缓存
一.概述 nop支持Redis作为缓存,Redis出众的性能在企业中得到了广泛的应用.Redis支持主从复制,HA,集群. 一般来说,只有一台Redis是不可行的,原因如下: 单台Redis服务器会发 ...
- Redis总结(五)缓存雪崩和缓存穿透等问题 Web API系列(三)统一异常处理 C#总结(一)AutoResetEvent的使用介绍(用AutoResetEvent实现同步) C#总结(二)事件Event 介绍总结 C#总结(三)DataGridView增加全选列 Web API系列(二)接口安全和参数校验 RabbitMQ学习系列(六): RabbitMQ 高可用集群
Redis总结(五)缓存雪崩和缓存穿透等问题 前面讲过一些redis 缓存的使用和数据持久化.感兴趣的朋友可以看看之前的文章,http://www.cnblogs.com/zhangweizhon ...
随机推荐
- PostMan参数传递
一.先取出返回中需要用的值,并设置变量 二.传入下一接口中
- php 序列化键、值逃逸
转自https://www.cnblogs.com/wangtanzhi/p/12261610.html PHP反序列化的对象逃逸(很重要一点,引号的匹配是从左到右按字符串长度进行匹配) 任何具有一定 ...
- 【题解】三角形 [P1222] / 三角形覆盖问题 [HNOI2012] [P3219]
[题解]三角形 [P1222] / 三角形覆盖问题 [HNOI2012] [P3219] 传送门: 三角形 \(\text{[P1222]}\) 三角形覆盖问题 \(\text{[HNOI2012] ...
- 廖雪峰官网学习js 数据类型和变量
数据类型: number 不分整数 和浮点数 字符串 用' ' " " 表示 布尔值 true false && 与运算符(都ture才ture ...
- 验证pdf文件的电子章签名
pom.xml <?xml version="1.0" encoding="UTF-8"?> <project xmlns="htt ...
- 前端开发超好用的截图、取色工具——snipaste
最近发现一个很好用的前端截图,取色工具,并且基本功能是免费使用的,可以提升开发效率,拿出来跟大家分享一下. 该工具主要能实现的功能就是截图,并且截图可以以窗口形式置顶在窗口: 第二个主要功能就是可以取 ...
- mysql位函数的使用
查询每个月的访问天数 mysql> create table t1 (year YEAR(4),month int(2) unsigned zerofill,day int(2) u nsign ...
- 手把手教你配置KVM服务器
1 Ubuntu系统安装 1.1 制作启动盘 准备一个U盘,将其清空后,去官网下载Ubuntu18.04系统的iso镜像文件,并将其拷进U盘.然后下载一个UltralOS软碟通工具,完成安装后打开软碟 ...
- AdaBoost 算法-分析波士顿房价数据集
公号:码农充电站pro 主页:https://codeshellme.github.io 在机器学习算法中,有一种算法叫做集成算法,AdaBoost 算法是集成算法的一种.我们先来看下什么是集成算法. ...
- 移动端 canvas基础1
一.canvas画布 Canvas是HTML5中新出的一个元素,开发者可以通过JS脚本动态绘制图像. #1. 创建canvas画布 在页面中创建canvas标签,并设置其id和宽高 (不要通过css设 ...