论文阅读:An End-to-End Network for Generating Social Relationship Graphs
论文链接:https://arxiv.org/abs/1903.09784v1
Abstract
社交关系智能代理在人工智能领域中越来越引人关注。为此,我们需要一个可以在不同社会关系上下文中理解社交关系的系统。在给定的视觉场景中推断社会情境不仅涉及对象的识别,而且还需要更深入地了解所涉人员的关系和属性。因此,一种表示人际关系和属性的计算方法是使用显式的知识图谱来进行更高级别的推理。我们介绍了一种新颖的可训练的端到端的神经网络,其能够生成社交关系图—对给定的输入图像中的社交关系和属性进行结构化、统一的表示。我们的社交关系图生成网络(SRG-GN)是第一个使用GRUs这样的记忆单元,并通过使用场景和属性上下文来循环更新关系图中的社交关系隐状态。神经网络利用GRU之间的常连接来实现图中节点和边之间的消息传递,并且比以前的社交关系识别方法效果有了显着改进。
Introduction
在计算机视觉研究中对人际关系的理解还处于起步阶段。相比之下,社会心理学家和其他研究人员已经做出了巨大的努力来研究人类的社会关系。在最近的计算机视觉研究中,“subject-predicate-object”类型的关系预测已引起了主要的研究关注。 这些可用于多种高级任务,例如图像检索,图像字幕,视觉问答等。
鉴于人类在其环境中所构成的广泛差异,理解人类关系的任务是一个艰巨的问题,因为图像中存在一些人类很容易理解的不可观察的潜在信息。为了在这种情况下发展人们对水平的理解,计算模型应基于社会和认知心理学的理论。基于Bugental的社会心理学理论,我们应当关注社交关系中的人类属性和环境。
在社会心理学研究中已经表明,诸如年龄,性别和穿着等外表提示对于理解社会关系很有用。 因此,我们使用场景上下文,活动和外观特征进行社交关系图推理。
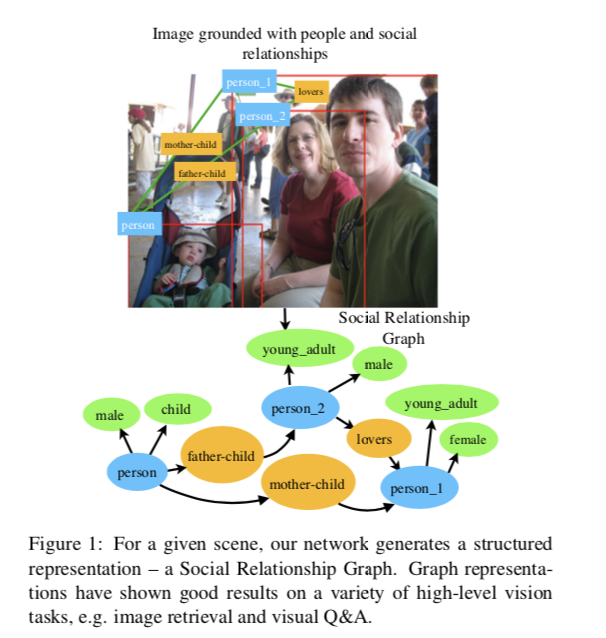
本文的主要贡献是:1)一种新颖的结构化表示(社会关系图),用于视觉场景中的社会理解; 2)一种新颖的使用GRU和语义属性进行图生成的端到端可训练神经网络架构; 3)在PIPA-relation 和PISC 数据集上获得社会关系识别的最新成果。第一个建立在社会关系和属性上的,使用记忆单元的架构,我们的结果证明了消息传递和场景上下文的重要性。
Related Work
2.1 Social Relationship Recognition
随着社交聊天机器人和个人助手需要了解社交互动,社交关系领域越来越受到社区的关注。许多研究人员试图理解社会关系,角色和互动等。Zhang等人使用具有暹罗式结构的面部表情研究了人际关系。也有些研究是关于亲属关系识别和亲属关系验证的。 Wang等人在个人图像集合中研究家庭关系。 Jinna等人介绍了一个视频数据集,用于了解人与人之间的粗粒度社会关系。Li等人使用Attentive-RCNN模型进行图片中的社交关系六分类预测。Ramanathan等人认识到人们在各种事件中扮演的社会角色。Chakraborty等人将照片分为“情侣,家庭,团体或人群”等类别。 Sun等人预测日常图像中的细粒度社交关系。上述许多作品都使用了物理外观或线索,如活动,亲近,情感,表情,背景等。我们工作不同之处在于通过将基本属性特征与内存单元相结合,从而为我们的问题提供了更丰富的框架。
2.2 Graph-Based Representations
最近,对于使用结构化图进行图像的可视化表示激起了人们兴趣。 知识图谱被广泛用于对象检测和图像分类。 Johnson等人介绍了使用实物标注的场景图,用于使用对象关系和属性进行图像检索。从那时起,通过使用固有图属性和周围环境直接从图像生成场景图的任务引起了人们的关注。研究人员还探索将视觉和语言模块一起使用来识别物体之间的关系。 我们提出了一个新颖的框架来生成图,重点关注人们的社会关系和属性,这与现有工作中重点关注的空间对象关系不同。
Model Definition
在本节中,我们概述了使用社会关系图生成网络(SRG-GN)从图像生成社会关系图的方法。 图2中的框架对我们的两个模块进行了更详细的描述:一个用于属性和关系表示的多网络卷积神经网络(MN-CNN)模块,然后是一个社会关系图推理网络(SRG-IN) 用于生成结构化图形表示的模块。 对该模型进行端到端的培训,以结构化语义定向图表示的形式预测作为场景一部分的关系,域和属性。
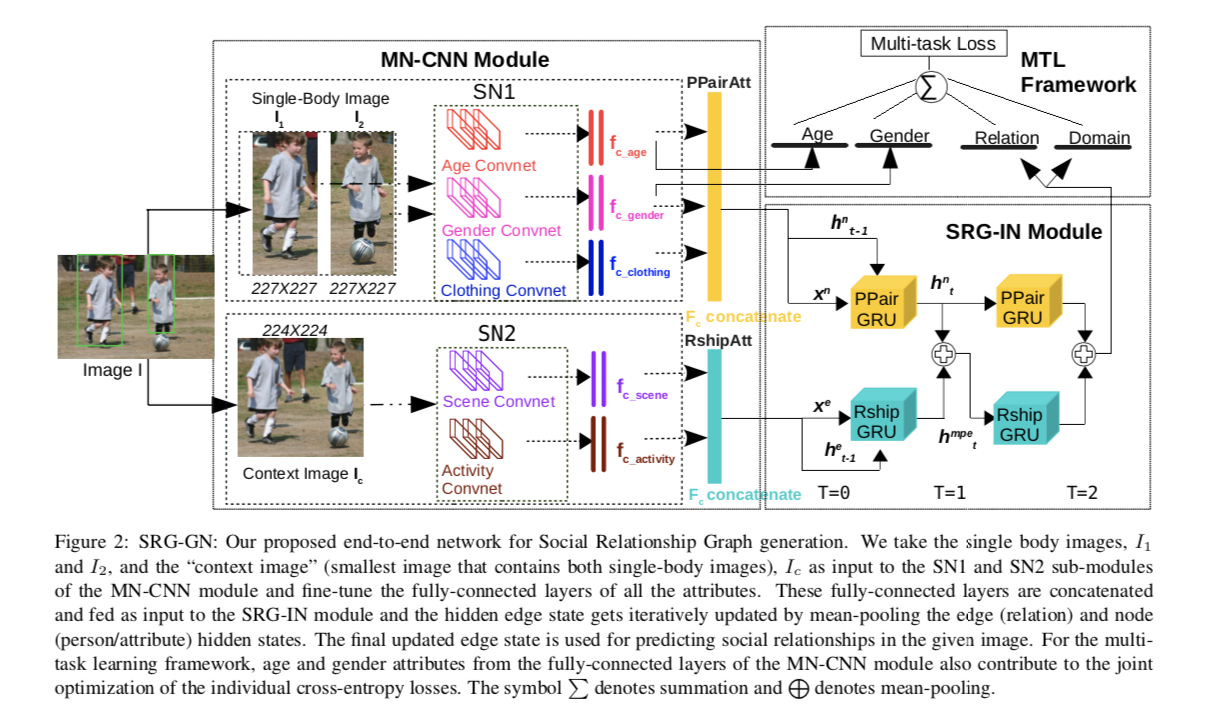
3.1 Multi-Network Convolutional Neural Network (MN-CNN) for Relationships and Attributes
输入为一幅图像I,和图像中的人物bounding-boxes集合(一幅图片中可能由多个人物,但每次仅预测两个人物间的社交关系。对于一张图片,要生成其对应的社交关系图可能需要进行多次预测),所有的bounding-boxes统一resize到227x227像素。对于每两个人之间的上下文关系,我们定义一个上下文图像Ic(包含两个人物图像的最小图像),大小调整为224x224像素。
MN-CNN模块包含两个子模块(SN1,SN2),他们的输入分别是两个人物的resize过的bounding-box图像 Ii,和两个人的上下文图像Ic。
SN1模块是一个属性卷积结构,其中包含三个卷积网络(年龄、性别、服饰)。每个卷积网络由五层卷积和两层fc组成。这三个卷积网络中的卷积层都使用预训练得到的权重,我们仅微调全连接层的权重。将每个人物图像通过SN1模块后得到的三个属性特征concat后得到人物级别的特征Fi。(由于预测的是两两关系,之后会将两个人物的特征Fi和Fj连接作为PPair GPU的输入)。
SN2模块中包含两个VGG-16网络分别计算活动和场景特征,同理也是卷积层使用预训练的权重,仅微调fc层的权重,最终把得到的两种特征concat后得到RshipAtt。
3.2 Social Relationship Graph Inference Network (SRG-IN)
在我们的网络中,图像中的每个关系都从其附近的节点(人员属性)以及附近的边(关系)获取信息。 通过使用门控循环单元(GRU)汇总来自相邻节点和关系的消息并迭代更新这些消息以改善给定节点的状态来实现。 因此,我们能够利用场景上下文中的信息和各个属性来改善“社交关系图”中的关系。
3.2.1 Inference using GRUs and Message Passing Scheme
网络里使用两种GRUs(Relationship(Rship)和Person-Pair(PPair))。
PPair GRU的输入和初始状态使用PPairAtt设置,即从MN-CNN中的SN1模块得到的特征向量,我们将两个节点的特征,即两个人物图片提取出的特征concat起来作为输入x。得到的更新节点状态特征h和x作为下一个GRU节点的状态输入和特征输入。
Rship GRU的输入和初始状态使用RshipAtt(SN2得到的特征向量)设置。节点状态使用mean-pooled方法更新。
3.3 Multi-Task Learning (MTL) Framework
对于我们的问题,我们有四个任务标签(年龄,性别,领域和关系),可以使用同一网络来学习。我们通过组合所有这四个任务的单个损失函数来共同优化损失函数。我们将域标签与关系标签一起学习,以便网络可以在这两个任务之间共享一些相关信息,以改善总体损失功能。Rship GRU的输出用于预测域和关系标签,而MN-CNN模块的fcage和fcgender特征向量分别用于使用交叉熵损失函数来预测年龄和性别属性标签。我们仅考虑年龄和性别属性预测,因为数据集仅限于这两个属性。图2显示了我们如何将MTL框架合并到我们的SRG-GN模型中。
Empirical Evaluation
4.1 Dataset Preparation
PIPA关系数据集具有16个细粒度的关系类别1。我们将其数据集扩展到PIPA关系图数据集。我们从发布在PIPA数据集上的属性注释中使用两个属性(年龄和性别)来构建PIPA关系图数据集。训练/验证/测试集包含6289张图像,这些图像具有13,672个关系和16,145个属性,270张图像具有706个关系和753个属性,2649张图像具有5075个关系和6655个属性。
我们进一步验证了我们模型在Li等人发布的大规模“社会背景下的人”(PISC)数据集上的性能。 PISC数据集具有22,670张图像,其中为人对添加了3种粗粒度关系(亲密,非亲密和无关系)和6种细粒度关系(商业,夫妻,家庭,朋友,专业和无关系)的注释。训练/验证/测试集分别包含16,828张图像和55,400个关系实例,500张图像和1,505个实例,1,250张图像和3,961个实例。
4.2 Baselines
Comparison models for PIPA-relation dataset:
- Double-Stream (DS) CaffeNet
- Finetuned model from pre-trained on Imagenet
- Primal-Dual graph model
Comparison models for PISC dataset:
- Pair–CNN+BBox
- Pair–CNN+BBox+Union
- Pair–CNN+BBox+Global
- Pair–CNN+BBox+Scene
- Dual-Glance
4.3 Implementation Details
模型中关于年龄,性别,服装和活动的预训练权重是公开的。Scene ConvNet体系结构的预训练权重来自Zhou等人发布的模型。 冻结了所有卷积层的权重,仅微调MN-CNN模块的全连接层和GRUs。两个GRU的输出的维数均为512。softmax层是为了计算年龄和性别属性、域和关系标签的最终分数。PISC数据集没有属性标签,因此仅获得域和关系的分数。作为MTL框架的一部分,最终将所有损失相加并共同优化总加权损失。GRU的学习速率为10-6,使用2个时间步长(即两层)来训练模型。为了防止过度拟合,采用了早期停止,dropout和正则化等方法。模型使用Tensorflow实现。
4.4 Result
作者从两方面对模型进行了评估。分别为社交关系识别、社交关系图生成。
作者除了将自己的模型和baseline对比,还进行了自比较:将完整的模型与仅有MN-CNN模块的模型、有MN-CNN模块,但SN2中仅有activity卷积网络的模型进行效果对比。
在两个数据集上分别与baseline做对比得出的结论是:使用语义属性、场景和活动特征是非常重要的。
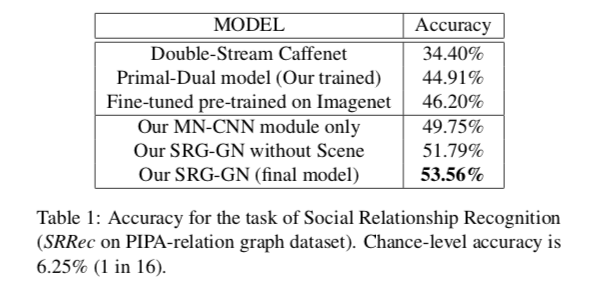
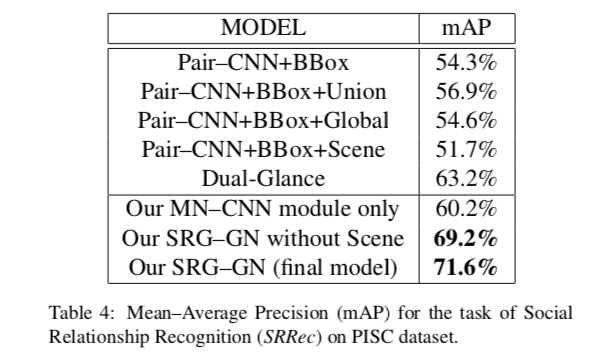
在两个数据集上分别与baseline做对比得出的结论是:使用语义属性、场景和活动特征是非常重要的。

自比较得出的结论是:信息传播和场景特征都很重要。
Conclusion
本文介绍了一种新型的端到端的可训练的网络,用于使用GRU从图像生成社交关系图。先前生成图形的工作涉及对象之间的关系,而我们的工作解决了推断社会关系这一更具挑战性的问题。 实验结果表明,在图表中传递消息时使用属性和上下文特征非常重要。 我们的模型在识别社会关系方面表现优于最新技术,并且在生成社会关系图方面表现出色。 这项工作可以扩展到更复杂的任务,例如预测社会意图。
my feeling
全文介绍了一个新型的针对图片级别的一个端到端网络,可以进行图片中的人物关系识别并可以生成关系图。相比较于前人的创新在于充分地利用了图片中的人物属性和上下文(识别人物的性别、年龄,图片的activity和scene),并使用了GRUs来更新state。
论文阅读:An End-to-End Network for Generating Social Relationship Graphs的更多相关文章
- 2018年发表论文阅读:Convolutional Simplex Projection Network for Weakly Supervised Semantic Segmentation
记笔记目的:刻意地.有意地整理其思路,综合对比,以求借鉴.他山之石,可以攻玉. <Convolutional Simplex Projection Network for Weakly Supe ...
- 论文阅读:EGNet: Edge Guidance Network for Salient Object Detection
论文地址:http://openaccess.thecvf.com/content_ICCV_2019/papers/Zhao_EGNet_Edge_Guidance_Network_for_Sali ...
- 论文阅读:Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs(2019 ACL)
基于Attention的知识图谱关系预测 论文地址 Abstract 关于知识库完成的研究(也称为关系预测)的任务越来越受关注.多项最新研究表明,基于卷积神经网络(CNN)的模型会生成更丰富,更具表达 ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- 【医学图像】3D Deep Leaky Noisy-or Network 论文阅读(转)
文章来源:https://blog.csdn.net/u013058162/article/details/80470426 3D Deep Leaky Noisy-or Network 论文阅读 原 ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
- [论文阅读笔记] Fast Network Embedding Enhancement via High Order Proximity Approximati
[论文阅读笔记] Fast Network Embedding Enhancement via High Order Proximity Approximation 本文结构 解决问题 主要贡献 主要 ...
- [论文阅读笔记] Community aware random walk for network embedding
[论文阅读笔记] Community aware random walk for network embedding 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 先前许多算法都 ...
- [论文阅读笔记] LouvainNE Hierarchical Louvain Method for High Quality and Scalable Network Embedding
[论文阅读笔记] LouvainNE: Hierarchical Louvain Method for High Quality and Scalable Network Embedding 本文结构 ...
随机推荐
- Docker笔记2:Docker 镜像仓库
Docker 镜像的官方仓库位于国外服务器上,在国内下载时比较慢,但是可以使用国内镜像市场的加速器(比如阿里云加速器)以提高拉取速度. Docker 官方的镜像市场,可以和 Gitlab 或 GitH ...
- nrf528xx bootloader 模块介绍
1. bootloader 的基本功能: 启动应用 几个应用之间切换 初始化外设 nordic nrf52xxx的bootloader主要功能用来做DFU, 可以通过HCI, UART 或BLE通信的 ...
- 第一个月多测师讲解__项目讲解以及注意事项(肖sir)
一.目的讲解流程:(讲述业务时长10-15分钟为宜)1.自我介绍礼貌用语,姓名,籍贯,学校,个人技能,经验,表现,兴趣爱好等 ,1分钟 ,谢谢2.介绍项目的名字 ,项目的背景,(涉及什么架构)3.对项 ...
- 面试一个百度T7程序员,一道简单的题没答上来!网友却都在吐槽面试官!
程序员面试时都考些什么? 一个面试官得意洋洋地说自己面了一个百度T7,出了一道coding题,结果对方连最长上升子序列都写不出来. 楼主本想嘲弄一下百度T7的代码水平低,没想到网友们炸开了锅,纷纷 ...
- CSP-S2020AFO记
2020-10.11 考初赛辣. 选择题考了一堆时间复杂度,一个不会(卒) 我寻思这01背包哪里能用贪心? 啊,这,这,这手写快排竟如此简单,手写取Max,手写队列,两个字符串颠来倒去,竟活到爆! 震 ...
- linux(centos8):firewalld对于请求会选择哪个zone处理?
一,firewalld对一个请求会适用哪个zone? 当接收到一个请求时,firewalld具体使用哪个zone? firewalld是通过三个步骤来判断的: source,即:源地址 interfa ...
- matplotlib直方图
import matplotlib.pyplot as plt import matplotlib as mpl from matplotlib.font_manager import FontPro ...
- vue中上拉加载数据的实现
获取屏幕高度来判断数据的加载 效果是这样的
- for循环结构中的3个表达式缺一不可?
do-while循环结构结束条件是while后的判断语句不成立for循环结构中的3个表达式都可以为空的.
- Vulkan Driver for VC4(Raspberry Pi 3b) base on mesa
这是一篇关于在raspberry Pi 3b上移植实现vulkan 驱动的文章. 经过一段时间的代码搬运,终于实现了零的突破,可以在树莓派3B上运行Vulkan triangle/texture.当然 ...