【补题记录】NOIp-提高/CSP-S 刷题记录
Intro
众所周知原题没写过是很吃亏的,突然发现自己许多联赛题未补,故开此坑。
在基本补完前会持续更新,希望在 NOIp2020 前填完。
虽然是“联赛题”,但不少题目还是富有思维含量的,值得一做。
关于为什么选 UOJ 测:UOJ 上有 Hack 机制,一些在官方数据下能过的错解会被卡掉,为了严谨一点还是在这里刷。
Contents
- 【NOIp2017】逛公园
最短路拓扑排序dp - 【NOIp2017】宝藏
状压 dp - 【NOIp2017】列队
线段树 - 【NOIp2018】赛道修建
二分答案贪心 - 【NOIp2018】保卫王国
树形 dp倍增 - 【CSP-S 2019】树的重心
树的重心 - 【CSP-S 2020】贪吃蛇
贪心链表
【NOIp2017】逛公园
发现数据范围中将“是否有 \(0\) 边”作为了一个特殊限制,那么自然地去想:两者有什么区别?如果存在一个 \(0\) 环,那么就可能在这上面走任意圈,从而答案为 \(-1\)。反之,合法路径条数就必然有限,因此我们不妨先将 \(0\) 环判掉。接下来的做法参考了 万弘 的做法,因为这是为数不多的正确解法。
首先,我们需要确定每个点是否能被一条合法路径经过。记 \(\text{dist}_1(x),\text{dist}_n(x)\) 分别表示从 \(1\) 到顶点 \(x\)、从 \(x\) 到终点 \(n\) 的最短路径长。那么 \(x\) 这个点可以被经过当且仅当 \(\text{dist}_1(x)+\text{dist}_n(x)\le \text{dist}_1(n)+k\)。
其次,还得确定每个点是否处于一个 \(0\) 环内。考虑将所有边长为 \(0\) 的边挑出来重建图,并对重构图上所有点进行标记,\(\text{side}_0(x)=1\) 说明顶点 \(x\) 在重构图上。若我们除去所有通过 \(0\) 边到达 \(0\) 环的、以及 \(0\) 环通过 \(0\) 边到达此处的这些点,余下的就是 \(0\) 环上的点。具体的,我们对重构图以及其反图都跑一边拓扑排序,若 \(x\) 在拓扑排序的过程中成功出队,那么 \(\text{vis}_1(x)=1\) 或 \(\text{vis}_2(x)=1\)。最后如果 \(x\) 满足 \(\text{side}_0(x)=1\land \text{vis}_1(x)=0\land \text{vis}_2(x)=0\) 那么它就在 \(0\) 环上。
若存在一个 \(x\) 同时满足上述两个条件,那么答案为 \(-1\)。
接下来计算答案。从 \(k\) 入手,考虑这样一个 dp:\(f(x, j)\) 表示到达结点 \(x\),所有满足长度 \(= \text{dist}_1(x)+j\) 的路径条数。答案即为 \(\sum_{j=0}^k f(n, j)\)。
对于一条边 \((u, v, w)\),对于一个 \(j\in[0, k]\),考虑当前路径长为 \(\text{dist}_1(x)+j\),那么走了这条边后到 \(y\) 的路径长即为 \(\text{dist}_1(x)+j+w\)。于是转移为:
\]
还有一个问题,就是 dp 的顺序。如果没有 \(0\) 边那么可以直接按 \(\text{dist}_1\) 值从小到大,加上 \(0\) 边的话,顺序按最短距离肯定没问题,但是由 \(0\) 边连接的两点 \(\text{dist}_1\) 值都是一样的,那么就按正的重构图的拓扑序作为第二关键字排序即可,保证图中“在后面”的点后转移。
参考代码:https://uoj.ac/submission/439360
【NOIp2017】宝藏
看到 \(n\le 12\) 的数据范围,考虑爆搜或状压 dp。这里提供状压 dp 的写法。
如何设计状态?首先代价会与到起点的距离有关,其次肯定需要知道开发的道路的端点,还有就是从这个端点出去打通的点的集合。于是设 \(f(i, j, S)\) 为当前在顶点 \(j\),至起点距离为 \(i\),要打通点集 \(S\) 的最小代价。注意这里 \(j\notin S\)。
如何转移?这里放一张图:
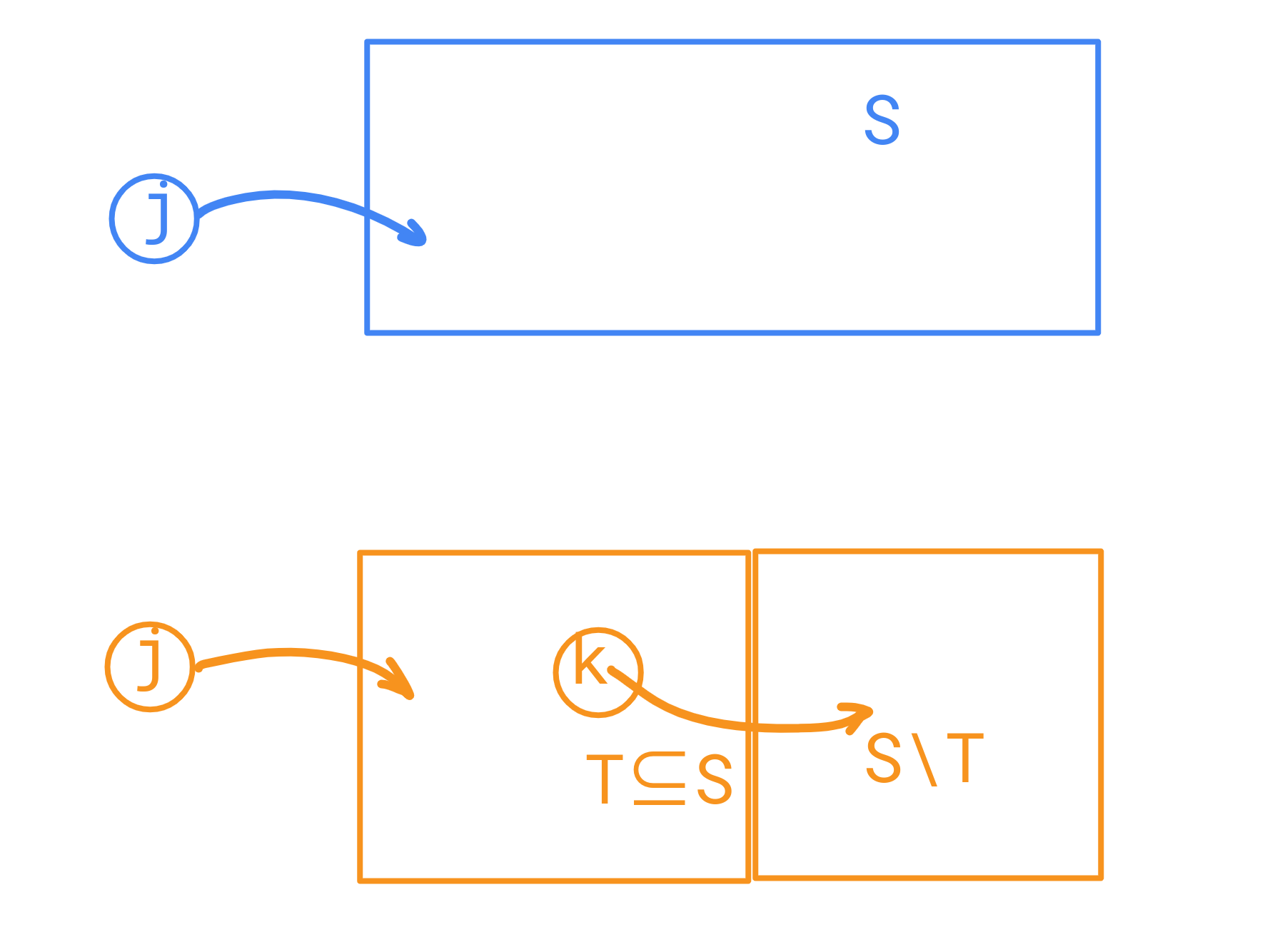
其中 \(k\) 为另一个与 \(j\) 相邻的顶点。我们发现集合 \(S\) 可以被拆成两个集合 \(T, S\setminus T\quad (T\subseteq S)\) ,分别由 \(k, j\) 两点打通。
那么可以枚举 \(S\) 的子集 \(T\),然后将 \(T\) 及 \(S\) 和 \(T\) 的差集的答案合并,并对 \(f(i, j, S)\) 更新。
记 \(d(j, k)\) 为 \(j, k\) 两顶点间的边长,那么由于 \(j\) 到起点距离为 \(i\),显然 \(k\) 就是 \(i+1\),于是这条边贡献就是 \(d(j, k)\times(i+1)\)。状态转移方程:
\]
边界:\(\forall i\in[0, n),\ j\in[1, n],\ f(n-1, j, \varnothing)\gets 0\)。答案:\(\min_{j\in[1, n]} f(0,j,U \setminus\{j\})\),\(U=\{1, 2, \cdots, n\}\) 为全集。
考虑计算这玩意的时间复杂度:枚举 \(i, j\) 为 \(O(n^2)\),枚举所有集合的子集为 \(O(3^n)\),再枚举 \(j\) 的相邻点为 \(O(n)\),所以总复杂度为 \(O(n^3\times 3^n)\)。 然而被爆搜打爆了。
参考代码:https://uoj.ac/submission/439548
【NOIp2017】列队
作为抛砖引玉,我们思考一下 \(x_i=1\) 的部分分做法:实现每次在一段序列中抽出一个树,然后加到末尾。这个平衡树一上就是裸题,但估计比较卡常(考场上写这种东西也并不是什么明智的选择,除非打的很熟),于是考虑换个思路:线段树。
首先对区间 \([1, n+q]\) 开线段树,初始每个位置都是 \(1\)。当我们删去一个位置 \(x\) 的数字时,我们将它置为 \(0\)。但这样就无法保证每次置 \(0\) 的位置都是真正的位置,因为删去之后实际上后面是要前移的。所幸的是,真正的位置并不难找,就是第一个满足 \(1\sim k\) 前缀和 \(=x\) 的位置 \(k\),这个可以线段树上二分简单实现。复杂度 \(O(\log n)\) 一次。
再考虑拓展到 \(n\times m\) 的情况。注意到最后一列其实很特殊(可以自己手玩一下),考虑与每一行(除最后一个)分开维护。当一个位置 \((x, y)\) 被移到最后时,最后一列的第 \(x\) 个元素被加到第 \(x\) 行尾端,原先这个元素又被加到最后一列的尾端。如果还是用平衡树,那么可以分别维护每一行(除最后一个)以及最后一列,由于空间不够所以将连续一整段未改动过的缩成一个,这样空间是线性,时间 \(O(q\log q)\)。
但这玩意常数大而且任意写挂,我们尝试沿用上面线段树的思路。对于第 \(i\) 行,我们在上面操作时,变化的只有 \((i, 1)\to (i, m)\to (n, m)\) 这一整段。我们考虑将其展平成一整个数列。那么对于在这一行的所有操作,我们按编号顺序一个个计算出真实删除的列号 \(y^\prime\),这里可以用上面线段树的思路完成,预处理出所有询问的总耗时为 \(O(q\log n)\)。
注意到我们得到的真实列号 \(y^\prime\) 完全有可能会 \(\ge m\),那么说明删除的其实是原来的最后一列的位置,这些位置的元素经过前面的操作被推入了这一行中。值得一提的是,对于原先 \(y=m\) 的操作我们最好与其他的分开算,毕竟最后列的性质还是比较特殊,实现时只用一个 isLast 标记即可。
预处理出真实行号后,我们考虑按编号依次处理所有的操作。还是用线段树辅助,不过现在是维护最后一列的删除情况。对于一个 \(y^\prime < m\),说明删的就是原先就在本行内的元素,那么答案直接算就是 \((x-1)m+y^\prime\);反之若 \(y^\prime \ge m\),说明删的是最后一列中的元素,那么答案就是在第 \(x\) 行中,第 \(y^\prime-m+1\) 个由最后一列推入的元素,我们用 rec 存储这些元素。
不管我们删的是不是原先的最后一列,这一列都会在第 \(x\) 行被移除一个元素,这个元素要么是直接被移除的,要么就是前面行内有被删去的空位把它推入其中的。总之,我们先通过线段树获取第 \(x\) 个未被删去的位置,然后记对应位置上的值为 \(v\)。
如果 isLast = 1,那么答案就是 \(v\),否则这东西会被压入对应行内的 rec 中。最后把我们刚刚得到的答案放在最后一列尾部即可。
最后这样的时间复杂度为 \(O((n+q)\log n)\)。
参考代码:https://uoj.ac/submission/439373
【NOIp2018】赛道修建
“最小的长度的最大值”,提示很明显了多半会和二分答案扯上关系。在这里我们先二分出一个值 \(\text{mid}\),然后约定所有的赛道长度都不得小于这个 \(\text{mid}\),并在这个前提下使赛道数尽可能多。最后将这个尽可能多的赛道数与 \(m\) 比较即可。
现在的终点就是,如何尽量多地安排满足条件的赛道。原图是一颗树,那么考虑递归求解:当前到达顶点 \(x\)。子树 \(x\) 中所有的路径可能的情况可以分为两类:跨越子树根 \(x\) 或在子树 \(x\) 内部的。
其中内部的递归上来就完事了,关键是经过 \(x\) 的。首先要知道一个子结点有且只有一条延伸到 \(x\) 的路径,因为 \(x\to\) 子结点只有一条边,而一条边上不会有两个路径。然后我们会得到每个子结点延伸上来的路径长的可重集合,任选两个不同(值可以相同)的元素都可以拼成一条经过 \(x\) 路径。我们需要将这些路径尽可能拼接,同时还得上传一条未拼接的路径(当然也要尽可能大)作为上一级所用。
先考虑这样一个问题:如果我们为了最大化上传的路径,而使成功拼接的路径数减少了,这一切值得吗?不难发现上传路径的长度再大,也只可能得到 \(1\) 的贡献,但我们牺牲的拼接路径则必然使我们失去 \(1\) 的贡献。显然以配对数为第一关键字不会使结果变劣。
再考虑这样一个问题:我们需要将可重集合 \(S\) 中的元素尽可能配对,要求每一对元素两者之和必须 \(\ge\) 一个值 \(k\),我们如何最大化这个配对数?有显然的一点是,\(\forall x\in S\),与之配对的必然是 \(\max\limits_{y\in S,\ x+y\ge k}y\)。还有就是按什么顺序配对的问题,假设有两个元素 \(x, y\in S\) 且 \(x<y\),那么优先考虑那个呢?答案是考虑小的 \(x\),先考虑大的固然也能配对,但小的配对就可能失去机会,向上贡献也可能一次变劣。
总结一下上述的贪心思想:在最大化配对的前提下,上传最大未配对的路径。在实现的时候,最直观的方法是 std::multiset,总复杂度 \(O(n\log(\sum l)\log n)\)。
参考代码:https://uoj.ac/submission/439589
【NOIp2018】保卫王国
题目要求最小权覆盖集,那么 \(O(nm)\) 的暴力就是每个询问都做一次树形 dp。设 \(f(i, 0/1)\) 表示顶点 \(i\) 选或不选,子树 \(x\) 中的最小花费。状态转移如下:
f(i,0) = \sum_{j\in son(i)} f(j, 1) \\
f(i,1) = \sum_{j\in son(i)} \max(f(j,0),f(j,1))
\end{cases}
\]
考虑只修改一个点(type[2] = 1)的部分分。隔离出我们询问的 \(b\) 顶点之后,整棵树会被分为两部分:子树 \(b\) 以及 \(b\) 父亲方向的顶点。于是我们再设计一种 dp,相当于把 \(f\) 倒过来已应付父亲方向的那部分:\(g(i, 0/1)\) 表示顶点 \(i\) 选或不选,整棵树除去子树 \(i\)(包括 \(i\))部分的贡献。那么在计算出 \(f\) 之后我们也不难推出 \(g\):
\begin{cases}
g(j,0)=f(i,1)+g(i,1)-\min(f(j,0),f(j,1))\\
g(j,1)=\min(f(i,0)+g(i,0)-f(j,0),\ f(i,1)+g(i,1)-\min(f(j,0),f(j,1)))
\end{cases}
\]
相当于在 \(j\) 的父亲 \(i\) 整棵树的影响的基础上,依据 \(f\) 的递推式撤销的 \(j\) 的影响。
最后思考正解。为什么询问是两个而不是 \(k\) 个?询问一个是一个顶点,那么两个就能构成一条路径。在观察一下我们 dp 的过程,发现一次询问虽然会使原来的 dp 数组改变,但变的范围仍是有限的。以 \(f\) 为例,改变的范围如下图:

其中 dp 值被修改的只有蓝色部分,而橙色的子树全部都可以直接沿用原先的 dp 值。如果我们就这样直接暴力修改这两条路径,那么复杂度为 \(O(mH)\),其中 \(H\) 为树高,可以过(type[1] = B)的数据点。
现在要做的就是加速链上的转移了。回顾我们求 LCA 的一个暴力算法:先将深度大的顶点跳到与另一个顶点深度相同,然后两点一起往上跳。当时的处境和我们现在很像,那个问题的解决方案之一是倍增加速,现在这里我们也可以尝试一下。
倍增 LCA 预处理了 \(\text{anc}\) 数组,\(\text{anc}_{i, j}\) 表示顶点 \(i\) 的 \(2^j\) 级祖先。不过这里还得多加一个 \(h(i,j,p,q)\) 表示顶点 \(i\) 及其 \(2^j\) 级祖先的选择状态分别为 \(p, q(\in\{0, 1\})\) 时,子树 \(\text{anc}_{i, j}\) 减去子树 \(i\) 部分的最小花费,用于倍增时快速在整条路径上的转移。
怎么预处理 \(h\) 呢?首先是 \(j=0\) 的所有情况需要先算(同 \(g\) 一样在 \(f\) 基础上挖去子树 \(i\)):
h(i,0,0,0) = \infty \\
h(i,0,0,1) = f(\text{anc}_{i,0},1)-\min(f(i,0),f(i,1)) \\
h(i,0,1,0) = f(\text{anc}_{i,0},0)-f(i,1) \\
h(i,0,1,1) = f(\text{anc}_{i,0},1)-\min(f(i,0),f(i,1)) \\
\end{cases}
\]
转移就简单了,每次我们就只需要把两段东西无脑拼接就行:
\]
最后来看询问:如何利用上面这些信息求解?我们设 \(\text{val}_a(0/1),\text{val}_b(0/1)\) 分别为 \(a,b\) 两部分的答案,并且在倍增的过程更新它们。开始先把深度大的向上跳,跳到深度相同时就一起向上跳,最后在两点的 LCA 处汇总。汇总时也是像上面一样,在 \(f(\text{lca}(a,b),0/1)\) 将 \(f\) 递推式中子树 \(a,b\) 的那部分挖掉再换上 \(\text{val}\),别忘了最后加上 \(g(\text{lca}(a, b),0/1)\)。
这样的时间复杂度为 \(O((n+q)\log n)\),空间 \(O(n\log n)\)。
参考代码:https://uoj.ac/submission/439748
【CSP-S 2019】树的重心
神题,具体见:
https://www.cnblogs.com/-Wallace-/p/14044869.html
【CSP-S 2020】贪吃蛇
考虑当前最强的蛇选择不吃的条件:
- 如果这条蛇吃之后,贪心地想:它不会被垫底,那么显然下一次它没有被吃的危险,必然不会停下来;
- 如果吃了之后会垫底,那么看着办——
设当前最强的、下一轮、下下一轮最强的……分别为 \(x_1, x_2, x_3, \cdots\)。对于 \(i\) 轮中最强的 \(x_i\) ,我们有:
- 如果当前吃了,但是由于后面的蛇都足够聪明,如果下一条 \(x_{i+1}\) 因为需要保命而不吃,那么它就不会有危险,于是这一步 \(x_i\) 是可以吃的;反之,那么现在吃了之后必死无疑,于是不吃。
- 得出当前 \(x_i\) 到底吃不吃的结果之后,它前一轮就可以根据这个结果进行决策;
- 要想得出当前的决策,还得看下一轮的决策。
- 如果下一轮 \(x_{i+1}\) 会选择吃,那么 \(x_i\) 为了保命必然不会吃,同理 \(x_{i-1}\) 吃了不会有问题会选择吃,\(x_{i-2}\) 不会吃……
发现这很想一个递归的过程,而本人也是用递归实现的。
但递归总有一个终止条件,那么在这里很显然的一点就是在剩两条蛇时的特判。
如果仅仅止步于此,那么答案就是最后蛇的个数在加上个数的奇偶性的影响即可。但这样是错误的,因为在上述递归的过程中完全可能出现最强蛇突然又发现自己吃了不垫底了,那么它必然直接吃。这时候就不需要继续递归了,已经可以确定上一条蛇吃不得了。
综上即为算法的大致过程,小结一下:
- 阶段一:吃了不垫底,不吃白不吃;
- 阶段二:吃了会垫底,先看看再吃。
这两个阶段都可以递归实现而且非常方便。
不过现在还有一个问题:如果维护蛇的集合?我们需要快速找到最大的、最小的和次小的蛇,那么不难想到 std::set。但这样复杂度为 \(O(Tn\log n)\),只有 70 pts.。但题目里面给定的序列是递增的,于是直接考虑链表,头、尾分别就是两个最值。
但是中间还设计到插入,怎么搞?观察到每次插入的蛇都不会比上一个大,那么就维护一个插入的位置,每次往前移即可。这样的复杂度为 \(O(n)\)。还有一个烂大街的双端队列写法这里不再赘述。
参考代码(std::list):https://uoj.ac/submission/439319
参考代码(手写链表):https://uoj.ac/submission/439416
【补题记录】NOIp-提高/CSP-S 刷题记录的更多相关文章
- 【NOIP2015模拟11.4】JZOJ8月6日提高组T1 刷题计划
[NOIP2015模拟11.4]JZOJ8月6日提高组T1 刷题计划 题目 题解 题意 有\(n\)道题,编号为1~\(n\) 给出\(m\)次操作 每次操作有3种类型 1 \(x\) 表示交了\(A ...
- LeetCode每日一题打卡组队监督!刷题群!
近 2000 人已经加入共同刷题啦! 群友每天都会在群里给大家讲解算法题 每周日「负雪明烛」组织直播讲题 我相信来看我博客的大部分人都是通过LeetCode刷题过来的.最近发现LeetCode中文网站 ...
- NOIP提高组历年真题题解
2018 铺设道路 差分水题,推一下结论就好了. #include<cstdio> #include<algorithm> using namespace std; ],d[] ...
- Leetcode刷题记录(python3)
Leetcode刷题记录(python3) 顺序刷题 1~5 ---1.两数之和 ---2.两数相加 ---3. 无重复字符的最长子串 ---4.寻找两个有序数组的中位数 ---5.最长回文子串 6- ...
- LeetCode刷题专栏第一篇--思维导图&时间安排
昨天是元宵节,过完元宵节相当于这个年正式过完了.不知道大家有没有投入继续投入紧张的学习工作中.年前我想开一个Leetcode刷题专栏,于是发了一个投票想了解大家的需求征集意见.投票于2019年2月1日 ...
- 【BZOJ-4590】自动刷题机 二分 + 判定
4590: [Shoi2015]自动刷题机 Time Limit: 10 Sec Memory Limit: 256 MBSubmit: 156 Solved: 63[Submit][Status ...
- BZOJ4590 自动刷题机
Description 曾经发明了信号增幅仪的发明家SHTSC又公开了他的新发明:自动刷题机--一种可以自动AC题目的神秘装置.自动 刷题机刷题的方式非常简单:首先会瞬间得出题目的正确做法,然后开始写 ...
- Leetcode按Tag刷题
按照Leetcode的Tag来刷题,从easy到hard刷题 关于如何让Leetcode按难易程度排序,可按以下步骤: 1. 进入Leetcode后,点击code 2.点击code后,可查看所有题目, ...
- BZOJ_4590_[Shoi2015]自动刷题机_二分答案
BZOJ_4590_[Shoi2015]自动刷题机_二分答案 Description 曾经发明了信号增幅仪的发明家SHTSC又公开了他的新发明:自动刷题机--一种可以自动AC题目的神秘装置.自动 刷题 ...
随机推荐
- linux全局和个人配置文件说明
1.bash配置文件: 1).全局(bash的配置文件) 有 /etc/profile /etc/profile.d/* 与 /etc/bashrc 其实都是bash这个程序启动的时候会读取配置 ...
- ntpd配置时间同步服务器
修改同步服务器的配置文件/etc/ntp.conf ,删除所有的内容,添加 restrict default nomodify server 127.127.1.0 # local clock fud ...
- Spring Boot优雅地处理404异常
背景 在使用SpringBoot的过程中,你肯定遇到过404错误.比如下面的代码: @RestController @RequestMapping(value = "/hello" ...
- 每天一个linux命令之stat
[Linux]Linux下使用stat命令所显示出来的三个时间 转 https://blog.csdn.net/pointer_y/article/details/54347968 在linux系统下 ...
- 卷积神经网络图像纹理合成 Texture Synthesis Using Convolutional Neural Networks
代码实现 概述 这是关于Texture Synthesis Using Convolutional Neural Networks论文的tensorflow2.0代码实现,使用keras预训练的VGG ...
- 循序渐进VUE+Element 前端应用开发(27)--- 数据表的动态表单设计和数据存储
在我们一些系统里面,有时候会需要一些让用户自定义的数据信息,一般这些可以使用扩展JSON进行存储,不过每个业务表的显示项目可能不一样,因此需要根据不同的表单进行设计,然后进行对应的数据存储.本篇随笔结 ...
- laravel 验证器使用
1.前后端不分离 (form表单提交) 控制器定义验证规则 <?php namespace App\Http\Controllers\Admin; use Illuminate\Http\Req ...
- 在Jenkins的帮助下让我们的应用CI与CD
上图三位大家应该很熟悉吧,借助这三者可以让我们的服务在Linux环境下持续集成.容器中持续部署. 本篇博客的项目是core webapi, .NET 5.0 在11号已经正式发布了,你们的项目都升级了 ...
- jenkins、gitlab配置CI/CD
1. 在gitlab中创建好项目(gitlab的安装和基本使用这里不在说明) 2. 创建jenkins任务 jenkins 需要几个插件请先安装好 - Git plugin - GitLab Plug ...
- 网络管理监视很重要!学编程的你知道哪些不错的网络监控工具?2020 最好的Linux网络监控工具分享给你
以下文章来源于新钛云服 翻译:侯明明 前言 虽然这个清单包含开源的和闭源的产品,但它着重于介绍基于 Linux 的网络监控工具, 少数常用工具只能在 Windows,Pandora 或其他系统上运行, ...