机器学习实战基础(十四):sklearn中的数据预处理和特征工程(七)特征选择 之 Filter过滤法(一) 方差过滤
Filter过滤法
过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法。它是根据各种统计检验中的分数以及相关性的各项指标来选择特征
1 方差过滤
1.1 VarianceThreshold
这是通过特征本身的方差来筛选特征的类。比如一个特征本身的方差很小,就表示样本在这个特征上基本没有差异,可能特征中的大多数值都一样,甚至整个特征的取值都相同,那这个特征对于样本区分没有什么作用。所以无论接下来的特征工程要做什么,都要优先消除方差为0的特征。
VarianceThreshold有重要参数threshold,表示方差的阈值,表示舍弃所有方差小于threshold的特征,不填默认为0,即删除所有的记录都相同的特征。
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold() #实例化,不填参数默认方差为0
X_var0 = selector.fit_transform(X) #获取删除不合格特征之后的新特征矩阵 #也可以直接写成 X = VairanceThreshold().fit_transform(X) X_var0.shape
可以看见,我们已经删除了方差为0的特征,但是依然剩下了708多个特征,明显还需要进一步的特征选择。然而,如果我们知道我们需要多少个特征,方差也可以帮助我们将特征选择一步到位。比如说,我们希望留下一半的特征,那可以设定一个让特征总数减半的方差阈值,只要找到特征方差的中位数,再将这个中位数作为参数
threshold的值输入就好了:
import numpy as np
X_fsvar = VarianceThreshold(np.median(X.var().values)).fit_transform(X) X.var().values np.median(X.var().values) X_fsvar.shape
当特征是二分类时,特征的取值就是伯努利随机变量,这些变量的方差可以计算为:
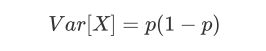
其中X是特征矩阵,p是二分类特征中的一类在这个特征中所占的概率
#若特征是伯努利随机变量,假设p=0.8,即二分类特征中某种分类占到80%以上的时候删除特征
X_bvar = VarianceThreshold(.8 * (1 - .8)).fit_transform(X)
X_bvar.shape
1.2 方差过滤对模型的影响
我们这样做了以后,对模型效果会有怎样的影响呢?在这里,我为大家准备了KNN和随机森林分别在方差过滤前和方差过滤后运行的效果和运行时间的对比。
KNN是K近邻算法中的分类算法,其原理非常简单,是利用每个样本到其他样本点的距离来判断每个样本点的相似度,然后对样本进行分类。
KNN必须遍历每个特征和每个样本,因而特征越多,KNN的计算也就会越缓慢。由于这一段代码对比运行时间过长,所以我为大家贴出了代码和结果。
1. 导入模块并准备数据
#KNN vs 随机森林在不同方差过滤效果下的对比
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.model_selection import cross_val_score
import numpy as np X = data.iloc[:,1:]
y = data.iloc[:,0] X_fsvar = VarianceThreshold(np.median(X.var().values)).fit_transform(X)
我们从模块neighbors导入KNeighborsClassfier缩写为KNN,导入随机森林缩写为RFC,然后导入交叉验证模块和
numpy。其中未过滤的数据是X和y,使用中位数过滤后的数据是X_fsvar,都是我们之前已经运行过的代码。
2. KNN方差过滤前
#======【TIME WARNING:35mins +】======#
cross_val_score(KNN(),X,y,cv=5).mean() #python中的魔法命令,可以直接使用%%timeit来计算运行这个cell中的代码所需的时间
#为了计算所需的时间,需要将这个cell中的代码运行很多次(通常是7次)后求平均值,因此运行%%timeit的时间会
远远超过cell中的代码单独运行的时间 #======【TIME WARNING:4 hours】======#
%%timeit
cross_val_score(KNN(),X,y,cv=5).mean()

3. KNN方差过滤后
#======【TIME WARNING:20 mins+】======#
cross_val_score(KNN(),X_fsvar,y,cv=5).mean() #======【TIME WARNING:2 hours】======#
%%timeit
cross_val_score(KNN(),X,y,cv=5).mean()
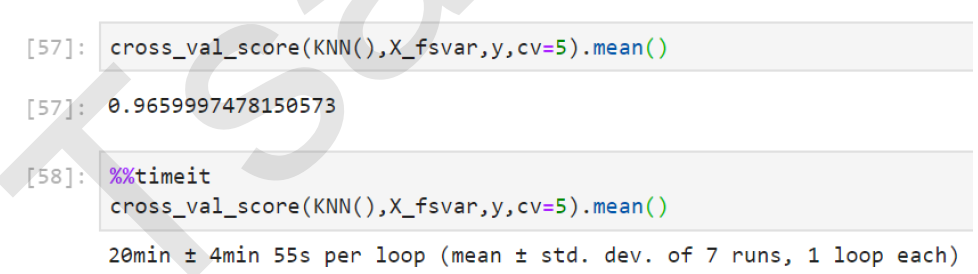
可以看出,对于KNN,过滤后的效果十分明显:准确率稍有提升,但平均运行时间减少了10分钟,特征选择过后算法的效率上升了1/3。那随机森林又如何呢?
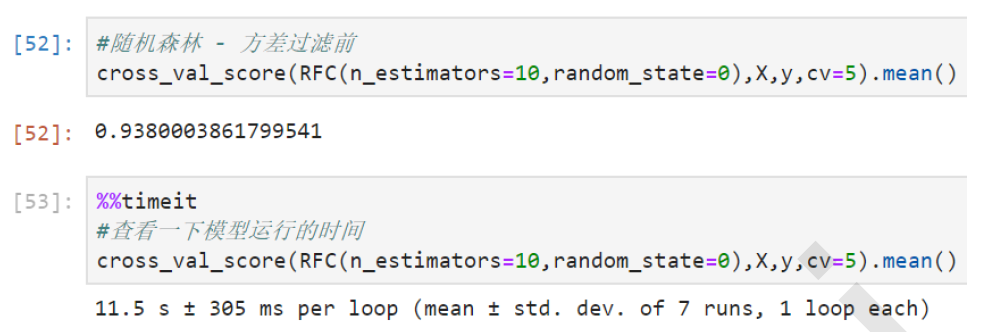
4. 随机森林方差过滤前
cross_val_score(RFC(n_estimators=10,random_state=0),X,y,cv=5).mean()
5. 随机森林方差过滤后
cross_val_score(RFC(n_estimators=10,random_state=0),X_fsvar,y,cv=5).mean()
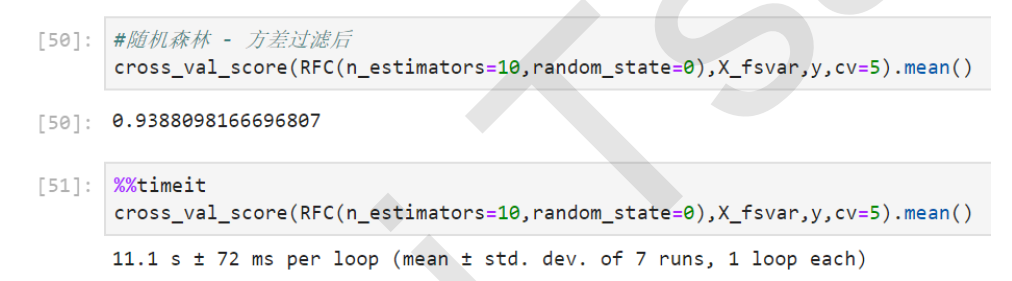
首先可以观察到的是,随机森林的准确率略逊于KNN,但运行时间却连KNN的1%都不到,只需要十几秒钟。
其次,方差过滤后,随机森林的准确率也微弱上升,但运行时间却几乎是没什么变化,依然是11秒钟。
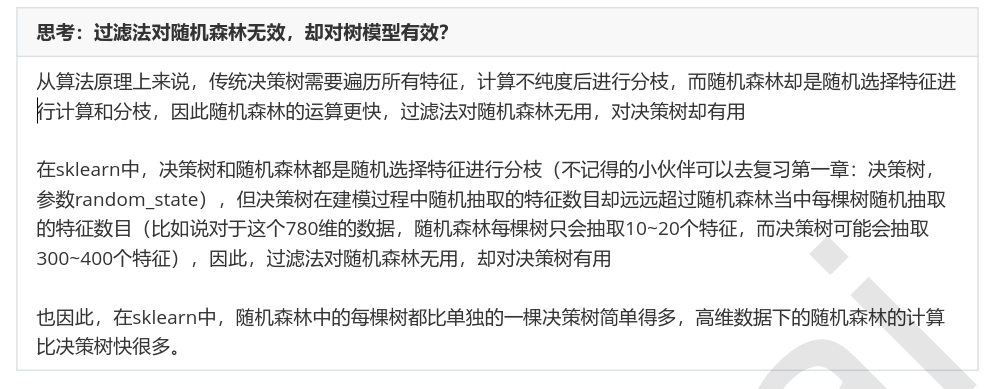
为什么随机森林运行如此之快?为什么方差过滤对随机森林没很大的有影响?
这是由于两种算法的原理中涉及到的计算量不同。最近邻算法KNN,单棵决策树,支持向量机SVM,神经网络,回归算法,都需要遍历特征或升维来进行运算,所以他们本身的运算量就很大,需要的时间就很长,因此方差过滤这样的特征选择对他们来说就尤为重要。
但对于不需要遍历特征的算法,比如随机森林,它随机选取特征进行分枝,本身运算就非常快速,因此特征选择对它来说效果平平。这其实很容易理解,无论过滤法如何降低特征的数量,随机森林也只会选取固定数量的特征来建模;而最近邻算法就不同了,特征越少,距离计算的维度就越少,模型明显会随着特征的减少变得轻量。
因此,过滤法的主要对象是:需要遍历特征或升维的算法们,而过滤法的主要目的是:在维持算法表现的前提下,帮助算法们降低计算成本。
对受影响的算法来说,我们可以将方差过滤的影响总结如下:

在我们的对比当中,我们使用的方差阈值是特征方差的中位数,因此属于阈值比较大,过滤掉的特征比较多的情况。我们可以观察到,无论是KNN还是随机森林,在过滤掉一半特征之后,模型的精确度都上升了。
这说明被我们过滤掉的特征在当前随机模式(random_state = 0)下大部分是噪音。那我们就可以保留这个去掉了一半特征的数据,来为之后的特征选择做准备。当然,如果过滤之后模型的效果反而变差了,我们就可以认为,被我们过滤掉的特征中有很多都有有效特征,那我们就放弃过滤,使用其他手段来进行特征选择。

1.3 选取超参数threshold
我们怎样知道,方差过滤掉的到底时噪音还是有效特征呢?过滤后模型到底会变好还是会变坏呢?
答案是:每个数据集不一样,只能自己去尝试。这里的方差阈值,其实相当于是一个超参数,要选定最优的超参数,我们可以画学习曲线,找模型效果最好的点。但现实中,我们往往不会这样去做,因为这样会耗费大量的时间。我们只会使用阈值为0或者阈值很小的方差过滤,来为我们优先消除一些明显用不到的特征,然后我们会选择更优的特征选择方法继续削减特征数量。
机器学习实战基础(十四):sklearn中的数据预处理和特征工程(七)特征选择 之 Filter过滤法(一) 方差过滤的更多相关文章
- 机器学习实战基础(八):sklearn中的数据预处理和特征工程(一)简介
1 简介 数据挖掘的五大流程: 1. 获取数据 2. 数据预处理 数据预处理是从数据中检测,纠正或删除损坏,不准确或不适用于模型的记录的过程 可能面对的问题有:数据类型不同,比如有的是文字,有的是数字 ...
- sklearn中的数据预处理和特征工程
小伙伴们大家好~o( ̄▽ ̄)ブ,沉寂了这么久我又出来啦,这次先不翻译优质的文章了,这次我们回到Python中的机器学习,看一下Sklearn中的数据预处理和特征工程,老规矩还是先强调一下我的开发环境是 ...
- 机器学习实战基础(十):sklearn中的数据预处理和特征工程(三) 数据预处理 Preprocessing & Impute 之 缺失值
缺失值 机器学习和数据挖掘中所使用的数据,永远不可能是完美的.很多特征,对于分析和建模来说意义非凡,但对于实际收集数据的人却不是如此,因此数据挖掘之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的 ...
- 机器学习实战基础(十八):sklearn中的数据预处理和特征工程(十一)特征选择 之 Wrapper包装法
Wrapper包装法 包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择.但不 ...
- 机器学习实战基础(十七):sklearn中的数据预处理和特征工程(十)特征选择 之 Embedded嵌入法
Embedded嵌入法 嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行.在使用嵌入法时,我们先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大 ...
- 机器学习实战基础(十一):sklearn中的数据预处理和特征工程(四) 数据预处理 Preprocessing & Impute 之 处理分类特征:编码与哑变量
处理分类特征:编码与哑变量 在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的 ...
- 机器学习实战基础(十五):sklearn中的数据预处理和特征工程(八)特征选择 之 Filter过滤法(二) 相关性过滤
相关性过滤 方差挑选完毕之后,我们就要考虑下一个问题:相关性了. 我们希望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息.如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会 ...
- 机器学习实战基础(九):sklearn中的数据预处理和特征工程(二) 数据预处理 Preprocessing & Impute 之 数据无量纲化
1 数据无量纲化 在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”.譬如梯度和矩阵为核心的算法中,譬如逻辑回 ...
- 机器学习实战基础(十三):sklearn中的数据预处理和特征工程(六)特征选择 feature_selection 简介
当数据预处理完成后,我们就要开始进行特征工程了. 在做特征选择之前,有三件非常重要的事:跟数据提供者开会!跟数据提供者开会!跟数据提供者开会!一定要抓住给你提供数据的人,尤其是理解业务和数据含义的人, ...
随机推荐
- @atcoder - AGC024F@ Simple Subsequence Problem
目录 @description@ @solution@ @accepted code@ @details@ @description@ 给定由若干长度 <= N 的 01 字符串组成的集合 S. ...
- TCP和UDP的Socket编程实验
Linux Socket 函数库是从 Berkeley 大学开发的 BSD UNIX 系统中移植过来的.BSD Socket 接口是在众多 Unix 系统中被广泛支持的 TCP/IP 通信接口,Lin ...
- Android学习笔记尺寸资源
尺寸资源语法 dp:设备独立资源像素 会根据设备匹配大小 一般用于设置边距和组件大小 sp : 可伸缩像素 根据用户手机字体大小首选项进行缩放 使用尺寸资源 定义尺寸资源 dimens <?xm ...
- fork,vfork和clone底层实现
分类: LINUX2011-10-13 09:33 1116人阅读 评论(0) 收藏 举报 structdstsignalthreadnulldomain fork,vfork,clone都是linu ...
- python中那些鲜为人知的功能特性
经常逛GitHub的可能关注一个牛叉的项目,叫 What the f*ck Python! 这个项目列出了几乎所有python中那些鲜为人知的功能特性,有些功能第一次遇见时,你会冒出 what the ...
- Andrew Ng - 深度学习工程师 - Part 1. 神经网络和深度学习(Week 3. 浅层神经网络)
=================第3周 浅层神经网络=============== ===3..1 神经网络概览=== ===3.2 神经网络表示=== ===3.3 计算神经网络的输出== ...
- Redis快照原理详解
本文对Redis快照的实现过程进行介绍,了解Redis快照实现过程对Redis管理很有帮助. Redis默认会将快照文件存储在Redis当前进程的工作目录中的dump.rdb文件中,可以通过配置dir ...
- Maven的pom文件依赖提示 ojdbc6 Missing artifact,需要手动下载并导入maven参考
eg: 需要 ojdbc6.jar 的下载地址 https://www.oracle.com/database/technologies/jdbcdriver-ucp-downloads.html c ...
- 如何修改git commit的author信息
本地有多个git账号时,容易发生忘记设置项目默认账号,最后以全局账号提交的情况,其实对代码本身并无影响,只是提交记录里显示的是别的名字稍显别扭. 举个例子: 查看提交日志,假设以a(a@email. ...
- springboot自动装配原理
最近开始学习spring源码,看各种文章的时候看到了springboot自动装配实现原理.用自己的话简单概括下. 首先打开一个基本的springboot项目,点进去@SpringBootApplica ...