PyTorch入门-CIFAR10图像分类
CIFAR10数据集下载
CIFAR10数据集包含10个类别,图像尺寸为 3×32×32

官方下载地址很慢,这里给一个百度云:
下载后在项目目录新建一个data目录解压进去
导入相关包
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import time
import copy
MINI_BATCH = 8 # 数据集的图片数量很大,无法一次性加载所有数据,所以一次加载一个mini-batch的图片
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') # GPU可用则使用GPU
使用torchvision加载并且归一化训练和测试数据集
CIFAR10数据集的输出是范围在[0,1]之间的PILImage,我们将它转换并归一化范围在[-1,1]之间的Tensor:
# ToTensor(): 将ndarrray格式的图像转换为Tensor张量
# Normalize(mean, std) mean:每个通道颜色平均值,这里的平均值为0.5,私人数据集自己计算;std:每个通道颜色标准偏差,(原始数据 - mean) / std 得到归一化后的数据
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
数据加载器:
# 训练数据加载
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=False, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=MINI_BATCH, shuffle=True, num_workers=4)
# 测试数据加载
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=MINI_BATCH, shuffle=False, num_workers=4)
定义卷积神经网络
我们实现一个简单的神经网络 LeNet-5来进行分类:
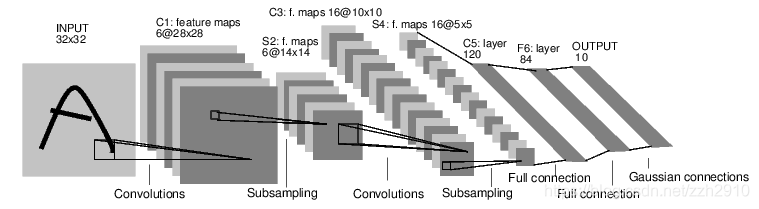
这个网络具有两个卷积层,两个池化层,三个全连接层,原网络用于手写数字识别,输入为灰度图,这里我们输入图像是RGB所以修改输入数据为 3×32×32 的Tensorr数据,输出数据维度为 1*10 ,表示图片属于10个类别的概率,图中数据维度变化说明:
- 二维卷积层输出大小 out = (in - F + 2P) / S + 1 ,其中:
F: 卷积核大小 F×F
P: Padding,默认为0
S: 步长Stride,默认为1
如图中第一层卷积层 (32 - 5) / 1 + 1 = 28 - 池化层输出大小 out = (in - F) / S + 1 ,其中:
F: 池化窗口大小 F×F
S: 池化窗口移动的步长Stride,默认和池化窗口维度相同
如图中第二层池化层 (28 - 2) / 2 + 1 = 14
这部分可以写成一个独立的文件,在训练代码中引入此文件中的网络结构:
# net.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 卷积层:3通道到6通道,卷积5*5
self.conv2 = nn.Conv2d(6, 16, 5) # 卷积层:6通道到16通道,卷积5*5
self.pool = nn.MaxPool2d(2, 2) # 池化层,在2*2窗口上进行下采样
# 三个全连接层 :16*5*5 -> 120 -> 84 -> 10
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
# 定义数据流向
def forward(self, x):
x = F.relu(self.conv1(x)) # F.relu 是一个常用的激活函数
x = self.pool(x)
x = F.relu(self.conv2(x))
x = self.pool(x)
x = x.view(-1, 16 * 5 * 5) # 变换数据维度为 1*(16*5*5),-1表示根据后面推测
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
定义一个通用的训练函数,得到最优参数
def train(model, criterion, optimizer, epochs):
since = time.time()
best_acc = 0.0 # 记录模型测试时的最高准确率
best_model_wts = copy.deepcopy(model.state_dict()) # 记录模型测试出的最佳参数
for epoch in range(epochs):
print('-' * 30)
print('Epoch {}/{}'.format(epoch+1, epochs))
# 训练模型
running_loss = 0.0
for i, data in enumerate(trainloader):
inputs, labels = data
inputs, labels = inputs.to(DEVICE), labels.to(DEVICE)
# 前向传播,计算损失
outputs = net(inputs)
loss = criterion(outputs, labels)
# 反向传播+优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
# 每1000批图片打印训练数据
if (i != 0) and (i % 1000 == 0):
print('step: {:d}, loss: {:.3f}'.format(i, running_loss/1000))
running_loss = 0.0
# 每个epoch以测试数据的整体准确率为标准测试一下模型
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.to(DEVICE), labels.to(DEVICE)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = correct / total
if acc > best_acc: # 当前准确率更高时更新
best_acc = acc
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print('-' * 30)
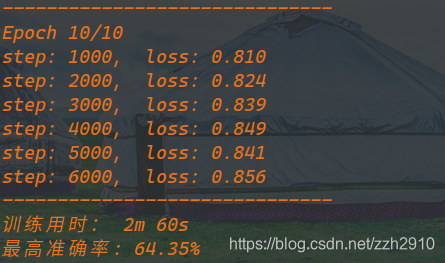
print('训练用时: {:.0f}m {:.0f}s'.format(time_elapsed//60, time_elapsed%60))
print('最高准确率: {}%'.format(100 * best_acc))
# 返回测试出的最佳模型
model.load_state_dict(best_model_wts)
return model
定义好损失函数和优化器后训练模型
from net import Net
net = Net()
net.to(DEVICE)
# 使用分类交叉熵 Cross-Entropy 作损失函数,动量SGD做优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 训练10个epoch
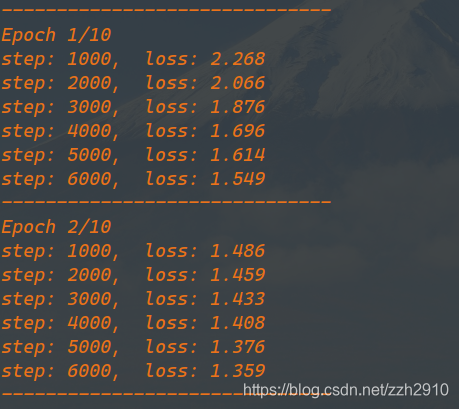
net = train(net, criterion, optimizer, 10)
# 保存模型参数
torch.save(net.state_dict(), 'net_dict.pt')
测试模型
# 图像类别
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = Net()
net.load_state_dict(torch.load('net_dict.pt')) # 加载各层参数
net.to(DEVICE)
# 整体正确率
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.to(DEVICE), labels.to(DEVICE)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
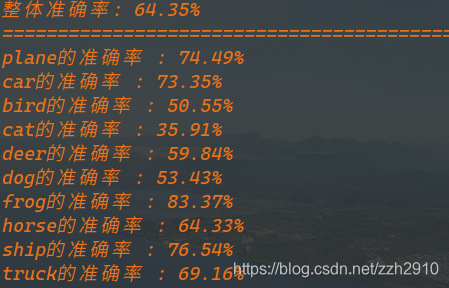
print('整体准确率: {}%'.format(100 * correct / total))
print('=' * 30)
# 每一个类别的正确率
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
if torch.cuda.is_available():
images, labels = images.cuda(), labels.cuda()
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(labels.size(0)):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('{}的准确率 : {:.2f}%'.format(classes[i], 100 * class_correct[i] / class_total[i]))
模型对测试集图片的一些预测结果
import matplotlib.pyplot as plt
import numpy as np
# 定义一个显示图片的函数
def imshow(img):
# 输入数据:torch.tensor[c, h, w]
img = img * 0.5 + 0.5 # 反归一
npimg = np.transpose(img.numpy(), (1, 2, 0)) # [c, h, w] -> [h, w, c]
plt.imshow(npimg)
plt.show()
# 取一批图片
testdata = iter(testloader)
images, labels = testdata.next()
imshow(torchvision.utils.make_grid(images))
print('真实类别: ', ' '.join('{}'.format(classes[labels[j]]) for j in range(labels.size(0))))
# 预测是10个标签的权重,一个类别的权重越大,神经网络越认为它是这个类别,所以输出最高权重的标签。
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('预测结果: ', ' '.join('{}'.format(classes[predicted[j]]) for j in range(labels.size(0))))


PyTorch入门-CIFAR10图像分类的更多相关文章
- Pytorch和CNN图像分类
Pytorch和CNN图像分类 PyTorch是一个基于Torch的Python开源机器学习库,用于自然语言处理等应用程序.它主要由Facebookd的人工智能小组开发,不仅能够 实现强大的GPU加速 ...
- Theano入门——CIFAR-10和CIFAR-100数据集
Theano入门——CIFAR-10和CIFAR-100数据集 1.CIFAR-10数据集介绍 CIFAR-10数据集包含60000个32*32的彩色图像,共有10类.有50000个训练图像和1000 ...
- Pytorch入门上 —— Dataset、Tensorboard、Transforms、Dataloader
本节内容参照小土堆的pytorch入门视频教程.学习时建议多读源码,通过源码中的注释可以快速弄清楚类或函数的作用以及输入输出类型. Dataset 借用Dataset可以快速访问深度学习需要的数据,例 ...
- Pytorch入门中 —— 搭建网络模型
本节内容参照小土堆的pytorch入门视频教程,主要通过查询文档的方式讲解如何搭建卷积神经网络.学习时要学会查询文档,这样会比直接搜索良莠不齐的博客更快.更可靠.讲解的内容主要是pytorch核心包中 ...
- Pytorch入门下 —— 其他
本节内容参照小土堆的pytorch入门视频教程. 现有模型使用和修改 pytorch框架提供了很多现有模型,其中torchvision.models包中有很多关于视觉(图像)领域的模型,如下图: 下面 ...
- [pytorch] Pytorch入门
Pytorch入门 简单容易上手,感觉比keras好理解多了,和mxnet很像(似乎mxnet有点借鉴pytorch),记一记. 直接从例子开始学,基础知识咱已经看了很多论文了... import t ...
- Pytorch入门随手记
Pytorch入门随手记 什么是Pytorch? Pytorch是Torch到Python上的移植(Torch原本是用Lua语言编写的) 是一个动态的过程,数据和图是一起建立的. tensor.dot ...
- pytorch 入门指南
两类深度学习框架的优缺点 动态图(PyTorch) 计算图的进行与代码的运行时同时进行的. 静态图(Tensorflow <2.0) 自建命名体系 自建时序控制 难以介入 使用深度学习框架的优点 ...
- 超简单!pytorch入门教程(五):训练和测试CNN
我们按照超简单!pytorch入门教程(四):准备图片数据集准备好了图片数据以后,就来训练一下识别这10类图片的cnn神经网络吧. 按照超简单!pytorch入门教程(三):构造一个小型CNN构建好一 ...
随机推荐
- 记录一次线上实施snmp
公司要实施一个部级的项目,我们公司的提供的产品要对接下客户的一个平台监控平台,该监控平台使用snmp,我们公司的产品不支持snmp,所以由我负责在现网实施snmp,记录这次现网 一.生成编译规则 1. ...
- 字节真题 ZJ26-异或:使用字典树减少计算次数
原题链接 题目描述: 个人分析:从输入数据看,要处理的元素个数(n)没有到达 10^9 或 10^8 级,或许可以使用暴力?但是稍微计算一下,有 10^5 * (10^5 - 1) / 2 = 10^ ...
- 区间DP 学习笔记
前言:本人是个DP蒟蒻,一直以来都特别害怕DP,终于鼓起勇气做了几道DP题,发现也没想象中的那么难?(又要被DP大神吊打了呜呜呜. ----------------------- 首先,区间DP是什么 ...
- slots属性(省内存,限制属性的定义)
class Foo: __slots__=['name','age'] #{'name':None,'age':None} # __slots__='name' #{'name':None,'age' ...
- Python高手是怎样炼成的!
很多想从事python行业的朋友都会问到,零基础如何自学成为Python高手?根据小北多年教育的经验,我总结了几个小建议,想看干货的请看下文! 如何克服入门难问题? 其实小北觉得,最好的方法就是和一群 ...
- 大学生可用来接单,利用Python实现教务系统扩容抢课!
最近一学期一次的抢课大戏又来了,几家欢乐几家愁.O(∩_∩)O哈哈~(l我每次一选就过了hah,我还是有欧的时候滴).看着他们盯着教务系统就着急,何况我们那教务系统,不想说什么.emmm 想周围的朋友 ...
- 禁用 Spring Boot 中引入安全组件 spring-boot-starter-security 的方法
1.当我们通过 maven 或 gradle 引入了 Spring boot 的安全组件 spring-boot-starter-security,Spring boot 默认开启安全组件,这样我们就 ...
- Java 变量及运算符
Java概述 Java的发展可以归纳如下的几个阶段: (1)第一阶段(完善期):JDK 1.0 ( 1995年推出)一JDK 1.2 (1998年推出,Java更名为Java 2): (2)第二阶段( ...
- C#设计模式之5-单例模式
单例模式(Singleton Pattern) 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/397 访问. 单例模式属 ...
- C#LeetCode刷题之#217-存在重复元素(Contains Duplicate)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3772 访问. 给定一个整数数组,判断是否存在重复元素. 如果任何 ...