为什么MySQL索引使用B+树
为什么MySQL索引使用B+树
聚簇索引与非聚簇索引
不同的存储引擎,数据文件和索引文件位置是不同的,但是都是在磁盘上而不是内存上,根据索引文件、数据文件是否放在一起而有了分类:
聚簇索引:数据文件和索引文件放在一起,例如:innodb
每一个数据库在磁盘上都会有一个对应的文件:
进去其中一个文件夹:
这其中:
.frm:存储的是表结构
.ibd:存储数据文件和索引文件
注意:mysql的innodb默认会将数据文件以及索引文件放在表格空间中,不会为每一个单独的表保存一份数据文件,如果需要单独保存,那么要将 innodb_file_per_table 设置为on;
非聚簇索引:数据和索引文件各自分开存放,例如:MyISAM
.frm 存储表结构
.MYI存储索引数据
.MYD 存储实际数据
索引备选存储结构
哈希表
二叉树
B树
B+树
HashMap(散列表)
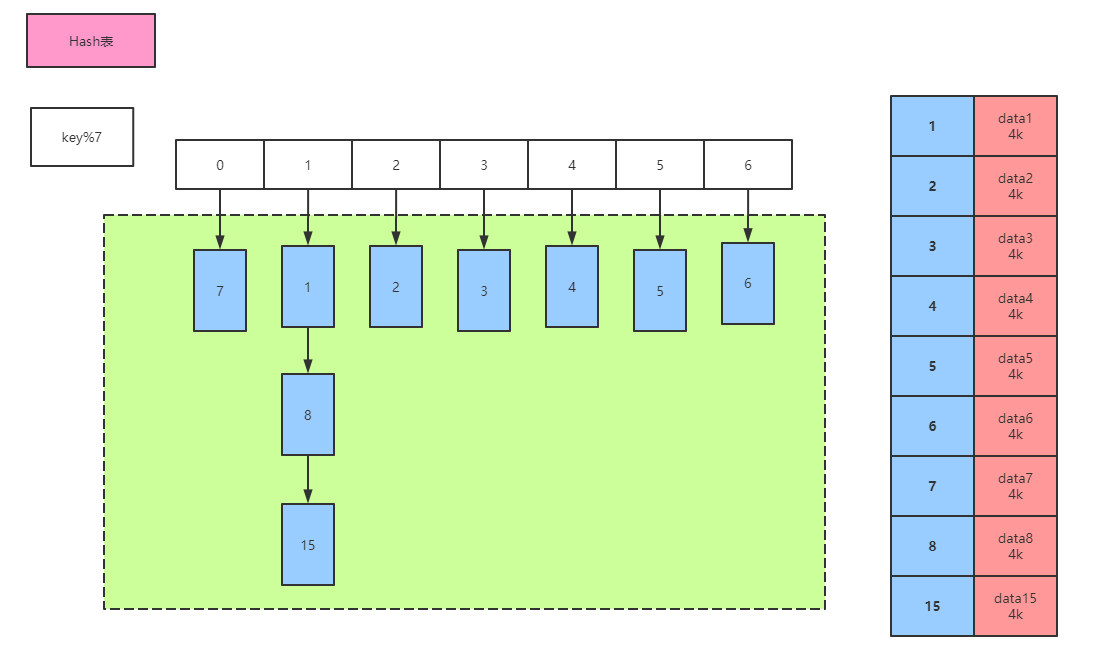
哈希表可以完成索引的存储,每次添加索引需要计算指定列的hash值,取模运算后计算出下标,将元素插入下标位,使用场景:等值查询,但是表格中的数据是无序数据(范围查找比较消耗时间,需要进行遍历操作),在企业中查询更多是范围查询,不合适.另外,Hashmap作为索引的时候,需要全部加载到内存,消耗内存空间。于是考虑树结构.
HashMap索引的限制:
- 哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。
- 哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序。
- 哈希索引也不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值的。
- 哈希索引只支持等值比较查询,包括=、IN()、<>(注意<>和<=>是不同的操作)。也不支持任何范围查询,例如WHERE price>100。
- 访问哈希索引的数据非常快,除非有很多哈希冲突(不同的索引列值却有相同的哈希值)。当出现哈希冲突的时候,存储引擎必须遍历链表中所有的行指针,逐行进行比较,直到找到所有符合条件的行。
- 如果哈希冲突很多的话,一些索引维护操作的代价也会很高。例如,如果在某个选择性很低(哈希冲突很多)的列上建立哈希索引,那么当从表中删除一行时,存储引擎需要遍历对应哈希值的链表中的每一行,找到并删除对应行的引用,冲突越多,代价越大。
树的发展缘由

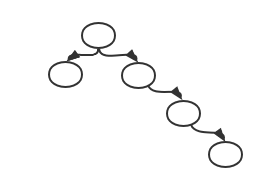
计算机领域的树的特点是左子树小于根节点,右子树大于根节点,从左到右是有序的,多叉树查找效率比较低,后来有了二叉树,二叉树接近二分查找(时间复杂度),但是会出现下面这种情况,变成了查询时间复杂度高的链表查询:
于是有了 平衡树(AVL树,要求左右结点高度差不大于于1),也就是插入数据之后,会自旋调整变成平衡树,但是旋转会影响插入的性能,也就是如果查询多但是插入少的话可以用AVL树,但是插入多的话就不适合,为了优化插入的时间复杂度,产生了红黑树,红黑树左右子节点高度差不超过一倍即可(例如左子树高度4,那么右子树高度可以是8),但是红黑树问题是:由于允许子树高度差超过一倍,可能出现由于树的深度过大而造成磁盘IO读写过于频繁,进而导致效率低下的情况。
为什么会出现这样的情况,我们知道要获取磁盘上数据,必须先通过磁盘移动臂移动到数据所在的柱面,然后找到指定盘面,接着旋转盘面找到数据所在的磁道,最后对数据进行读写。磁盘IO代价主要花费在查找所需的柱面上,树的深度过大会造成磁盘IO频繁读写。根据磁盘查找存取的次数往往由树的高度所决定,所以,只要我们通过某种较好的树结构减少树的结构尽量减少树的高度,B树可以有多个子女,从几十到上千,可以降低树的高度。
接下来考虑B树(B-树)
B树
B树特点是,结点(非叶子结点)有可变数量的子节点(事先设定好),在一个节点中需要设置键值,因为子节点数量有一定的允许范围,所以B树不需要像其他自平衡查找树那样频繁地重新保持平衡,B树示意图:
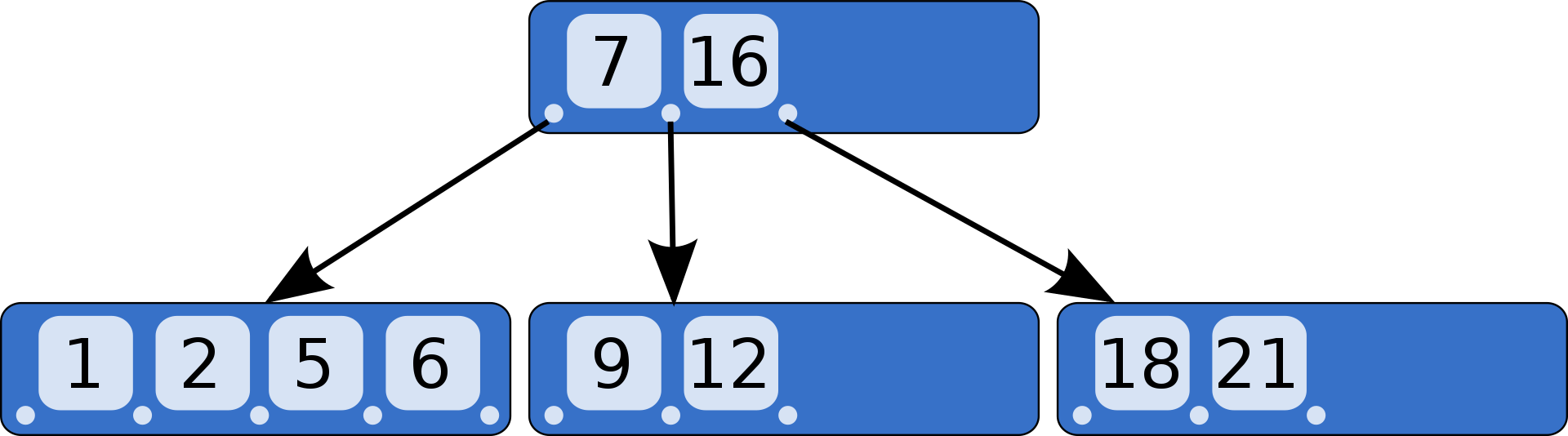
B树特点:
1、所有键值分布在整颗树中
2、搜索有可能在非叶子结点结束,在关键字全集内做一次查找,性能逼近二分查找
3、每个节点最多拥有m个子树,最多有m-1个键值
4、根节点至少有2个子树
5、分支节点至少拥有m/2颗子树(除根节点和叶子节点外都是分支节点)
6、所有叶子节点都在同一层、每个节点最多可以有m-1个key,并且以升序排列
B树键值携带数据
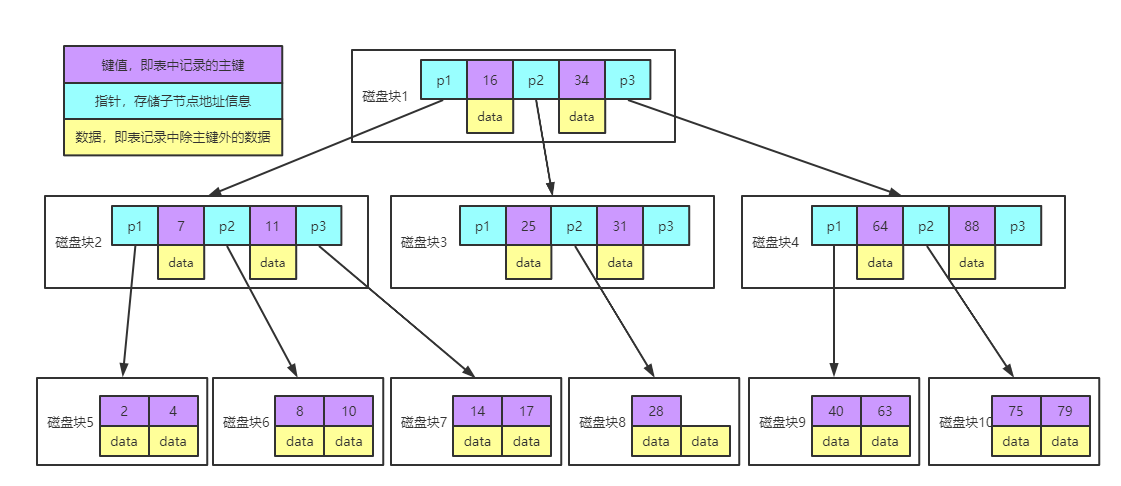
实例图说明:
每个节点占用一个磁盘块,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。以根节点为例,关键字为 16 和 34,P1 指针指向的子树的数据范围为小于 16,P2 指针指向的子树的数据范围为 16~34,P3 指针指向的子树的数据范围为大于 34。
查找关键字过程:
1、根据根节点找到磁盘块 1,读入内存。【磁盘 I/O 操作第 1 次】
2、比较关键字 28 在区间(16,34),找到磁盘块 1 的指针 P2。
3、根据 P2 指针找到磁盘块 3,读入内存。【磁盘 I/O 操作第 2 次】
4、比较关键字 28 在区间(25,31),找到磁盘块 3 的指针 P2。
5、根据 P2 指针找到磁盘块 8,读入内存。【磁盘 I/O 操作第 3 次】
6、在磁盘块 8 中的关键字列表中找到关键字 28。
缺点:
1、每个节点都有key,同时也包含data,而每个页存储空间是有限的,如果data比较大的话会导致每个节点存储的key数量变小
2、当存储的数据量很大的时候会导致深度较大,增大查询时磁盘io次数,进而影响查询性能
B+树
特点:
B+树与B树类似,但只有叶节点存放数据,其余节点用来索引,B-树是每个索引节点都会有Data域.B-树/B+树的特点就是每层节点数目非常多,层数很少,目的就是为了就少磁盘IO次数,B-树的每个节点都有data域(指针),这无疑增大了节点大小,说白了增加了磁盘IO次数(磁盘IO一次读出的数据量大小是固定的,单个数据变大,每次读出的就少,IO次数增多,一次IO多耗时),而B+树除了叶子节点其它节点并不存储数据,节点小,磁盘IO次数就少。这是优点之一。
另一个优点是: B+树所有的Data域在叶子节点,一般来说都会进行一个优化,就是将所有的叶子节点用指针串起来。这样遍历叶子节点就能获得全部数据,这样就能进行区间访问啦。在数据库中基于范围的查询是非常频繁的,而B树不支持这样的遍历操作。
图示:
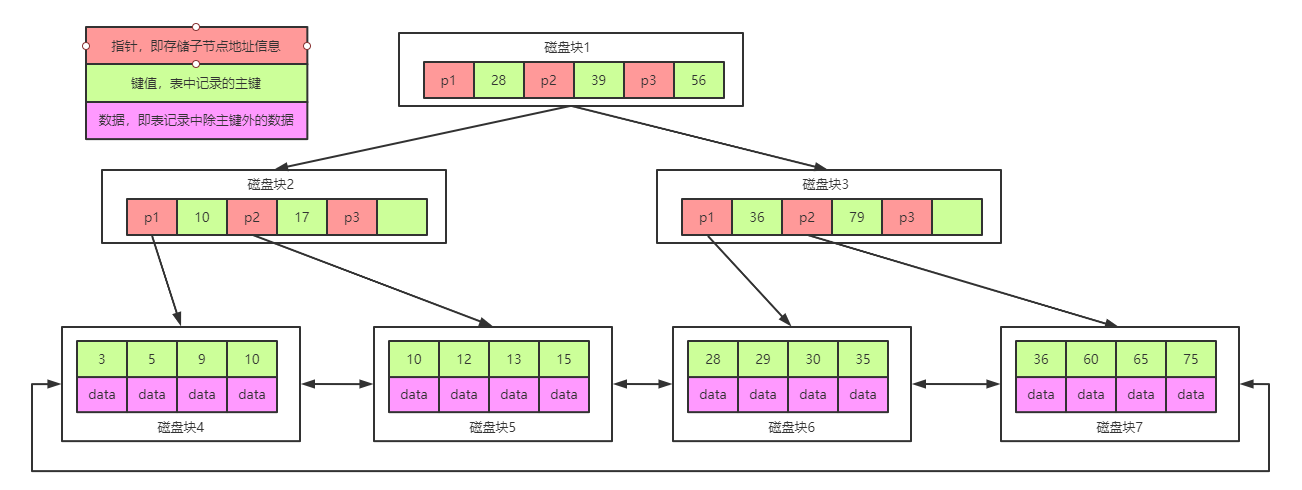
B+Tree是在BTree的基础之上做的一种优化,变化如下:
1、B+Tree每个节点可以包含更多的节点,这个做的原因有两个,第一个原因是为了降低树的高度,第二个原因是将数据范围变为多个区间,区间越多,数据检索越快
2、非叶子节点存储key,叶子节点存储key和数据
3、叶子节点两两指针相互连接(符合磁盘的预读特性),顺序查询性能更高
注意:在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对 B+Tree 进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
1、InnoDB是通过B+Tree结构对主键创建索引,然后叶子节点中存储记录,如果没有主键,那么会选择唯一键,如果没有唯一键,那么会生成一个6位的row_id来作为主键
2、如果创建索引的键是其他字段,那么在叶子节点中存储的是该记录的主键,然后再通过主键索引找到对应的记录,叫做回表
为什么MySQL索引使用B+树的更多相关文章
- MySQL索引之B+树
MySQL索引大都存储在B+树中,除此还有R树和hash索引.B+树的基础还是B树. B树由2部分组成,节点和索引.下面将构建一个B树,每个节点存2个数据,每个节点有前,中,后三个索引.插入数字的顺序 ...
- 聊聊Mysql索引和redis跳表
摘要 面试时,交流有关mysql索引问题时,发现有些人能够涛涛不绝的说出B+树和B树,平衡二叉树的区别,却说不出B+树和hash索引的区别.这种一看就知道是死记硬背,没有理解索引的本质.本文旨在剖析这 ...
- [转] MySQL索引原理
MySQL索引原理 B+树索引是B+树在数据库中的一种实现,是最常见也是数据库中使用最为频繁的一种索引.B+树中的B代表平衡(balance),而不是二叉(binary),因为B+树是从最早的平衡二叉 ...
- 浅谈Mysql索引
文章原创于公众号:程序猿周先森.本平台不定时更新,喜欢我的文章,欢迎关注我的微信公众号. 我们都知道,数据库索引可以帮助我们更加快速的找出符合的数据,但是如果不使用索引,Mysql则会从第一条开始查询 ...
- 聊聊Mysql索引和redis跳表 ---redis的有序集合zset数据结构底层采用了跳表原理 时间复杂度O(logn)(阿里)
redis使用跳表不用B+数的原因是:redis是内存数据库,而B+树纯粹是为了mysql这种IO数据库准备的.B+树的每个节点的数量都是一个mysql分区页的大小(阿里面试) 还有个几个姊妹篇:介绍 ...
- 从MongoDB及mysql 谈B/B+树
一 B树的由来 B树指的是一类树,包括B-树,B+树,B*树等,是一种自平衡的搜索树,它类似普通的平衡二叉树,不同的一点是B树允许每个节点有更多的子节点.B树是专门为外部存储器设计的,如磁盘,它对于读 ...
- mysql索引原理深度解析
mysql索引原理深度解析 一.总结 一句话总结: mysql索引是b+树,因为b+树在范围查找.节点查找等方面优化 hash索引,完全平衡二叉树,b树等 1.数据库中最常见的慢查询优化方式是什么? ...
- MySQL索引由浅入深
索引是SQL优化中最重要的手段之一,本文从基础到原理,带你深度掌握索引. 一.索引基础 1.什么是索引 MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构,索引对于 ...
- B+树|MYSQL索引使用原则
MySQL一直了解得都不多,之前写sql准备提交生产环境之前的时候,老员工帮我检查了下sql,让修改了一下存储引擎,当时我使用的是Myisam,后面改成InnoDB了.为什么要改成这样,之前都没有听过 ...
随机推荐
- Python的一个mysql实例
按公司名统计一定时期内入货的总车数,总重量还有总价格.数据表如下: 要用到的库是pymysql,读取excel表格的xlrd,写入excel的xlwt和复制excel模板的xlutils,代码如下: ...
- linux不同环境变量文件的比较,如/etc/profile和/etc/environment
/etc/profile 为系统的每个用户设置环境信息和启动程序,当用户第一次登录时,该文件被执行,其配置对所有登录的用户都有效. 当被修改时,必须重启才会生效.英文描述:"System w ...
- 现代JavaScript—ES6+中的Imports,Exports,Let,Const和Promise
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者.原文出处:https://www.freecodecamp.org/news/learn-modern-jav ...
- AOP的姿势之 简化 MemoryCache 使用方式
0. 前言 之前写了几篇文章介绍了一些AOP的知识, 但是还没有亮出来AOP的姿势, 也许姿势漂亮一点, 大家会对AOP有点兴趣 内容大致会分为如下几篇:(毕竟人懒,一下子写完太累了,没有动力) AO ...
- React Native Android 环境搭建
因为工作需要,最近正在学习React Native Android.温故而知新,把学习的内容记录下来巩固一下知识,也给有需要的人一些帮助. 需要说明的是,我刚接触React Native也不久,对它的 ...
- 一文掌握XSS
目录 XSS跨站脚本攻击 1.什么叫跨站脚本攻击? 2.XSS跨站脚本攻击的原理 3.XSS跨站脚本攻击的目的是什么? 4.XSS跨站脚本攻击出现的原因 5.XSS跨站脚本攻击的条件 1.有输入有输出 ...
- 实现连续登录X天送红包这个连续登录X天算法
实现用户只允许登录系统1次(1天无论登录N次算一次) //timeStamp%864000计算结果为当前时间在一天当中过了多少秒 //当天0点时间戳 long time=timeStamp-timeS ...
- WebService 适用场合
适用场合 1.跨防火墙通信 如果应用程序有成千上万的用户,而且分布在世界各地,那么客户端和服务器之间的通信将是一个棘手的问题.因为客户端和服务器之间通常会有防火墙或者代理服 务器.在这种情况下,使用D ...
- 强化学习 1 --- 马尔科夫决策过程详解(MDP)
强化学习 --- 马尔科夫决策过程(MDP) 1.强化学习介绍 强化学习任务通常使用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述,具体而言:机器处在一个环境 ...
- TurtleBot3 Waffle (tx2版华夫)(8)键盘控制
1)[Remote PC] 启动roscore $ roscore 2)[Turbot3] 启动turbot3 $ roslaunch turbot3_bringup minimal.launch 3 ...