Dubbo工作流程
一、dubbo整体架构
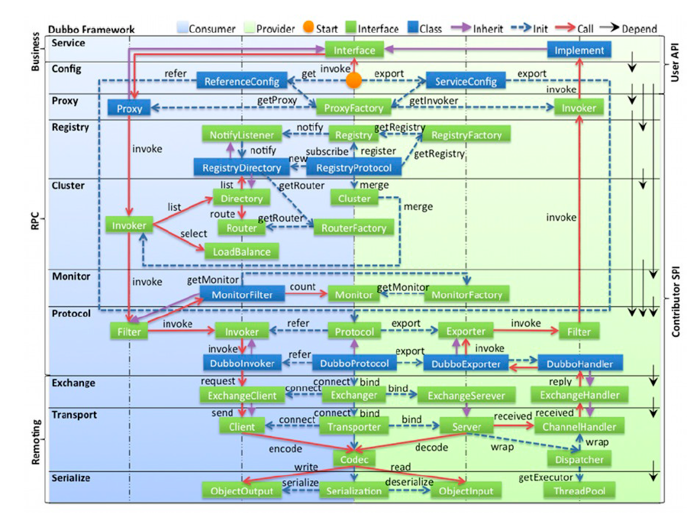
- 其中Service 和 Config 层为 API,对应服务提供方来说是使用ServiceConfig来代表一个要发布的服务配置对象,对应服务消费方来说ReferenceConfig代表了一个要消费的服务的配置对象。可以直接初始化配置类,也可以通过 spring 解析配置生成配置类。
- proxy 服务代理层:扩展接口为 ProxyFactory,dubbo实现的SPI主要JavassistProxyFactory(默认使用)和JdkProxyFactory,用来对服务提供方和服务消费方的服务进行代理。
- registry 注册中心层:封装服务地址的注册与发现,扩展接口为 Registry , RegistryService,Dubbo提供的扩展接口实现为ZookeeperRegistry,RedisRegistry,MulticastRegistry,DubboRegistry。
- 扩展接口RegistryFactory,dubbo提供的扩展接口实现DubboRegistryFactory,DubboRegistryFactory,RedisRegistryFactory,ZookeeperRegistryFactory。
- cluster 路由层:封装多个提供者的路由及负载均衡,并桥接注册中心,
- 扩展接口为 Cluster , Directory , Router ,LoadBalance。
- monitor 监控层:RPC 调用次数和调用时间监控,扩展接口为 MonitorFactory , Monitor , MonitorService。
- protocol 远程调用层:封将 RPC 调用,扩展接口为 Protocol , Invoker , Exporter。
- exchange 信息交换层:封装请求响应模式,同步转异步,扩展接口为 Exchanger , ExchangeChannel ,ExchangeClient , ExchangeServer
- transport 网络传输层:抽象 mina 和 netty 为统一接口扩展接口为 Channel , Transporter , Client , Server , Codec
- serialize 数据序列化层:可复用的一些工具,扩展接口为 Serialization ,ObjectInput , ObjectOutput , ThreadPool
二、dubbo服务发布原理

首先 ServiceConfig 类拿到对外提供服务的实际类 ref(如:UserServiceImpl),然后通过 ProxyFactory 类的 getInvoker 方法使用 ref 生成一个AbstractProxyInvoker 实例,到这一步就完成具体服务到 Invoker 的转化。
接下来就是 Invoker 转换到 Exporter 的过程。Dubbo 处理服务暴露的关键就在 Invoker 转换到 Exporter 的过程,上图中的红色部分。
Dubbo 协议的 Invoker 转为 Exporter 发生在 DubboProtocol 类的 export 方法,它主要是打开创建一个Netty Server 侦听服务,并接收客户端发来的各种请求,通讯细节由 Dubbo 自己实现,然后注册服务到服务注册中心
三、dubbo消费原理
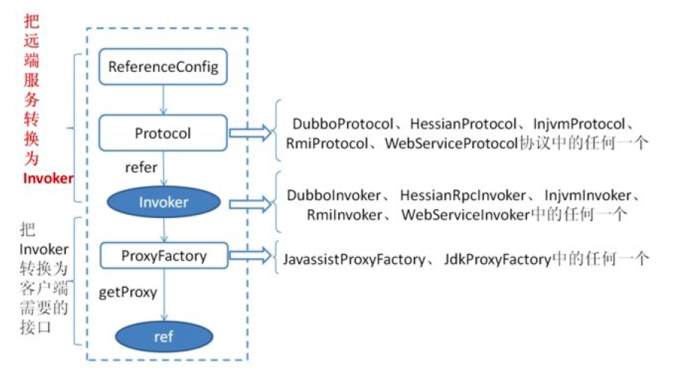
首先 ReferenceConfig 类的 init 方法调用 Protocol 的 refer 方法生成 Invoker 实例(如上图中的红色部分),这是服务消费的关键。接下来把Invoker 转换为客户端需要的接口。
dubbo协议的invoker转换为客户端需要的接口是发生在DubboProtocol的refer方法,他主要是创建一个netty client 链接服务提供者,通讯细节由 Dubbo 自己实现。
四、dubbo原理总结
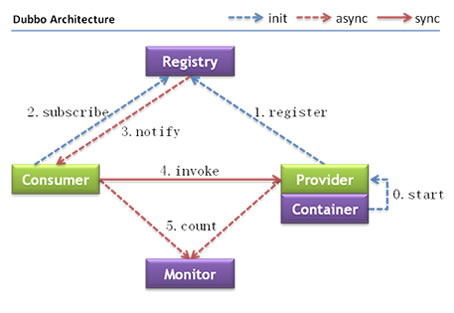
节点角色说明:
- Provider: 暴露服务的服务提供方。
- Consumer: 调用远程服务的服务消费方。
- Registry: 服务注册与发现的注册中心。
- Monitor: 统计服务的调用次调和调用时间的监控中心。
- Container: 服务运行容器。
调用关系说明:
- 服务容器负责启动,加载,运行服务提供者。
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
registry(configServer)
注册中心,和每个Server/Client之间会作一个实时的心跳检测(因为它们都是建立的Socket长连接),比如几秒钟检测一次。收集每个Server提供的服务的信息,每个Client的信息,整理出一个服务列表
当某个Server不可用,那么就更新受影响的服务对应的serverAddressList,即把这个Server从serverAddressList中踢出去(从地址列表中删除),同时将推送serverAddressList给这些受影响的服务的clientAddressList里面的所有Client
consumer(client)
Client在使用服务的时候根据服务名称去ConfigServer中获取服务提供者信息(这样ConfigServer就知道某个服务是当前哪几个Client在使用),Client拿到这些服务提供者信息后,与它们都建立连接,后面就可以直接调用服务了,当有多个服务提供者的时候,Client根据一定的规则来进行负载均衡,如轮询,随机,按权重等。
一旦Client使用的服务它对应的服务提供者有变化(服务提供者有新增,删除的情况),ConfigServer就会把最新的服务提供者列表推送给Client,Client就会依据最新的服务提供者列表重新建立连接,新增的提供者建立连接,删除的提供者丢弃连接
provider(server)
优点:
- 只要在Client和Server启动的时候,ConfigServer是好的,服务就可调用了,如果后面ConfigServer挂了,那只影响ConfigServer挂了以后服务提供者有变化,而Client还无法感知这一变化。
- Client每次调用服务是不经过ConfigServer的,Client只是与它建立联系,从它那里获取提供服务者列表而已
- 调用服务-负载均衡:Client调用服务时,可以根据规则在多个服务提供者之间轮流调用服务。
- 服务提供者-容灾:某一个Server挂了,Client依然是可以正确的调用服务的,当前提是这个服务有至少2个服务提供者,Client能很快的感知到服务提供者的变化,并作出相应反应。
- 服务提供者-扩展:添加一个服务提供者很容易,而且Client会很快的感知到它的存在并使用它。
Dubbo工作流程的更多相关文章
- dubbo系列二、dubbo请求流程记录
目录 1.dubbo请求处理流程 1.1. consumer端处理流程 1.2.provider端处理流程 1.3.dubbo请求分析记录-图 泳道图 xmind图 2.dubbo请求核心说明 1.d ...
- struts2工作流程
struts2的框架结构图 工作流程 1.客户端请求一个HttpServletRequest的请求,如在浏览器中输入http://localhost: 8080/bookcode/Reg.action ...
- SecondaryNameNode的工作流程
SecondaryNameNode是用来合并fsimage和edits文件来更新NameNode和metadata的. 其工作流程为: 1.secondary通知namenode切换edits文件 2 ...
- Storm 中什么是-acker,acker工作流程介绍
概述 我们知道storm一个很重要的特性是它能够保证你发出的每条消息都会被完整处理, 完整处理的意思是指: 一个tuple被完全处理的意思是: 这个tuple以及由这个tuple所导致的所有的tupl ...
- gitlab工作流程简介
gitlab工作流程简介 新建项目流程 创建/导入项目 可以选择导入github.bitbucket项目,也可以新建空白项目,还可以从SVN导入项目 建议选择private等级 初始化项目 1.本地克 ...
- Git 工作流程
Git 作为一个源码管理系统,不可避免涉及到多人协作. 协作必须有一个规范的工作流程,让大家有效地合作,使得项目井井有条地发展下去.”工作流程”在英语里,叫做”workflow”或者”flow”,原意 ...
- Spark基本工作流程及YARN cluster模式原理(读书笔记)
Spark基本工作流程及YARN cluster模式原理 转载请注明出处:http://www.cnblogs.com/BYRans/ Spark基本工作流程 相关术语解释 Spark应用程序相关的几 ...
- tornado 学习笔记10 Web应用中模板(Template)的工作流程分析
第8,9节中,我们分析Tornado模板系统的语法.使用以及源代码中涉及到的相关类,而且对相关的源代码进行了分析.那么,在一个真正的Web应用程序中,模板到底是怎样使用?怎样被渲染? ...
- RDIFramework.NET ━ .NET快速信息化系统开发框架 ━ 工作流程组件介绍
RDIFramework.NET ━ .NET快速信息化系统开发框架 工作流程组件介绍 RDIFramework.NET,基于.NET的快速信息化系统开发.整合框架,给用户和开发者最佳的.Net框架部 ...
随机推荐
- Docker 安装及配置镜像加速
Docker 版本 随着 Docker 的飞速发展,企业级功能的上线,更好的服务意味着需要支付一定的费用,目前 Docker 被分为两个版本: community-edition 社区版 enterp ...
- lammps_data文件
一.notes: 1.不在data文件里写“#”(注释),否则,容易出错: 2.前两行不用写东西(建议): 3.相互作用系数可以不用写在data里边(如pair_coeff等),可有可无,but fo ...
- edge 修改链接打开方式
我目前的edge版本是 Version 84.0.522.63 (Official build) (64-bit) 每次点击链接, 都是默认在原页面打开新标签, 不符合过往习惯. 修改方式 打开控制面 ...
- 移动web开发之布局
移动web开发流式布局 1.0 移动端基础 1.1浏览器现状 PC端常见浏览器:360浏览器.谷歌浏览器.火狐浏览器.QQ浏览器.百度浏览器.搜狗浏览器.IE浏览器. 移动端常见浏览器:UC浏览器,Q ...
- oracle备份之恢复管理目录
一.管理恢复目录 #现实应用中一般都是专门新建一个rman 数据库,给所有的数据库做catalog1.建立恢复目录 #建立恢复目录表空间SQL> create tablespace rman_t ...
- 【Pod Terminating原因追踪系列之一】containerd中被漏掉的runc错误信息
前一段时间发现有一些containerd集群出现了Pod卡在Terminating的问题,经过一系列的排查发现是containerd对底层异常处理的问题.最后虽然通过一个短小的PR修复了这个bug,但 ...
- 极简 Node.js 入门 - 3.5 文件夹操作
极简 Node.js 入门系列教程:https://www.yuque.com/sunluyong/node 本文更佳阅读体验:https://www.yuque.com/sunluyong/node ...
- IOS 打包相关
Unity 导出的Xcode工程 http://gad.qq.com/article/detail/29330 [Unity3D]Unity 生成的XCode工程结构 http://blog.163. ...
- webdriver入门之环境准备
1.安装ruby 下载ruby的安装包,很简单,不解释.装好之后打开cmd输入以下命令验证是否安装成功 ruby -v 2.安装webdriver 确保机器联网,用gem命令安装是在有网络的情况下进行 ...
- 尝试MatCap类型shader
听说MatCap能在低端机上做出很漂亮的pbr效果,就尝试了一下. MatCap全称MaterailCapture,里面存的是光照信息,通过法线的xy分量去采样matcap,得到在该方向法线的光照信息 ...