Hadoop框架:HDFS高可用环境配置
本文源码:GitHub·点这里 || GitEE·点这里
一、HDFS高可用
1、基础描述
在单点或者少数节点故障的情况下,集群还可以正常的提供服务,HDFS高可用机制可以通过配置Active/Standby两个NameNodes节点实现在集群中对NameNode的热备来消除单节点故障问题,如果单个节点出现故障,可通过该方式将NameNode快速切换到另外一个节点上。
2、机制详解
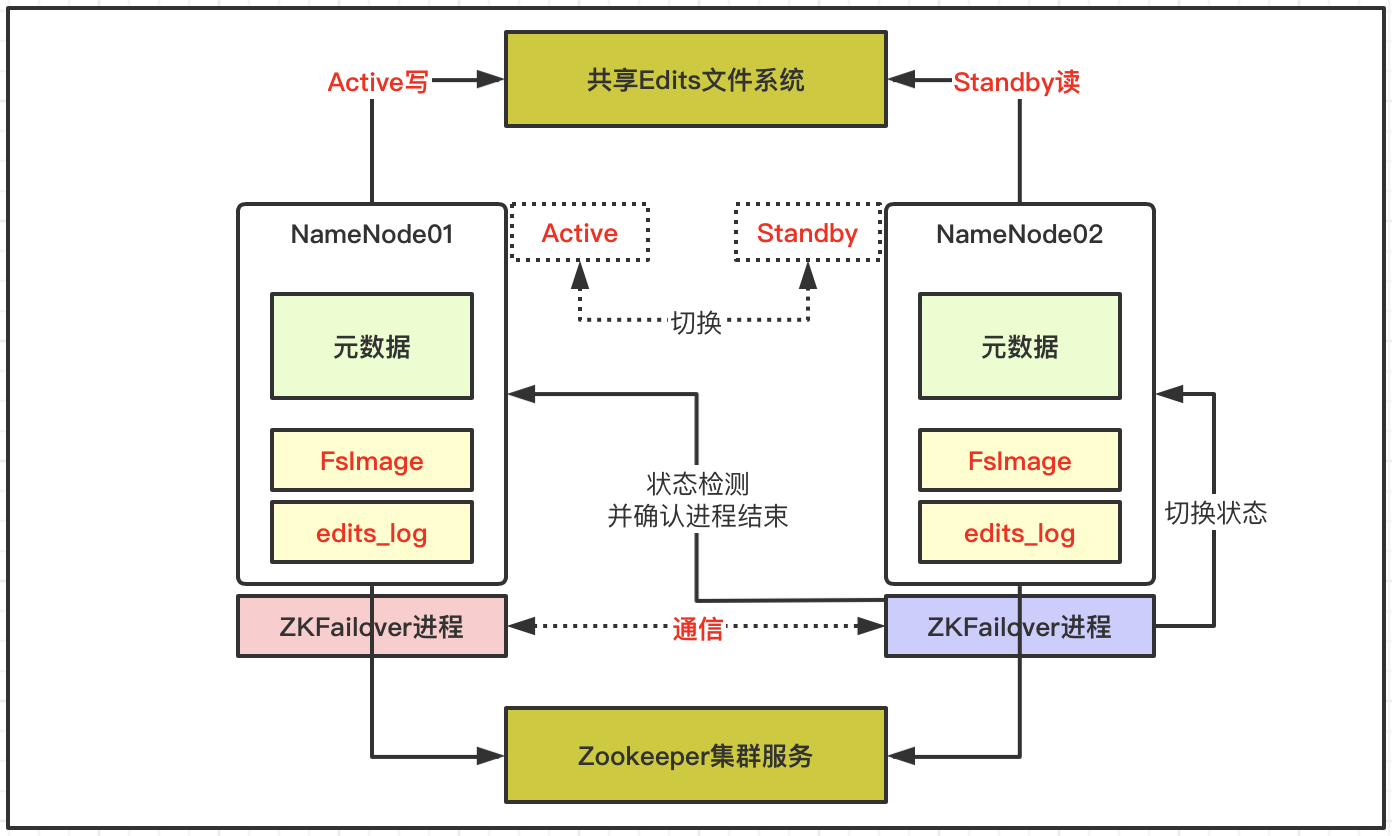
- 基于两个NameNode做高可用,依赖共享Edits文件和Zookeeper集群;
- 每个NameNode节点配置一个ZKfailover进程,负责监控所在NameNode节点状态;
- NameNode与ZooKeeper集群维护一个持久会话;
- 如果Active节点故障停机,ZooKeeper通知Standby状态的NameNode节点;
- 在ZKfailover进程检测并确认故障节点无法工作后;
- ZKfailover通知Standby状态的NameNode节点切换为Active状态继续服务;
ZooKeeper在大数据体系中非常重要,协调不同组件的工作,维护并传递数据,例如上述高可用下自动故障转移就依赖于ZooKeeper组件。
二、HDFS高可用
1、整体配置
| 服务列表 | HDFS文件 | YARN调度 | 单服务 | 共享文件 | Zk集群 |
|---|---|---|---|---|---|
| hop01 | DataNode | NodeManager | NameNode | JournalNode | ZK-hop01 |
| hop02 | DataNode | NodeManager | ResourceManager | JournalNode | ZK-hop02 |
| hop03 | DataNode | NodeManager | SecondaryNameNode | JournalNode | ZK-hop03 |
2、配置JournalNode
创建目录
[root@hop01 opt]# mkdir hopHA
拷贝Hadoop目录
cp -r /opt/hadoop2.7/ /opt/hopHA/
配置core-site.xml
<configuration>
<!-- NameNode集群模式 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hopHA/hadoop2.7/data/tmp</value>
</property>
</configuration>
配置hdfs-site.xml,添加内容如下
<!-- 分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- NN1 RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hop01:9000</value>
</property>
<!-- NN2 RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hop02:9000</value>
</property>
<!-- NN1 Http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hop01:50070</value>
</property>
<!-- NN2 Http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hop02:50070</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hop01:8485;hop02:8485;hop03:8485/mycluster</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hopHA/hadoop2.7/data/jn</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 访问代理类失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
依次启动journalnode服务
[root@hop01 hadoop2.7]# pwd
/opt/hopHA/hadoop2.7
[root@hop01 hadoop2.7]# sbin/hadoop-daemon.sh start journalnode
删除hopHA下数据
[root@hop01 hadoop2.7]# rm -rf data/ logs/
NN1格式化并启动NameNode
[root@hop01 hadoop2.7]# pwd
/opt/hopHA/hadoop2.7
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
NN2同步NN1数据
[root@hop02 hadoop2.7]# bin/hdfs namenode -bootstrapStandby
NN2启动NameNode
[root@hop02 hadoop2.7]# sbin/hadoop-daemon.sh start namenode
查看当前状态
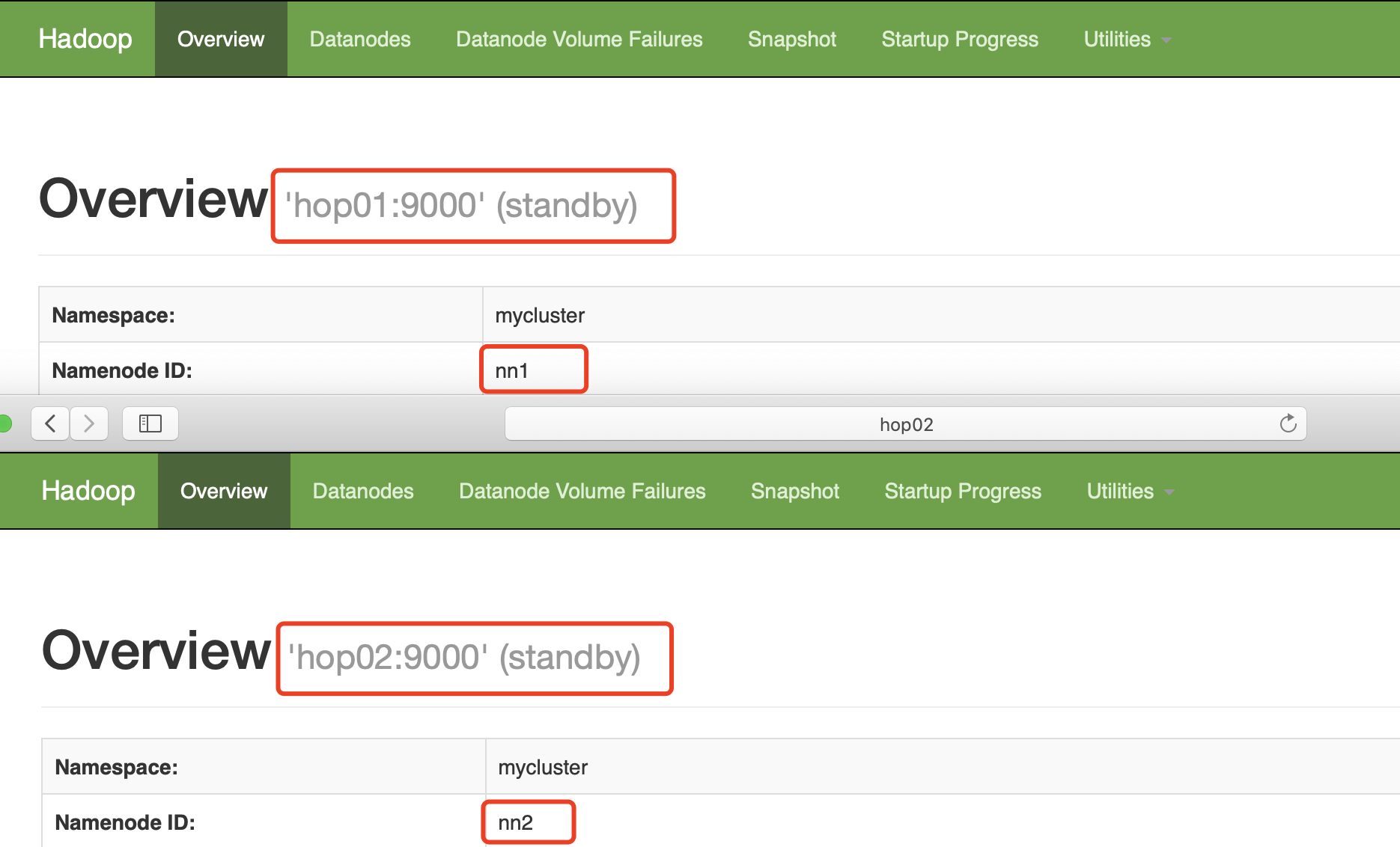
在NN1上启动全部DataNode
[root@hop01 hadoop2.7]# sbin/hadoop-daemons.sh start datanode
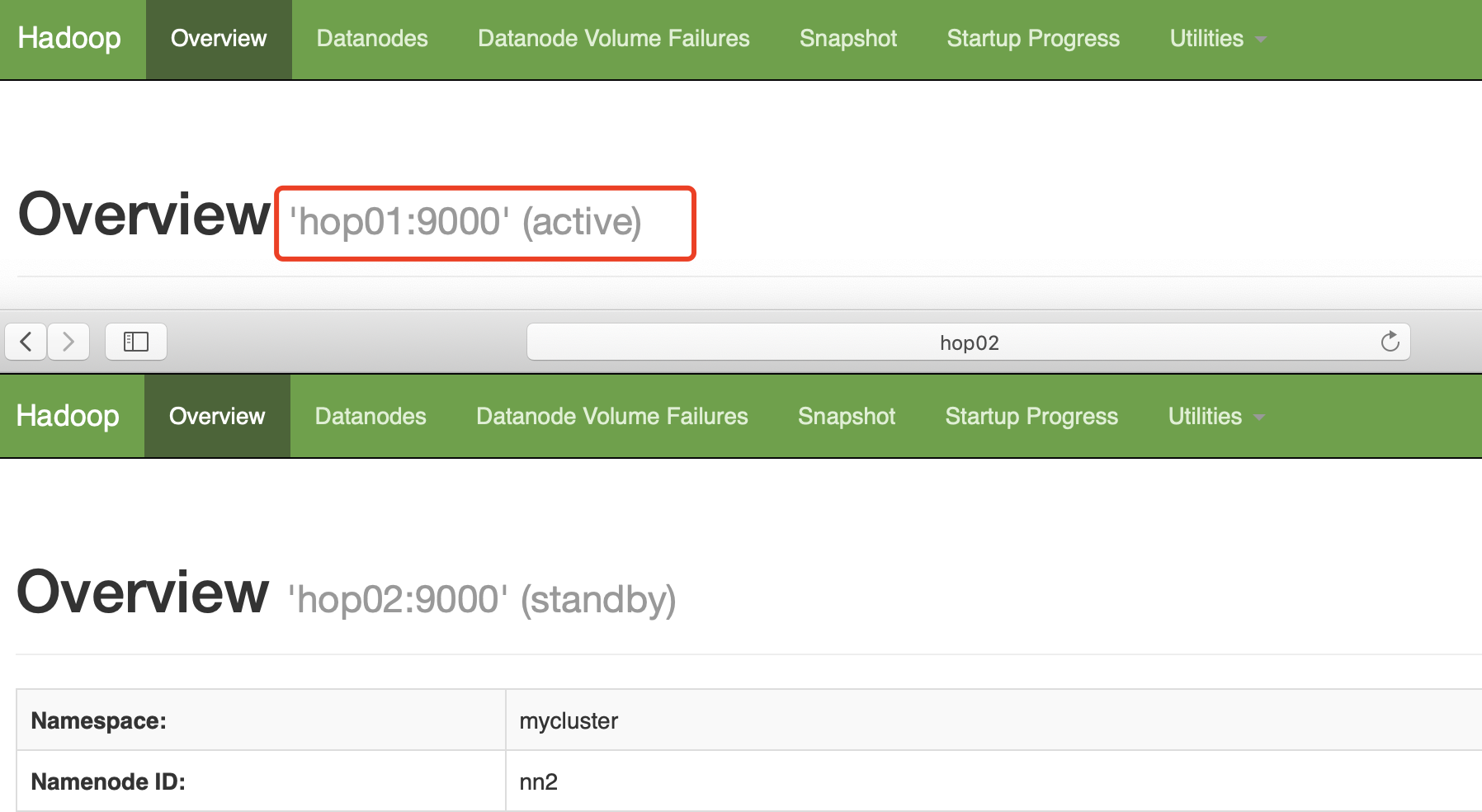
NN1切换为Active状态
[root@hop01 hadoop2.7]# bin/hdfs haadmin -transitionToActive nn1
[root@hop01 hadoop2.7]# bin/hdfs haadmin -getServiceState nn1
active
3、故障转移配置
配置hdfs-site.xml,新增内容如下,同步集群
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
配置core-site.xml,新增内容如下,同步集群
<property>
<name>ha.zookeeper.quorum</name>
<value>hop01:2181,hop02:2181,hop03:2181</value>
</property>
关闭全部HDFS服务
[root@hop01 hadoop2.7]# sbin/stop-dfs.sh
启动Zookeeper集群
/opt/zookeeper3.4/bin/zkServer.sh start
hop01初始化HA在Zookeeper中状态
[root@hop01 hadoop2.7]# bin/hdfs zkfc -formatZK
hop01启动HDFS服务
[root@hop01 hadoop2.7]# sbin/start-dfs.sh
NameNode节点启动ZKFailover
这里hop01和hop02先启动的服务状态就是Active,这里先启动hop02。
[hadoop2.7]# sbin/hadoop-daemon.sh start zkfc
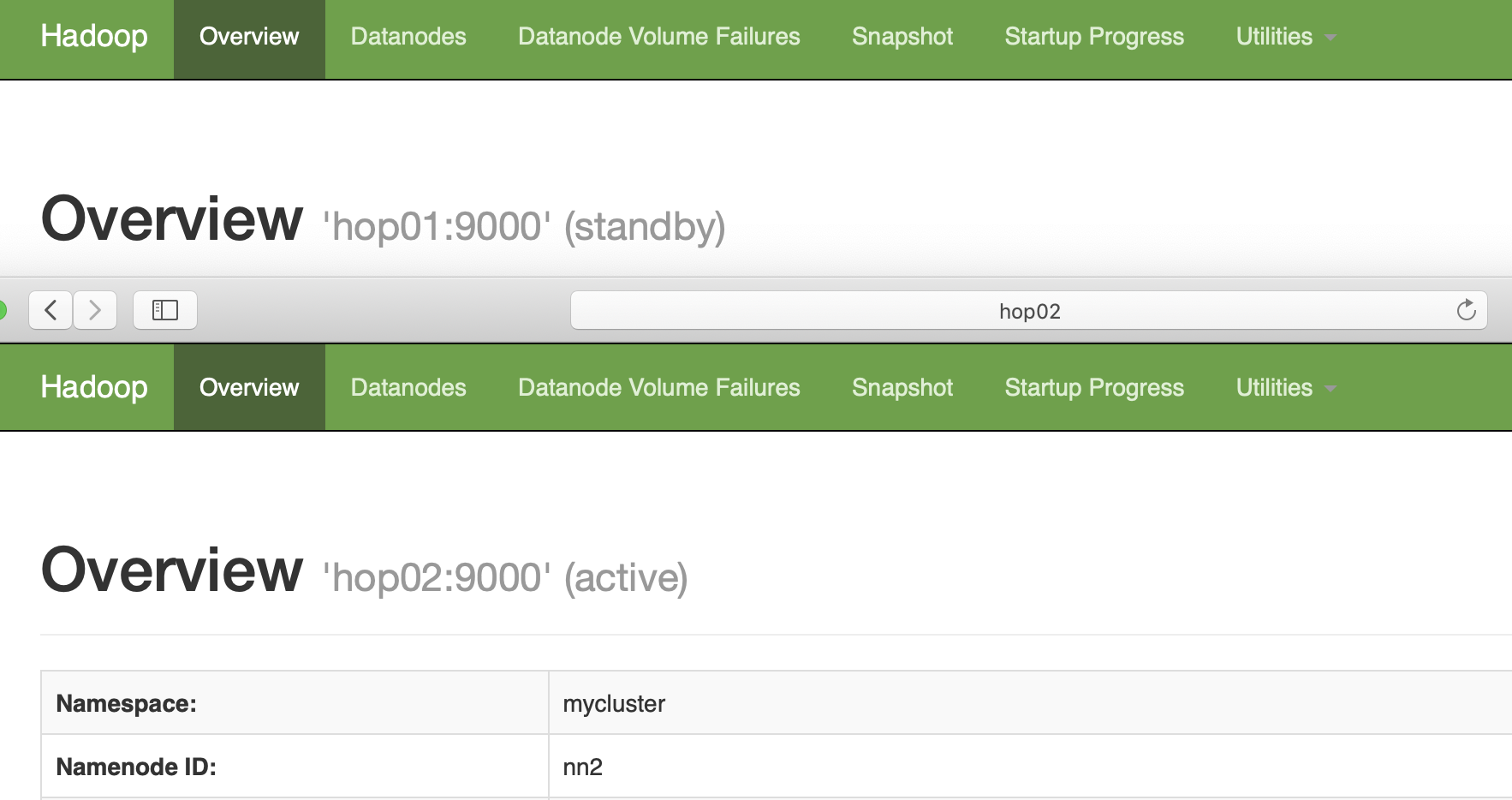
结束hop02的NameNode进程
kill -9 14422
等待一下查看hop01状态
[root@hop01 hadoop2.7]# bin/hdfs haadmin -getServiceState nn1
active
三、YARN高可用
1、基础描述
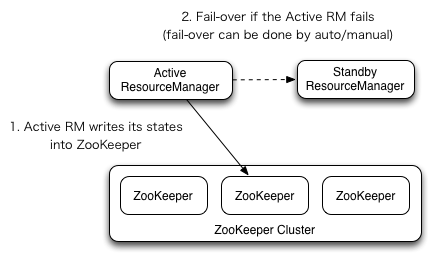
基本流程和思路与HDFS机制类似,依赖Zookeeper集群,当Active节点故障时,Standby节点会切换为Active状态持续服务。
2、配置详解
环境同样基于hop01和hop02来演示。
配置yarn-site.xml,同步集群下服务
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用HA机制-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明Resourcemanager服务-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn01</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hop01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hop02</value>
</property>
<!--Zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hop01:2181,hop02:2181,hop03:2181</value>
</property>
<!--启用自动恢复机制-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定状态存储Zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
重启journalnode节点
sbin/hadoop-daemon.sh start journalnode
在NN1服务格式化并启动
[root@hop01 hadoop2.7]# bin/hdfs namenode -format
[root@hop01 hadoop2.7]# sbin/hadoop-daemon.sh start namenode
NN2上同步NN1元数据
[root@hop02 hadoop2.7]# bin/hdfs namenode -bootstrapStandby
启动集群下DataNode
[root@hop01 hadoop2.7]# sbin/hadoop-daemons.sh start datanode
NN1设置为Active状态
先启动hop01即可,然后启动hop02。
[root@hop01 hadoop2.7]# sbin/hadoop-daemon.sh start zkfc
hop01启动yarn
[root@hop01 hadoop2.7]# sbin/start-yarn.sh
hop02启动ResourceManager
[root@hop02 hadoop2.7]# sbin/yarn-daemon.sh start resourcemanager
查看状态
[root@hop01 hadoop2.7]# bin/yarn rmadmin -getServiceState rm1
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent
推荐阅读:编程体系整理
| 序号 | 项目名称 | GitHub地址 | GitEE地址 | 推荐指数 |
|---|---|---|---|---|
| 01 | Java描述设计模式,算法,数据结构 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 02 | Java基础、并发、面向对象、Web开发 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆ |
| 03 | SpringCloud微服务基础组件案例详解 | GitHub·点这里 | GitEE·点这里 | ☆☆☆ |
| 04 | SpringCloud微服务架构实战综合案例 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 05 | SpringBoot框架基础应用入门到进阶 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆ |
| 06 | SpringBoot框架整合开发常用中间件 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 07 | 数据管理、分布式、架构设计基础案例 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 08 | 大数据系列、存储、组件、计算等框架 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
Hadoop框架:HDFS高可用环境配置的更多相关文章
- HDFS 高可用分布式环境搭建
HDFS 高可用分布式环境搭建 作者:Grey 原文地址: 博客园:HDFS 高可用分布式环境搭建 CSDN:HDFS 高可用分布式环境搭建 首先,一定要先完成分布式环境搭建 并验证成功 然后在 no ...
- 大数据学习(07)——Hadoop3.3高可用环境搭建
前面用了五篇文章来介绍Hadoop的相关模块,理论学完还得操作一把才能加深理解.这一篇我会花相当长的时间从环境搭建开始,到怎么在使用Hadoop,逐步介绍Hadoop的使用. 本篇分这么几段内容: 规 ...
- 使用KeepAlived搭建MySQL高可用环境
使用KeepAlived搭建MySQL的高可用环境.首先搭建MySQL的主从复制在Master开启binlog,创建复制帐号,然后在Slave输入命令 2016年7月25日 配置安装技巧: ...
- Jumpserver双机高可用环境部署笔记
之前在IDC部署了Jumpserver堡垒机环境,作为登陆线上服务器的统一入口.后面运行一段时间后,发现Jumpserver服务器的CPU负载使用率高达80%以上,主要是python程序对CPU的消耗 ...
- Haproxy+Keepalived高可用环境部署梳理(主主和主从模式)
Nginx.LVS.HAProxy 是目前使用最广泛的三种负载均衡软件,本人都在多个项目中实施过,通常会结合Keepalive做健康检查,实现故障转移的高可用功能. 1)在四层(tcp)实现负载均衡的 ...
- LVS+Keepalived 高可用环境部署记录(主主和主从模式)
之前的文章介绍了LVS负载均衡-基础知识梳理, 下面记录下LVS+Keepalived高可用环境部署梳理(主主和主从模式)的操作流程: 一.LVS+Keepalived主从热备的高可用环境部署 1)环 ...
- redis-3.0.1 sentinel 主从高可用 详细配置
最近项目上线部署,要求redis作高可用,由于redis cluster还不是特别成熟,就选择了redis sentinel做高可用.redis本身有replication,实现主从备份.结合sent ...
- 阶段5 3.微服务项目【学成在线】_day09 课程预览 Eureka Feign_03-Eureka注册中心-搭建Eureka高可用环境
1.3.2.2 高可用环境搭建 Eureka Server 高可用环境需要部署两个Eureka server,它们互相向对方注册.如果在本机启动两个Eureka需要 注意两个Eureka Server ...
- Eureka高可用环境搭建
1.创建govern-center 子工程 包结构:com.dehigher.govern.center 2.pom文件 (1)父工程pom,用于依赖版本管理 <dependencyManage ...
随机推荐
- kubernetes的思考
初识k8s kubernetes,从接触到今年6月接触到现在有3个月了,严格来说是断断续续的接触,没有一直持续学习.在未接触之前,这个技术对我来说,有点像传说,运维同行对此评价普遍是比较难懂,概念庞大 ...
- 学习OpenGL
重要!!! OpenGL新人一枚,希望可以再此和大家分享有用的知识,少走弯路 文章会定期更新,把前面几段已经整理过的知识更完后,接下来每周至少会更两次. 文章如果有不对的,理解错误的地方,也非常希望在 ...
- 安装Angular CLI开发工具
目前,无论你使用什么前端框架,都必然要用到NodeJS工具,Angular也不例外,与其他框架不同的是,Angular一开始就使用"全家桶"式的设计思路,因此@angular/cl ...
- Linux基本命令学习
对操作系统进行信息查询 硬盘大小 查看磁盘信息: fdisk -l/dev/sda 操作系统中第一块硬盘的名称以及所在路径linux操作系统中一切皆文件(文件名) sd(硬 ...
- spring aop 源码分析(二) 代理方法的执行过程分析
在上一篇aop源码分析时,我们已经分析了一个bean被代理的详细过程,参考:https://www.cnblogs.com/yangxiaohui227/p/13266014.html 本次主要是分析 ...
- P3378 堆(模板)
P3378 [模板]堆 题目描述 给定一个数列,初始为空,请支持下面三种操作: 给定一个整数 x,请将 x 加入到数列中. 输出数列中最小的数. 删除数列中最小的数(如果有多个数最小,只删除 1 个) ...
- Metasploit简单使用——后渗透阶段
在上文中我们复现了永恒之蓝漏洞,这里我们学习一下利用msf简单的后渗透阶段的知识/ 一.meterperter常用命令 sysinfo #查看目标主机系统信息 run scraper #查看目标主机详 ...
- Linux 安装Navicat Premium 15
参考:https://gitee.com/andisolo/navicat-keygen 安装 aptitude 管理软件 $ sudo apt-get install aptitude 安装Navi ...
- Charles 模拟弱网
1.Charles安装方法: 1)在官网下载安装: 2)输入如下注册码破解,Charles 4.2.7 目前版本,可用. Registered Name: https://zhile.io ...
- Fabric1.4.4 多机solo共识搭建
简单记录一下fabric版本1.4.4的搭建部署,运行环境为CentOs7.8,如有错误欢迎批评指正.然后就是本编文章不对环境搭建做说明,基础环境搭建看这里. 1.总体设计 本案例部署一个排序(ord ...