Kafka学习笔记(三)——架构深入
之前搭建好了Kafka的学习环境,了解了具体的配置文件内容,并且测试了生产者、消费者的控制台使用方式,也学习了基本的API。那么下一步,应该学习一下具体的内部流程~
1、Kafka的工作流程
大致的工作流程图如下:

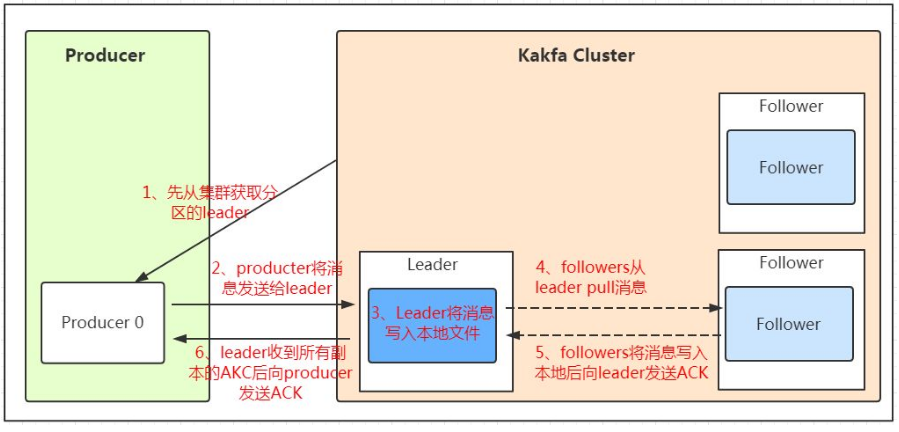
如图所示哈,整个工作环境包括:一个生产者(producer),一个消费者组(含有三个消费者),一个主题:A,三个节点(broker),三个分区(partition)和两个副本(副本数=leader数+follower数)。
分析一下大致工作流程:
- Producer是消息的生产者,首先Producer从集群中获取分区的leader,完了以后producer将消息发送给leader,leader将消息写入到本地文件。之后,follower要从leader这里主动同步数据。
- 图中所示,每一个分区中都有消息的编号,称为偏移量(offset),它的作用是可以让消费者追踪消息在分区里的位置。注意:这个偏移量不是全局的,而是分区独立使用的。因此,Kafka只保证区内消息有序(生产顺序和消费顺序相同)。
- Kafka中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的。
- topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是producer生产的数据。Producer生产的数据会被不断追加到该log文件末端(log文件太大的时候会被切分,之后再说),且每条数据都有自己的offset。
- 消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,出错复活之后,从上次的位置继续消费。
在网上找了一个图,还挺通俗的:
2、Kafka的文件存储机制

Producer 将数据写入 Kafka 后,集群就需要对数据进行保存了。Kafka 将数据保存在磁盘,可能在我们的一般的认知里,写入磁盘是比较耗时的操作,不适合这种高并发的组件。Kafka 初始会单独开辟一块磁盘空间,顺序写入数据(效率比随机写入高)。
2.1 Partition 结构
前面说过了每个 Topic 都可以分为一个或多个 Partition,如果你觉得 Topic 比较抽象,那 Partition 就是比较具体的东西了!
Partition 在服务器上的表现形式就是一个一个的文件夹,由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment。
每组 Segment 文件又包含 .index 文件、.log 文件、.timeindex 文件(早期版本中没有)三个文件。
log和index文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。例如,simon这个topic有2个分区,则其对应的文件夹为simon-0,simon-1:

log 文件就是实际存储 Message 的地方,而 index 和 timeindex 文件为索引文件,用于检索消息。

2.2 Message 结构
上面说到 log 文件就实际是存储 Message 的地方,我们在 Producer 往 Kafka 写入的也是一条一条的 Message。
那存储在 log 中的 Message 是什么样子的呢?消息主要包含消息体、消息大小、Offset、压缩类型……等等!
我们重点需要知道的是下面三个:
- Offset:Offset 是一个占 8byte 的有序 id 号,它可以唯一确定每条消息在 Parition 内的位置;
- 消息大小:消息大小占用 4byte,用于描述消息的大小;
- 消息体:消息体存放的是实际的消息数据(被压缩过),占用的空间根据具体的消息而不一样。
index和log文件以当前segment的第一条消息的offset命名,下图为index文件和log文件的结构示意图:
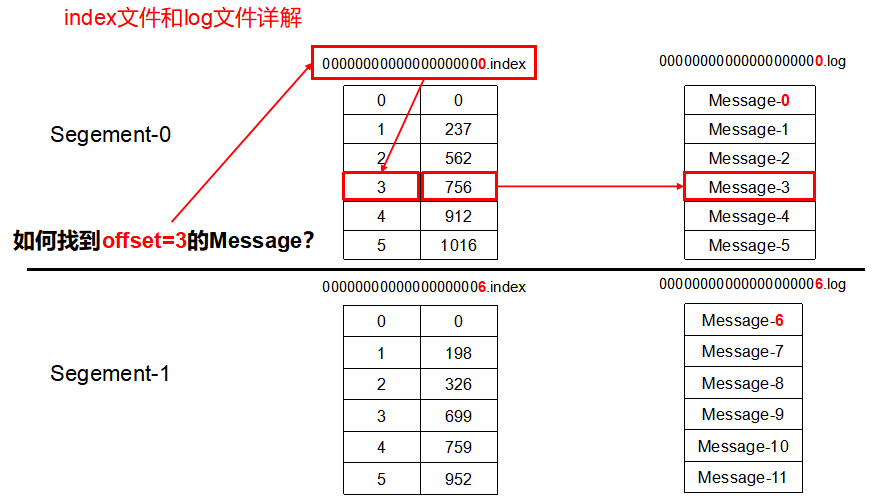
例如:进入simon-0目录下查看

2.3 存储策略
无论消息是否被消费,Kafka 都会保存所有的消息。那对于旧数据有什么删除策略呢?
- 基于时间,默认配置是 168 小时(7 天);
- 基于大小,默认配置是 1073741824。
需要注意的是,Kafka 读取特定消息的时间复杂度是 O(1),所以这里删除过期的文件并不会提高 Kafka 的性能!
3、Kafka的生产者
3.1 分区策略
1)为什么要分区呢 ?
- 方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;【提高负载能力】
- 可以提高并发,因为可以以Partition为单位读写了。
2)分区的原则
我们需要将producer发送的数据封装成一个ProducerRecord对象。

(1)指明 partition 的情况下,直接将指明的值直接作为 partiton 值;
(2)没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
(3)既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的 round-robin 算法。
3.2 数据可靠性保证
为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,都需要向producer发送ack(acknowledgement确认收到),如果producer收到ack,就会进行下一轮的发送,否则重新发送数据。
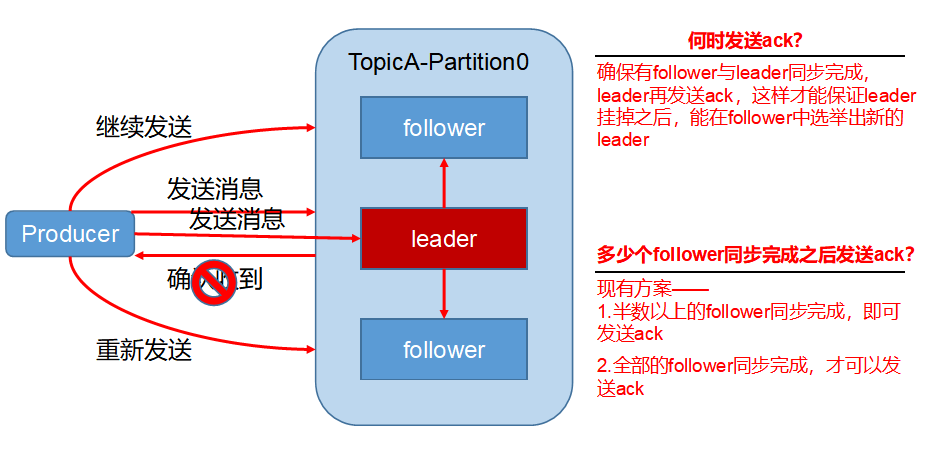
1)副本数据同步策略
| 方案 | 优点 | 缺点 |
|---|---|---|
| 半数以上完成同步,就发送ack | 延迟低 | 选举新的leader时,容忍n台节点的故障,需要2n+1个副本 |
| 全部完成同步,才发送ack | 选举新的leader时,容忍n台节点的故障,需要n+1个副本 | 延迟高 |
Kafka选择了第二种方案,原因如下:
同样为了容忍n台节点的故障,第一种方案需要2n+1个副本,而第二种方案只需要n+1个副本,而Kafka的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。
虽然第二种方案的网络延迟会比较高,但网络延迟对Kafka的影响较小。
留下一个疑问:既然是全部follower同步完成才发Ack,那么如果有一个follower在同步之前挂了,岂不是永远无法发送ack?哎,这就有了ISR机制~~
2)ISR
采用第二种方案之后,设想一下:leader收到数据,所有的follower都开始同步数据,但是有一个follower,因为某种故障迟迟无法与leader同步,那么leader就要一直等下去,直到它同步完成,才能发生ack,这样的问题如何解决呢?
Leader维护了一个动态的in-sync replica set (ISR),意为和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,leader就会给follower发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由replica.lag.time.max.ms参数设定。Leader发生故障之后,就会从ISR中选举新的leader。
注意:在旧的版本中有两种踢出策略,一个是follower同步消息过慢,另一种是follower和leader的数据量相差过大(默认是10000),新的版本仅保留了前者。原因是:producer发送数据的单位是batch,假如一个batch中包含有12000条数据的话,那么ISR中的所有follower都会被踢出,待同步完成之后又会被加回来。如此往复几次的话,就会造成大量的资源开销,所以这个策略被弃用了。
3)ack应答机制
按照思路继续往下走,当follower同步完成数据之后,leader返回给producer信号,通知它已经收到了,你可以继续往下发数据。
但是,并不是所有的follower很快就能同步完成数据,对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等ISR中的follower全部接收成功。
所以Kafka为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择以下的配置。
acks参数配置:
acks:
0【不需要确认,直接连发】:producer不等待broker的ack,这一操作提供了一个最低的延迟,broker一接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据;
1【只等leader写完】:producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据;

- -1【等leader和follower都写完】:producer等待broker的ack,partition的leader和ISR中的follower全部落盘成功后才返回ack。但是如果在follower同步完成后,broker发送ack之前,leader发生故障,那么会造成数据重复。(但是如果ISR中只有一个leader,就和acks=1的效果一样了)
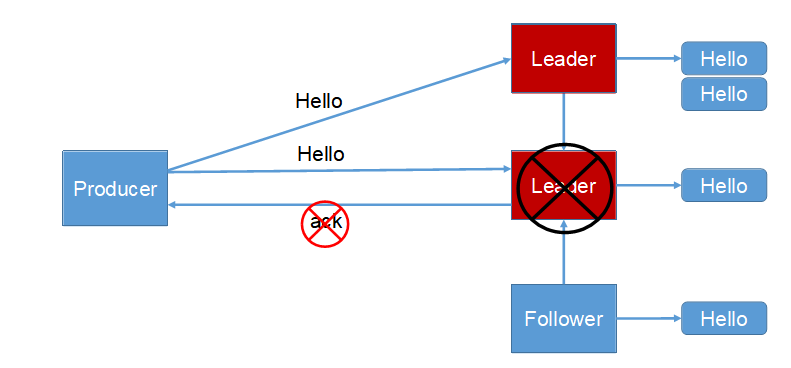
4)故障处理细节
假设一个场景:有一个leader写了10条数据,ISR中有F1(写了8条数据),F2(写了9条数据)。如果leader挂了,选择了F1成为新的leader,那么问题就显而易见了,F1和F2的数据不一致了。如果选择F2当leader,但是原来的leader又诈尸了,活过来了,那么数据又出现不一致了。这么一来,消费者不得疯了嘛。。。仁慈而又伟大的Kafka开发人员怎么会想不到这个问题呢,且看:
如下图:leader中现在有19条数据,F1和F2分别有12、15条数据,某一时刻,出故障了~
注意:LEO:指每个副本最大的offset,
HW:指的是消费者能见到的最大的offset,ISR中最小的LEO [保证消费者消费的一致性]
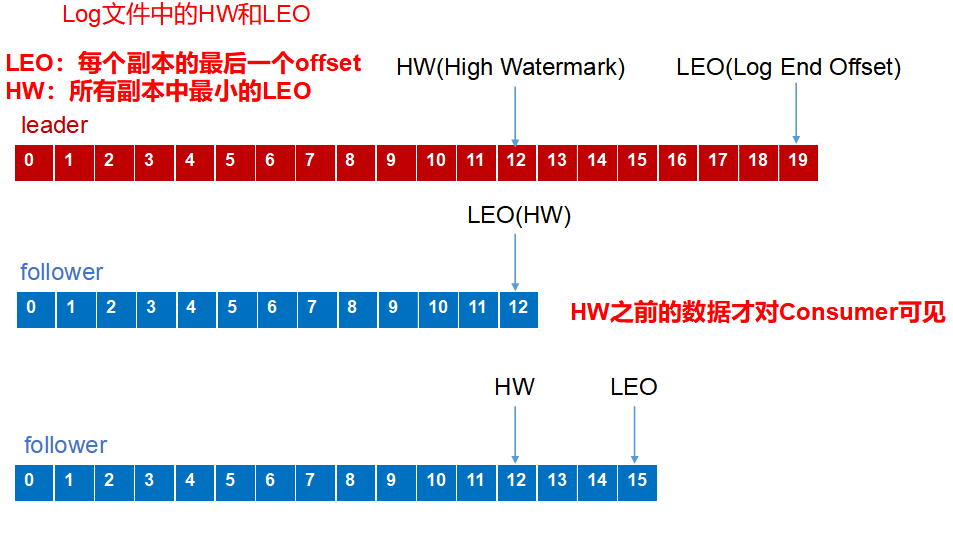
① follower故障:
follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉(过长,就把它切掉~),从HW开始向leader进行同步。等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
② leader故障
leader发生故障之后,会从ISR中选出一个新的leader。之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。(老大通知小弟,把个人主义切掉,再把比我少的补上~)
注意:不要搞混,这只能保证副本之间的数据一致性,ack机制才能保证数据不丢失或者不重复。
3.3 Exactly Once语义
将服务器的 ACK 级别设置为-1,可以保证 Producer 到 Server 之间不会丢失数据,但是有可能重复数据,即 At Least Once 语义。相对的,将服务器 ACK 级别设置为 0,可以保证生产者每条消息只会被发送一次,即 At Most Once 语义。
At Least Once 可以保证数据不丢失,但是不能保证数据不重复;相对的,At Least Once可以保证数据不重复,但是不能保证数据不丢失。但是,对于一些非常重要的信息,比如说交易数据,下游数据消费者要求数据既不重复也不丢失,即 Exactly Once 语义。在 0.11 版本以前的 Kafka,对此是无能为力的,只能保证数据不丢失,再在下游消费者对数据做全局去重。对于多个下游应用的情况,每个都需要单独做全局去重,这就对性能造成了很大影响。
0.11 版本的 Kafka,引入了一项重大特性:幂等性。所谓的幂等性就是指 Producer 不论向 Server 发送多少次重复数据,Server 端都只会持久化一条。幂等性结合 At Least Once 语义,就构成了 Kafka 的 Exactly Once 语义。即:
At Least Once + 幂等性 = Exactly Once
要启用幂等性,只需要将 Producer 的参数中 enable.idompotence 设置为 true 即可。Kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。开启幂等性的 Producer 在初始化的时候会被分配一个 PID,发往同一 Partition 的消息会附带 Sequence Number。而Broker 端会对<PID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时,Broker 只会持久化一条。但是 PID 重启就会变化,同时不同的 Partition 也具有不同主键,所以幂等性无法保证跨分区跨会话的 Exactly Once。
4、Kafka消费者
4.1 消费方式
consumer采用pull(拉)模式从broker中读取数据。
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout。
4.2 分区分配策略
一个consumer group中有多个consumer,一个 topic有多个partition,所以必然会涉及到partition的分配问题,即确定那个partition由哪个consumer来消费。同一组里的不同消费者,不能消费同一分区。
Kafka有两种分配策略,RoundRobin和Range。
- RoundRobin模式:按组划分

- Range模式:按主题划分

什么时候会触发这些策略呢?一句话:当消费者组里的消费者个数发送变化的时候会重新分配。
4.3 offset的维护
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
假设有这么一个场景:一个消费者组里有消费者A,他消费着Topic t的三个分区t0、t1、t2分区里的数据,并且都消费到了0ffset=10。此时,消费者组里加入了消费者B,那么就会触发分区分配策略。假设分区t2被分给了B。那么,B应该从哪里开始消费呢?是从头还是从offset=10 ? --很明显哈,是从offset=10接着消费。如果是从头消费呢,一旦扩充消费者组,每次都从头消费,造成了多次重复消费相同的数据。注意:消费者组 + 主题 + 分区 = 唯一确定一个offset !!!
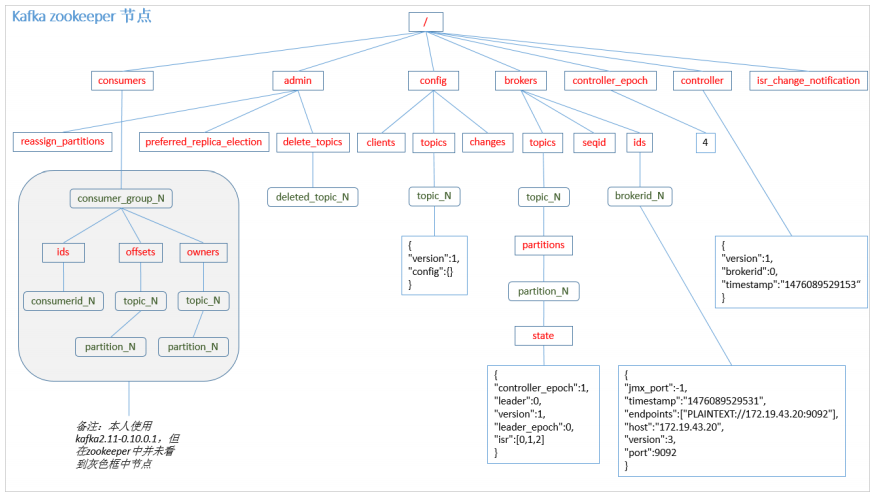
Kafka 0.9版本之前,consumer默认将offset保存在Zookeeper中,从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该Topic为__consumer_offsets.
Kafka的信息将被保存在zookeeper中,详细存储情况如下图:
5、Kafka高效读写数据
5.1 顺序读写
Kafka的producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到到600M/s,而随机写只有100k/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
5.2 零拷贝技术
零拷贝技术,可以有效的减少上下文切换和拷贝次数。kafka的设计实现,涉及到很多的底层技术,若希望能够把它吃透,需要花大量的时间,大量的精力。现在还是小菜鸡一名,今后任重道远 ~
5.3 Page Cache
为了优化读写性能,Kafka利用了操作系统本身的Page Cache,就是利用操作系统自身的内存而不是JVM空间内存。通过操作系统的Page Cache,Kafka的读写操作基本上是基于内存的,读写速度得到了极大的提升。
6、Zookeeper在Kafka中的作用
Kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。Controller的管理工作都是依赖于Zookeeper的。
简述一下partition的leader的选举过程:

Kafka学习笔记(三)——架构深入的更多相关文章
- Kafka 学习笔记之 架构
Kafka的概念: 1. AMQP协议 Advanced Message Queuing Protocol (高级消息队列协议) The Advanced Message Queuing Protoc ...
- 大数据 -- kafka学习笔记:知识点整理(部分转载)
一 为什么需要消息系统 1.解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险.许多 ...
- kafka学习笔记(一)消息队列和kafka入门
概述 学习和使用kafka不知不觉已经将近5年了,觉得应该总结整理一下之前的知识更好,所以决定写一系列kafka学习笔记,在总结的基础上希望自己的知识更上一层楼.写的不对的地方请大家不吝指正,感激万分 ...
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- 学习笔记(三)--->《Java 8编程官方参考教程(第9版).pdf》:第十章到十二章学习笔记
回到顶部 注:本文声明事项. 本博文整理者:刘军 本博文出自于: <Java8 编程官方参考教程>一书 声明:1:转载请标注出处.本文不得作为商业活动.若有违本之,则本人不负法律责任.违法 ...
- [Big Data - Kafka] kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- 物联网学习笔记三:物联网网关协议比较:MQTT 和 Modbus
物联网学习笔记三:物联网网关协议比较:MQTT 和 Modbus 物联网 (IoT) 不只是新技术,还是与旧技术的集成,其关键在于通信.可用的通信方法各不相同,但是,各种不同的协议在将海量“事物”连接 ...
- Oracle学习笔记三 SQL命令
SQL简介 SQL 支持下列类别的命令: 1.数据定义语言(DDL) 2.数据操纵语言(DML) 3.事务控制语言(TCL) 4.数据控制语言(DCL)
- [Firefly引擎][学习笔记三][已完结]所需模块封装
原地址:http://www.9miao.com/question-15-54671.html 学习笔记一传送门学习笔记二传送门 学习笔记三导读: 笔记三主要就是各个模块的封装了,这里贴 ...
- JSP学习笔记(三):简单的Tomcat Web服务器
注意:每次对Tomcat配置文件进行修改后,必须重启Tomcat 在E盘的DATA文件夹中创建TomcatDemo文件夹,并将Tomcat安装路径下的webapps/ROOT中的WEB-INF文件夹复 ...
随机推荐
- 记录一次利用 python 进行日志模块开发过程
只记录大体思路和我认为其中需要记录的地方. 正则匹配 正则匹配的模式很难记忆,即使记住了,也很难写出无错误的匹配模式.但是,借助网上一些提供实时对比的网站,如 regexr.com. 代码示意: im ...
- poi导入读取时间格式问题
万能处理方案: 所有日期格式都可以通过getDataFormat()值来判断 yyyy-MM-dd-----14 yyyy年m月d日--- 31 yyyy年m月-------57 m月d日 ---- ...
- HashMap多线程并发问题分析-正常和异常的rehash1(阿里)
多线程put后可能导致get死循环 从前我们的Java代码因为一些原因使用了HashMap这个东西,但是当时的程序是单线程的,一切都没有问题.后来,我们的程序性能有问题,所以需要变成多线程的,于是,变 ...
- 【Beta】Scrum meeting 10
目录 写在前面 进度情况 任务进度表 Beta-1阶段燃尽图 遇到的困难 照片 commit记录截图 后端代码 前端代码 技术博客 写在前面 例会时间:5.14 22:30-22:45 例会地点:微信 ...
- DNS技术和NAT技术详解
DNS技术和NAT技术详解一.DNS(Domain Name System)1.什么是DNS2. 了解域名3.域名解析过程4.使用dig工具分析DNS过程5.浏览器输入URL后发生什么事?二.ICMP ...
- docker run 中的privileged参数
docker 应用容器 获取宿主机root权限(特殊权限-) docker run -d --name="centos7" --privileged=true centos:7 / ...
- 利用FUSE编写自定义的文件系统
FUSE--用户空间文件系统(Filesystem in Userspace),具体可以度娘,反正是简化了自定义文件系统的复杂度,可以更方便地利用自定义文件系统做一些事情. 一.使用 Python 编 ...
- unable to access android sdk add-on list的解决
第一次安装android studio时候弹出unable to access android sdk add-on list原因是你电脑没有SDK而且你下载的android studio又是不带SD ...
- [转]iview的render函数用法
原文地址:https://www.jianshu.com/p/f593cbc56e1d 一.使用html的标签(例如div.p) 原生标签用法 二.使用iview的标签(例如Button) iview ...
- CentOS7下NFS服务安装及配置固定端口
CentOS7下NFS服务安装及配置 系统环境:CentOS Linux release 7.4.1708 (Core) 3.10.0-693.el7.x86_64 软件版本:nfs-utils-1. ...