Self-paced Clustering Ensemble自步聚类集成论文笔记
0.摘要
- 现有的聚类集成方法大多利用所有的数据来学习一致的聚类结果,没有充分考虑一些困难实例所带来的不利影响。
- 为了解决这个问题,提出Self-Paced Clustering Ensemble(SPCE)方法。逐步将例子从简单到困难的纳入到集成学习中。
- 将实例的难易度评价和集成学习集成在一个框架中
- 联合学习算法获得最终的一致的聚类结果
1.introduction
传统聚类的问题
- 在给定的数据集中,不同的目标函数会有非常不同的结构。
- 没有ground truth
- 比如k-means,高度依赖初始化
clustering ensemble定义
- Clustering ensemble provides an elegant framework for combining multiple weak base clusterings of a data set to generate a consensus clustering.
之前的clustering ensemble方法
- information theoretic based clustering ensemble methods 基于信息论的集成聚类方法
[3] A. Strehl and J. Ghosh, “Cluster ensembles — a knowledge reuse framework for combining multiple partitions,” Journal of Machine Learning Research, vol. 3, no. 3, pp. 583–617, 2003.
[4] A. Topchy, A. K. Jain, and W. F. Punch, “Combining multiple weak clusterings,” in ICDM, 2003, pp. 331–338.
an alignment method to combine multiple k-means clustering results 一种组合多个k均值聚类结果的对齐方法
[5] Z. Zhou and W. Tang, “Clusterer ensemble,” Knowledge Based Systems, vol. 19, no. 1, pp. 77–83, 2006.
extended graph cut method into clustering ensemble 扩展图切割的方法到集成聚类
[8]X. Z. Fern and C. E. Brodley, “Solving cluster ensemble problems by bipartite graph partitioning,” in ICML, 2004, p. 36
spectral clustering based ensemble method 基于谱聚类的集成方法
[9] H. Liu, T. Liu, J. Wu, D. Tao, and Y. Fu, “Spectral ensemble clustering,” in SIGKDD, 2015, pp. 715–724.
[10] Z. Tao, H. Liu, and Y. Fu, “Simultaneous clustering and ensemble.” in AAAI, 2017, pp. 1546–1552.
utilized non-negative matrix factorization (NMF) to learn a consensus clustering result 利用非负矩阵分解来学习一致的聚类结果
[11] T. Li, C. H. Q. Ding, and M. I. Jordan, “Solving consensus and semisupervised clustering problems using nonnegative matrix factorization,” in ICDM, 2007, pp. 577–582.
[12] T. Li and C. H. Q. Ding, “Weighted consensus clustering.” in SDM, 2008, pp. 798–809.
introduced probabilistic graphical model into clustering ensemble 将概率图模型引入集成聚类
[13] H. Wang, H. Shan, and A. Banerjee, “Bayesian cluster ensembles,” in SDM, 2009, pp. 211–222.
[14] D. Huang, J. Lai, and C. Wang, “Ensemble clustering using factor graph,” Pattern Recognition, vol. 50, pp. 131–142, 2016.
- Besides these work which ensemble all base clustering results, some work tried to select some informative and non-redundant base clustering results for ensemble. 除了这些集合所有基本聚类结果的工作之外,还有的工作致力于为集成学习选择一些信息性和非冗余的基本聚类结果。
adaptive clustering ensemble selection method to select the base results 自适应聚类集成选择方法选择基础结果
[15] J. Azimi and X. Fern, “Adaptive cluster ensemble selection,” in Twenty-First International Joint Conference on Artificial Intelligence, 2009.
transferred the clustering selection to feature selection and designed a hybrid strategy to select base results 将聚类选择转移到特征选择并设计混合策略以选择基础结果
[16] Z. Yu, L. Li, Y. Gao, J. You, J. Liu, H. Wong, and G. Han, “Hybrid clustering solution selection strategy,” Pattern Recognition, vol. 47,no. 10, pp. 3362–3375, 2014.
Zhao et al. proposed internal validity indices for clustering ensemble selection 提出内部有效性指标来进行集成聚类选择
[17] X. Zhao, J. Liang, and C. Dang, “Clustering ensemble selection for categorical data based on internal validity indices,” Pattern Recognition, vol. 69, pp. 150–168, 2017.
存在问题
- 使用所有的数据进行聚类集成,可能有些样本很难聚类,甚至有些是异常值,可能会导致聚类性能差。
改进
- 将基础的聚类集成到课程学习(Curriculum Learning)框架中。
- 课程学习关键思想是,在早期,模型相对较弱,需要一些简单的实例进行训练;随着时间的推移,模型的能力越来越强,可以处理越来越多的困难实例;最后,它足够强大,可以处理几乎所有的实例。
- 将权重矩阵学习和一致连接矩阵学习集成在一个目标函数中。
- 将基础的聚类集成到课程学习(Curriculum Learning)框架中。
2.Related Work
2.1聚类集成相关定义
- 给定数据集,对数据集做m次聚类可以得到m个聚类结果 [Math Processing Error]C^i = \{C^1, C^2, …,C^m\}Ci={C1,C2,…,Cm},每一个聚类结果[Math Processing Error]C^iCi包含簇的集合[Math Processing Error]\{\pi_1^i,\pi_2^i,…,\pi_k^i\}{π1i,π2i,…,πki},[Math Processing Error]kk是[Math Processing Error]C^iCi中的簇的数目。
- 根据聚类结果可以得到实例之间的关系,根据[Math Processing Error]C^iCi可以构建连接矩阵[Math Processing Error]S^{(i)} \in R^{n*n}S(i)∈Rn∗n
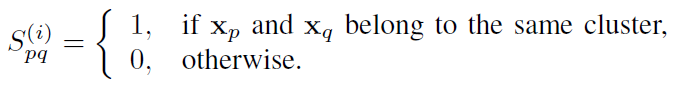
- 聚类集成的目标就是从[Math Processing Error]S^{(1)},S^{(2)},…,S^{(m)}S(1),S(2),…,S(m)中学习一个一致矩阵[Math Processing Error]SS,最后的聚类结果就可以直接从[Math Processing Error]SS中获得。
2.2Self-paced Learning自步学习
[Math Processing Error]f(\omega_i, \lambda)f(ωi,λ)是自步正则化项,最优的[Math Processing Error]\omega_i^*ωi∗随着[Math Processing Error]\lambdaλ的增加而增加,随着[Math Processing Error]l_ili的增加而减小。也就是说损失越小,越简单,权重越大,越先学习。[Math Processing Error]\lambdaλ随着学习的过程的进行而增加,越来越多的实例被采用。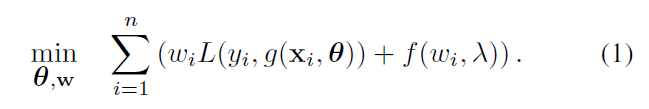
3.自步聚类集成
目标函数
- (1)S是一致矩阵,我们希望使得它与所有连接矩阵之间的差异性越小越好,既 [Math Processing Error]\sum_{i=1}^m\Vert S-S^{(i)}\Vert_F^2∑i=1m∥S−S(i)∥F2
- (2)但是不能每种结果都是相同的权重,加个权重:[Math Processing Error]\sum_{i=1}^m\alpha_i\Vert S-S^{(i)}\Vert_F^2∑i=1mαi∥S−S(i)∥F2
- (3)[Math Processing Error]\alphaα的取值采用auto-weighted的方法,定义[Math Processing Error]\alpha_i=\frac{1}{\Vert S-S^(i)\Vert_F}αi=∥S−S(i)∥F1,也就是说越相似,权重越大。objective function:
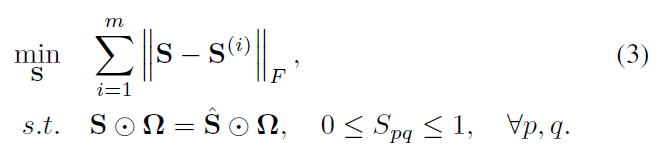
- (4)添加自步学习框架:添加自步函数 [Math Processing Error]f(W, \lambda)=-\lambda\Vert W\Vert_1f(W,λ)=−λ∥W∥1
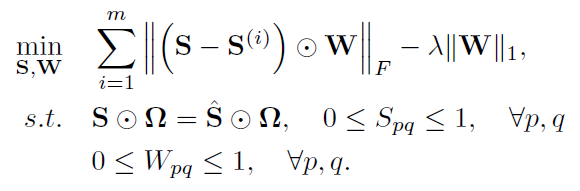
- (5)Theorem 1 说明如果S的拉普拉斯矩阵的秩为 n-c,就可以直接得到一致矩阵有c个连通分量,也就是c个簇。所以添加约束[Math Processing Error]rank(L)=n-crank(L)=n−c。

- (6)又希望一致矩阵S尽可能的稀疏,这样得到的聚类结果会更加清晰,会占喜出更加清晰的图结构、聚类结构。所以对S添加一个一范约束。[Math Processing Error]\gammaγ是调节S稀疏程度的超参数。

优化
Self-paced Clustering Ensemble自步聚类集成论文笔记的更多相关文章
- 挑子学习笔记:两步聚类算法(TwoStep Cluster Algorithm)——改进的BIRCH算法
转载请标明出处:http://www.cnblogs.com/tiaozistudy/p/twostep_cluster_algorithm.html 两步聚类算法是在SPSS Modeler中使用的 ...
- Using SMOTEBoost(过采样) and RUSBoost(使用聚类+集成学习) to deal with class imbalance
Using SMOTEBoost and RUSBoost to deal with class imbalance from:https://aitopics.org/doc/news:1B9F7A ...
- 【Ensemble methods】组合方法&集成方法
机器学习的算法中,讨论的最多的是某种特定的算法,比如Decision Tree,KNN等,在实际工作以及kaggle竞赛中,Ensemble methods(组合方法)的效果往往是最好的,当然需要消耗 ...
- iOS开发- 三步快速集成社交化分享工具ShareSDK
1.前言 作为现在App里必不可少的用户分享需要,社交化分享显然是我们开发app里较为常用的. 最近因为公司App有社交化分享的需要,就特此研究了会,拿出来与大家分享. 想要集成社交会分享,我们可以使 ...
- iOS- 三步快速集成社交化分享工具ShareSDK
http://www.cnblogs.com/qingche/p/3727559.html 1.前言 作为现在App里必不可少的用户分享需要,社交化分享显然是我们开发app里较为常用的. 最近因为公司 ...
- Hierarchical clustering:利用层次聚类算法来把100张图片自动分成红绿蓝三种色调—Jaosn niu
#!/usr/bin/python # coding:utf-8 from PIL import Image, ImageDraw from HierarchicalClustering import ...
- 机器学习-聚类-k-Means算法笔记
聚类的定义: 聚类就是对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小,它是无监督学习. 聚类的基本思想: 给定一个有N个对象的数据集 ...
- Typecho集成ueditor笔记
前言:萝卜青菜各有所爱,因为个人需求所以需要在博客中集成ueditor,并非是我不喜欢md语法 其实本篇的笔记的书写最早也是在本地的md编辑器上完成的 1. 首先下载ueditor编辑器,然后重命名文 ...
- php持续集成环境笔记
记录下php集成环境中若干个工具的安装步骤和过程: 安装pear wget http://pear.php.net/go-pear.phar $ php go-pear.phar 使用:pear in ...
随机推荐
- SDSC2019【游记】
目录 SDSC2019 游记 Day0 Day 1 Day2 Day3 Day4 Day5 Day6 Day 7 Day8 SDSC2019 游记 Day0 这次夏令营在日照某大学举行,我很想夸一夸喷 ...
- 【JZOJ6227】【20190621】ichi
题目 $n , m ,d,x\le 10^5 , $强制在线 题解 对原树做dfs,得到原树的dfs序 对kruksal重构树做dfs,得到重构树的dfs序 那么就是一个三维数点问题 强制在线并且卡空 ...
- Vue中插槽slot的使用
插槽,也就是slot,是组件的一块HTML模板,这块模板显示不显示.以及怎样显示由父组件来决定. 实际上,一个slot最核心的两个问题在这里就点出来了,是显示不显示和怎样显示. 由于插槽是一块模板,所 ...
- 【python驱动】python进行selenium测试时GeckoDriver放在什么地方?
背景:用python进行selenium 关于b/s架构的测试,需要配置驱动否则程序无法执行 情况1:windows下放置GeckoDriver 步骤1:下载驱动 GeckoDriver下载地址fir ...
- Beta冲刺(3/5)
队名:無駄無駄 组长博客 作业博客 组员情况 张越洋 过去两天完成了哪些任务 数据库实践的报告 提交记录(全组共用) 接下来的计划 加快校园百科的进度 还剩下哪些任务 学习软工的理论课 学习代码评估. ...
- vim 注释颜色
方法一 修改 vim 配置文件 /etc/vim/vimrc (1)用vim打开 /etc/vim/vimrc文件 (2)按大写 ‘G’ 到最后一行,插入 hi comment ctermfg=6 ...
- K8S API对象
POD Pod是在K8s集群中运行部署应用或服务的最小单元,它是可以支持多容器的.Pod的设计理念是支持多个容器在一个Pod中共享网络地址和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合 ...
- 第10组 Beta冲刺(2/5)
链接部分 队名:女生都队 组长博客: 博客链接 作业博客:博客链接 小组内容 恩泽(组长) 过去两天完成了哪些任务 描述 新增修改用户信息.任务完成反馈等功能API 服务器后端部署,API接口的bet ...
- sip user Authentication and 401
https://www.vocal.com/sip-2/sip-user-authentication/ https://tools.ietf.org/html/rfc3261 SIP User Au ...
- XCode教程之 如何在苹果开发者平台添加设备UDID
XCode教程之 如何在苹果开发者平台添加设备UDID.在Xcode开发中,如何在苹果开发者平台添加新的手机设备UDID,进行测试,具体如下 工具/原料 Apple Developer 方法/步骤 1 ...