爬虫请求库之requests库
一、介绍
介绍:使用requests可以模拟浏览器的请求,比之前的urllib库使用更加方便 注意:requests库发送请求将网页内容下载下来之后,并不会执行js代码,这需要我们自己分析目标站点然后发起新的request请求 安装:pip install requests 常用的请求方式:requests.get(),requests.post()
二、基于GET请求
1.基本请求
import requests
res = requests.get('http://www.baidu.com')
res.encoding='utf-8'
print(res.text) #获取百度首页页面html代码
2.带参数的GET请求-->params
自己拼接GET参数 (在?后面拼接参数)
#加上请求头headers伪装成浏览器,百度才会正常返回页面,不一定只加User-agent,每个网站需要加不一样的请求头参数,需要自己慢慢试
import requests res = requests.get('https://www.baidu.com/s?wd=python', #?拼接路径
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
})
res.encoding='utf-8'
print(res.text)
注意:如果拼接的参数是中文或者有其他特殊符号,则不得进行url编码,使用下面这种方式
params参数使用
import requests
res = requests.get('https://www.baidu.com/s',
params={
'wd':'python'
},
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
})
res.encoding='utf-8'
print(res.text)
3.带参数的GET请求-->headers
#通常我们在发送请求时需要带上请求头,请求头是将自身伪装成浏览器的关键,请求头headers中常见的参数如下:
Host
Referer #大型网站通常都会根据该参数判断请求的来源
User-Agent
Cookie #cookie信息虽然包含在请求头内,但requests模块有单独的参数来处理它,所以在headers中就不需要放它了
4.带参数的GET请求-->cookies
比如登录了某个网站,然后从浏览器获取cookies,以后就可以直接拿着cookie登录了,无需输入用户名密码
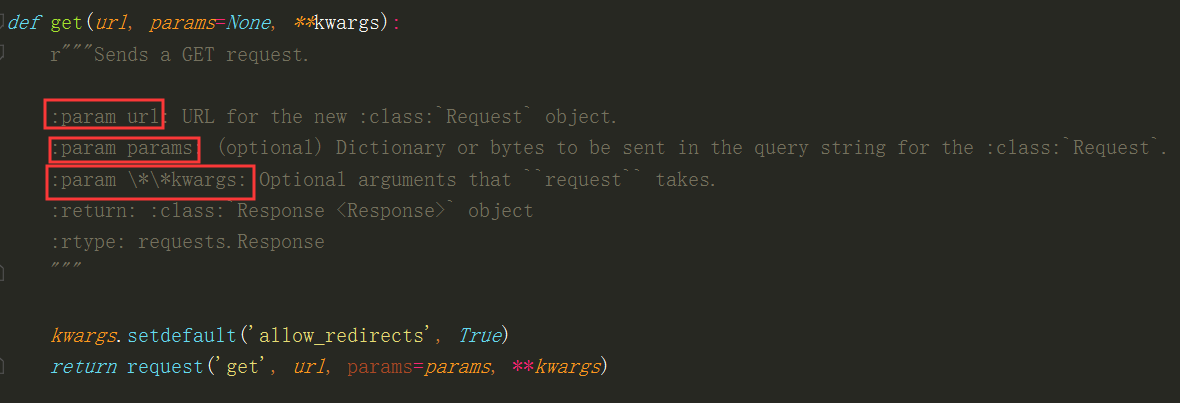
Requests库get请求参数源码:
三、基于POST请求
1、介绍
#GET请求方式
HTTP默认的请求方式是GET
没有请求体
数据必须在1k之内
GET请求数据会暴露在浏览器的地址栏中(不安全) GET请求常用的操作:
1.在浏览器的地址栏中直接给出url,那么就一定是GET请求
2.点击页面上的超链接也一定是GET请求
3.提交表单时,表单默认使用GET请求,但可以设置为POST #POST请求方式
1.数据不会出现在地址栏中
2.数据的大小没有上限
3.有请求体data 请求体就类似于,在登录某网站使用的用户名和密码
4.请求体中如果存在中文,会使用url编码
注意:requests.post()用法与requests.get()完全一致,特殊的是requests.post()有一个data参数,用来存放请求体参数
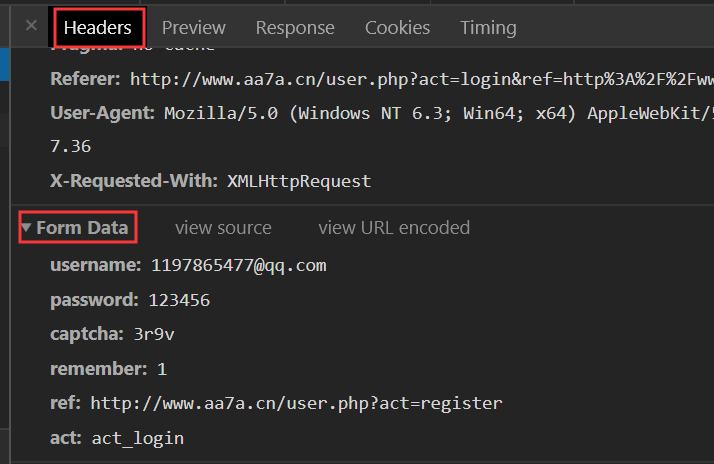
Requests库post请求参数源码(data参数)

data参数在Headers Form Data中获取
2.模拟登录某网站
import requests #设置headers请求头
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36',
'Referer': 'http://www.aa7a.cn/'
} #登录网站,需要传入data请求体参数
response = requests.post('http://www.aa7a.cn/user.php',
data={
'username': '1197865477@qq.com',
'password': 'wcc123',
'captcha': 'dbcn',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}) #登录网站后,网页会保存登录cookie,获取这个cookie
cookie=response.cookies.get_dict()#登录之后,会跳转到首页,向首页发送get请求,获取登录后页面html,带上headers和cookies
res = requests.get('http://www.aa7a.cn/',headers=headers,cookies=cookie)
if '1197865477@qq.com' in res.text:
print('登录成功')
else:
print('登录失败')
流程分析:
先post请求模拟登录,带上data请求体参数和headers参数,登录成功之后,用get请求获取页面,检验是否登录成功。
四、响应Response
1.response属性
import requests
respone=requests.get('http://www.jianshu.com')
# respone属性
print(respone.text)
print(respone.content) print(respone.status_code)
print(respone.headers)
print(respone.cookies)
print(respone.cookies.get_dict())
print(respone.cookies.items()) print(respone.url)
print(respone.history) print(respone.encoding) #关闭:response.close()
from contextlib import closing
with closing(requests.get('xxx',stream=True)) as response:
for line in response.iter_content():
pass
2.编码问题 (有些页面需要设置,不设置页面就会乱码)
import requests
response=requests.get('http://www.baidu.com')
response.encoding='utf-8'
print(response.text)
3.获取二进制数据 (针对于很大的文件用iter_cntent方法)
#stream参数:一点一点取,比如下载很大的视频,用response.content一下子全部写到文件中是不合理的
import requests response=requests.get('请求路由地址',stream=True)
with open('b.mp4','wb') as f:
for line in response.iter_content():
f.write(line)
4.解析json
#解析json import requests
response=requests.get('http://httpbin.org/get') import json
res1=json.loads(response.text) #这种反序列化的方式太麻烦了 res2=response.json() #直接获取到json数据
print(res1==res2) #True
返回值Response源码可以获取的属性(不止以下的这些属性,还有一些其他的)

五、高级用法
1、SSL (https协议)一般都不会校验,直接用第一种方法就行
#证书验证(大部分网站都是https)
import requests
response=requests.get('http://www.12306.cn') #如果是ssl请求,首先校验证书是否合法,不合法直接终止程序 #改进1:不进行校验,但是会报警告
import requests
response=requests.get('https://www.12306.cn',verify=False) #不校验证书,报警告
print(response.status_code) #返回200 #改进2:去掉报错,并且去掉警报信息
import requests
from requests.packages import urllib3
urllib3.disable_warings() #关闭警告
response=requests.get('https://www.12306.cn',verify=False)
print(response.status_code) #改进3:加上证书
#很多网站都是https,但是不用证书也可以,某些网站需要携带证书
import requests
response=requests.get('https://www.12306.cn',cert('/path/server.crt','/path/key')) #证书地址
print(response.status_code)
2.使用代理 (在网上找一些免费代理ip)
#代理设置:先发送请求给代理,然后由代理帮忙发送 (这个就是正向代理) import requests
proxies={
'http':'49.70.94.204:9999',
'https':'113.194.48.33:9999' }
response=requests.get('https://12306.cn',proxies=proxies)
print(response.status_code) #返回200代表这个代理ip可以使用
3.超时设置
#超时设置
#有两种超时:float 和 tuple
#timeout=0.1 #代表接收数据的超时时间,0.1秒之后没接收到就超时
#timeout=(0.1,0.2) #0.1代表链接超时 0.2代表接收数据的超时时间 import requests
response=requests.get('https:www.baidu.com',timeout=0.1)
4.上传文件
import requests
files = {'file':open('a.jpg','rb')}
response=requests.post('https://httpbin.org/post',files=files)
print(response.status_code)
爬取梨视频视频
流程:
1.先访问梨视频网站,选中某个类型,往下滑点击加载更多,在Network中获取实际请求的地址

访问实际的请求地址:


2.鼠标右击查看网页源代码,获取到这些视频的地址

前面拼接网址就能进行播放

3.在播放的页面,鼠标右击,点击查看网页源代码,发现真实的视频地址在js中

这个就是真实的视频地址,下载这个就能把这个视频下载下来
代码示例
import requests
import re
res=requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=2&start=0') #用正则方式获取视频id
reg_text = 'a href="(.*?)" class="vervideo-lilink actplay"'
obj=re.findall(reg_text,res.text) #正则匹配
#for循环取出视频id,访问地址,获取真实视频地址mp4
for urls in obj:
url = 'https://www.pearvideo.com/' + urls
res1 = requests.get(url) #请求单独的视频地址
obj1 = re.findall('srcUrl="(.*?)"',res1.text) #获取到mp4地址
name = obj1[0].rsplit('/',1)[1] #获取视频的名字,用来做保存在本地文件的名字。切割地址,从右边切一次,取索引1的
print(name)
res2 = requests.get(obj1[0]) #二进制数据
with open(name,'wb') as f: #二进制读取
for line in res2.iter_content():
f.write(line)
爬虫请求库之requests库的更多相关文章
- (转)Python爬虫利器一之Requests库的用法
官方文档 以下内容大多来自于官方文档,本文进行了一些修改和总结.要了解更多可以参考 官方文档 安装 利用 pip 安装 $ pip install requests 或者利用 easy_install ...
- [python爬虫]Requests-BeautifulSoup-Re库方案--Requests库介绍
[根据北京理工大学嵩天老师“Python网络爬虫与信息提取”慕课课程编写 文章中部分图片来自老师PPT 慕课链接:https://www.icourse163.org/learn/BIT-10018 ...
- Python爬虫利器一之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- 网络爬虫必备知识之requests库
就库的范围,个人认为网络爬虫必备库知识包括urllib.requests.re.BeautifulSoup.concurrent.futures,接下来将结对requests库的使用方法进行总结 1. ...
- python网络爬虫(三)requests库的13个控制访问参数及简单案例
酱酱~小编又来啦~
- 【Python爬虫】HTTP基础和urllib库、requests库的使用
引言: 一个网络爬虫的编写主要可以分为三个部分: 1.获取网页 2.提取信息 3.分析信息 本文主要介绍第一部分,如何用Python内置的库urllib和第三方库requests库来完成网页的获取.阅 ...
- 从0开始学爬虫12之使用requests库基本认证
从0开始学爬虫12之使用requests库基本认证 此处我们使用github的token进行简单测试验证 # coding=utf-8 import requests BASE_URL = " ...
- 从0开始学爬虫11之使用requests库下载图片
从0开始学爬虫11之使用requests库下载图片 # coding=utf-8 import requests def download_imgage(): ''' demo: 下载图片 ''' h ...
- python爬虫(八) requests库之 get请求
requests库比urllib库更加方便,包含了很多功能. 1.在使用之前需要先安装pip,在pycharm中打开: 写入pip install requests命令,即可下载 在github中有关 ...
随机推荐
- jsp解决大文件断点续传
我们平时经常做的是上传文件,上传文件夹与上传文件类似,但也有一些不同之处,这次做了上传文件夹就记录下以备后用. 这次项目的需求: 支持大文件的上传和续传,要求续传支持所有浏览器,包括ie6,ie7,i ...
- pgloader 学习(四)一些简单操作例子
上边已经说明了pgloader 的基本使用(篇理论),但是对于实际操作偏少,以下是一个简单的操作 不像官方文档那样,我为了方便,直接使用docker-compose 运行,同时这个环境,会在后边大部分 ...
- cube.js 学习(十一)cube + gitbase 分析git 代码
这个是一个简单的demo,使用gitbase+cube 分析git 仓库代码 需求 我们平时使用的gitlab,或者gogs 等git 仓库管理工具,有自己的管理强项,但是对于分析上可能就不是那么强大 ...
- JMX脚本在某些机器上报错,有的运行超时
运行超时的 是因为在server端运行命令执行脚本,是server给agent下达的指定,但是server端到agent的10050端口没开,所以或一致堵死在那,知道执行超时, 解决:开通server ...
- xamarin/xamarin.forms 在锁屏电源唤醒时保持后台运行
PARTIAL_WAKE_LOCK:保持CPU 运转,屏幕和键盘灯有可能是关闭的. SCREEN_DIM_WAKE_LOCK:保持CPU 运转,允许保持屏幕显示但有可能是灰的,允许关闭键盘灯 SCRE ...
- 洛谷 P4017 最大食物链计数 题解
P4017 最大食物链计数 题目背景 你知道食物链吗?Delia生物考试的时候,数食物链条数的题目全都错了,因为她总是重复数了几条或漏掉了几条.于是她来就来求助你,然而你也不会啊!写一个程序来帮帮她吧 ...
- Python各种扩展名(py, pyc, pyw, pyo, pyd)区别
扩展名 在写Python程序时我们常见的扩展名是py, pyc,其实还有其他几种扩展名.下面是几种扩展名的用法. py py就是最基本的源码扩展名 pyw pyw是另一种源码扩展名,跟py唯一的区别是 ...
- 「ZJOI2019」开关
传送门 Description 有一些一开始全都是关的开关,每次随机选择一个(每个开关概率不同)开关并改变它的状态,问达到目标状态的期望步数 Solution \(P=\sum_{i=1}^{n}p ...
- [SNOI2019]纸牌
传送门 Description 有一副纸牌.牌一共有\(n\)种,分别标有 \(1,2,...,n\),每种有\(C\)张.故这副牌共有\(nC\)张. 三张连号的牌(\(i,i+1,i+2\))或三 ...
- Ubuntu 安装MySQL报共享库找不到
错误信息1: ./mysqld: error : cannot open shared object file: No such file or directory 解决办法:安装改库 # apt-g ...