Python爬虫b站视频弹幕并生成词云图分析
爬虫:requests,beautifulsoup
词云:wordcloud,jieba
代码加注释:
# -*- coding: utf-8 -*-
import xlrd#读取excel
import xlwt#写入excel
import requests
import linecache
import wordcloud
import jieba
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup if __name__=="__main__":
yun="" n=0#ID编号
target='https://api.bilibili.com/x/v1/dm/list.so?oid=132084205'#b站oid页
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'
headers = {'User-Agent':user_agent}#伪装浏览器 req=requests.get(url=target)
html=req.text
html=html.encode('ISO 8859-1')
#html=html.replace('<br>',' ').replace('<br/>',' ').replace('/>','>')
bf=BeautifulSoup(html,"html.parser") texts=bf.find('i')
texts_div=texts.find_all('d')
#print(texts_div)
for item in texts_div:
n=n+1
item_name=item.text#标题
yun+=str(item_name) yun=yun.replace(" ","")
yun=yun.replace("哈","")
yun=yun.replace("啊","")
yun=yun.replace("一","")#去除无意义弹幕
# 结巴分词,生成字符串,wordcloud无法直接生成正确的中文词云
cut_text = " ".join(jieba.cut(yun))
wc = wordcloud.WordCloud(
#设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
font_path="C:/Windows/Fonts/simfang.ttf",
#设置了背景,宽高
background_color="white",width=1000,height=880).generate(cut_text) plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.show()
print("Done!")
运行结果图:
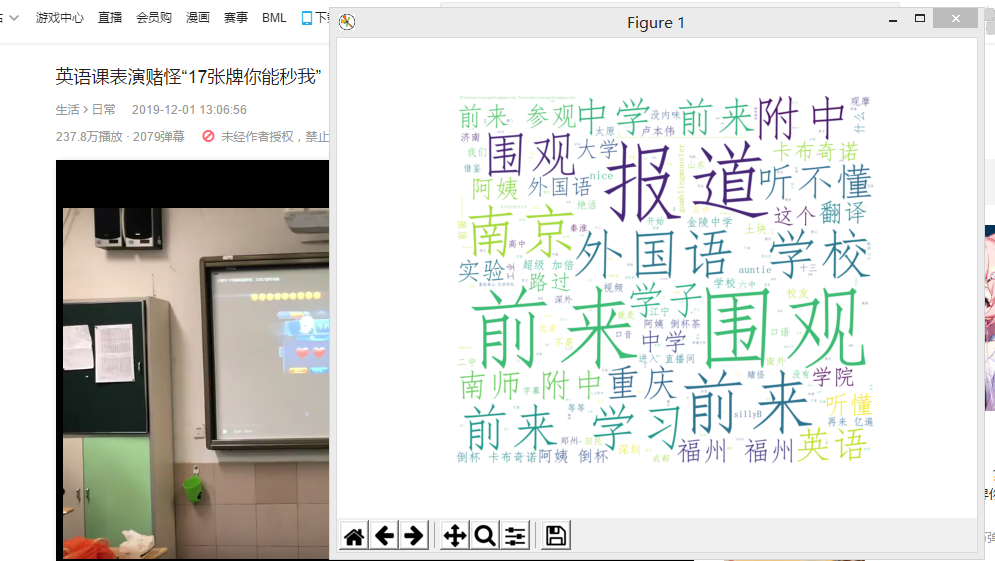
Python爬虫b站视频弹幕并生成词云图分析的更多相关文章
- python 爬取B站视频弹幕信息
获取B站视频弹幕,相对来说很简单,需要用到的知识点有requests.re两个库.requests用来获得网页信息,re正则匹配获取你需要的信息,当然还有其他的方法,例如Xpath.进入你所观看的视频 ...
- python爬虫抓站的一些技巧总结
使用python爬虫抓站的一些技巧总结:进阶篇 一.gzip/deflate支持现在的网页普遍支持gzip压缩,这往往可以解决大量传输时间,以VeryCD的主页为例,未压缩版本247K,压缩了以后45 ...
- 转载:用python爬虫抓站的一些技巧总结
原文链接:http://www.pythonclub.org/python-network-application/observer-spider 原文的名称虽然用了<用python爬虫抓站的一 ...
- 用python爬虫抓站的一些技巧总结 zz
用python爬虫抓站的一些技巧总结 zz 学用python也有3个多月了,用得最多的还是各类爬虫脚本:写过抓代理本机验证的脚本,写过在discuz论坛中自动登录自动发贴的脚本,写过自动收邮件的脚本, ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
- python根据文本生成词云图
python根据文本生成词云图 效果 代码 from wordcloud import WordCloud import codecs import jieba #import jieba.analy ...
- Python模块---Wordcloud生成词云图
wordcloud是Python扩展库中一种将词语用图片表达出来的一种形式,通过词云生成的图片,我们可以更加直观的看出某篇文章的故事梗概. 首先贴出一张词云图(以哈利波特小说为例): 在生成词云图之前 ...
- [转]用python爬虫抓站的一些技巧总结 zz
来源网站:http://www.pythonclub.org/python-network-application/observer-spider 学用python也有3个多月了,用得最多的还是各类爬 ...
- 用 python 爬虫抓站的一些技巧总结
学用python也有3个多月了,用得最多的还是各类爬虫脚本:写过抓代理本机验证的脚本,写过在discuz论坛中自动登录自动发贴的脚本,写过自动收邮件的脚本,写过简单的验证码识别的脚本,本来想写goog ...
随机推荐
- Building a Service Mesh with HAProxy and Consul
转自:https://www.haproxy.com/blog/building-a-service-mesh-with-haproxy-and-consul/ HashiCorp added a s ...
- check_monitor
#! /bin/bash # 声明agent配置文件路径 CONF=/etc/sdata/zabbix/zabbix_agentd.conf #CONF=/tmp/zabbix_agentd.conf ...
- SIGIR2018 Paper Abstract Reading Notes (1)
1.A Click Sequence Model for Web Search(日志分析) 更好的理解用户行为对于推动信息检索系统来说是非常重要的.已有的研究工作仅仅关注于建模和预测一次交互行为,例如 ...
- B. Heaters ( Codeforces Round #515 (Div. 3) )
题解:对于每个点 i 来说,从 j = i + r - 1 开始往前找,如果找到一个 a [ j ] 是 1 ,那么就把它选上,但是我们需要判断交界处,也就是如果前面选的那个可以让这个点变温暖,就不用 ...
- GoCN每日新闻(2019-10-04)
GoCN每日新闻(2019-10-04) 国庆专辑:GopherChina祝大家国庆节快乐 GoCN每日新闻(2019-10-04) 1. Go提议流程:代表 https://research.swt ...
- 文档流&浮动&定位
文档流指元素在文档中的位置由元素在html里的位置决定,块级元素独占一行,自上而下排列:内联元素从左到右排列脱离文档流的方式: 浮动,通过设置float属性 绝对定位,通过设置position:abs ...
- Linux Shell:根据指定的文件列表 或 map配置,进行文件位置转移
读取配置文件,进行文件位置转移 在whenb.csv中指定了需要从/home/root/cf/下移除到/home/root/cf_wh/下文件列表,whenb.csv中包含记录如下: enb- enb ...
- XmlIgnore的解释和使用
XmlIgnore是一个自定义属性,用来指明在序列化时是否序列化一个属性.如下面的例子: public class Group { public string GroupName; [XmlIgnor ...
- redis 服务器开放给其他电脑连接
1.云服务器的端口6379开通 2.宝塔服务器上的6379开通 3.修改服务器上的redis配置文件: # bind 127.0.0.1 注释掉daemonize no 改为noprotected-m ...
- mysql union all limit的使用
To apply ORDER BY or LIMIT to an individual SELECT, place the clause inside the parentheses that enc ...