基于Custom-metrics-apiserver实现Kubernetes的HPA(内含踩坑)
前言
这里要说一下Prometheus的检控指标从哪里来,它有3个渠道:
主机监控,也就是部署了Node Exporter组件的主机,它以DaemonSet或者系统进程的形式运行,Prometheus会从这里获取关于宿主机相关的资源指标
从Kubernetes自身组件,比如API Server或者Kubelet的/metrics,可以获取工作队列长度、请求QPS以及kubelet暴露出来的关于POD和容器的相关指标,其中容器的是通过Kubelet内置的cAdvisor服务暴露的,它是监控容器内部的。
通过插件获取的,也就是Heapster的替代者Metrics Server,这个用来获取Pod和Node资源使用情况,它主要是用来供HPA使用。它的数据并不是来自于Prometheus,不过Prometheus可以获取。
今天我们说的自定义API其实就是和Metrics Server的实现方式一样,都是通过注册API的形式来完成和Kubernetes的集成的,也就是在API Server增加原本没有的API。不过添加API还可以通过CRD的方式完成,不过我们这里直说聚合方式。看下图:
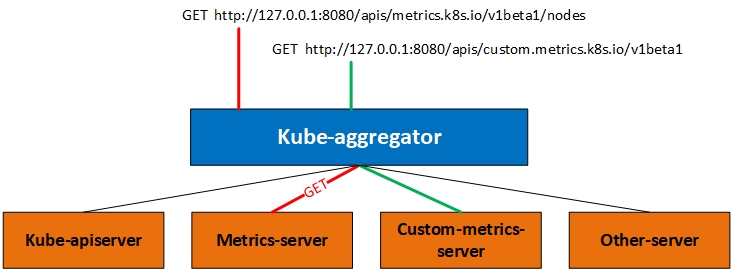
实际上我们访问API的时候访问的是一个aggregator的代理层,下面绿色的都是可用的后端。我们访问上图中的2个URL其实是被代理到不同的后端,在这个机制下你可以添加更多的后端,而我们今天要说的Custome-metrics-apiserver就是绿色线条的路径。如果你部署Metrics-server的话对于理解今天的内容也不会很难。
通过聚合器实现自定义API需要的步骤
首先在API Server中启用API聚合功能,在kube-apiserver启动参数中加入如下内容,其中证书名称换成你自己环境中的:
# CA根证书
--requestheader-client-ca-file=
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
# 在请求期间验证aggregator的客户端CA证书,我这里就是CA根证书
--proxy-client-cert-file=
# 私钥,我这里配置的就是CA根证书私钥
--proxy-client-key-file=
另外在kube-controller-manager组件上也有一些参数可以配置,但是不是必须的:
# HPT控制器同步Pod副本数量的时间间隔,默认15秒
--horizontal-pod-autoscaler-sync-period=15s
# 执行缩容的等待时间,默认5分钟
--horizontal-pod-autoscaler-downscale-stabilization=5m0s
# 等待Pod到达Reday状态的延时,默认30秒
--horizontal-pod-autoscaler-initial-readiness-delay=30s
其次定义api,然后向API Server进行注册
最后部署提供服务的应用。
演示
本次演示使用的配置清单文件请提前下载。下面对每个文件做一下简要说明。
custom-metrics-apiserver-auth-delegator-cluster-role-binding:
custom-metrics-apiserver-auth-reader-role-binding:
custom-metrics-apiserver-deployment:自定义指标提供者的容器
custom-metrics-apiserver-resource-reader-cluster-role-binding:
custom-metrics-apiserver-service:为deployment创建的service
custom-metrics-apiserver-service-account:创建服务账号
custom-metrics-apiservice:需要注册的apiserver名称以及关联的service
custom-metrics-cluster-role:
custom-metrics-config-map:配置文件
custom-metrics-resource-reader-cluster-role:
hpa-custom-metrics-cluster-role-binding:
上面的文件看起来比较多,我们合并一下,便于演示。
custom-metrics-apiserver-auth-delegator-cluster-role-binding、custom-metrics-apiserver-auth-reader-role-binding、custom-metrics-apiserver-resource-reader-cluster-role-binding、custom-metrics-apiserver-service-account、custom-metrics-cluster-role、custom-metrics-resource-reader-cluster-role、hpa-custom-metrics-cluster-role-binding,这几个合并到一个文件中,主要是服务账号和授权类的。其他保持单独的。合并文件custom-metrics-apiserver-rabc.yaml内容如下:
# 创建名称空间
kind: Namespace
apiVersion: v1
metadata:
name: custom-metrics
---
# 创建服务账号
kind: ServiceAccount
apiVersion: v1
metadata:
name: custom-metrics-apiserver
namespace: custom-metrics
---
# 把系统角色system:auth-delegator绑定到服务账号,使该服务账号可以将认证请求转发到自定义的API上
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: custom-metrics:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: custom-metrics-apiserver
namespace: custom-metrics
---
# 创建集群角色custom-metrics-resource-reader
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: custom-metrics-resource-reader
rules:
- apiGroups:
- ""
resources:
- namespaces
- pods
- services
verbs:
- get
- list
---
# 把集群角色custom-metrics-resource-reader绑定到服务账号
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: custom-metrics-resource-reader
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: custom-metrics-resource-reader
subjects:
- kind: ServiceAccount
name: custom-metrics-apiserver
namespace: custom-metrics
---
# 把系统自带的角色extension-apiserver-authentication-reader绑定到服务账号,允许服务账号可以访问系统的ConfigMap extension-apiserver-authentication
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: custom-metrics-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: custom-metrics-apiserver
namespace: custom-metrics
---
# 创建集群角色custom-metrics-server-resources
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: custom-metrics-server-resources
rules:
- apiGroups:
- custom.metrics.k8s.io
resources: ["*"]
verbs: ["*"]
---
# 把集群角色custom-metrics-server-resources绑定到系统自带的服务账号horizontal-pod-autoscaler
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: hpa-controller-custom-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: custom-metrics-server-resources
subjects:
- kind: ServiceAccount
name: horizontal-pod-autoscaler
namespace: kube-system
源文件中使用的monitoring这个Namespace,但是它没有创建Namespace的内容,所以上面文件第一部分我自己增加了一个,然后我使用的Namespace是custom-metrics,并把源文件中的做了修改。
应用custom-metrics-apiserver-rabc.yaml文件
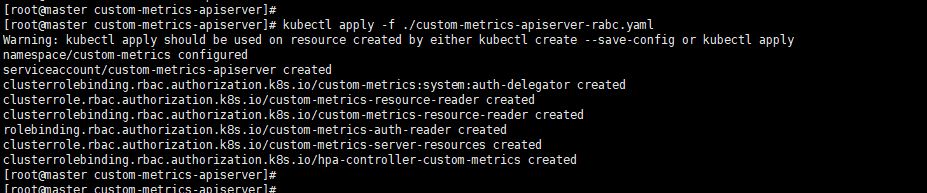
创建证书文件和Secret
#!/bin/bash
TEMP_WORK_DIR="/tmp/work"
cd ${TEMP_WORK_DIR}
cat << EOF > custom-metrics-apiserver-csr.json
{
"CN": "custom-metrics-apiserver",
"hosts": [
"custom-metrics-apiserver.custom-metrics.svc"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing"
}
]
}
EOF
# 会产生 custom-metrics-apiserver.pem custom-metrics-apiserver-key.pem
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes custom-metrics-apiserver-csr.json | cfssljson -bare custom-metrics-apiserver
# 创建secret
kubectl create secret generic cm-adapter-serving-certs --from-file=serving.crt=./custom-metrics-apiserver.pem --from-file=serving.key=./custom-metrics-apiserver-key.pem -n custom-metrics
ca-config.json文件内容
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
},
"etcd": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
},
"client": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"client auth"
]
}
}
}
}
前提是你安装好了cfssl工具、配置好了kubectl环境变量以及在当前工作目录具有ca-config.json文件,这个文件不一定是这个名字。这个文件是我之前部署k8s集群时候使用的,所以现在继续使用,它用于配置证书的通用属性信息。

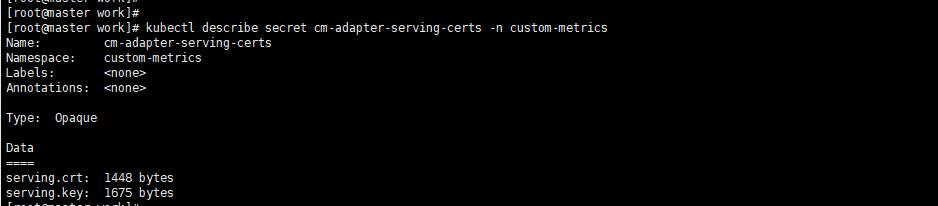
上图看到的TYPE是Opaque类型,因为Secret有4中类型Opaque是base64编码的Secret,用于存储密码和秘钥等加密比较弱。kubernetes.io/dockerconfigjson是用来存储私有docker仓库的认证信息。kubernetes.io/service-account-token是用来被service account使用的,是K8S用于验证service account的有效性的token。还有一种是tls专门用于加密证书文件的。
注册api文件
该文件的主要作用就是向Api server注册一个api,此API名称是关联到一个service名称上。
# 这个是向K8S apiserver注册自己的api以及版本
apiVersion: apiregistration.k8s.io/v1beta1
kind: APIService
metadata:
name: v1beta1.custom.metrics.k8s.io
spec:
# 该API所关联的service名称,也就是访问这个自定义API后,被转发到哪个service来处理,custom-metrics-apiserver-service这里定义的
service:
name: custom-metrics-apiserver
namespace: custom-metrics
# api所属的组名称
group: custom.metrics.k8s.io
# api版本
version: v1beta1
insecureSkipTLSVerify: true
groupPriorityMinimum: 100
versionPriority: 100
从下图可以看到这个api以及注册上了。

这个注册的api的其实就是hpa去api server访问这个注册的api,这个注册的api其实起到的是代理作用,把请求代理到某一个service上,这个service的endpoint其实就是提供检控数据的一个应用,也就是下面的适配器,适配器的作用就是从prometheus中查询数据然后重新组装成k8s可以识别的数据格式。
部署适配器
这里我们应用剩余的三个配置清单。这里我们主要说一下deployment文件。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: custom-metrics-apiserver
name: custom-metrics-apiserver
namespace: custom-metrics
spec:
replicas: 1
selector:
matchLabels:
app: custom-metrics-apiserver
template:
metadata:
labels:
app: custom-metrics-apiserver
name: custom-metrics-apiserver
spec:
serviceAccountName: custom-metrics-apiserver
containers:
- name: custom-metrics-apiserver
image: quay.io/coreos/k8s-prometheus-adapter-amd64:v0.4.1
args:
- /adapter
- --secure-port=6443
# 这里是custom-metrics-apiserver连接k8s apiserver使用的证书和私钥,这个证书你可以自己生成,主要注意CN和hosts字段。另外使用k8s的CA根证书来签发
# CN可以写service名称,hosts写service的DNS名称,鉴于IP会变所以不建议写IP地址,然后使用sfssl来生成证书,最后创建secret。
# 该文件下面secretName中的名称。
- --tls-cert-file=/var/run/serving-cert/serving.crt
- --tls-private-key-file=/var/run/serving-cert/serving.key
- --logtostderr=true
# 这个是连接prometheus的地址,它这里写的是prometheus service的域名
- --prometheus-url=http://prometheus.kube-system.svc:9090/
- --metrics-relist-interval=30s
- --v=10
- --config=/etc/adapter/config.yaml
ports:
- containerPort: 6443
volumeMounts:
- mountPath: /var/run/serving-cert
name: volume-serving-cert
readOnly: true
- mountPath: /etc/adapter/
name: config
readOnly: true
volumes:
- name: volume-serving-cert
secret:
secretName: cm-adapter-serving-certs
- name: config
configMap:
name: adapter-config
首先进入这个POD看看证书有没有挂载上来

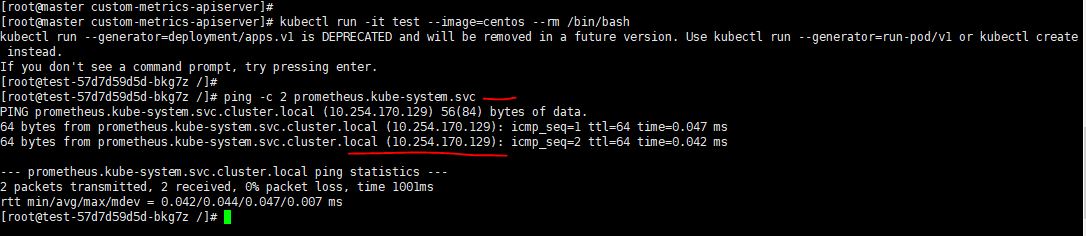
启动一个容器测试一下看看是否可以ping通prometheus的域名,通过下面的命令启动一个容器--rm是退出容器就删除该容器。kubectl run -it test --image=centos --rm /bin/bash ,如下图:
通过下面这个命令来查看自定义的api提供了哪些metrics,curl http://127.0.0.1:8080/apis/custom.metrics.k8s.io/v1beta1
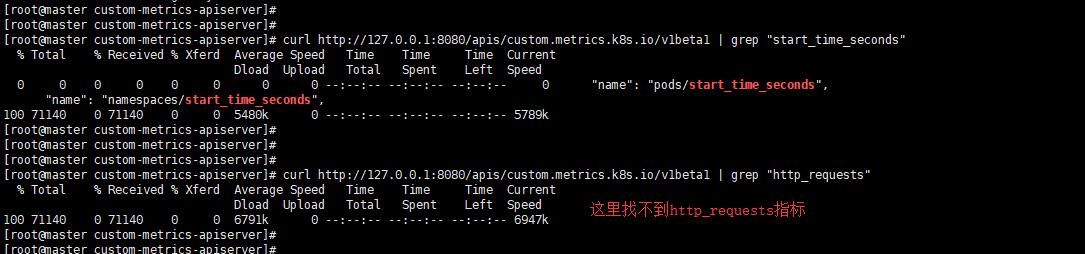
按照网上的测试方法会得到这样的错误提示"message": "the server could not find the metric http_requests for pods",如下图:
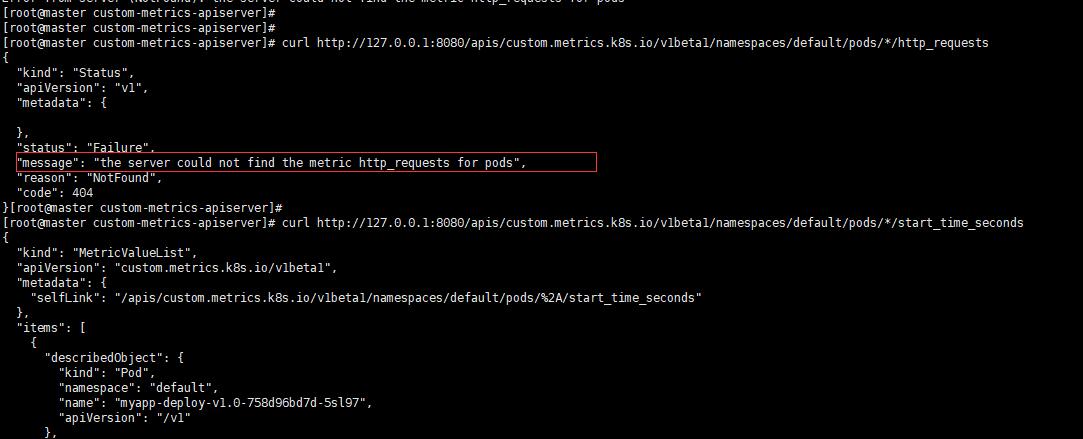
如果这里的指标找不到,那你将无法通过这个指标来实现HPA,这是怎么回事呢?这个就跟你部署的那个deployment的具体镜像k8s-prometheus-adapter-amd64它使用的配置文件有关,也就是custom-metrics-config-map.yaml里面定义的rules,文件中所有的seriesQuery项在prometheus中查询后的结果都没有http_request_totals指标,所以也就肯定找不到。
这里的原理就是adapter通过使用prometheus的查询语句来获取指标然后做一下修改最终把重新组装的指标和值通过自己的接口暴露,然后由自定义api代理到adapter的service上来获取这些指标。
既然样例中的规则缺少了,那么我们就自己拼凑一个(需要首先保障你的prometheus中可以搜索到http_requests_total这个指标),内容如下:
- seriesQuery: '{__name__=~"^http_requests_.*",kubernetes_pod_name!="",kubernetes_namespace!=""}'
seriesFilters: []
resources:
overrides:
kubernetes_namespace:
resource: namespace
kubernetes_pod_name:
resource: pod
name:
matches: ^(.*)_(total)$
as: "${1}"
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
最终的custom-metrics-config-map.yaml就是下面这个
apiVersion: v1
kind: ConfigMap
metadata:
name: adapter-config
namespace: custom-metrics
data:
config.yaml: |
rules:
- seriesQuery: '{__name__=~"^container_.*",container_name!="POD",namespace!="",pod_name!=""}'
seriesFilters: []
resources:
overrides:
namespace:
resource: namespace
pod_name:
resource: pod
name:
matches: ^container_(.*)_seconds_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>,container_name!="POD"}[1m])) by (<<.GroupBy>>)
- seriesQuery: '{__name__=~"^container_.*",container_name!="POD",namespace!="",pod_name!=""}'
seriesFilters:
- isNot: ^container_.*_seconds_total$
resources:
overrides:
namespace:
resource: namespace
pod_name:
resource: pod
name:
matches: ^container_(.*)_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>,container_name!="POD"}[1m])) by (<<.GroupBy>>)
- seriesQuery: '{__name__=~"^container_.*",container_name!="POD",namespace!="",pod_name!=""}'
seriesFilters:
- isNot: ^container_.*_total$
resources:
overrides:
namespace:
resource: namespace
pod_name:
resource: pod
name:
matches: ^container_(.*)$
as: ""
metricsQuery: sum(<<.Series>>{<<.LabelMatchers>>,container_name!="POD"}) by (<<.GroupBy>>)
- seriesQuery: '{namespace!="",__name__!~"^container_.*"}'
seriesFilters:
- isNot: .*_total$
resources:
template: <<.Resource>>
name:
matches: ""
as: ""
metricsQuery: sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>)
- seriesQuery: '{namespace!="",__name__!~"^container_.*"}'
seriesFilters:
- isNot: .*_seconds_total
resources:
template: <<.Resource>>
name:
matches: ^(.*)_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
- seriesQuery: '{__name__=~"^http_requests_.*",kubernetes_pod_name!="",kubernetes_namespace!=""}'
seriesFilters: []
resources:
overrides:
kubernetes_namespace:
resource: namespace
kubernetes_pod_name:
resource: pod
name:
matches: ^(.*)_(total)$
as: "${1}"
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
- seriesQuery: '{namespace!="",__name__!~"^container_.*"}'
seriesFilters: []
resources:
template: <<.Resource>>
name:
matches: ^(.*)_seconds_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
resourceRules:
cpu:
containerQuery: sum(rate(container_cpu_usage_seconds_total{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
nodeQuery: sum(rate(container_cpu_usage_seconds_total{<<.LabelMatchers>>, id='/'}[1m])) by (<<.GroupBy>>)
resources:
overrides:
instance:
resource: node
namespace:
resource: namespace
pod_name:
resource: pod
containerLabel: container_name
memory:
containerQuery: sum(container_memory_working_set_bytes{<<.LabelMatchers>>}) by (<<.GroupBy>>)
nodeQuery: sum(container_memory_working_set_bytes{<<.LabelMatchers>>,id='/'}) by (<<.GroupBy>>)
resources:
overrides:
instance:
resource: node
namespace:
resource: namespace
pod_name:
resource: pod
containerLabel: container_name
window: 1m
删除之前的config然后重新创建adapter再进行测试。

下面测试一下看看,发现已经有了。
curl http://127.0.0.1:8080/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests
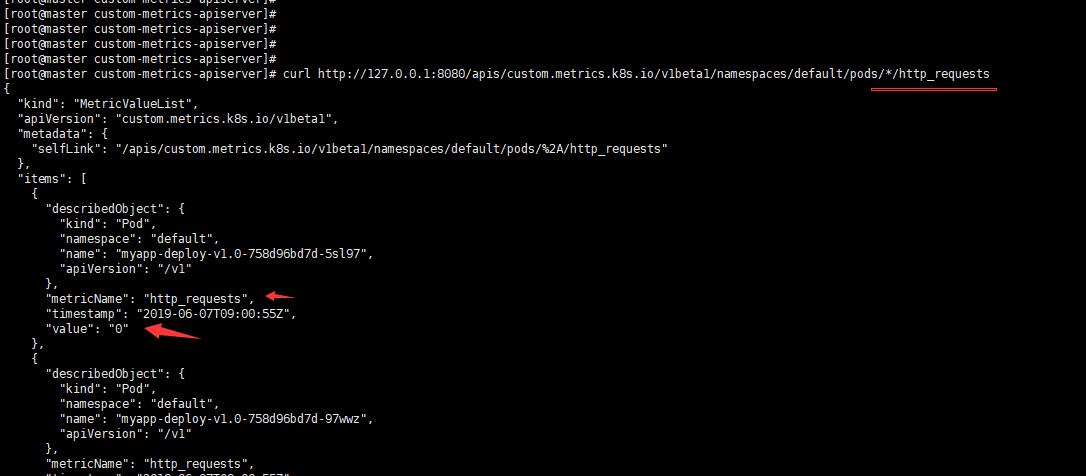
当你访问这个注册的URL时候会被代理到后端adaptor上,然后这个adaptor会去prometheus里面查询具体的资源,比如上面/pods/*/http_requests,其资源就是pod,星号这是所有pod,的http_requests。然后按照k8s的格式进行返回。这也就是说你要访问的资源首先要在Prometheus中存在,并且该资源还需要被体现在http_requests_total指标中。所以我们上面自己加的那段就是为了让adaptor可以去获取Prometheus的http_requests_total指标,然后这个指标中包含POD名称,如下图:
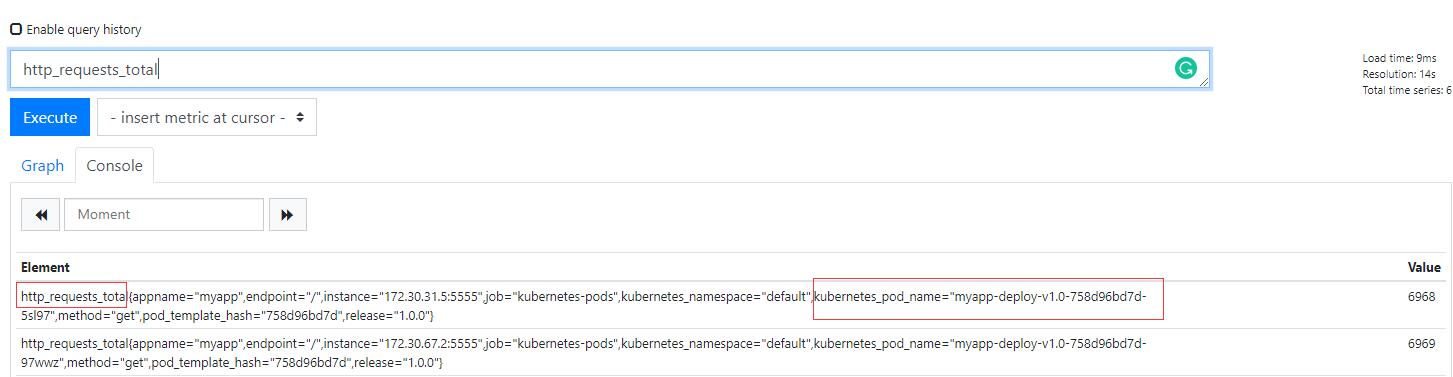
也就是说在prometheus中有指标是基础,然后adaptor才会按照它自己的配置规则去过滤,我们上面添加的规则其实就是过滤规则。
部署APP和Service
这个app我们用自己创建的景象
apiVersion: v1
kind: Service
metadata:
name: myapp-svc
labels:
appname: myapp-svc
spec:
type: ClusterIP
ports:
- name: http
port: 5555
targetPort: 5555
selector:
appname: myapp
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy-v1.0
labels:
appname: myapp
spec:
replicas: 2
selector:
matchLabels:
appname: myapp
release: 1.0.0
template:
metadata:
name: myapp
labels:
appname: myapp
release: 1.0.0
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "5555"
spec:
containers:
- name: myapp
image: myapp:v1.0
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: "250m"
memory: "128Mi"
limits:
cpu: "500m"
memory: "256Mi"
ports:
- name: http
containerPort: 5555
protocol: TCP
livenessProbe:
httpGet:
path: /healthy
port: http
initialDelaySeconds: 20
periodSeconds: 10
timeoutSeconds: 2
readinessProbe:
httpGet:
path: /healthy
port: http
initialDelaySeconds: 20
periodSeconds: 10
revisionHistoryLimit: 10
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
具体镜像制作过程参见使用Kubernetes演示金丝雀发布
创建HPA
基于POD
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: myapp-custom-metrics-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp-deploy-v1.0
minReplicas: 2
maxReplicas: 10
metrics:
- type: Pods
pods:
metricName: http_requests
targetAverageValue: 5000m
自定义资源指标含义是基于myapp-deploy-v1.0这个deployment的全部pod来计算http_requests的平局值,如果达到5000m就进行扩容。
scaleTargetRef:这里定义的是自动扩容缩容的对象,可以是Deployment或者ReplicaSet,这里写具体的Deployment的名称。
metrics:这里是指标的目标值。在type中定义类型;通过target来定义指标的阈值,系统将在指标达到阈值的时候出发扩缩容操作。
metrics中的type有如下类型:
Resource:基于资源的指标,可以是CPU或者是内存,如果基于这个类型的指标来做只需要部署Metric-server即可,不需要部署自定义APISERVER。
Pods:基于Pod的指标,系统将对Deployment中的全部Pod副本指标进行平均值计算,如果是Pod则该指标必须来源于Pod本身。
Object:基于Ingress或者其他自定义指标,比如ServiceMonitor。它的target类型可以是Value或者AverageValue(根据Pod副本数计算平均值)。
这里说一下5000m是什么意思。自定义API SERVER收到请求后会从Prometheus里面查询http_requests_total的值,然后把这个值换算成一个以时间为单位的请求率。500m的m就是milli-requests,按照定义的规则metricsQuery中的时间范围1分钟,这就意味着过去1分钟内每秒如果达到500个请求则会进行扩容。
在一个HPA中可以定义了多种指标,如果定义多个系统将针对每种类型指标都计算Pod副本数量,取最大的进行扩缩容。换句话说,系统会根据CPU和pod的自定义指标计算,任何一个达到了都进行扩容。应用上面的HPA配置清单文件:

使用下面的命令进行测试:
ab -c 10 -n 10000 http://10.254.101.238:5555 10个用户,总共发10000个请求,平均到2个POD,每个POD承受500,显然不会达到我们设置的阈值。
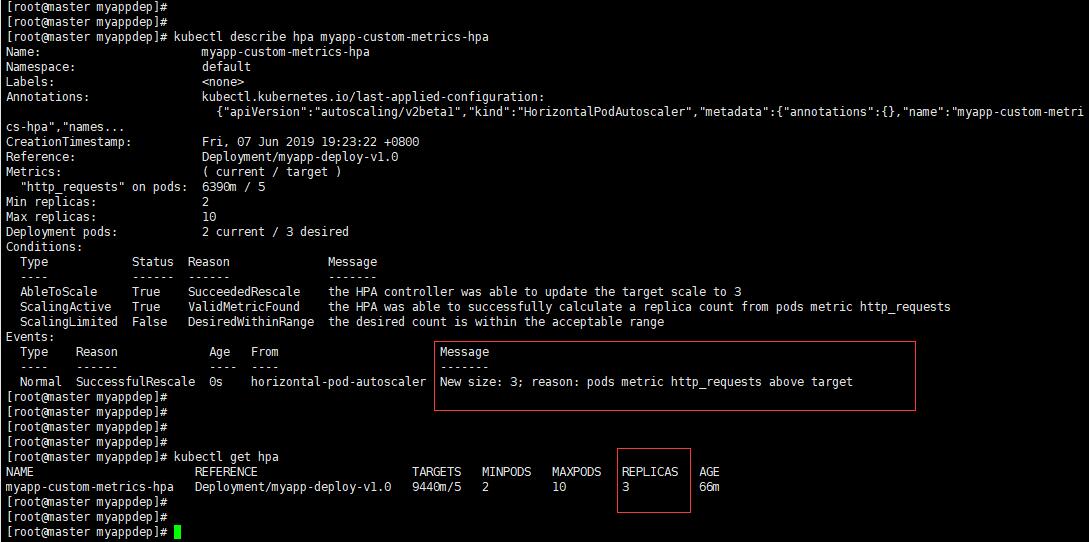
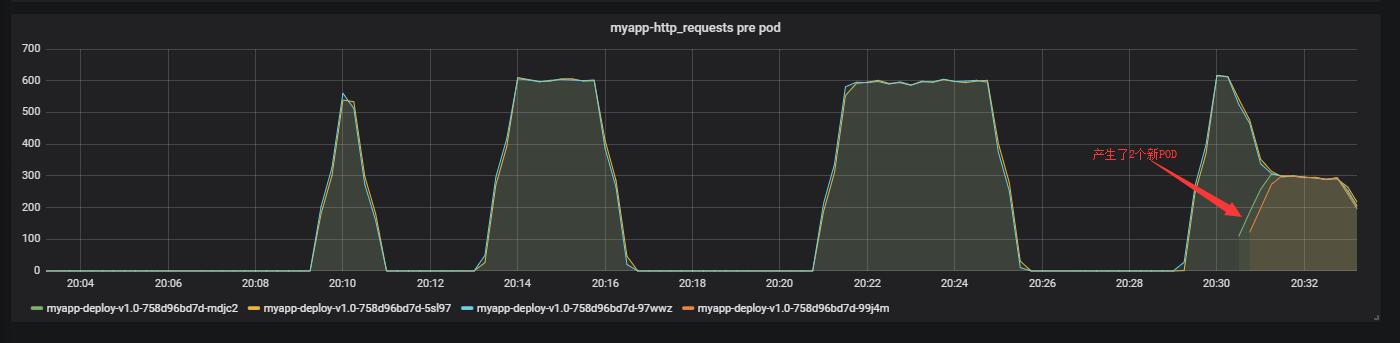
可以看到已经扩容到3个了。从监控上也可以看到,如下图:
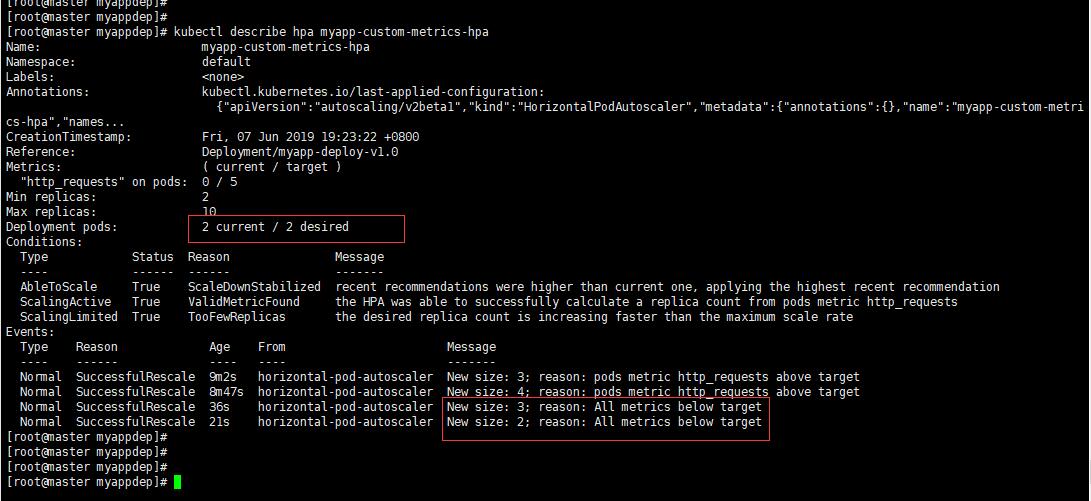
过了一会流量没有了它会自动缩容,如下图:
基于Service
如果基于Service的话你可以改成service,如下:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: myapp-custom-metrics-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp-deploy-v1.0
minReplicas: 2
maxReplicas: 10
metrics:
- type: Object
object:
target:
kind: Service
# 这里是你自己的APP的service
name: myapp-svc
metricName: http_requests
targetValue: 100
不过这个配置在我的环境中无法访问,curl http://127.0.0.1:8080/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/services/myapp-svc/http_requests 结果如下图:

因为上面的APP中的service没有配置被监控,另外在adaptor中的规则是针对pod名字的,所以这里要做一下修改。
说明,所有修改都是基于你的Prometheus中的k8s动态发现规则的配置。
首先修改myapp的service配置,然后就可以在k8s自动发现的角色endpoints里被发现:
apiVersion: v1
kind: Service
metadata:
name: myapp-svc
labels:
appname: myapp-svc
annotations:
prometheus.io/scrape: "true" # 新增内容
prometheus.io/port: "5555" # 新增内容
spec:
type: ClusterIP
ports:
- name: http
port: 5555
targetPort: 5555
selector:
appname: myapp
重启应用,在Prometheus中查看

指标内容就比之前多一条:
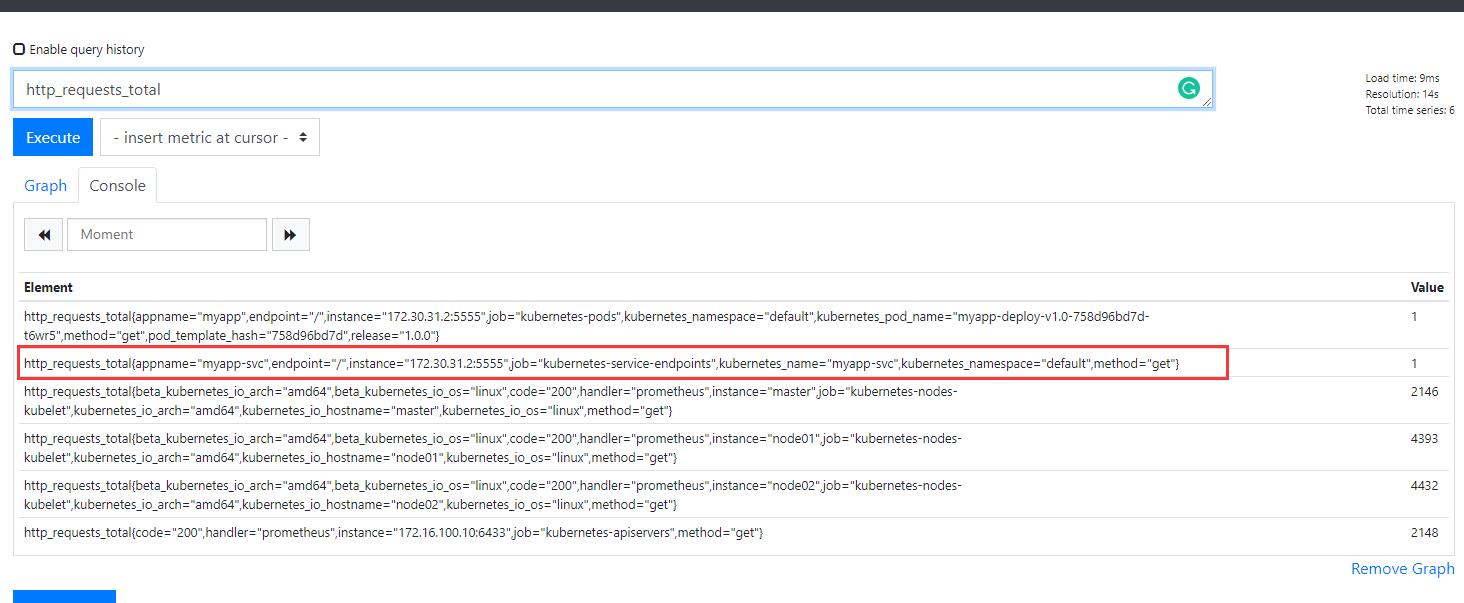
然后配置适配器规则,增加如下内容:
- seriesQuery: '{__name__=~"^http_requests_.*",kubernetes_name!="",kubernetes_namespace!=""}'
seriesFilters: []
resources:
overrides:
kubernetes_namespace:
resource: namespace
kubernetes_name:
resource: service
name:
matches: ^(.*)_(total)$
as: "${1}"
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
kubernetes_name在prometheus中就是service的名称,这个是k8s中动态发现里面的relable修改的,我们来测试一下新的条件是否可以找到:
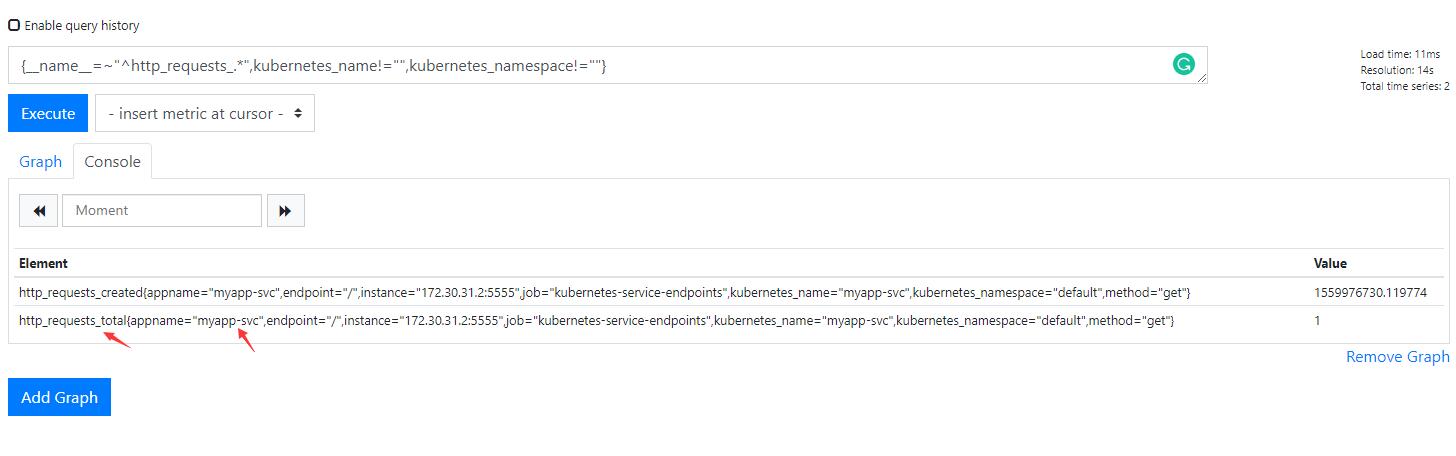
应用这个配置,然后重建适配器。
再次通过该URL进行访问curl http://127.0.0.1:8080/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/services/myapp-svc/http_requests,结果如下图:

关于这里的拍错需要说一下,就是你可以访问curl http://127.0.0.1:8080/apis/custom.metrics.k8s.io/v1beta1 > /tmp/metrics.txt 把它能使用资源列出来,如果没有service/http_requests则说明你无法访问那个URL,也就是说没有什么你就加什么就好了。
我这里就不做演示了,因为只要这个URL可以出来内容,那么针对Service的HPA就可以做。
参考:
基于Custom-metrics-apiserver实现Kubernetes的HPA(内含踩坑)的更多相关文章
- 基于JQuery可拖动列表格插件DataTables的踩坑记
前言 最近项目中在使用能够拖动列调整列位置顺序的表格插件---DataTables,这也是目前我找到的唯一一种存在有这种功能的插件. 在查找使用方法的过程中发现可用案例并不多,且大多言语不详.本文将全 ...
- centos7使用Minikube“快速搭建“出Kubernetes本地实验环境(踩坑集锦及解决方案)
先决条件(先假设你做完这两步骤) 检查Linux是否支持虚拟化,验证输出是否为非空如何开启虚拟化 grep -E --color 'vmx|svm' /proc/cpuinfo 安装 kubectl ...
- kubernetes pod的弹性伸缩———基于pod自定义custom metrics(容器的IO带宽)的HPA
背景 自Kubernetes 1.11版本起,K8s资源采集指标由Resource Metrics API(Metrics Server 实现)和Custom metrics api(Promet ...
- 基于TLS证书手动部署kubernetes集群(下)
一.master节点组件部署 承接上篇文章--基于TLS证书手动部署kubernetes集群(上),我们已经部署好了etcd集群.flannel网络以及每个节点的docker,接下来部署master节 ...
- (转)基于TLS证书手动部署kubernetes集群(下)
转:https://www.cnblogs.com/wdliu/p/9152347.html 一.master节点组件部署 承接上篇文章--基于TLS证书手动部署kubernetes集群(上),我们已 ...
- 基于docker和cri-dockerd部署kubernetes v1.25.3
基于docker和cri-dockerd部署kubernetes v1.25.3 1.环境准备 1-1.主机清单 主机名 IP地址 系统版本 k8s-master01 k8s-master01.wan ...
- 新书推荐《再也不踩坑的Kubernetes实战指南》
<再也不踩坑的Kubernetes实战指南>终于出版啦.目前可以在京东.天猫购买,京东自营和当当网预计一个星期左右上架. 本书贴合生产环境经验,解决在初次使用或者是构建集群中的痛点,帮 ...
- NET Core2.0 Memcached踩坑,基于EnyimMemcachedCore整理MemcachedHelper帮助类。
DotNetCore2.0下使用memcached缓存. Memcached目前微软暂未支持,暂只支持Redis,由于项目历史原因,先用博客园开源项目EnyimMemcachedCore,后续用到的时 ...
- Asp.Net Core 2.0 项目实战(5)Memcached踩坑,基于EnyimMemcachedCore整理MemcachedHelper帮助类。
Asp.Net Core 2.0 项目实战(1) NCMVC开源下载了 Asp.Net Core 2.0 项目实战(2)NCMVC一个基于Net Core2.0搭建的角色权限管理开发框架 Asp.Ne ...
随机推荐
- sql注入知识点
需找sql注入点1\无特定目标inurl:.php?id= 2\有特定目标:inurl:.php?id= site:target.com 3\工具爬取spider,对搜索引擎和目标网站的链接进行爬取 ...
- 怎么解决禅道启动服务mysqlzt时的端口失败
打开Windows任务管理器 查看服务是否有MySQL正在运行,停止服务 启动mysqlzt服务 重新启动禅道
- 微信小程序 - 结构目录 | 配置介绍
结构目录 小程序框架提供了自己的视图层描述语言 WXML 和 WXSS,以及 JavaScript,并在视图层与逻辑层间提供了数据传输和事件系统,让开发者能够专注于数据与逻辑. 一.小程序文件结构和传 ...
- JDOJ 1929: 求最长不下降序列长度
JDOJ 1929: 求最长不下降序列长度 JDOJ传送门 Description 设有一个正整数的序列:b1,b2,-,bn,对于下标i1<i2<-<im,若有bi1≤bi2≤-≤ ...
- [POJ1952]BUY LOW, BUY LOWER
题目描述 Description The advice to "buy low" is half the formula to success in the bovine stoc ...
- biopython处理中蜂基因组
1.安装包 pip install bcbio-gff pprint 2.显示中蜂的序列 from Bio import SeqIO genome_name = 'GCF_001442555.1_AC ...
- docker--发布docker镜像
前戏 前面我们自己做了个docker镜像,我们可以上传到docker hub,别人就可以下载使用了 发布到docker hub 我们前面使用docker search 查找的镜像都是从docker h ...
- ASP.NET Core 新建项目(Windows)
对于任何语言和框架,都是从 Hello World 开始的,这个非常简单,但却有十分重大的意义,ASP.NET Core 基础教程也会以 Hello World 开始 为什么呢? 因为能够运行 Hel ...
- 【UVA1303】Wall(凸包)
点此看题面 大致题意: 给你一个多边形,要求建一面墙使得墙上的点至少离多边形每个顶点\(R\)的距离,求最短的墙长. 考虑\(R=0\) 考虑当\(R=0\)时,所求的答案显然就是求得的凸包的周长. ...
- PurpleAir空气质量数据采集
PurpleAir空气质量数据采集 # -*- coding: utf-8 -*- import time, datetime, calendar import urllib, requests im ...