Spring Cloud OkHttp设计原理
Spring Cloud 框架最底层核心的组件就是服务调用方式,一般Spring Cloud框架采用的是HTTP的调用框架,本文将在 Spring Cloud应用场景下,介绍组件OkHttp3的设计原理。
1. Spring Cloud的接口调用工作模式

Spring Cloud作为组合式的分布式微服务解决方案,再服务调用上,至少需要解决如下几个环节:
- 面向接口的编程形式
接口调用过程,除了拼装Http请求外,为了提高接口调用的无感性,在这个环节上,目前采用的是Feign工具完成的。至于feign的工作原理,请参考我的另一篇博文:客户端负载均衡Feign之三:Feign设计原理
- 服务负载均衡和选择机制
作为分布式调用框架,服务消费方需要通过一定的机制知道应当调用某一特定服务提供方实例,Spring Cloud 目前采用的是 Ribbon来完成的。至于Ribbon的工作原理,请参考我的另一篇博文:
Spring Cloud Ribbon设计原理. - 作为http 客户端,向服务器发起Http请求
Http客户端在Java语言中,目前比较流行的有 Apache HttpClients components,HttpUrlConnection,OkHttp等,OkHttp 在性能、体积各方面表现比较好,采用此框架作为http 客户端是一个不错的选择。本文将深入OkHttp的底层设计原理,通过分析整理出它的最佳打开方式。
2. 什么是OkHttp,它有什么特点?
OkHttp是square公司开发的一个同时支持Http和Http2协议的Java客户端,可用于Android和Java应用中。
OKHttp有如下几个特性:
- 支持Http1.1、SPDY,和Http2
- 内部采用连接池机制,能够缓存和复用Tcp/IP连接,减少请求延迟。
- 支持GZIP格式压缩,减少数据传输大小
- 对重复请求返回结果进行缓存,减少交互次数
- OKHttp底层采用DNS反解析,当其中一个实例不可用时,会自动切换至下一个服务,有较好的连接管理能力。
- OkHttp支持最新的TLS特性(TLS 1.3, ALPN, certificate pinning)
- 同时支持同步调用和异步调用两种方式
3. Okhttp3的设计原理
本章节将详细介绍OkHttp3底层的设计原理,并结合设计原理,总结在使用过程中应当注意的事项。
3.1 Ohttp3的的基本工作流程
以如下的简单交互代码为例,OkHttp3的简单工作方式如下所示:
//Step1:初始化连接池
ConnectionPool connectionPool = new ConnectionPool(50, 5, TimeUnit.MINUTES);
OkHttpClient.Builder
builder = new OkHttpClient.Builder().connectionPool(connectionPool);
//Step2:创建Client
OkHttpClient client = builder.build();
//Step3:构造请求
Request request = new Request.Builder()
.url("http://www.baidu.com")
.build();
//Step4:发送请求
Response response = client.newCall(request).execute();
String result = response.body().string();
System.out.println(result);
根据上述的流程,其内部请求主要主体如下所示:
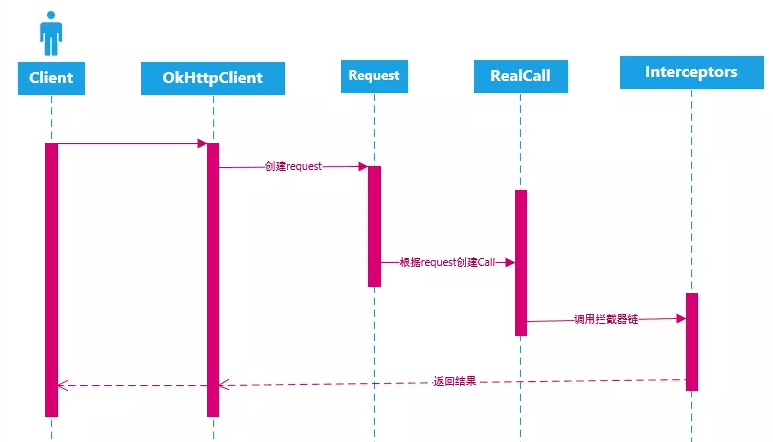
OkHttp3在请求处理上,采用了拦截器链的模式来处理请求,拦截器链中,负责通过http请求调用服务方,然后将结果返回。
3.2 okHttp3的拦截器链
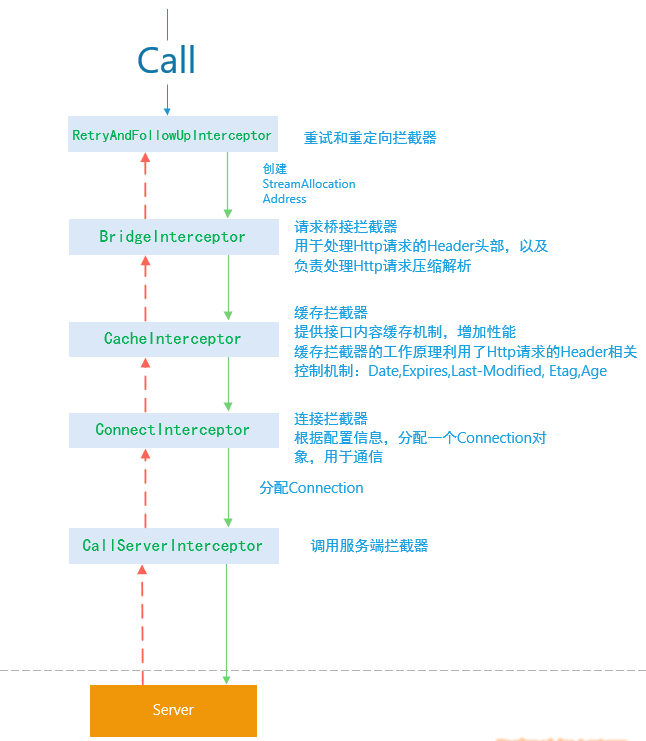
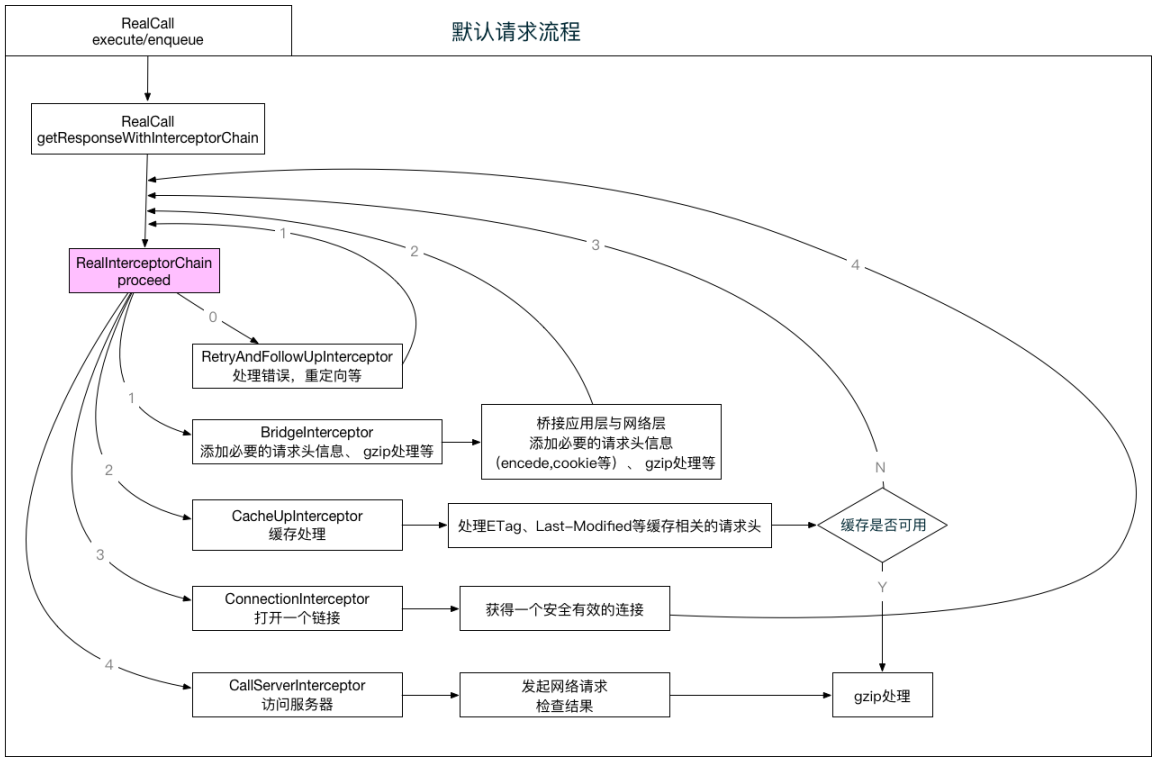
OkHttp3的核心是拦截器链,通过拦截器链,处理Http请求:
RetryAndFollowUpInterceptor,重试和重定向拦截器,主要作用是根据请求的信息,创建StreamAllocation和Address实例;BridgeInterceptor请求桥接拦截器,主要是处理Http请求的Header头部信息,处理Http请求压缩和解析;CacheInterceptor缓存拦截器,此拦截器借助于Http协议的客户端缓存定义,模拟浏览器的行为,对接口内容提供缓存机制,提高客户端的性能;ConnectInterceptor连接拦截器,负责根据配置信息,分配一个Connection实例对象,用于TCP/IP通信。CallServerInterceptor调用服务端拦截器,该拦截器负责向Server发送Http请求报文,并解析报文。
CallServerInterceptor拦截器底层使用了高性能的okio(okhttp io components)子组件完成请求流的发送和返回流的解析。
3.3 OkHttp3的内部核心架构关系
作为拦截器链的展开,下图展示了OKHttp3的核心部件及其关系:
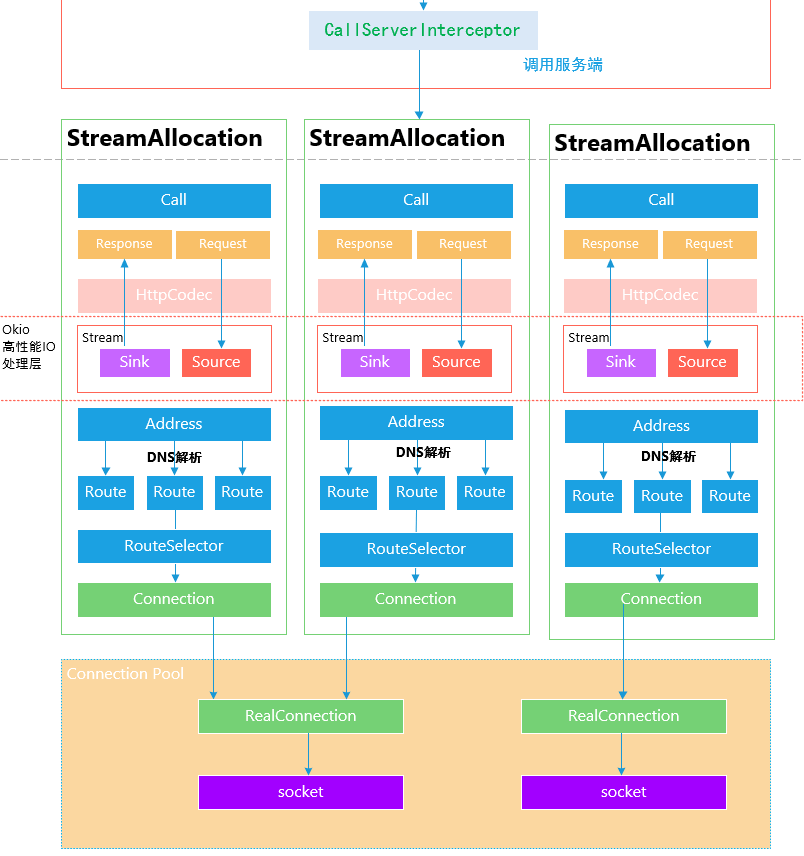
上述架构图中,有如下几个概念:
StreamAllocation当一个请求发起时,会为该请求创建一个StreamAllocation实例来表示其整个生命周期;Call该对象封装了对某一个Http请求,类似于command命令模式;Request,Response当Call被执行时,会转换成Request对象, 执行结束之后,通过Response对象返回表示HttpCodec处理上述的Request和Response,将数据基于Http协议解析转换Stream这一层是okio高性能层进行io转换处理,聚焦于Source和Sink的处理Addressokhttp3对于调用服务的地址封装,比如www.baidu.com则表示的百度服务的AddressRoute框架会对Address判断是否DNS解析,如果解析,一个Address可能多个IP,每一个IP被封装成RouteRouteSelector当存在多Route的情况下,需要定义策略选择RouteConnection表示的是Http请求对应的一个占用Connection,Connection的分配时通过Connnection Pool获取Connection Pool维护框架的连接池
3.4 OKhttp3的网络连接的抽象
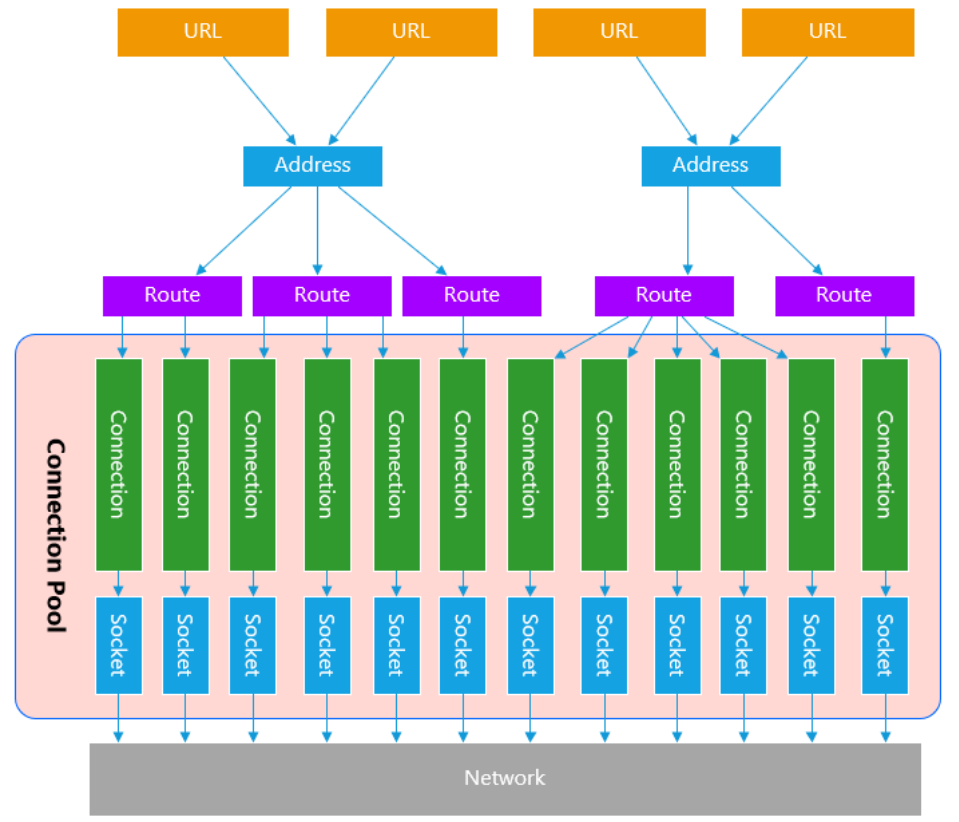
OKHttp3对网络连接过程中,涉及到的几种概念:
- 请求URL:OKHttp3 是处理URL请求的HTTP请求的基础,URL的格式遵循标准的HTTP协议。对于某个HTTP服务器而言,会提供多个URL地址链接。URL协议中,基本格式为
http(s)://<domain-or-ip>:<port>/path/to/service,其中<domain-or-ip>则表示的是服务器的地址 Adress - Address(地址): 即上述的
<domain-or-ip>,表示服务的域名或者IP - Route (路由) :当URL中的<domain-or-ip>是domain时,表示的是服务的域名,而域名通过DNS解析时,可能会解析出多个IP,也就是说一个Address可以映射到多个Route,一个Route 表示的是一个机器IP,用于建立TCP/IP网络连接
- Connection:Connection表示的是一个Socket连接通信实例
- Connection Pool: 对于Connection实例,统一维护在
连接池中, OKHttp的连接池比较特殊,详情参考后续章节。
3.5 连接池的工作原理

在OKHttp3内部使用了双端队列管理连接池,也就是说 连接池没有数量的限制。
那既连接数量的限制,OKHttp3是怎么保证队列内存不溢出呢?
3.5.1 连接池的连接清空机制
连接池通过最大闲置连接数(maxIdleConnections)和保持存活时间(keepAliveDuration)来控制连接池中连接的数量。
在连接池的内部,会维护一个守护线程,当每次往线程池中添加新的连接时,将会触发异步清理闲置连接任务。
private final Runnable cleanupRunnable = new Runnable() {
@Override public void run() {
while (true) {
//执行清空操作,返回下次执行清空的时间
long waitNanos = cleanup(System.nanoTime());
if (waitNanos == -1) return;
if (waitNanos > 0) {
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
//将当前清理线程睡眠指定的时间片后再唤醒
synchronized (ConnectionPool.this) {
try {
ConnectionPool.this.wait(waitMillis, (int) waitNanos);
} catch (InterruptedException ignored) {
}
}
}
}
}
};
/**
* Performs maintenance on this pool, evicting the connection that has been idle the longest if
* either it has exceeded the keep alive limit or the idle connections limit.
*
* <p>Returns the duration in nanos to sleep until the next scheduled call to this method. Returns
* -1 if no further cleanups are required.
*/
long cleanup(long now) {
int inUseConnectionCount = 0;
int idleConnectionCount = 0;
RealConnection longestIdleConnection = null;
long longestIdleDurationNs = Long.MIN_VALUE;
// Find either a connection to evict, or the time that the next eviction is due.
synchronized (this) {
//遍历连接池中的每个连接
for (Iterator<RealConnection> i = connections.iterator(); i.hasNext(); ) {
RealConnection connection = i.next();
// If the connection is in use, keep searching.
if (pruneAndGetAllocationCount(connection, now) > 0) {
inUseConnectionCount++;
continue;
}
idleConnectionCount++;
// If the connection is ready to be evicted, we're done.
long idleDurationNs = now - connection.idleAtNanos;
//计算连接的累计闲置时间,统计最长的闲置时间
if (idleDurationNs > longestIdleDurationNs) {
longestIdleDurationNs = idleDurationNs;
longestIdleConnection = connection;
}
}
//如果闲置时间超过了保留限额 或者闲置连接数超过了最大闲置连接数值
if (longestIdleDurationNs >= this.keepAliveDurationNs
|| idleConnectionCount > this.maxIdleConnections) {
// We've found a connection to evict. Remove it from the list, then close it below (outside
// of the synchronized block).
//从连接池中剔除当前连接
connections.remove(longestIdleConnection);
} else if (idleConnectionCount > 0) {
// 如果未达到限额,返回移除时间点
// A connection will be ready to evict soon.
return keepAliveDurationNs - longestIdleDurationNs;
} else if (inUseConnectionCount > 0) {
// All connections are in use. It'll be at least the keep alive duration 'til we run again.
// 都在使用中,没有被清理的,则返回保持存活时间
return keepAliveDurationNs;
} else {
// No connections, idle or in use.
cleanupRunning = false;
return -1;
}
}
closeQuietly(longestIdleConnection.socket());
// Cleanup again immediately.
return 0;
}
默认情况下:
- 最大闲置连接数(maxIdleConnections):5
- 保持存活时间(keepAliveDuration):5(mins)
连接池(Connection Pool)的工作原理:
- 当某一个Http请求结束后,对应的Connection实例将会标识成idle状态,然后连接池会立马判断当前
连接池中的处于idle状态的Connection实例是否已经超过 maxIdleConnections 阈值,如果超过,则此Connection实例将会被释放,即对应的TCP/ IP Socket通信也会被关闭。- 连接池内部有一个异步线程,会检查
连接池中处于idle实例的时长,如果Connection实例时长超过了keepAliveDuration,则此Connection实例将会被剔除,即对应的TCP/ IP Socket通信也会被关闭。
3.5.2 连接池使用注意事项:
对于瞬时并发很高的情况下,okhttp连接池中的TCP/IP连接将会冲的很高,可能和并发数量基本一致。但是,当http请求处理完成之后,连接池会根据maxIdleConnections来保留Connection实例数量。maxIdleConnections的设置,应当根据实际场景请求频次来定,才能发挥最大的性能。
假设我们的连接池配置是默认配置,即:最大闲置连接数(maxIdleConnections):5,保持存活时间(keepAliveDuration):5(mins);
当前瞬时并发有100个线程同时请求,那么,在okhttp内创建100个 tcp/ip连接,假设这100个线程在1s内全部完成,那么连接池内只有5个tcp/ip连接,其余的都将释放;在下一波50个并发请求过来时,连接池只有5个可以复用,剩下的95个将会重新创建tcp/ip连接,对于这种并发能力较高的场景下,最大闲置连接数(maxIdleConnections)的设置就不太合适,这样连接池的利用率只有5 /50 *100% = 10%,所以这种模式下,okhttp的性能并不高。
所以,综上所述,可以简单地衡量连接池的指标:
连接池的利用率 = maxIdleConnections / 系统平均并发数
说明:根据上述公式可以看出,利用率越高,maxIdleConnections和系统平均并发数这两个值就越接近,即:maxIdleConnections应当尽可能和系统平均并发数相等。
3.6 spring cloud对连接池的设置
Spring cloud在对这个初始化的过程比较开放,默认的大小是200,具体的指定关系和其实现关系。
package org.springframework.cloud.commons.httpclient; import okhttp3.ConnectionPool; import java.util.concurrent.TimeUnit; /**
* Default implementation of {@link OkHttpClientConnectionPoolFactory}.
* @author Ryan Baxter
*/
public class DefaultOkHttpClientConnectionPoolFactory implements OkHttpClientConnectionPoolFactory { @Override
public ConnectionPool create(int maxIdleConnections, long keepAliveDuration, TimeUnit timeUnit) {
return new ConnectionPool(maxIdleConnections, keepAliveDuration, timeUnit);
}
}
在设置上,共有两个地方可以指定连接参数:
- 基于ribbon的
maxTotalConnections值,默认为 :200; - 基于feign的
getMaxConnections值,默认为:200
3.6.1 基于ribbon和okhttp的配置(ribbon.okhttp.enabled开启配置):
@Configuration
@ConditionalOnProperty("ribbon.okhttp.enabled") //开启参数
@ConditionalOnClass(name = "okhttp3.OkHttpClient")
public class OkHttpRibbonConfiguration {
@RibbonClientName
private String name = "client"; @Configuration
protected static class OkHttpClientConfiguration {
private OkHttpClient httpClient; @Bean
@ConditionalOnMissingBean(ConnectionPool.class)
public ConnectionPool httpClientConnectionPool(IClientConfig config,
OkHttpClientConnectionPoolFactory connectionPoolFactory) {
RibbonProperties ribbon = RibbonProperties.from(config);
//使用了ribbon的 maxTotalConnections作为idle数量,ribbon默认值为200
int maxTotalConnections = ribbon.maxTotalConnections();
long timeToLive = ribbon.poolKeepAliveTime();
TimeUnit ttlUnit = ribbon.getPoolKeepAliveTimeUnits();
return connectionPoolFactory.create(maxTotalConnections, timeToLive, ttlUnit);
} @Bean
@ConditionalOnMissingBean(OkHttpClient.class)
public OkHttpClient client(OkHttpClientFactory httpClientFactory,
ConnectionPool connectionPool, IClientConfig config) {
RibbonProperties ribbon = RibbonProperties.from(config);
this.httpClient = httpClientFactory.createBuilder(false)
.connectTimeout(ribbon.connectTimeout(), TimeUnit.MILLISECONDS)
.readTimeout(ribbon.readTimeout(), TimeUnit.MILLISECONDS)
.followRedirects(ribbon.isFollowRedirects())
.connectionPool(connectionPool)
.build();
return this.httpClient;
}
}
}
3.6.2 基于feign的OKHttp配置(feign.okhttp.enabled参数开启)
@Configuration
@ConditionalOnClass(OkHttpClient.class)
@ConditionalOnMissingClass("com.netflix.loadbalancer.ILoadBalancer")
@ConditionalOnMissingBean(okhttp3.OkHttpClient.class)
@ConditionalOnProperty(value = "feign.okhttp.enabled")
protected static class OkHttpFeignConfiguration { private okhttp3.OkHttpClient okHttpClient; @Bean
@ConditionalOnMissingBean(ConnectionPool.class)
public ConnectionPool httpClientConnectionPool(FeignHttpClientProperties httpClientProperties,
OkHttpClientConnectionPoolFactory connectionPoolFactory) {
Integer maxTotalConnections = httpClientProperties.getMaxConnections();
Long timeToLive = httpClientProperties.getTimeToLive();
TimeUnit ttlUnit = httpClientProperties.getTimeToLiveUnit();
return connectionPoolFactory.create(maxTotalConnections, timeToLive, ttlUnit);
} @Bean
public okhttp3.OkHttpClient client(OkHttpClientFactory httpClientFactory,
ConnectionPool connectionPool, FeignHttpClientProperties httpClientProperties) {
Boolean followRedirects = httpClientProperties.isFollowRedirects();
Integer connectTimeout = httpClientProperties.getConnectionTimeout();
Boolean disableSslValidation = httpClientProperties.isDisableSslValidation();
this.okHttpClient = httpClientFactory.createBuilder(disableSslValidation).
connectTimeout(connectTimeout, TimeUnit.MILLISECONDS).
followRedirects(followRedirects).
connectionPool(connectionPool).build();
return this.okHttpClient;
} @PreDestroy
public void destroy() {
if(okHttpClient != null) {
okHttpClient.dispatcher().executorService().shutdown();
okHttpClient.connectionPool().evictAll();
}
} @Bean
@ConditionalOnMissingBean(Client.class)
public Client feignClient(okhttp3.OkHttpClient client) {
return new OkHttpClient(client);
}
}
Spring Cloud OkHttp设计原理的更多相关文章
- Spring Cloud Feign设计原理
什么是Feign? Feign 的英文表意为“假装,伪装,变形”, 是一个http请求调用的轻量级框架,可以以Java接口注解的方式调用Http请求,而不用像Java中通过封装HTTP请求报文的方式直 ...
- 撸一撸Spring Cloud Ribbon的原理-负载均衡器
在上一篇<撸一撸Spring Cloud Ribbon的原理>中整理发现,RestTemplate内部调用负载均衡拦截器,拦截器内最终是调用了负载均衡器来选择服务实例. 接下来撸一撸负载均 ...
- 撸一撸Spring Cloud Ribbon的原理-负载均衡策略
在前两篇<撸一撸Spring Cloud Ribbon的原理>,<撸一撸Spring Cloud Ribbon的原理-负载均衡器>中,整理了Ribbon如何通过负载均衡拦截器植 ...
- Eureka 系列(03)Spring Cloud 自动装配原理
Eureka 系列(03)Spring Cloud 自动装配原理 [TOC] 0. Spring Cloud 系列目录 - Eureka 篇 本文主要是分析 Spring Cloud 是如何整合 Eu ...
- Spring技术内幕——深入解析Spring架构与设计原理(一)IOC实现原理
IOC的基础 下面我们从IOC/AOP开始,它们是Spring平台实现的核心部分:虽然,我们一开始大多只是在这个层面上,做一些配置和外部特性的使用工作,但对这两个核心模块工作原理和运作机制的理解,对深 ...
- Spring Could Feign 设计原理
什么是Feign? Feign 的英文表意为"假装,伪装,变形", 是一个http请求调用的轻量级框架,可以以Java接口注解的方式调用Http请求,而不用像Java中通过封装HT ...
- 撸一撸Spring Cloud Ribbon的原理
说起负载均衡一般都会想到服务端的负载均衡,常用产品包括LBS硬件或云服务.Nginx等,都是耳熟能详的产品. 而Spring Cloud提供了让服务调用端具备负载均衡能力的Ribbon,通过和Eure ...
- Spring Cloud OpenFeign的原理(六)
通过上篇我们了解OpenFeign他也可以完成远程通信,但是它并不是真正义意上的RPC通信,因为他是通过封装代理来实现的,下面和以前一样,知道了怎么用就来看下他是怎么实现的. 一.思考Feign要做的 ...
- Spring Cloud个组件原理
引言 面试中面试官喜欢问组件的实现原理,尤其是常用技术,我们平时使用了SpringCloud还需要了解它的实现原理,这样不仅起到举一反三的作用,还能帮助轻松应对各种问题及有针对的进行扩展.以下是 课程 ...
随机推荐
- 修改Nginx配置参数解决http状态码:413上传文件大小限制问题
修改Nginx上传文件大小限制 我们使用ngnix做web server的时候,nginx对上传文件的大小有限制,默认是1M. 当超过大小的时候会报413(too large)错误.这个时候我们要修改 ...
- 架构师小跟班:送你一份2019年阿里巴巴最新Java面试题,以供参考
大家都说大厂面试造飞机,工作拧螺丝.这话只对了一部分,大厂是平时拧螺丝,一旦需要飞机时也能造的起来. 目录 技术一面(23问) 技术二面(3大块) JAVA开发技术面试中可能问到的问题(17问) JA ...
- Invalid attempt to spread non-iterable instance
问题在于对数据的操作,或数据类型,或数据名称
- TP5.1 调用common里面自定义的常量
公共文件:\application\common.php define('cms_password', cms); 控制器引用: 调用: $aa = cms_password; dump(cms_pa ...
- Java中的equals与==
package demo; public class Test { public static void main(String[] args) { String str1 = new String( ...
- Android程序员事件分发机制学习笔记
通过问题来学习一个东西是很好的方法.学习Android中View的事件体系,我也通过给自己提问题,在解决问题的同时也就知道了其中原理. 首先来几个问题起步: 什么是事件?什么是事件分发机制? 在我们通 ...
- 数据结构篇——字典树(trie树)
引入 现在有这样一个问题, 给出\(n\)个单词和\(m\)个询问,每次询问一个单词,回答这个单词是否在单词表中出现过. 好像还行,用 map<string,bool> ,几行就完事了. ...
- jQuery中关于Ajax的详解
原文来自:http://developer.51cto.com/art/201205/335732.htm Ajax让用户页面丰富起来, 增强用户体验. Ajax是所有Web开发的必修课. 虽然Aja ...
- eclipse export runnable jar(导出可执行jar包) runnable jar可以执行的
如果要导出可运行的JAR文件,需要选择Runnable Jar File. 1. 选择要到处JAR文件的工程,右键选择“Export”: 2. 选择“Java-->Runnable JAR fi ...
- 1. vue 的安装
兼容性 Vue 不支持 IE8 及以下版本,因为 Vue 使用了 IE8 无法模拟的 ECMAScript 5 特性.但它支持所有兼容 ECMAScript 5 的浏览器. 安装: 1.直接用 < ...