Flink 之 Data Sink
首先 Sink 的中文释义为:
下沉; 下陷; 沉没; 使下沉; 使沉没; 倒下; 坐下;
所以,对应 Data sink 意思有点把数据存储下来(落库)的意思;
Source 数据源 ---- > Compute 计算 -----> sink 落库
如上图,Source 就是数据的来源,中间的 Compute 其实就是 Flink 干的事情,可以做一系列的操作,操作完后就把计算后的数据结果 Sink 到某个地方。(可以是 MySQL、ElasticSearch、Kafka、Cassandra 等)。
这里我说下自己目前做告警这块就是把 Compute 计算后的结果 Sink 直接告警出来了(发送告警消息到钉钉群、邮件、短信等),这个 sink 的意思也不一定非得说成要把数据存储到某个地方去。
其实官网用的 Connector 来形容要去的地方更合适,这个 Connector 可以有 MySQL、ElasticSearch、Kafka、Cassandra RabbitMQ 等。
Data Source 介绍了 Flink Data Source 有哪些,这里也看看 Flink Data Sink 支持的有哪些:

看下源码有哪些呢?

可以看到有 Kafka、ElasticSearch、Socket、RabbitMQ、JDBC、Cassandra POJO、File、Print 等 Sink 的方式。
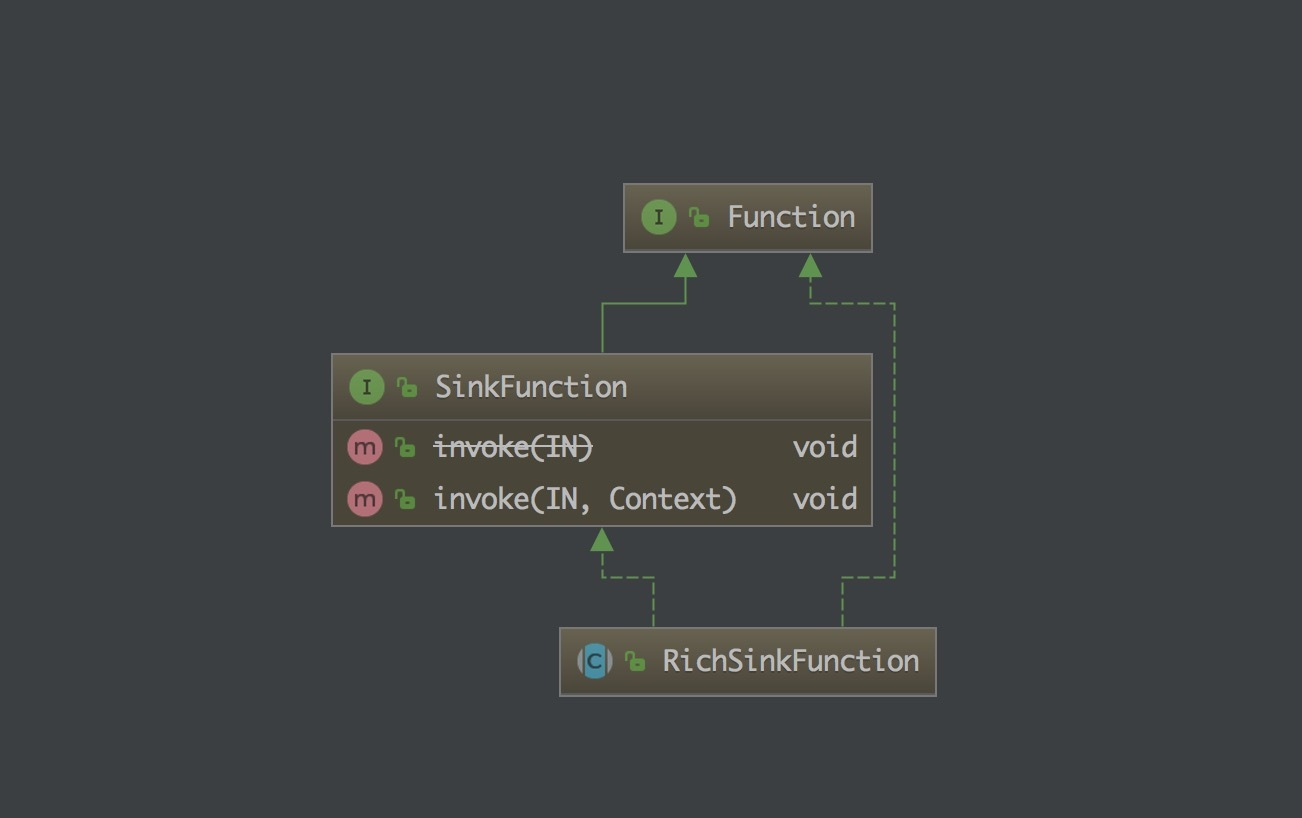
从上图可以看到 SinkFunction 接口有 invoke 方法,它有一个 RichSinkFunction 抽象类。
上面的那些自带的 Sink 可以看到都是继承了 RichSinkFunction 抽象类,实现了其中的方法,那么我们要是自己定义自己的 Sink 的话其实也是要按照这个套路来做的。
这里就拿个较为简单的 PrintSinkFunction 源码来讲下:
@PublicEvolving
public class PrintSinkFunction<IN> extends RichSinkFunction<IN> {
private static final long serialVersionUID = 1L; private static final boolean STD_OUT = false;
private static final boolean STD_ERR = true; private boolean target;
private transient PrintStream stream;
private transient String prefix; /**
* Instantiates a print sink function that prints to standard out.
*/
public PrintSinkFunction() {} /**
* Instantiates a print sink function that prints to standard out.
*
* @param stdErr True, if the format should print to standard error instead of standard out.
*/
public PrintSinkFunction(boolean stdErr) {
target = stdErr;
} public void setTargetToStandardOut() {
target = STD_OUT;
} public void setTargetToStandardErr() {
target = STD_ERR;
} @Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
StreamingRuntimeContext context = (StreamingRuntimeContext) getRuntimeContext();
// get the target stream
stream = target == STD_OUT ? System.out : System.err; // set the prefix if we have a >1 parallelism
prefix = (context.getNumberOfParallelSubtasks() > 1) ?
((context.getIndexOfThisSubtask() + 1) + "> ") : null;
} @Override
public void invoke(IN record) {
if (prefix != null) {
stream.println(prefix + record.toString());
}
else {
stream.println(record.toString());
}
} @Override
public void close() {
this.stream = null;
this.prefix = null;
} @Override
public String toString() {
return "Print to " + (target == STD_OUT ? "System.out" : "System.err");
}
}
可以看到它就是实现了 RichSinkFunction 抽象类,然后实现了 invoke 方法,这里 invoke 方法就是把记录打印出来了就是,没做其他的额外操作。
如何使用?
SingleOutputStreamOperator.addSink(new PrintSinkFunction<>();
这样就可以了,如果是其他的 Sink Function 的话需要换成对应的。
使用这个 Function 其效果就是打印从 Source 过来的数据,和直接 Source.print() 效果一样。

下篇文章我们将讲解下如何自定义自己的 Sink Function,并使用一个 demo 来教大家,让大家知道这个套路,且能够在自己工作中自定义自己需要的 Sink Function,来完成自己的工作需求。
最后
本文主要讲了下 Flink 的 Data Sink,并介绍了常见的 Data Sink,也看了下源码的 SinkFunction,介绍了一个简单的 Function 使用, 告诉了大家自定义 Sink Function 的套路,下篇文章带大家写个。
原创地址为:http://www.54tianzhisheng.cn/2018/10/29/flink-sink/
Flink 之 Data Sink的更多相关文章
- 《从0到1学习Flink》—— Data Sink 介绍
前言 再上一篇文章中 <从0到1学习Flink>-- Data Source 介绍 讲解了 Flink Data Source ,那么这里就来讲讲 Flink Data Sink 吧. 首 ...
- 《从0到1学习Flink》—— 如何自定义 Data Sink ?
前言 前篇文章 <从0到1学习Flink>-- Data Sink 介绍 介绍了 Flink Data Sink,也介绍了 Flink 自带的 Sink,那么如何自定义自己的 Sink 呢 ...
- Flink 从 0 到 1 学习 —— 如何自定义 Data Sink ?
前言 前篇文章 <从0到1学习Flink>-- Data Sink 介绍 介绍了 Flink Data Sink,也介绍了 Flink 自带的 Sink,那么如何自定义自己的 Sink 呢 ...
- 《从0到1学习Flink》—— Data Source 介绍
前言 Data Sources 是什么呢?就字面意思其实就可以知道:数据来源. Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集.历史的数据集:也可以用来做流处理,即实时的处理些 ...
- flink with rabbitmq,sink source mysql redis es
flink-dockerhttps://github.com/melentye/flink-docker https://shekharsingh.com/blog/2016/11/12/apache ...
- 如何用Flink把数据sink到kafka多个(成百上千)topic中
需求与场景 上游某业务数据量特别大,进入到kafka一个topic中(当然了这个topic的partition数必然多,有人肯定疑问为什么非要把如此庞大的数据写入到1个topic里,历史留下的问题,现 ...
- 如何用Flink把数据sink到kafka多个不同(成百上千)topic中
需求与场景 上游某业务数据量特别大,进入到kafka一个topic中(当然了这个topic的partition数必然多,有人肯定疑问为什么非要把如此庞大的数据写入到1个topic里,历史留下的问题,现 ...
- Flink 之 Data Source
Data Sources 是什么呢?就字面意思其实就可以知道:数据来源. Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集.历史的数据集: 也可以用来做流处理,即实时的处理些实时 ...
- 《从0到1学习Flink》—— Flink Data transformation(转换)
前言 在第一篇介绍 Flink 的文章 <<从0到1学习Flink>-- Apache Flink 介绍> 中就说过 Flink 程序的结构 Flink 应用程序结构就是如上图 ...
随机推荐
- Spark 用Scala和Java分别实现wordcount
Scala import org.apache.spark.{SparkConf, SparkContext} object wordcount { def main(args: Array[Stri ...
- LFS7.10——构造临时Linux系统
参考:LFS编译——准备Host系统 前言 在准备好Host环境后,接下来构造一个临时Linux系统.该系统包含****构建所需要的工具.构造临时Linux系统分两步: 构建一个宿主系统无关的新工具链 ...
- css详解3
推荐学习链接:css盒模型 1.盒模型的常用属性 1.1.pading <html lang="en"> <head> <meta charset=& ...
- 数据库类型对应Java语言类型表
下表列出了基本 SQL Server.JDBC 和 Java 编程语言数据类型之间的默认映射: SQL Server 类型 JDBC 类型 (java.sql.Types) Java 语言类型 big ...
- Python3执行top指令
import subprocess top_info = subprocess.Popen(["], stdout=subprocess.PIPE) out, err = top_info. ...
- pyserial 挺强大的
Ref: https://pythonhosted.org/pyserial/ pyserial写的很规范,无论安装和使用都非常的容易,目前使用下来非常好. 没有使用它做过压力测试,不知道表现如何. ...
- Python通过lxml库遍历xml通过xpath查询(标签,属性名称,属性值,标签对属性)
xml实例: 版本一: <?xml version="1.0" encoding="UTF-8"?><country name="c ...
- 优化MyEclipse编译速度慢的问题、build、project clean 慢
优化MyEclipse编译速度慢的问题(重点是1) 1 .关闭MyEclipse的自动validation windows > perferences > myeclipse > v ...
- js判断日期格式(YYYYMM)
function datepanduan(obj){ var date = document.getElementById(obj.id).value; var reg = /^\b[1-3]\d{3 ...
- nginx优化、负载均衡、rewrite
nginx优化 # 普通用户启动 (useradd nginx -s /sbin/nologin -M) user nginx; # 配置nginx worker进程个数 #worker_proces ...