python网络爬虫入门(二)
刚去看了一下,18年2月份写了第一篇关于爬虫的文章(仅仅介绍了使用requests库去获取HTML代码),一年多之后看来很稚嫩也没有多少参考的意义,但没想着要去修改它,留着也是一个回忆吧。至少证明着我是有些许进步的,愿你也是一样!
下面是它的姊妹篇,介绍使用requests和bs4(BeautifulSoup)库来爬取静态网页中的信息。
爬虫从黑盒的角度来看,就是给出网页的链接,输出你想要的信息的一段程序。大概会涉及这几个步骤:

1. 使用requests+re正则
单纯使用requests库来做,需要会写正则表达式,这里借助之前的那篇 爬取猫眼Top100榜单 来讲。
第一步——获取HTML代码
一般使用requests库get()方法,这里封装成为一个函数
def get_one_page(url):
try:
headers = {
'user-agent':'Mozilla/5.0'
}
# use headers to avoid 403 Forbidden Error(reject spider)
response = requests.get(url, headers=headers)
if response.status_code == 200 :
return response.text
return None
except RequestException:
return None
第二部——分析页面HTML代码,写正则表达式,提取信息
先来看页面
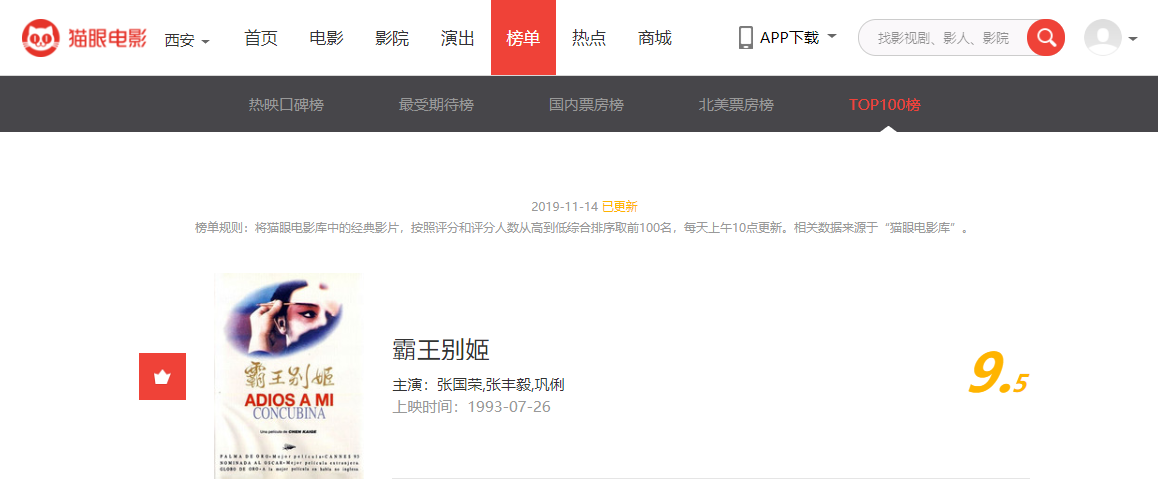
分析它的HTML,我目前需要排名、片名、主演、上映时间和评分信息。
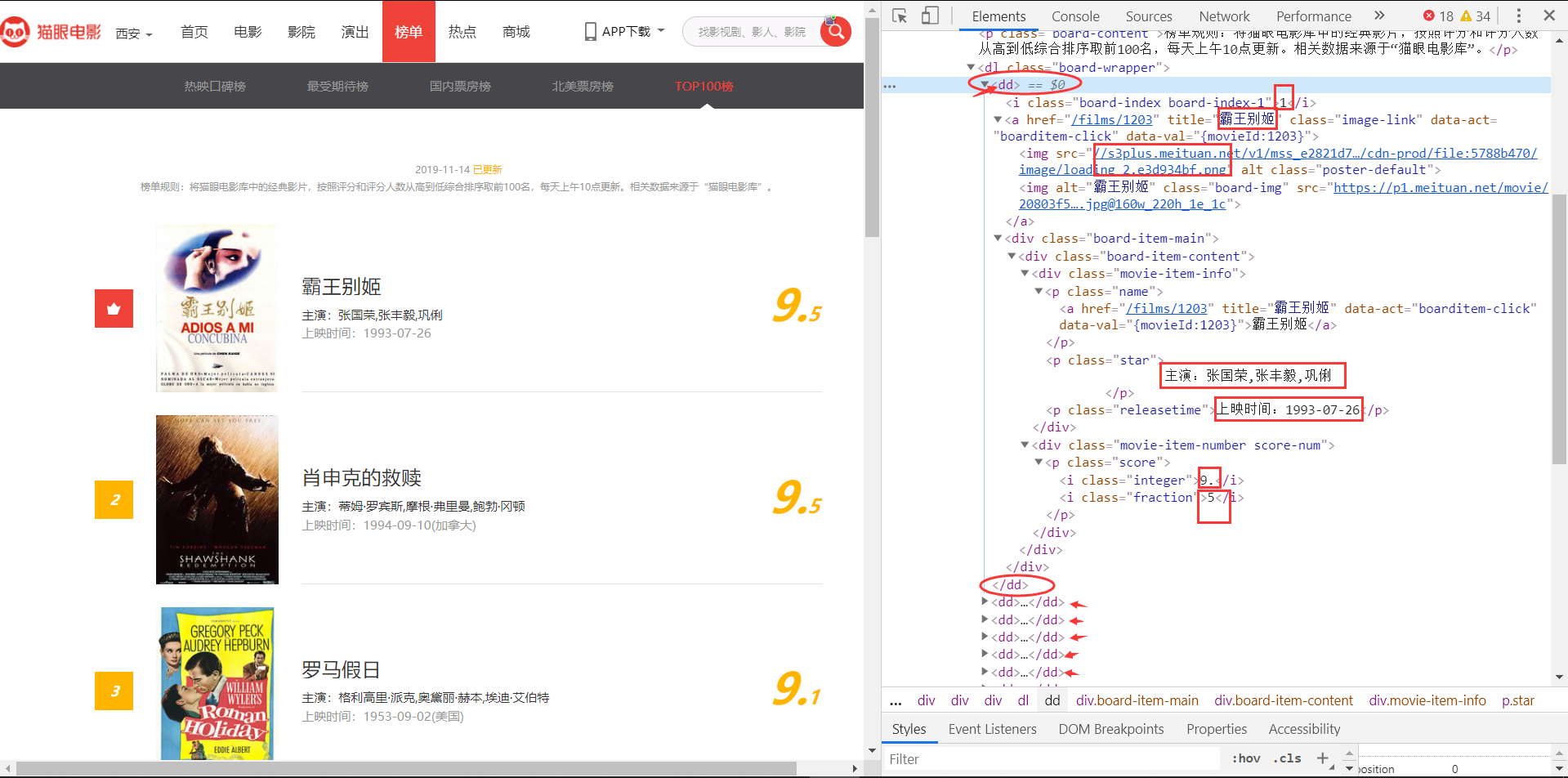
可以看到,榜单中每一个电影条目都在一组<dd></dd>标签中,而且所需的信息也很明确,我们来写正则,正则的关键在于找好独一无二的参照(已在途中方格标出)
re_text =
'<dd>.*?board-index.*?>(\d+)<.*?<a.*?title="(.*?)"'
+'.*?data-src="(.*?)".*?</a>.*?star">[\\s]*(.*?)[\\n][\\s]*</p>.*?'
+'releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?'
+'fraction">(.*?)</i>.*?</dd>'
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)<.*?<a.*?title="(.*?)"'
+'.*?data-src="(.*?)".*?</a>.*?star">[\\s]*(.*?)[\\n][\\s]*</p>.*?'
+'releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?'
+'fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
return items
先编译正则表达式成为pattern,然后在页面中findall符合条件的信息。这样就会将正则表达式匹配到的所有信息,以一个列表的形式返回。
第三部——持久化存储数据
我所做的实践由于数据量较小,目前都是采用excel(*.xlsx)来存储。需要用到一个openpyxl库,自行安装即可,它的使用教程有很多,不是我所述的主要内容,烦请自行学习。
已经爬到的数据
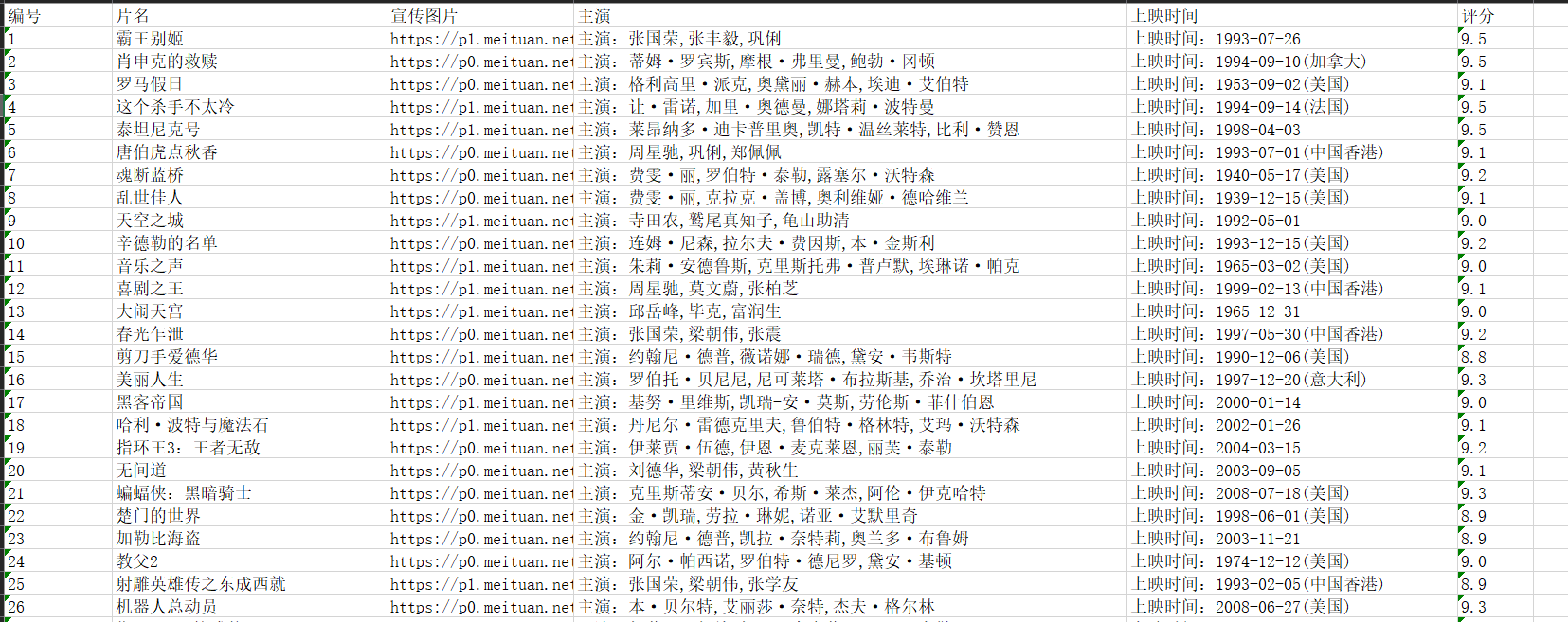
注意:上面所讲的是获取一个页面(含20条信息,该榜单有100条,势必会有分页),所以URL肯定需要替换,但是肯定是有规律的(具体的看这篇博客吧 猫眼top100 )
2. 使用bs4(BeautifulSoup)筛选器
使用bs4库,需要先自己安装一下。
所谓筛选器,即相当于我们上面正则表达式中的“参考”,即:锚点。通过筛选器,可以非常方便的获取页面当中的信息。下面讲一个例子,就明白了。
栗子:
获取博客园新闻板块第一条的新闻title,先来瞧瞧HTML和selector。
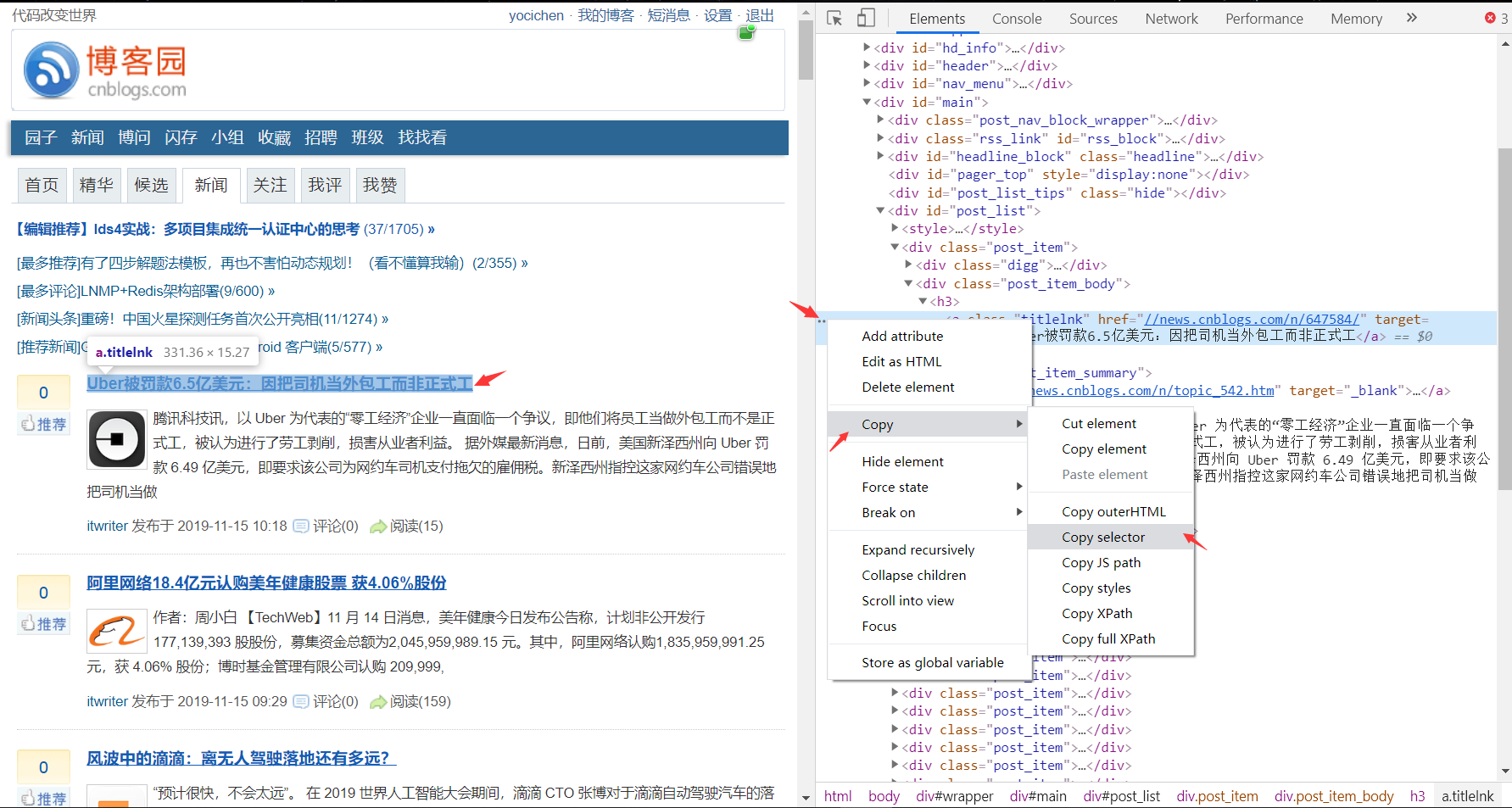
代码:
# -*- coding: utf-8 -*-
# @Author : yocichen
# @Email : yocichen@126.com
# @File : test_bs4.py
# @Software: PyCharm
# @Time : 2019/11/15 10:23 import requests
from bs4 import BeautifulSoup
import lxml url = 'https://www.cnblogs.com/news/'
headers = {
'user-agent':'Mozilla/5.0'
}
# 获取HTML
html = requests.get(url, headers=headers)
# 解析HTML
soup = BeautifulSoup(html.text, 'lxml')
# 筛选器筛选信息
selector = '#post_list > div:nth-child(2) > div.post_item_body > h3 > a'
res = soup.select(selector)
print('博客园新闻板块第一条title\n', res[0].string)
结果:

可以看到,获取selector十分简单,chrome浏览器或者其他浏览器也有支持,这样一来就避免了去写繁杂的正则表达还写不出来的窘境。
最终的持久化存储过程,同上,不再赘述。
后记
python爬虫入门篇就此结束了,爬虫深入的话还涉及到防止反爬,以及爬取动态页面等问题,有机会的话会再学习再写一篇。
以上内容其实是对我最近所学所做的总结,如果你从中也有些许收获,不妨点个“推荐”吧!
python网络爬虫入门(二)的更多相关文章
- python网络爬虫入门范例
python网络爬虫入门范例 Windows用户建议安装anaconda,因为有些套件难以安装. 安装使用pip install * 找出所有含有特定标签的HTML元素 找出含有特定CSS属性的元素 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- python 网络爬虫(二) BFS不断抓URL并放到文件中
上一篇的python 网络爬虫(一) 简单demo 还不能叫爬虫,只能说基础吧,因为它没有自动化抓链接的功能. 本篇追加如下功能: [1]广度优先搜索不断抓URL,直到队列为空 [2]把所有的URL写 ...
- python 网络爬虫(二)
一.编写第一个网络爬虫 为了抓取网站,我们需要下载含有感兴趣的网页,该过程一般被称为爬取(crawling).爬取一个网站有多种方法,而选择哪种方法更加合适,则取决于目标网站的结构. 首先探讨如何安全 ...
- python网络爬虫-入门(二)
为什么要学网络爬虫 可以替代人工从网页中找到数据并复制粘贴到excel中,这种重复性的工作不仅浪费时间还一不留神还会出错----解决无法自动化和无法实时获取数据 对于这些公开数据的应用价值,我 ...
- Python网络爬虫入门篇
1. 预备知识 学习者需要预先掌握Python的数字类型.字符串类型.分支.循环.函数.列表类型.字典类型.文件和第三方库使用等概念和编程方法. 2. Python爬虫基本流程 a. 发送请求 使用 ...
- Python网络爬虫入门实战(爬取最近7天的天气以及最高/最低气温)
_ 前言 本文文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Bo_wen 最近两天学习了一下python,并自己写了一个 ...
- python网络爬虫-入门(一)
前言 1.爬虫程序是Dt(Data Technology,数据技术)收集信息的基础,爬取到目标网站的资料后,就可以分析和建立应用了. 2.python是一个简单.有效的语言,爬虫所需要的获取.存储.整 ...
- python网络爬虫入门(一)
python网络爬虫(一) 2018-02-10 python版本:python 3.7.0b1 IDE:PyCharm 2016.3.2 涉及模块:requests & builtwit ...
随机推荐
- php常用命令
--------------------------------------------------------------- 重启phpservice php-fpm restart ------- ...
- java8之Spliterator
基本用法: import java.util.Arrays; import java.util.Spliterator; import java.util.stream.IntStream; publ ...
- [E2E_L9]类化和级联化
一.多车辆识别可能和车辆车牌分割: 这样一张图,可以识别多车辆和车牌,问题是如何区分并且配对. 0 1 7 8 是否是车牌可以通过图片的大小进行判断.而配对是前后顺序的. // ------- ...
- docker vim右键进入visual模式无法粘贴
右键不能粘贴,反而进入了visual模式, vim版本:version 8.0.707 修改方法: vim /usr/share/vim/vim80/defaults.vim 第70行 在mouse= ...
- stylelint那些事儿
一.参考文档 - http://stylelint.cn/ - https://stylelint.io/ - https://stylelint.io/user-guide/exampl ...
- 使用Termux,在手机上做nodejs编程,运行nodejs程序。
如果你是一名nodejs开发者,是否想过以下问题:在手机上运行nodejs程序?用手机当nodejs服务器?在手机上做nodejs编程?YES!使用Termux,以上都可以做到! 下面展示如何实现这个 ...
- [LeetCode] 3.Longest Substring Without Repeating Characters 最长无重复子串
Given a string, find the length of the longest substring without repeating characters. Example 1: In ...
- [LeetCode] 49. Group Anagrams 分组变位词
Given an array of strings, group anagrams together. For example, given: ["eat", "tea& ...
- [LeetCode] 407. Trapping Rain Water II 收集雨水 II
Given an m x n matrix of positive integers representing the height of each unit cell in a 2D elevati ...
- [ERROR] Failed to execute goal org.apache.maven.plugins:maven-install-plugin:2.4: install (default-install) on project authorizationManagement-service: Failed to install metadata com.dmsdbj.itoo:autho
今天在打包时遇到这个问题: [ERROR] Failed to execute goal org.apache.maven.plugins:maven-install-plugin:2.4: inst ...