HDFS-SecondaryNameNode(SNN)角色介绍
它出现在Hadoop1.x版本中,又称辅助NameNode,在Hadoop2.x以后的版本中此角色消失。如果充当datanode节点的一台机器宕机或者损害,其数据不会丢失,因为备份数据还存在于其他的datanode中。但是,如果充当namenode节点的机器宕机或损害导致文件系统无法使用,那么文件系统上的所有文件将会丢失,因为我们不知道如何根据datanode的块重建文件。因此,对namenode实现容错非常重要。Hadoop提供了两种机制实现高容错性。
第一种机制是备份那些组成文件系统元数据持久状态的文件。Hadoop可以通过配置使namenode在多个文件系统上保存元数据的持久化状态。这些写操作是实时同步的,是原子操作。一般的配置是,将持久状态写入本地磁盘的同时,写入一个远程挂载的网络文件系统(NFS)。
另一种可行的方法是运行一个辅助namenode,但是它不能用作namenode,这个辅助namenode,在hadoop1.x中被称为secondary namenode,在hadoop2.x中,利用高可用(HA)解决单点故障问题。
Secondary namenode,以下简称SN,其重要作用是定期将编辑日志和元数据信息合并,防止编辑日志文件过大,并且能保证其信息与namenode信息保持一致。SN一般在另一台单独的物理计算机上运行,因为它需要占用大量CPU时间来与namenode进行合并操作,一般情况是单独开一个线程来执行操作过程。但是,SN保存的信息永远是滞后于namenode,所以在namenode失效时,难免会丢失部分数据。在这种情况下,一般把存储在NFS上的namenode元数据复制到SN并作为新的namenode。SN不是namenode的备份,可以作为备份。SN主要工作是帮助NN合并edits和fsimage,减少namenode的启动时间。
它不是NameNode的备份,但可以做备份,其主要工作是帮助NameNode合并editslog,减少NameNode的启动时间。SecondaryNameNode执行合并的时机决定于:
(1) 配置文件设置的时间间隔fs.checkpoint.period,默认为3600秒。
(2) 配置文件设置edits log大小fs.checkpoint.size,规定edits文件的最大值默认是64MB。
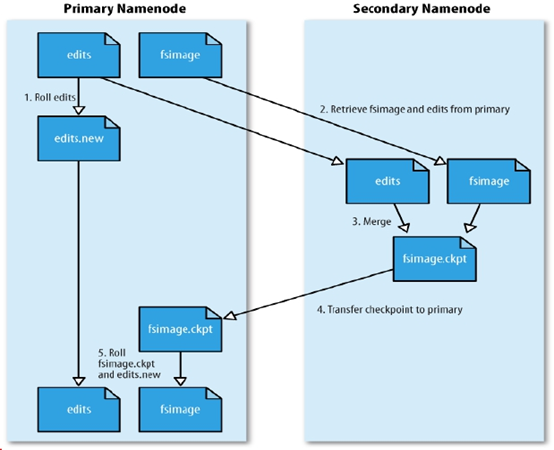
图1.6 SecondaryNameNode合并流程
如上图,当namenode运行了3600s后,SN取出fsimage和edits,合并,更新fsimage,命名为fsimage.ckpt,将fsimage.ckpt文件传入namenode中,合并过程中,客户端会继续上传文件。同时,namenode会创建新的edits.new文件,将合并过程中,产生的日志存入edits.new,namenode将 fsimage.ckpt,更名为fsimage,edits.new更名为edits。
如果在合并过程中,namenode损坏,那么,丢失了在合并过程中产生的edits.new,因此namenode失效时,难免会丢失部分数据。
HDFS-SecondaryNameNode(SNN)角色介绍的更多相关文章
- Spark角色介绍及spark-shell的基本使用
Spark角色介绍 1.Driver 它会运行客户端的main方法,构建了SparkContext对象,它是所有spark程序的入口 2.Application 它就是一个应用程序,包括了Driver ...
- HDFS中hsync方法介绍
HDFS中hsync方法介绍 原创文章,转载请注明:博客园aprogramer 原文链接:HDFS中hsync方法介绍 1. 背景介绍 HDFS在写数据务必要保证数据的一致性与持久性,从HDFS最初的 ...
- 【Q】类和对象:游戏角色开发(角色介绍)
案例情景:某公司要开发新游戏,请用面向对象的思想设计英雄类.怪物类和武器类. 编写测试类,创建英雄对象.怪物对象和武器对象,并输出各自的信息. 其中设定分别如下: 1.英雄类 属性:英雄名字.生命值. ...
- 2 Spark角色介绍及运行模式
第2章 Spark角色介绍及运行模式 2.1 集群角色 从物理部署层面上来看,Spark主要分为两种类型的节点,Master节点和Worker节点:Master节点主要运行集群管理器的中心化部分,所承 ...
- HBase在HDFS上的目录介绍
总所周知,HBase 是天生就是架设在 HDFS 上,在这个分布式文件系统中,HBase 是怎么去构建自己的目录树的呢? 第一,介绍系统级别的目录树. 一.0.94-cdh4.2.1版本 系统级别的一 ...
- 大数据框架hadoop服务角色介绍
翻了一下最近一段时间写的分享,DKHadoop发行版本下载.安装.运行环境部署等相关内容几乎都已经写了一遍了.虽然有的地方可能写的不是很详细,个人理解水平有限还请见谅吧!我记得在写DKHadoop运行 ...
- Windows Server 2016-FSMO操作主机角色介绍
FSMO五个操作主机角色 1.林范围操作主机角色(两种): 架构主机角色:Schema Master 域命名主机角色:Domain Naming Master 2.域范围操作主机角色(三种): 域范围 ...
- 012_Eclipse中使用 HDFS URL API 事例介绍
本事例其实和使用hdfs FileSystem API差不多,FileSystem API也是通过解释成URL在hdfs上面执行的,性质相同,但是实际中用 的fFileSystem会多一点,源码如下: ...
- javascript中间preventDefault与stopPropagation角色介绍
preventDefault的作用是什么方法,它? 我们知道,例如,<a href="http://www.baidu.com">百度</a>,这是html ...
随机推荐
- ArcGIS 要素类整体平移工具-arcgis/arcpy/模型构建器案例实习教程
ArcGIS 要素类整体平移工具-arcgis/arcpy/模型构建器案例实习教程 联系方式:谢老师,135-4855_4328,xiexiaokui#qq.com 目的:对整个要素类,按指定偏移距离 ...
- Oracle中如何修改已存在数据的列名的数据类型
在oracle中,如何修改已存在数据列名的数据类型 一般人直接在表结构设计这里修改,这里只适合修改列没有数据,可修改 那么,如何这个列是有数据,是怎么修改的呢? 直接修改会Oracle错误 第一步:先 ...
- EOS require_auth函数
action的结构 要说清楚这个方法的含义和用法,咱们需要从action的结构说起.详见eoslib.hpp中的action类,这里把它的结构简化表示成下面这样: * struct action { ...
- nginx-rtmp
最近使用ffmpeg推流为rtmp,进行直播.记录一下nginx-rtmp的配置.因为我们要添加ngin-rtmp模块,所以不能直接apt安装. 下载niginx和nginx-rtmp-module的 ...
- Linux共享文件夹映射到Windows磁盘
摘自:https://www.jianshu.com/p/4a06121450e5 1.1方案背景 本方案就是在解决磁盘不足的问题而产生的,利用映射盘的原理将Linux共享文件夹映射到Windows磁 ...
- Java虚拟机栈(java stack)
虚拟机栈(java stack) 百度图片搜索里的动图搜索功能不错,可以搜索一些动图,展示操作数栈的操作过程,比较形象.这点google差点意思 虚拟机栈(jvm stacks)是线程独占的 里面是多 ...
- Indy10 Tcp接收数据问题
在做Delphi开发时,使用Indy组件来做网络通讯是一种比较快捷的方式.今天要说一下indy10中tcp接收数据的问题. 我们在测试时经常使用Wrinteln来发送数据,用Readln来接收数据.用 ...
- python面试题300道
本文截取了一些面试题及解决方案: Python 基础 文件操作 模块与包 数据类型 企业面试题 Python 高级 设计模式 系统编程 Python 基础 什么是 Python?根据Python 创建 ...
- testNG的安装
1,testNG介绍 TestNG ( Testing Next Generation ,下一代测试技术) testNG的强大之处在于它是 利用注释(注解) 来强化测试功能的测试框架,可以用来做接口测 ...
- c++ 初始化
1. 内置类型默认初始化 内置类型如果没有被显示初始化,则会被编译器默认初始化.初始化会根据①变量类型的不同②变量类型位置,来决定初始化之后的值.但是内置类型如果在函数体内部,则将不被初始化——也就是 ...