spark 机器学习 随机森林 实现(二)
通过天气,温度,风速3个特征,建立随机森林,判断特征的优先级
结果 天气 温度 风速
结果(0否,1是)
天气(0晴天,1阴天,2下雨)
温度(0热,1舒适,2冷)
风速(0没风,1微风,2大风)
1 1:0 2:1 3:0
结果去打球 1字段:晴天 2字段:温度舒适 3字段:风速没风
[hadoop@h201 pp]$ cat pp1.txt
1 1:0 2:1 3:0
0 1:2 2:2 3:2
1 1:0 2:0 3:0
1 1:0 2:0 3:1
1 1:0 2:1 3:1
1 1:0 2:1 3:1
1 1:0 2:1 3:0
0 1:1 2:2 3:2
0 1:1 2:2 3:2
0 1:2 2:2 3:2
0 1:2 2:1 3:1
0 1:2 2:1 3:2
0 1:1 2:2 3:2
1 1:0 2:1 3:0
本例子 用官方提供代码进行更改完成
hadoop fs -put pp1.txt /
scala> import org.apache.spark.mllib.tree.RandomForest
scala> import org.apache.spark.mllib.tree.model.RandomForestModel
scala> import org.apache.spark.mllib.util.MLUtils
val data = MLUtils.loadLibSVMFile(sc, "hdfs://h201:9000/pp1.txt")
//标记点是将密集向量或者稀疏向量与应答标签相关联(结果),在MLlib中,标记点用于监督学习算法。LIBSVM是林智仁教授等开发设计的一个简单、易用和快速有效的SVM模式识别与回归的软件包。MLlib已经提供了MLUtils.loadLibSVMFile方法读取存储在LIBSVM格式文本文件中的训练数据
//数据格式 :空格分割,第一部分为结果,后面为特征向量
scala> val splits = data.randomSplit(Array(0.7, 0.3))
scala> val (trainingData, testData) = (splits(0), splits(1))
scala> val numClasses = 2
//分类数
scala> val categoricalFeaturesInfo = Map[Int, Int]()
// categoricalFeaturesInfo 为空,意味着所有的特征为连续型变量
scala> val numTrees = 3
//树的个数
scala> val featureSubsetStrategy = "auto"
//特征子集采样策略,auto 表示算法自主选取
scala> val impurity = "gini"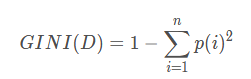
//以性别举例:性别 :1-(1/2)^2-(1/2)^2 =0.5
scala> val maxDepth = 4
//树的最大层次
scala> val maxBins = 32
//特征最大装箱数
val model = RandomForest.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo,
numTrees, featureSubsetStrategy, impurity, maxDepth, maxBins)
//训练随机森林分类器
val labelAndPreds = testData.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
scala> val testErr = labelAndPreds.filter(r => r._1 != r._2).count.toDouble / testData.count()
scala> println("Test Error = " + testErr)
// 测试数据评价训练好的分类器并计算错误率
scala> println("Learned classification forest model:\n" + model.toDebugString)
scala> model.save(sc, "myModelPath")
//持久化保存随机森林
scala> val sameModel = RandomForestModel.load(sc, "myModelPath")
//加载随机森林
spark 机器学习 随机森林 实现(二)的更多相关文章
- spark 机器学习 随机森林 原理(一)
1.什么是随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决 策树之间是没有关联的.在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分 ...
- 使用基于Apache Spark的随机森林方法预测贷款风险
使用基于Apache Spark的随机森林方法预测贷款风险 原文:Predicting Loan Credit Risk using Apache Spark Machine Learning R ...
- 机器学习实战基础(三十五):随机森林 (二)之 RandomForestClassifier 之重要参数
RandomForestClassifier class sklearn.ensemble.RandomForestClassifier (n_estimators=’10’, criterion=’g ...
- Spark mllib 随机森林算法的简单应用(附代码)
此前用自己实现的随机森林算法,应用在titanic生还者预测的数据集上.事实上,有很多开源的算法包供我们使用.无论是本地的机器学习算法包sklearn 还是分布式的spark mllib,都是非常不错 ...
- 机器学习——随机森林,RandomForestClassifier参数含义详解
1.随机森林模型 clf = RandomForestClassifier(n_estimators=200, criterion='entropy', max_depth=4) rf_clf = c ...
- spark 机器学习 knn 代码实现(二)
通过knn 算法规则,计算出s2表中的员工所属的类别原始数据:某公司工资表 s1(训练数据)格式:员工ID,员工类别,工作年限,月薪(K为单位) 101 a类 8年 ...
- 【Spark机器学习速成宝典】模型篇06随机森林【Random Forests】(Python版)
目录 随机森林原理 随机森林代码(Spark Python) 随机森林原理 参考:http://www.cnblogs.com/itmorn/p/8269334.html 返回目录 随机森林代码(Sp ...
- Spark随机森林实现学习
前言 最近阅读了spark mllib(版本:spark 1.3)中Random Forest的实现,发现在分布式的数据结构上实现迭代算法时,有些地方与单机环境不一样.单机上一些直观的操作(递归),在 ...
- 04-10 Bagging和随机森林
目录 Bagging算法和随机森林 一.Bagging算法和随机森林学习目标 二.Bagging算法原理回顾 三.Bagging算法流程 3.1 输入 3.2 输出 3.3 流程 四.随机森林详解 4 ...
随机推荐
- ajax发送json数据时为什么需要设置contentType: "application/json”
1. ajax发送json数据时设置contentType: "application/json”和不设置时到底有什么区别?contentType: "application/js ...
- elasticsearch jestclient api
1.es search sroll 可以遍历索引下所有数据 public class TestDemo { @Test public void searchSroll() { JestClientFa ...
- Oracle系列五 多表查询
笛卡尔集笛卡尔集会在下面条件下产生: 省略连接条件 连接条件无效 所有表中的所有行互相连接 为了避免笛卡尔集, 可以在 WHERE 加入有效的连接条件. Oracle 连接 使用连接在多个表中查询数据 ...
- svg的viewport和viewbox
svg中视区重要的概念 1. viewport 视口,相当于显示器屏幕 2. viewbox 视区,相当于在屏幕上截取一小块,放大到整个屏幕,就是特写的效果 3. preserveAspectR ...
- SqlServer Stuff
SqlServer Stuff DECLARE @TAB TABLE ( UserID INT, UserName ) ) INSERT INTO @TAB ( UserID, UserName ) ...
- mongoDB索引相关
参考链接:MongoDB索引管理-索引的创建.查看.删除 索引 db.集合名.ensureIndex({"key":1}) 使用了ensureIndex在name上建立了索引.”1 ...
- 【VS开发】#pragma pack(push,1)与#pragma pack(1)的区别
这是给编译器用的参数设置,有关结构体字节对齐方式设置, #pragma pack是指定数据在内存中的对齐方式. #pragma pack (n) 作用:C编译器将按照n个字节对 ...
- [神经网络与深度学习][计算机视觉]SSD编译时遇到了json_parser_read.hpp:257:264: error: ‘type name’ declared as function ret
运行make之后出现如下错误: /usr/include/boost/property_tree/detail/json_parser_read.hpp:257:264: error: 'type n ...
- QT笔记--事件处理
1 事件是什么 这里的事件主要是用户输入事件,比如点击一个按钮,选中复选框等.当事件发生的时候,达到我们满意的效果. 2信号与槽 connect(A,XX,B,YY) 当A事件发生的时候,B中的处理函 ...
- Oracle ROWNUM的陷阱
先抛出一个问题: 我有一张表T,现在我想对表中1/4的记录作UPDATE操作,我的SQL如下: Update t set col1='123' where mod(rownum,4)=1 我能够得到想 ...