了解一下Elasticsearch的基本概念
一、前文介绍
Elasticsearch(简称ES)是一个基于Apache Lucene(TM)的开源搜索引擎,无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。注意,Lucene 只是一个库。想要发挥其强大的作用,你需使用 Java 并要将其集成到你的应用中。
Lucene 非常复杂,你需要深入的了解检索相关知识来理解它是如何工作的,就跟学习 springmvc 之前先从 servlet 开始,繁琐复杂的工作,Solor、Elasticsearch 应由而生, 其使用 Java 编写并使用 Lucene 来建立索引并实现搜索功能,但是它的目的是通过简单连贯的 RESTful API 让全文搜索变得简单并隐藏 Lucene 的复杂性。
重要特性:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 实时分析的分布式搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
基本概念:
索引(indices)-------------------Databases 数据库
类型(type)----------------------Table 数据表
文档(Document)---------------Row 行
字段(Field)---------------------Columns 列
详细说明:
| 概念 | 说明 |
|---|---|
| 索引库(indices) | indices是index的复数,代表许多的索引, |
| 类型(type) | 类型是模拟mysql中的table概念,一个索引库下可以有不同类型的索引,比如商品索引,订单索引,其数据格式不同。不过这会导致索引库混乱,因此未来版本中会移除这个概念 |
| 文档(document) | 存入索引库原始的数据。比如每一条商品信息,就是一个文档 |
| 字段(field) | 文档中的属性 |
| 映射配置(mappings) | 字段的数据类型、属性、是否索引、是否存储等特性 |
要注意的是:Elasticsearch 本身就是分布式的,因此即便你只有一个节点,Elasticsearch 默认也会对你的数据进行分片和副本操作,当你向集群添加新数据时,数据也会在新加入的节点中进行平衡。
二、Elasticsearch安装[windows]
如下主要针对 windows 环境下的 Elasticsearch 学习。
下载地址:https://www.elastic.co/cn/products/
解压后,进入 bin/ 目录,双击执行 elasticsearch .bat
Elasticsearch 启动后可以看到绑定了两个端口:
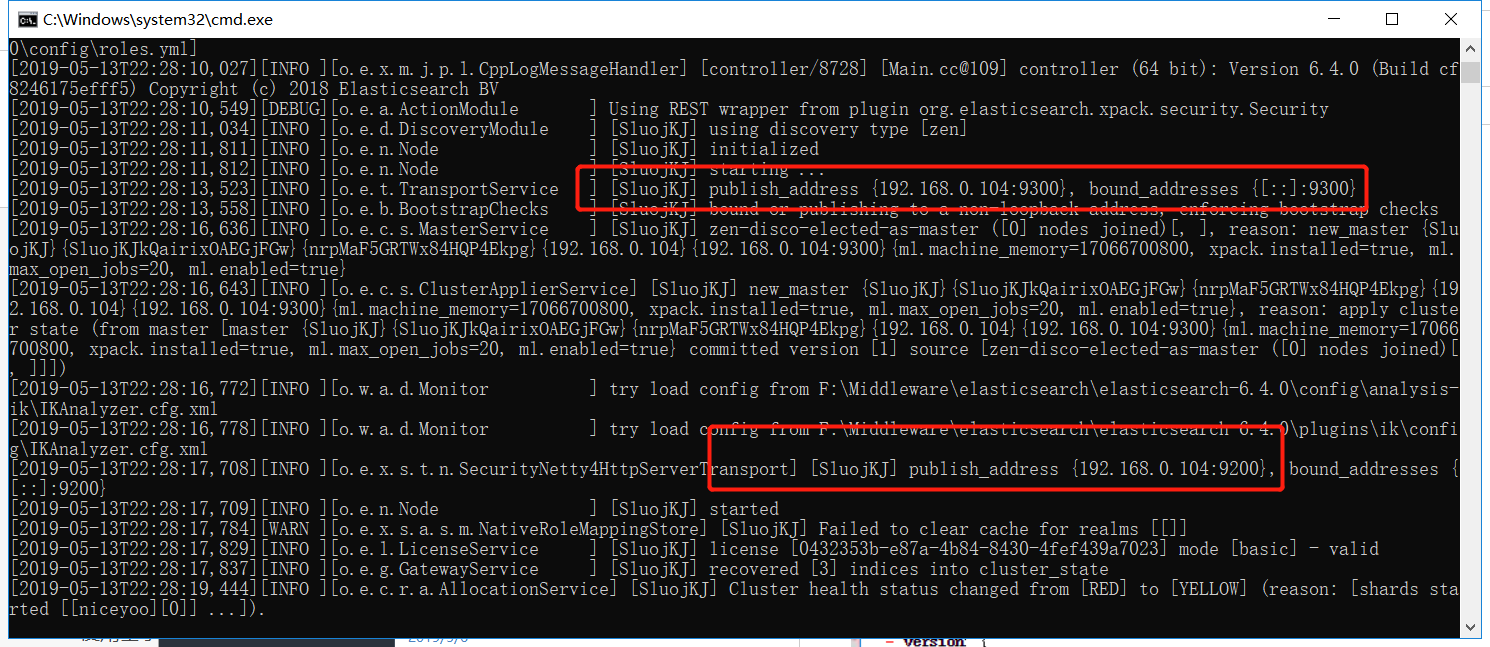
- 9300:集群节点间通讯接口【tcp连接方式,性能优于http】
- 9200:客户端访问接口【接收http请求】
9200,我们可以通过浏览器直接访问,9300 则不可以直接访问。
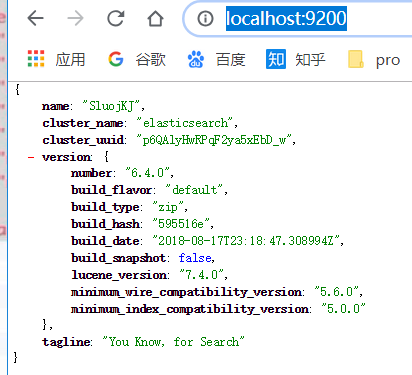
三、Kibana 安装
Kibana 是一个基于 Node.js 的 Elasticsearch 索引库数据统计工具,可以利用 Elasticsearch 的聚合功能,生成各种图表,如柱形图,线状图,饼图等。
而且还提供了操作 Elasticsearch 索引数据的控制台,并且提供了一定的API提示,非常有利于我们学习 Elasticsearch 的语法。
1、配置
我们可以把 Kibana 当成,durid 连接池对于 mysql 的可视化来理解。
下载地址:https://www.elastic.co/cn/downloads/kibana
解压后,进入安装目录下的 config 目录,修改 kibana.yml 文件:
修改elasticsearch服务器的地址,去掉原来的注释:
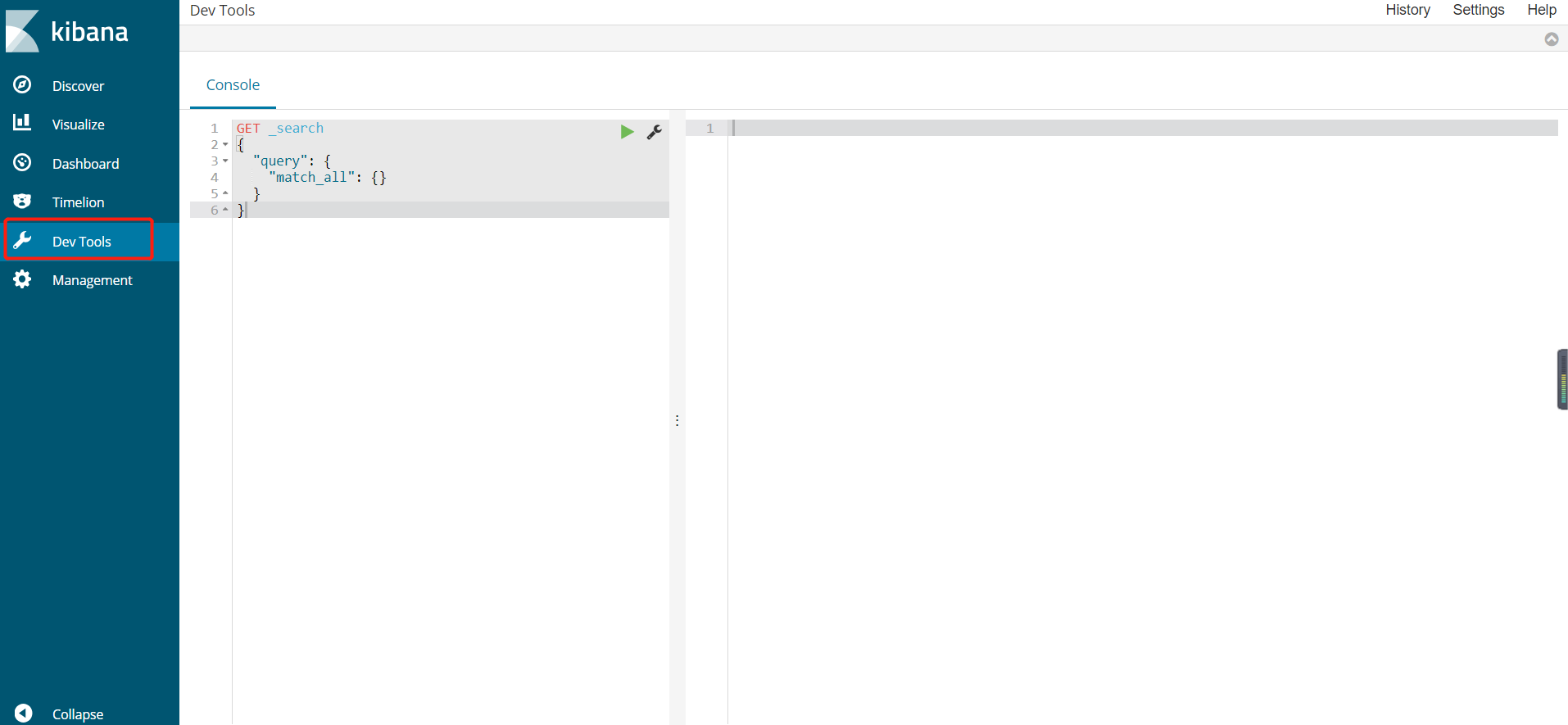
elasticsearch.url: "http://localhost:9200"
Kibana 的监听端口为 5601:http://127.0.0.1:5601 浏览器打开如下图所示:
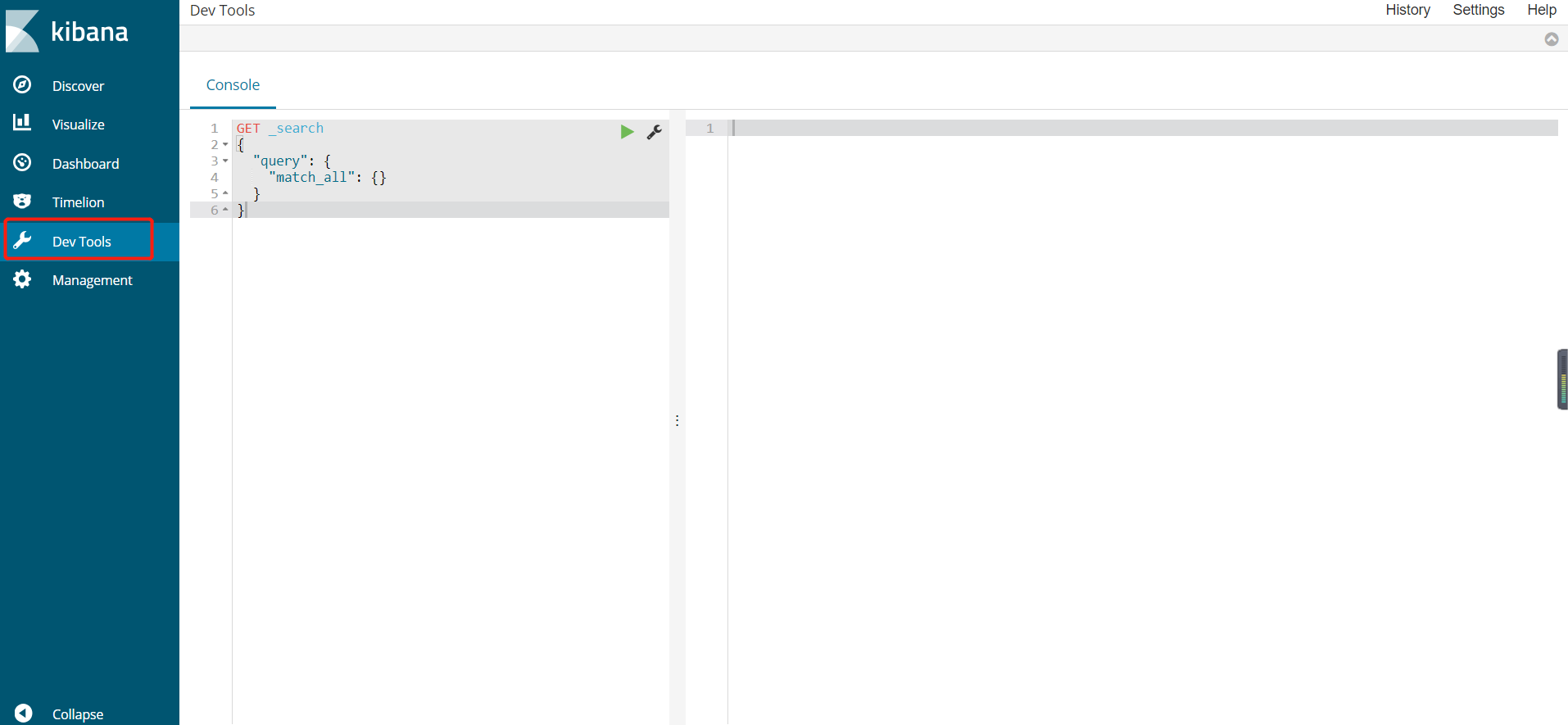
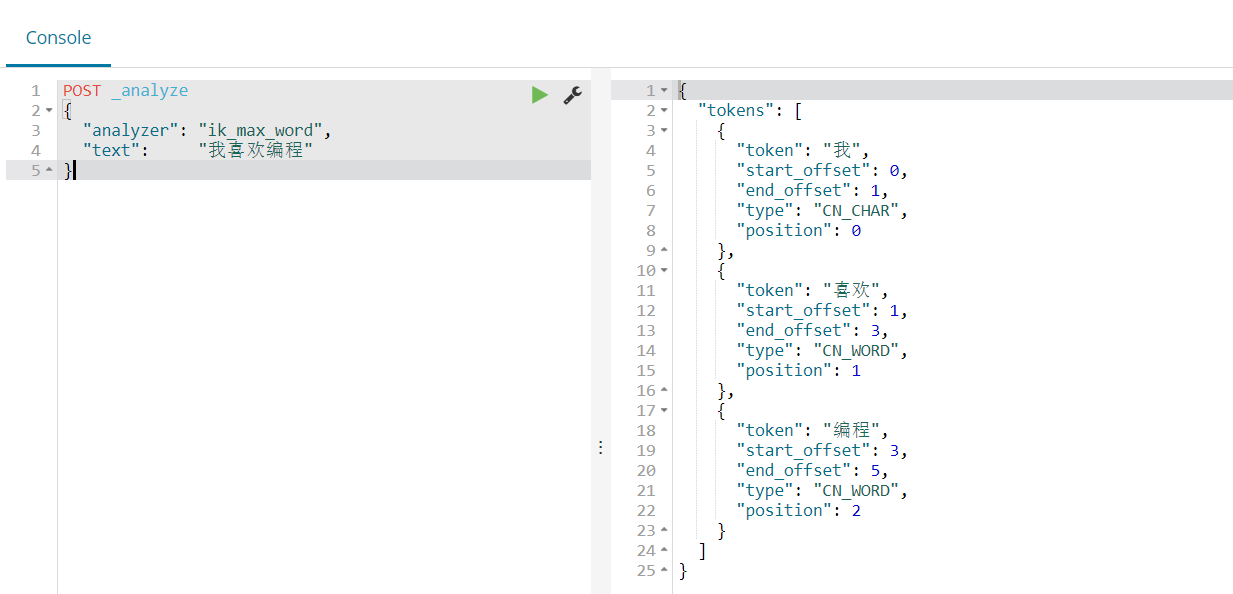
Dev Tools 相当于一个命令行窗口工具,带提示,Elasticsearch 执行的数据格式为 json,举例:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我喜欢编程"
}
四、ik 分词器安装
由于 Elasticsearch 在拆分单词时,是按空格来分,即 hello world 分为 hello 和 world,这是没问题的,但是在拆分中文时也是按照一个汉字一个汉字来拆分。即“我喜欢编程”分为 我、喜、欢、编、程 5个字符,所以就需要用到 IK 分词器这个插件来进行拆分。
Lucene 的 IK 分词器早在 2012 年已经没有维护了,现在我们要使用的是在其基础上维护升级的版本,并且开发为 ElasticSearch 的集成插件了,与 Elasticsearch 一起维护升级,版本也保持一致。
IK下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
注意 ES 与 IK 版本对应地址:https://github.com/medcl/elasticsearch-analysis-ik/tree/2.x
将 zip 包,解压到 Elasticsearch 目录的 plugins 目录中:
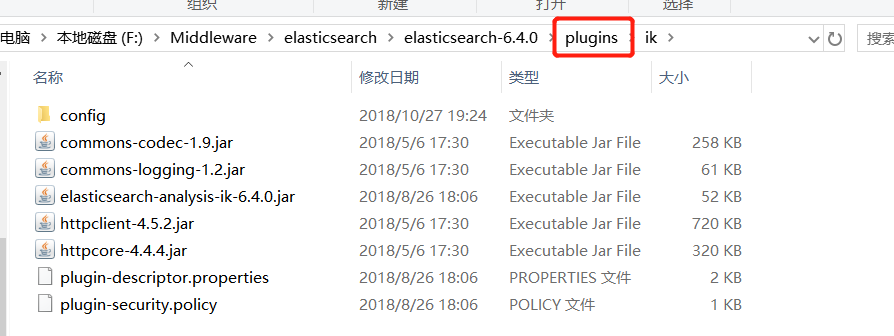
然后重启 Elasticsearch
五、基本概念-详细了解
上文也了解到 ES 操作的数据为 json,实际项目中,比如 springboot 中,无须操作 json,都是面向对象编程,但是,学习其实际原理固然重要。
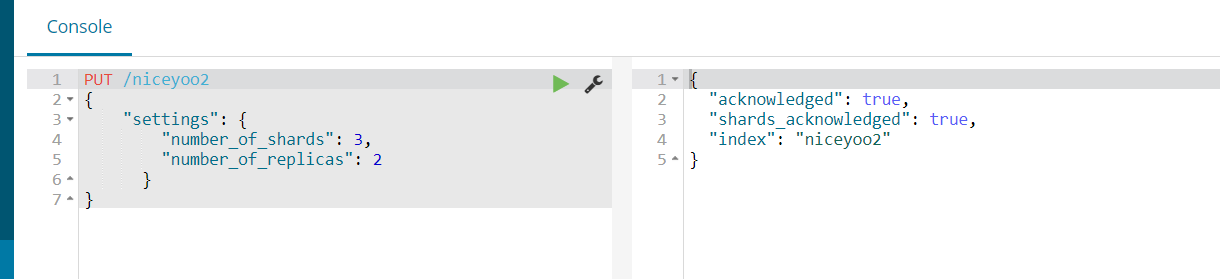
5.1、创建索引
创建索引的请求格式:
- 请求方式:PUT
- 请求路径:/索引库名
- 请求参数:json格式:
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
- settings:索引库的设置
- number_of_shards: 分片数量
- number_of_replicas:副本数量
示例:
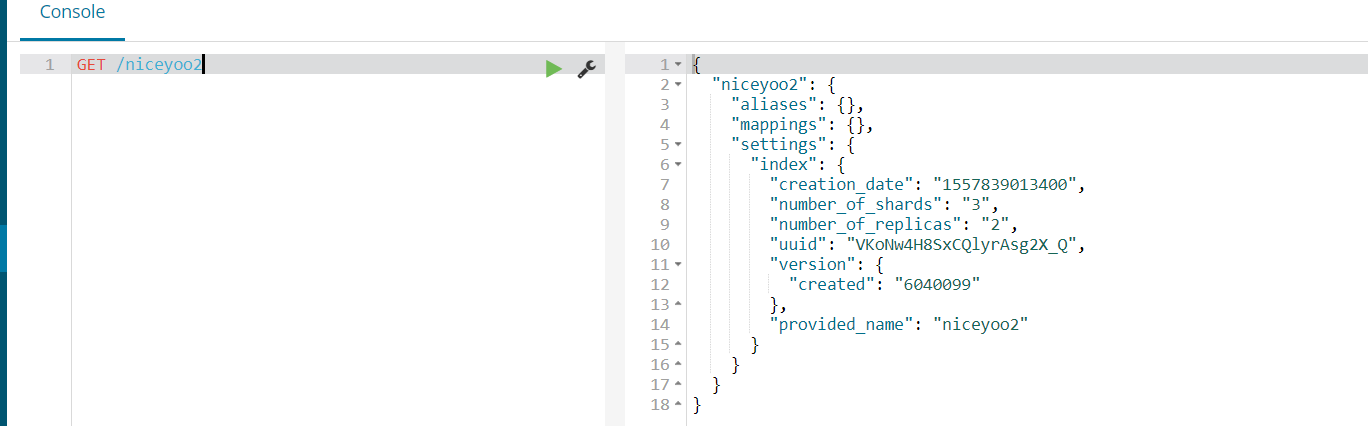
5.2、查看索引设置
语法
Get请求可以帮我们查看索引信息,格式:
GET /索引库名
5.3、删除索引
删除索引使用DELETE请求
语法
DELETE /索引库名

六、映射配置
6.1、创建映射字段
语法
请求方式依然是PUT
PUT /索引库名/_mapping/类型名称
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
}
- 类型名称:就是前面将的type的概念,类似于数据库中的不同表
字段名:任意填写 ,可以指定许多属性,例如: - type:类型,可以是text、long、short、date、integer、object等
- index:是否索引,默认为true
- store:是否存储,默认为false
- analyzer:分词器,这里的
ik_max_word即使用ik分词器
示例
发起请求:
PUT niceyoo2/_mapping/goods
{
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"images": {
"type": "keyword",
"index": "false"
},
"price": {
"type": "float"
}
}
}
响应结果:
{
"acknowledged": true
}
6.2、查看映射关系
语法:
GET /索引库名/_mapping
示例:
GET /niceyoo2/_mapping
响应:
{
"niceyoo2": {
"mappings": {
"goods": {
"properties": {
"images": {
"type": "keyword",
"index": false
},
"price": {
"type": "float"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
}
七、字段属性详解
7.1、type
Elasticsearch 中支持的数据类型非常丰富:
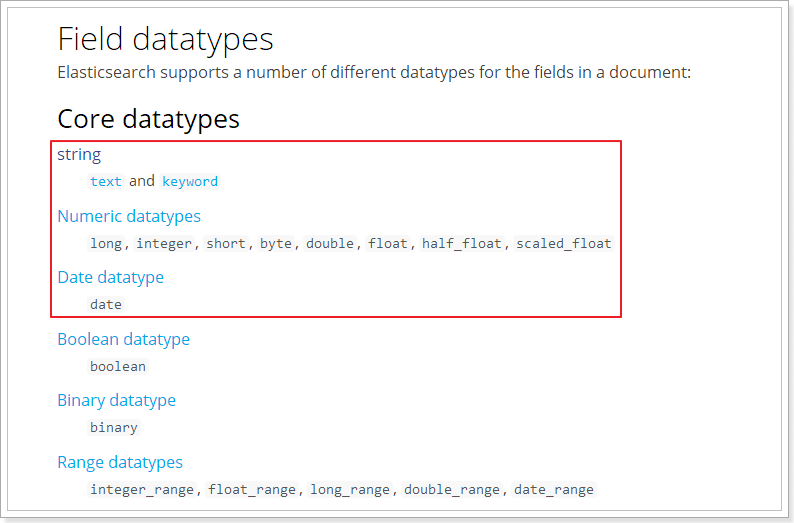
我们说几个关键的:
String类型,又分两种:
- text:可分词,不可参与聚合
- keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合
Numerical:数值类型,分两类:
- 基本数据类型:long、interger、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- 需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。
Date:日期类型
elasticsearch 可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为 long,节省空间。
7.2、index
index影响字段的索引情况。
- true:字段会被索引,则可以用来进行搜索。默认值就是true
- false:字段不会被索引,不能用来搜索
index的默认值就是true,也就是说你不进行任何配置,所有字段都会被索引。
但是有些字段是我们不希望被索引的,比如商品的图片信息,就需要手动设置index为false。
7.3、store
是否将数据进行额外存储。
在学习lucene和solr时,我们知道如果一个字段的store设置为false,那么在文档列表中就不会有这个字段的值,用户的搜索结果中不会显示出来。
但是在Elasticsearch中,即便store设置为false,也可以搜索到结果。
原因是Elasticsearch在创建文档索引时,会将文档中的原始数据备份,保存到一个叫做_source的属性中。而且我们可以通过过滤_source来选择哪些要显示,哪些不显示。
而如果设置store为true,就会在_source以外额外存储一份数据,多余,因此一般我们都会将store设置为false,事实上,store的默认值就是false。
7.4、boost
激励因子,这个与lucene中一样
其它的不再一一讲解,用的不多,大家参考官方文档:
最后
下篇带大家详细了解 elasticsearch 中的
- 增:随机id、自定义id
- 删:带条件删除
- 改:带条件修改
- 查:带条件查询
推荐阅读:
重温Elasticsearch:https://www.cnblogs.com/niceyoo/p/11329426.html
elasticsearch集群搭建-windows:https://www.cnblogs.com/niceyoo/p/11343697.html
基于Docker方式实现Elasticsearch集群:https://www.cnblogs.com/niceyoo/p/11342903.html
18年专科毕业后一度迷茫,创建了一个用来记录自己成长的公众号,感兴趣的小伙伴可以关注一下~

了解一下Elasticsearch的基本概念的更多相关文章
- elasticsearch的核心概念
1.elasticsearch的核心概念 (1)Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒):基于es执行搜索和分析可以达到秒级 (2) ...
- Elasticsearch系列---Elasticsearch的基本概念及工作原理
基本概念 Elasticsearch有几个核心的概念,花几分钟时间了解一下,有助于后面章节的学习. NRT Near Realtime,近实时,有两个层面的含义,一是从写入一条数据到这条数据可以被搜索 ...
- 写给大忙人的Elasticsearch架构与概念(未完待续)
最新版本官方文档https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html文档增删改参考https://www ...
- 图解Elasticsearch的核心概念
本文讲解大纲,分8个核心概念讲解说明: NRT Cluster Node Document&Field Index Type Shard Replica Near Realtime(NRT)近 ...
- ElasticSearch入门-基本概念介绍以及安装
Elasticsearch基本概念 Elasticsearch是基于Lucene的全文检索库,本质也是存储数据,很多概念与传统关系型数据库类似. 传统关系型数据库与Elasticsearch进行概念对 ...
- elasticsearch常用的概念整理
节点node 节点(node)是一个运行着的Elasticsearch实例 集群中一个节点会被选举为主节点(master),它将临时管理集群级别的一些变更,例如新建或删除索引.增加或移除节点等.主节点 ...
- elasticsearch中的概念简述
Near Realtime(NRT) Elasticsearch接近实时.从为一个文档建立索引到可被搜索,正常情况下有1秒延迟. Cluster 一个集群有一个唯一的名字,默认是"elast ...
- Elasticsearch的基本概念和指标
背景 在13年的时候,我开始负责整个公司的搜索引擎.嗯……,不是很牛的那种大项目负责人.而是整个搜索就我一个人做.哈哈. 后来跳槽之后,所经历的团队都用Elasticsearch,基本上和缓存一样,是 ...
- 【elasticsearch】关于elasticSearch的基础概念了解【转载】
转载原文:https://www.cnblogs.com/chenmc/p/9516100.html 该作者本系列文章,写的很详尽 ================================== ...
随机推荐
- python_操作linux上的mysql
在编写初期,遇见一个问题,发现怎么连接不上mysql,一直报错1045: 最后发现,只要下面的,连接写正确,不会出现这个问题, 只要你保证你的user.pwd是正确的, import pymysqld ...
- Oracle将小于1的数字to_char后,丢掉小数点前0的解决办法
使用to_char方法将小于0的数字转化为字符串时会出现小数点前0丢失的问题: 解决方案: 使用 oracle的tochar() 函数,并指定位数. --解决方案: 使用 oracle的tochar( ...
- 《JAVA高并发编程详解》-并发编程有三个至关重要的特性:原子性,有序性,可见性
- 阿里巴巴 Java 开发手册 (十二)安全规约
1. [强制]隶属于用户个人的页面或者功能必须进行权限控制校验. 说明:防止没有做水平权限校验就可随意访问.修改.删除别人的数据,比如查看他人的私信 内容.修改他人的订单. 2. [强制]用户敏感数据 ...
- JavaScript字符串转数值
JavaScript字符串转数值:方法主要有三种 转换函数.强制类型转换.利用js变量弱类型转换. 1. 转换函数 js提供了parseInt()和parseFloat()两个转换函数.前者把值转换成 ...
- aria2 https
https://github.com/aria2/aria2/issues/361 ... and also make sure that aria2 was built with HTTPS sup ...
- VUE基础回顾6
1.ref ref可以直接访问元素,而不需要使用querySelector或者其他dom节点的原生方法. <div ref = "box"></div> 在 ...
- JavaScript变量存储浅析(一)
Hello! 上一篇关于JS中函数传参(http://www.cnblogs.com/souvenir/p/4969092.html)的介绍中提到了JS的另外一个基本概念:JS变量存储, 今天我们就用 ...
- 如何查看服务器对外的IP
开发的时候经常会被IP受限,这是由于数据源方限制了IP,所以需要报备一下IP白名单,怎么查看自己的网络对外的IP呢? 用下面的方式最为准确: Windows上操作: 直接再浏览器访问 http://h ...
- 电脑 DNS纪要
电脑 DNS说明 1.电脑的DNS必须设置成114.114.114.114才能上网? 电脑的DNS不是必须设置成114.114.114.114才能上网,而只是DNS设置为这个地址刚好能够上网.设置合适 ...