数据分析 - Numpy
简介
Numpy是高性能科学计算和数据分析的基础包。它也是pandas等其他数据分析的工具的基础,基本所有数据分析的包都用过它。NumPy为Python带来了真正的多维数组功能,并且提供了丰富的函数库处理这些数组。它将常用的数学函数都支持向量化运算,使得这些数学函数能够直接对数组进行操作,将本来需要在Python级别进行的循环,放到C语言的运算中,明显地提高了程序的运算速度。
下载
>: pip install numpy
引用方式
import numpy as np # 约定俗成的起别名:np
这是官方认证的导入方式,可能会有人说为什么不用from numpy import *,是因为在numpy当中有一些方法与Python中自带的一些方法,例如max、min等冲突,为了避免这些麻烦大家就约定俗成的都使用这种方法。
ndarray
Numpy的核心特征就是N-维数组对——ndarray.
ndarray的优势
有一个购物车, 购物车中有商品的数量和对应的价格, 求总的价格
shop_car = [2,4,6,1]
shop_price = [10,20,1,30]
- pycharm中实现:
shop_car = [2,4,6,1]
shop_price = [10,20,1,30]
prices = 0
index = 0
for i in shop_car:
price = shop_price[index]
prices += i * price
index +=1
print(prices) #
- numpy中实现:
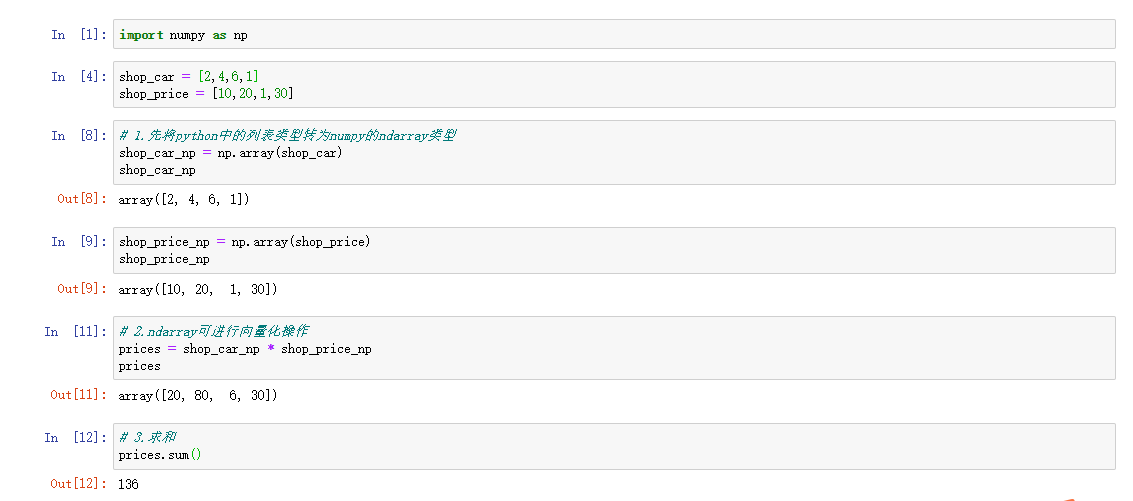
通过ndarray这个多维数组对象可以让这些批量计算变得更加简单,当然这只它其中一种优势,接下来就通过具体的操作来发现。
ndarray是一个多维数组列表

注意:
- 1.数组对象内的元素类型必须相同
- 2.数组大小不可修改
常用属性
| 属性 | 描述 | |
|---|---|---|
| T | 数组的转置(对高维数组而言) | |
| dtype | 数组元素的数据类型 | |
| size | 数组元素的个数 | |
| ndim | 数组的维数 | |
| shape | 数组的维度大小(以元组形式) |
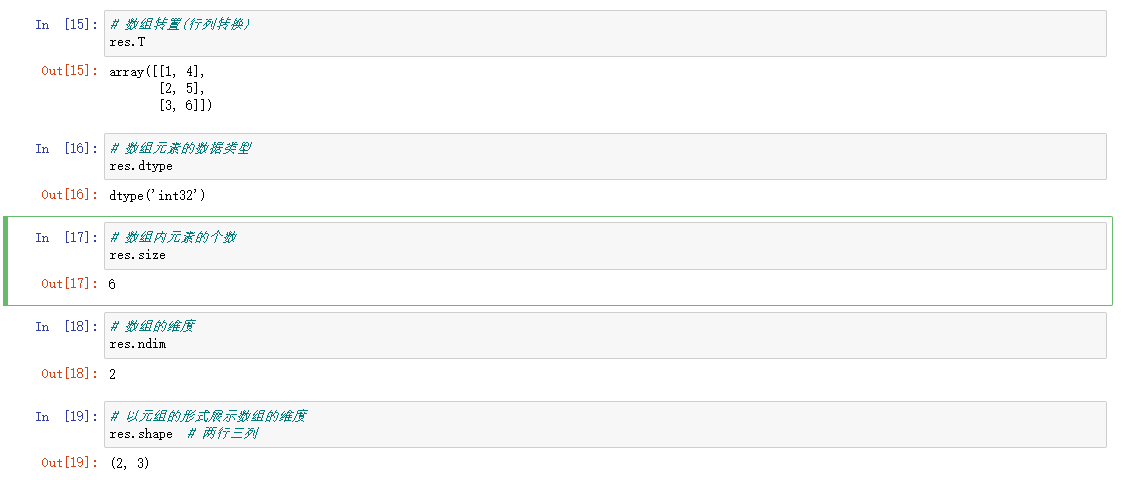
数据类型
| 类型 | 描述 | |
|---|---|---|
| 布尔型 | bool_ | |
| 整型 | int_ int8 int16 int32 int 64 | |
| 无符号整型 | uint8 uint16 uint32 uint64 | |
| 浮点型 | float_ float16 float32 float64 | |
| 复数型 | complex_ complex64 complex128 |

注意: astype()方法可以修改数组的数据类型
创建ndarray对象
| 方法 | 描述 | |
|---|---|---|
| array() | 将列表转换为数组,可选择显式指定dtype | |
| arange() | range的numpy版,支持浮点数 | |
| linspace() | 类似arange(),第三个参数为数组长度 | |
| zeros() | 根据指定形状和dtype创建全0数组 | |
| ones() | 根据指定形状和dtype创建全1数组 | |
| empty() | 根据指定形状和dtype创建空数组(随机值) | |
| eye() | 根据指定边长和dtype创建单位矩阵 |
array()

arange()

linspace()
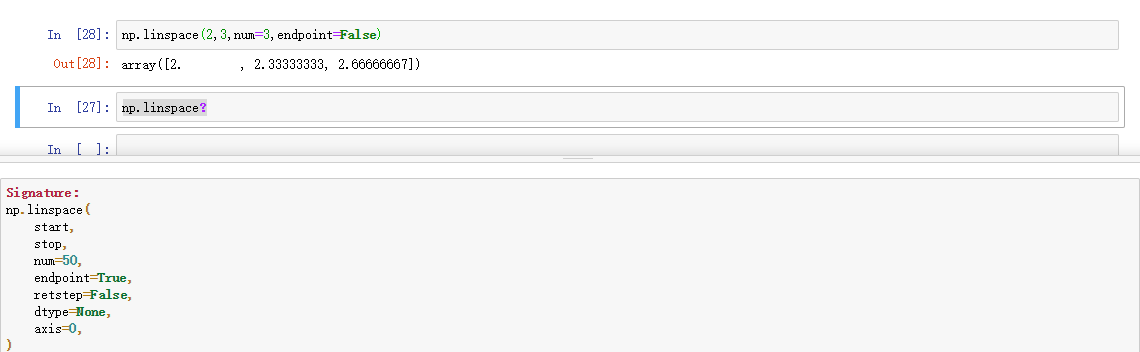
zeros()

ones()

eye()

reshape()

empty()

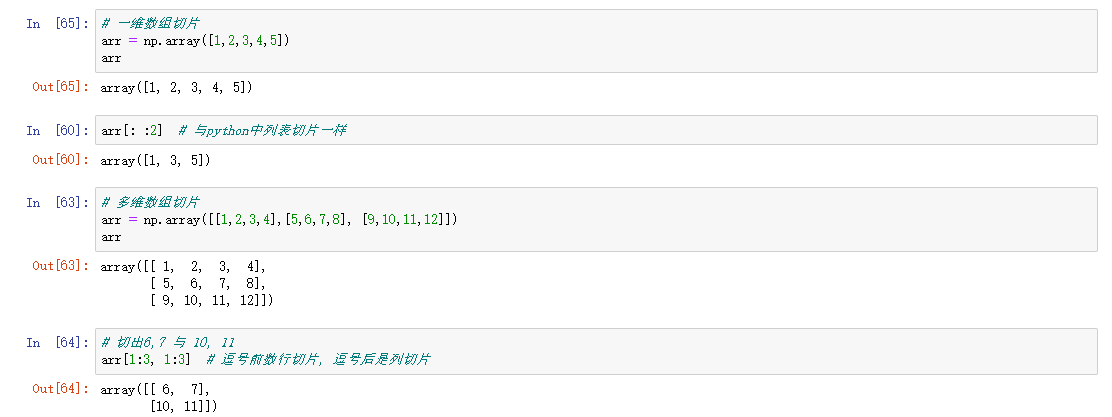
索引和切片
numpy数组索引与python中的索引用法一样
索引取值
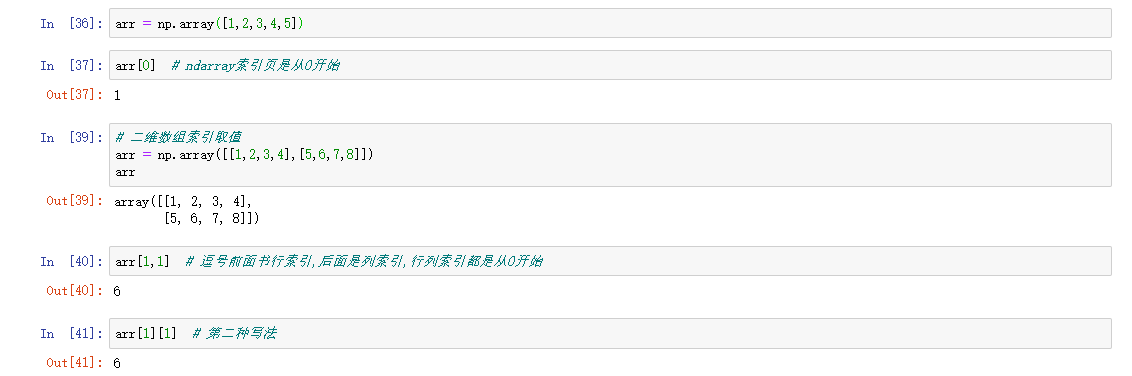
布尔索引
ndarray可以直接对判断数组中的元素进行判断,返回一个布尔值(True,False)组成的数组


花式索引 [ [ ] ]
花式索引括号内是被取值的索引下标

切片
通用函数
能对数组中所有元素同时进行运算的函数就是通用函数
能够接受一个数组的叫做一元函数,接受两个数组的叫二元函数,结果返回的也是一个数组
一元函数
| 函数 | 功能 | |
|---|---|---|
| abs、fabs | 分别是计算整数和浮点数的绝对值 | |
| sqrt | 计算各元素的平方根 | |
| square | 计算各元素的平方 | |
| exp | 计算各元素的指数e**x | |
| log | 计算自然对数 | |
| sign | 计算各元素的正负号 | |
| ceil | 向上取整 | |
| floor | 向下取整 | |
| rint | 计算各元素的值四舍五入到最接近的整数,保留dtype | |
| modf | 将数组的小数部分和整数部分以两个独立数组的形式返回,与Python的divmod方法类似 | |
| isnan | 判断是否是 NaN | |
| isinf | 表示那些元素是无穷的布尔型数组 | |
| cos,sin,tan | 普通型和双曲型三角函数 |
abs,fabs

sqrt,square

exp,log

ceil,floor

modf

isnan

二元函数
| 函数 | 功能 | |
|---|---|---|
| add | 将数组中对应的元素相加 | |
| subtract | 从第一个数组中减去第二个数组中的元素 | |
| multiply | 数组元素相乘 | |
| divide、floor_divide | 除法或向下圆整除法(舍弃余数) | |
| power | 对第一个数组中的元素A,根据第二个数组中的相应元素B计算A**B | |
| maximum,fmax | 计算最大值,fmax忽略NAN | |
| miximum,fmix | 计算最小值,fmin忽略NAN | |
| mod | 元素的求模计算(除法的余数) |
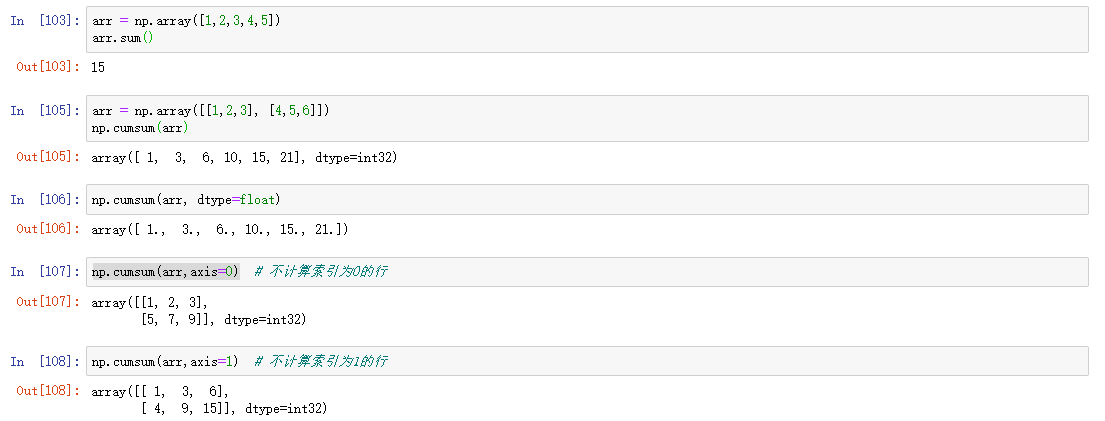
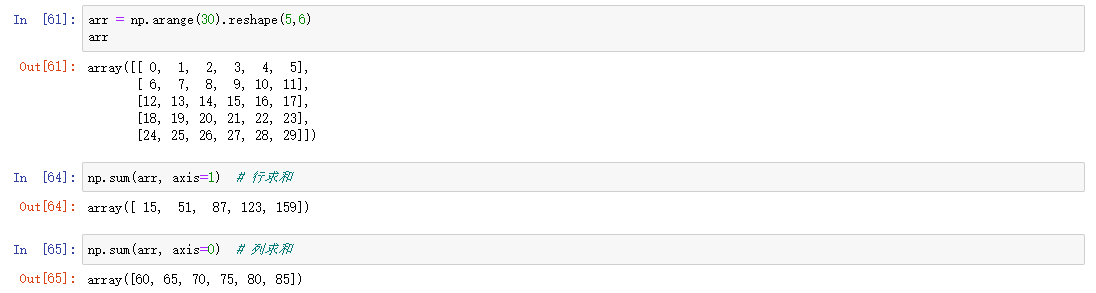
数学统计方法
| 函数 | 功能 | |
|---|---|---|
| sum | 求和 | |
| cumsum | 求前缀和 | |
| mean | 求平均数 | |
| std | 求标准差 | |
| var | 求方差 | |
| min | 求最小值 | |
| max | 求最大值 | |
| argmin | 求最小值索引 | |
| argmax | 求最大值索引 |
sum,cumsum
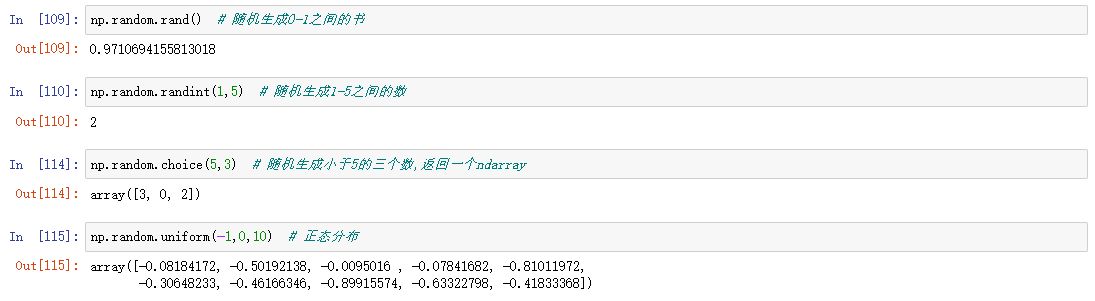
随机数
随机数生成函数在np.random的子包当中
| 函数 | 功能 | |
|---|---|---|
| rand | 给定形状产生随机数组(0到1之间的数) | |
| randint | 给定形状产生随机整数 | |
| chocie | 给定形状产生随机选择 | |
| shuffle | 与random.shuffle相同 | |
| uniform | 给定形状产生随机数组 |
补充 NaN:
1、nan(Not a Number):不等于任何浮点数(nan != nan)
---------------------------------------------
2、inf(infinity):比任何浮点数都大
---------------------------------------------- Numpy中创建特殊值:np.nan、np.inf
- 数据分析中,nan常被用作表示数据缺失值
数据分析 - Numpy的更多相关文章
- 利用Python进行数据分析——Numpy基础:数组和矢量计算
利用Python进行数据分析--Numpy基础:数组和矢量计算 ndarry,一个具有矢量运算和复杂广播能力快速节省空间的多维数组 对整组数据进行快速运算的标准数学函数,无需for-loop 用于读写 ...
- Python数据分析-Numpy数值计算
Numpy介绍: NumPy是高性能科学计算和数据分析的基础包.它是pandas等其他各种工具的基础. NumPy的主要功能: 1)ndarray,一个多维数组结构,高效且节省空间 2)无需循环对整组 ...
- Python数据分析numpy库
1.简介 Numpy库是进行数据分析的基础库,panda库就是基于Numpy库的,在计算多维数组与大型数组方面使用最广,还提供多个函数操作起来效率也高 2.Numpy库的安装 linux(Ubuntu ...
- 数据分析——numpy
DIKW DATA-->INFOMATION-->KNOWLEDGE-->WISDOM 数据-->信息-->知识-->智慧 爬虫-->数据库-->数据分 ...
- Python数据分析Numpy库方法简介(二)
数据分析图片保存:vg 1.保存图片:plt.savefig(path) 2.图片格式:jpg,png,svg(建议使用,不失真) 3.数据存储格式: excle,csv csv介绍 csv就是用逗号 ...
- python数据分析Numpy(二)
Numpy (Numerical Python) 高性能科学计算和数据分析的基础包: ndarray,多维数组(矩阵),具有矢量运算能力,快速.节省空间: 矩阵运算,无需循环,可以完成类似Matlab ...
- python 数据分析----numpy
NumPy是高性能科学计算和数据分析的基础包.它是pandas等其他各种工具的基础. NumPy的主要功能: ndarray,一个多维数组结构,高效且节省空间 无需循环对整组数据进行快速运算的数学函数 ...
- 数据分析--numpy的基本使用
一.numpy概述 NumPy是高性能科学计算和数据分析的基础包.它是pandas等其他各种工具的基础. NumPy的主要功能: ndarray,一个多维数组结构,高效且节省空间 无需循环对整组数据进 ...
- 数据分析-numpy的用法
一.jupyter notebook 两种安装和启动的方式: 第一种方式: 命令行安装:pip install jupyter 启动:cmd 中输入 jupyter notebook 缺点:必须手动去 ...
随机推荐
- LeetCode 1046. 最后一块石头的重量(1046. Last Stone Weight) 50
1046. 最后一块石头的重量 1046. Last Stone Weight 题目描述 每日一算法2019/6/22Day 50LeetCode1046. Last Stone Weight Jav ...
- 20 SSM三大框架的整合
1.SSM整合的相关概念 (1)整合说明:SSM整合可以使用多种方式,优先使用XML + 注解的方式(2)整合的思路 1.先搭建整合的环境 2.先把Spring的配置搭建完成 3.再使用Spring整 ...
- ubuntu查看软件安装位置
ubuntu中的软件可通过图形界面的软件中心安装,也可以通过命令行apt-get install安装.但是安装后的软件在哪个位置呢?这点跟windows环境下安装软件的路径选择不一样.ubuntu中可 ...
- 【leetcode】347. Top K Frequent Elements
题目地址:https://leetcode.com/problems/top-k-frequent-elements/ 从一个数组中求解出现次数最多的k个元素,本质是top k问题,用堆排序解决. 关 ...
- 4. Spark Streaming解析
4.1 初始化StreamingContext import org.apache.spark._ import org.apache.spark.streaming._ val conf = new ...
- Spring mvc请求处理流程详解(一)之视图解析
本文链接:https://blog.csdn.net/lchpersonal521/article/details/53112728 前言 Spring mvc框架相信很多人都很熟悉了,关于这方面 ...
- Spring-Cloud之Eureka注册与发现-2
一.Eureka是Netflix开发的服务发现框架,本身是一个基于REST的服务,主要用于定位运行在AWS域中的中间层服务,以达到负载均衡和中间层服务故障转移的目的.SpringCloud将它集成在其 ...
- c# 基于WebApi的快速开发框架FastFramework
一.框架简介 此框架是针对于webapi进行开发,项目分层是基于ABP框架的分层,更好的抽离业务逻辑关系,ABP是基于EF做数据访问层,本人个人比较喜欢Dapper,就把数据访问层封装成了Dapper ...
- 数组中[::-1]或[::-n]的区别,如三维数组[:,::-1,:]
import numpy as npa=np.array([[11,12,13,14,15,16,17,18],[21,22,23,24,25,26,27,28],[31,32,33,34,35,36 ...
- win 修改notebook路径
开始发现 notebook 默认的路径是 C:\Users\Administrator 需要修改 将目标中的%USERPROFILE% 直接删掉了