讲解Flume
4个demo看懂Flume
1、netcat数据展示到console
## 定义 sources、channels 以及 sinks
agent1.sources = netcatSrc
agent1.channels = me moryChannel
agent1.sinks = loggerSink ## netcatSrc 的配置
agent1.sources.netcatSrc.type = netcat
agent1.sources.netcatSrc.bind = localhost
agent1.sources.netcatSrc.port = 44445 ## loggerSink 的配置
agent1.sinks.loggerSink.type = logger ## memoryChannel 的配置
agent1.channels.memoryChannel.type = memory
agent1.channels.memoryChannel.capacity = 100 ## 通过 memoryChannel 连接 netcatSrc 和 loggerSink
agent1.sources.netcatSrc.channels = memoryChannel
agent1.sinks.loggerSink.channel = memoryChannel
2、netcat数据保存到HDFS,分别使用memory和file channal
## 定义 sources、channels 以及 sinks
agent1.sources = netcatSrc
agent1.channels = memoryChannel
agent1.sinks = hdfsSink ## netcatSrc 的配置
agent1.sources.netcatSrc.type = netcat
agent1.sources.netcatSrc.bind = localhost
agent1.sources.netcatSrc.port = 44445 ## hdfsSink 的配置
agent1.sinks.hdfsSink.type = hdfs
agent1.sinks.hdfsSink.hdfs.path = hdfs://master:9999/user/hadoop-twq/spark-course/steaming/flume/%y-%m-%d
agent1.sinks.hdfsSink.hdfs.batchSize = 5
agent1.sinks.hdfsSink.hdfs.useLocalTimeStamp = true ## memoryChannel 的配置
agent1.channels.memoryChannel.type = memory
agent1.channels.memoryChannel.capacity = 100 ## 通过 memoryChannel 连接 netcatSrc 和 hdfsSink
agent1.sources.netcatSrc.channels = memoryChannel
agent1.sinks.hdfsSink.channel = memoryChannel
3、日志文件数据保存到HDFS
## 定义 sources、channels 以及 sinks
agent1.sources = logSrc
agent1.channels = fileChannel
agent1.sinks = hdfsSink ## logSrc 的配置
agent1.sources.logSrc.type = exec
agent1.sources.logSrc.command = tail -F /home/hadoop-twq/spark-course/steaming/flume-course/demo3/logs/webserver.log ## hdfsSink 的配置
agent1.sinks.hdfsSink.type = hdfs
agent1.sinks.hdfsSink.hdfs.path = hdfs://master:9999/user/hadoop-twq/spark-course/steaming/flume/%y-%m-%d
agent1.sinks.hdfsSink.hdfs.batchSize = 5
agent1.sinks.hdfsSink.hdfs.useLocalTimeStamp = true ## fileChannel 的配置
agent1.channels.fileChannel.type = file
agent1.channels.fileChannel.checkpointDir = /home/hadoop-twq/spark-course/steaming/flume-course/demo2-2/checkpoint
agent1.channels.fileChannel.dataDirs = /home/hadoop-twq/spark-course/steaming/flume-course/demo2-2/data ## 通过 fileChannel 连接 logSrc 和 hdfsSink
agent1.sources.logSrc.channels = fileChannel
agent1.sinks.hdfsSink.channel = fileChannel
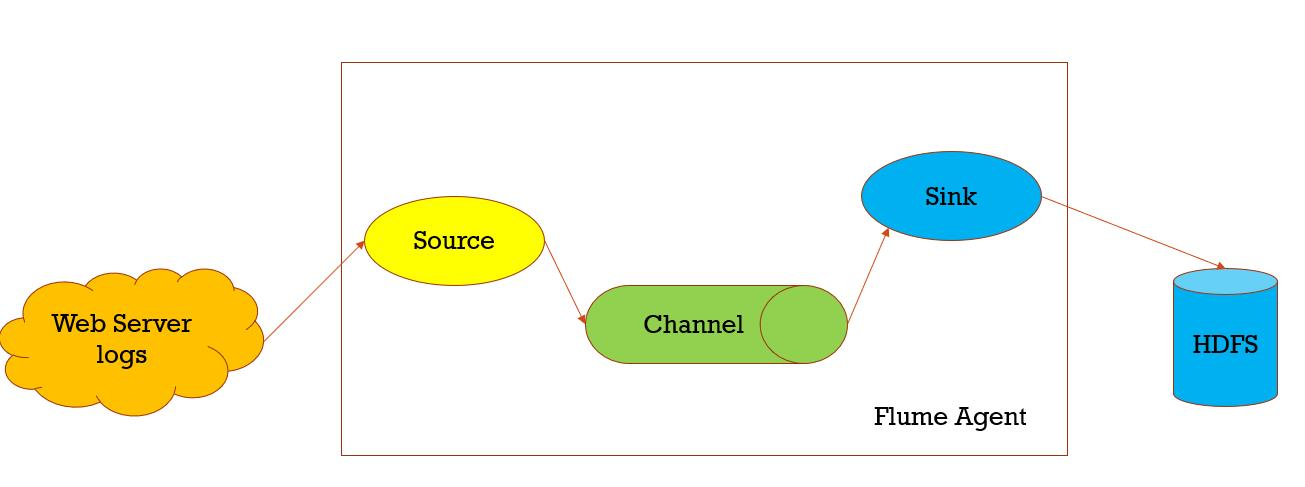
数据收集,从一个数据源经过channels,Sink到存储结构上,以event的方式发送

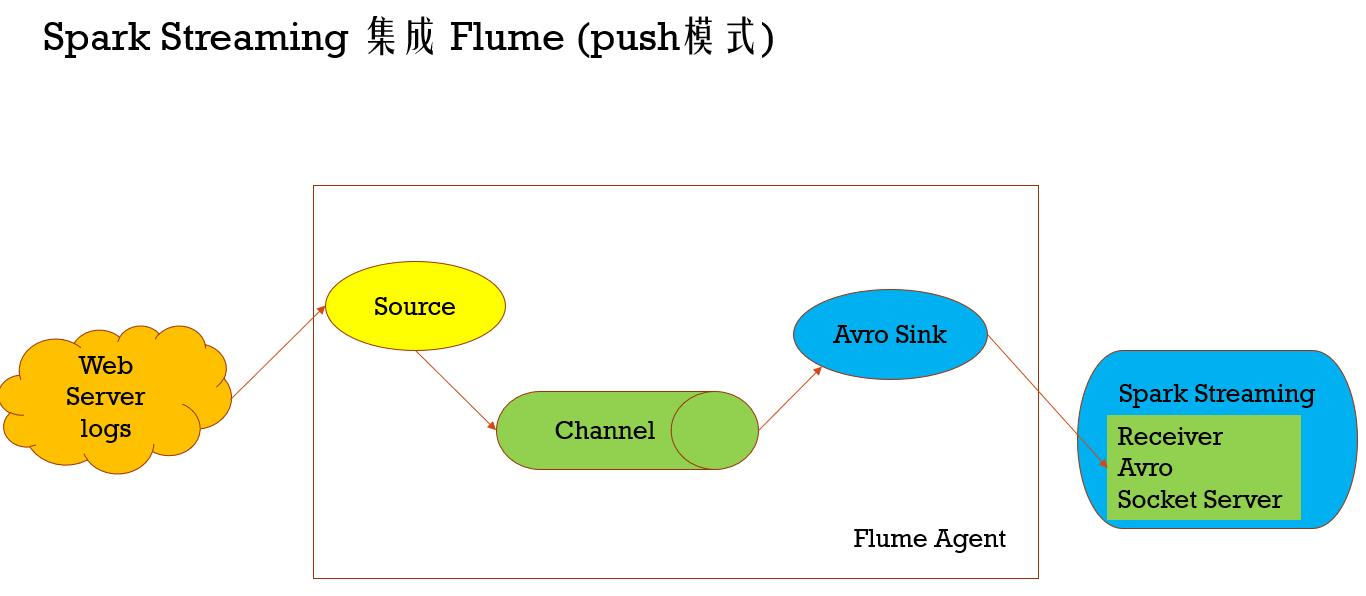
Spark Streaming 集成 Flume (push模式)
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming._
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.flume._
import org.apache.spark.util.IntParam /**
* Produces a count of events received from Flume.
*
* This should be used in conjunction with an AvroSink in Flume. It will start
* an Avro server on at the request host:port address and listen for requests.
* Your Flume AvroSink should be pointed to this address.
*
* Flume-style Push-based Approach(Spark Streaming作为一个agent存在)
*
* 1、在slave1(必须要有spark的worker进程在)上启动一个flume agent
* bin/flume-ng agent -n agent1 -c conf -f conf/flume-conf.properties
*
* 2、启动Spark Streaming应用
spark-submit --class com.twq.streaming.flume.FlumeEventCountPushBased \
--master spark://master:7077 \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--total-executor-cores 4 \
--executor-cores 2 \
/home/hadoop-twq/spark-course/streaming/spark-streaming-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar \
172.26.232.97 44446 3、在slave1上 telnet slave1 44445 发送消息
*/
object FlumeEventCountPushBased {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println(
"Usage: FlumeEventCount <host> <port>")
System.exit(1)
} val Array(host, port) = args val batchInterval = Milliseconds(2000) // Create the context and set the batch size
val sparkConf = new SparkConf().setAppName("FlumeEventCount")
val ssc = new StreamingContext(sparkConf, batchInterval) // Create a flume stream
val stream: DStream[SparkFlumeEvent] = FlumeUtils.createStream(ssc, host, port.toInt, StorageLevel.MEMORY_ONLY_SER_2) // Print out the count of events received from this server in each batch
stream.count().map(cnt => "Received " + cnt + " flume events." ).print() ssc.start()
ssc.awaitTermination()
}
}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.flume._
import org.apache.spark.util.IntParam /**
* Produces a count of events received from Flume.
*
* This should be used in conjunction with the Spark Sink running in a Flume agent. See
* the Spark Streaming programming guide for more details.
*
* Pull-based Approach using a Custom Sink(Spark Streaming作为一个Sink存在)
*
* 1、将jar包scala-library_2.11.8.jar(这里一定要注意flume的classpath下是否还有其他版本的scala,要是有的话,则删掉,用这个,一般会有,因为flume依赖kafka,kafka依赖scala)、
* commons-lang3-3.5.jar、spark-streaming-flume-sink_2.11-2.2.0.jar
* 放置在master上的/home/hadoop-twq/spark-course/streaming/spark-streaming-flume/apache-flume-1.8.0-bin/lib下
*
* 2、配置/home/hadoop-twq/spark-course/streaming/spark-streaming-flume/apache-flume-1.8.0-bin/conf/flume-conf.properties
*
* 3、启动flume的agent
* bin/flume-ng agent -n agent1 -c conf -f conf/flume-conf.properties
*
* 4、启动Spark Streaming应用
spark-submit --class com.twq.streaming.flume.FlumeEventCountPullBased \
--master spark://master:7077 \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--total-executor-cores 4 \
--executor-cores 2 \
/home/hadoop-twq/spark-course/streaming/spark-streaming-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar \
master 44446 3、在master上 telnet localhost 44445 发送消息 */
object FlumeEventCountPullBased {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println(
"Usage: FlumePollingEventCount <host> <port>")
System.exit(1)
} val Array(host, port) = args val batchInterval = Milliseconds(2000) // Create the context and set the batch size
val sparkConf = new SparkConf().setAppName("FlumePollingEventCount")
val ssc = new StreamingContext(sparkConf, batchInterval) // Create a flume stream that polls the Spark Sink running in a Flume agent
val stream = FlumeUtils.createPollingStream(ssc, host, port.toInt) // Print out the count of events received from this server in each batch
stream.count().map(cnt => "Received " + cnt + " flume events." ).print() ssc.start()
ssc.awaitTermination()
}
}
讲解Flume的更多相关文章
- 海量日志收集利器 —— Flume
Flume 是什么? Flume是一个分布式.可靠.和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- flume http source示例讲解
一.介绍 flume自带的Http Source可以通过Http Post接收事件. 场景:对于有些应用程序环境,它可能不能部署Flume SDK及其依赖项,或客户端代码倾向于通过HTTP而不是Flu ...
- Flume1 初识Flume和虚拟机搭建Flume环境
前言: 工作中需要同步日志到hdfs,以前是找运维用rsync做同步,现在一般是用flume同步数据到hdfs.以前为了工作简单看个flume的一些东西,今天下午有时间自己利用虚拟机搭建了 ...
- 高可用Hadoop平台-Flume NG实战图解篇
1.概述 今天补充一篇关于Flume的博客,前面在讲解高可用的Hadoop平台的时候遗漏了这篇,本篇博客为大家讲述以下内容: Flume NG简述 单点Flume NG搭建.运行 高可用Flume N ...
- 用通俗易懂的大白话讲解Map/Reduce原理
Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Reduce,分布式文件系统HDFS,以及分布式数据库Hbase,同时Hadoop的相关项目也很丰 ...
- Flume协作框架
1.概述 ->flume的三大功能 collecting, aggregating, and moving 收集 聚合 移动 2.框图 3.架构特点 ->on streaming data ...
- Flume NG之Interceptor简介
转载地址:http://www.cnblogs.com/lxf20061900/p/3658172.html 有的时候希望通过Flume将读取的文件再细分存储,比如讲source的数据按照业务类型分开 ...
- 基于Flume的美团日志收集系统(一)架构和设计
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
随机推荐
- Oracle RAC 创建实例出错(非+DATA目录)的简单处理
今天进行oracle的rac测试 发现开发同事没有写好 oracle rac的设置. 创建完之后就会报错了 因为自己对oracle 的RAC 不太熟悉 不太会用.. 所以用 一个比较简单的办法. a ...
- GitLabCICD
CI/CD是什么 CI全名Continuous Integration,啥意思?就是我们经常听到的持续集成概念.当开发每天会提交多次代码到主干上,会做一些重复性的动作时,就可以用持续集成环境来操作.有 ...
- MySQL高级 之 order by、group by 优化
参考: https://blog.csdn.net/wuseyukui/article/details/72627667 order by示例 示例数据: Case 1 Case 2 Case 3 ...
- spring的exception
Springmvc的对于异常类进行统一处理的方法 一.局部异常统一处理 当异常出现时,将抛给异常处理方法,异常处理发放接收到异常数据,进行处理,统一到异常页面 @ExceptionHandler:通过 ...
- LeetCode第154场周赛(Java)
估计要刷很久才能突破三道题了.还是刷的太少.尽管对了前两题,但是我觉得写的不怎么样.还是将所有题目都写一下吧. 5189. "气球" 的最大数量 题目比较简单.就是找出一个字符串中 ...
- chrome Network 过滤和高级过滤
转自:https://blog.csdn.net/tengdazhang770960436/article/details/90644523
- hystrix中request cache请求缓存
有一个概念,叫做reqeust context,请求上下文,一般来说,在一个web应用中, 我们会在一个filter里面,对每一个请求都施加一个请求上下文,就是说,tomcat容器内,每一次请求,就是 ...
- js的splice和delete
例如有一个数组是 :var textArr = ['a','b','c','d']; 这时我想删除这个数组中的b元素: 方法一:delete 删除数组 delete textArr[1] 结果为: ...
- 无法定位 Local Database Runtime 安装。请验证 SQL Server Express 是否正确安装以及本地数据库运行时功能是否已启用。
错误描述: 在与 SQL Server 建立连接时出现与网络相关的或特定于实例的错误.未找到或无法访问服务器.请验证实例名称是否正确并且 SQL Server 已配置为允许远程连接. (provide ...
- 用GraphicsMagick处理svg转png遇到的坑
1前言 用GraphicsMagick处理svg转png,且背景是透明且没有黑边,由于使用虚拟机的gm版本是1.3.28导致有黑边问题且svg中path中有opacity属性时,加上+antialia ...