HDFS文件读写流程
一、HDFS
HDFS全称是Hadoop Distributed System。HDFS是为以流的方式存取大文件而设计的。适用于几百MB,GB以及TB,并写一次读多次的场合。而对于低延时数据访问、大量小文件、同时写和任意的文件修改,则并不是十分适合。
目前HDFS支持的使用接口除了Java的还有,Thrift、C、FUSE、WebDAV、HTTP等。HDFS是以block-sized chunk组织其文件内容的,默认的block大小为64MB,对于不足64MB的文件,其会占用一个block,但实际上不用占用实际硬盘上的64MB,这可以说是HDFS是在文件系统之上架设的一个中间层。之所以将默认的block大小设置为64MB这么大,是因为block-sized对于文件定位很有帮助,同时大文件更使传输的时间远大于文件寻找的时间,这样可以最大化地减少文件定位的时间在整个文件获取总时间中的比例 。
二、HDFS的体系结构
构成HDFS主要是Namenode(master)和一系列的Datanode(workers)。Namenode是管理HDFS的目录树和相关的文件元数据,这些信息是以"namespace image"和"edit log"两个文件形式存放在本地磁盘,但是这些文件是在HDFS每次重启的时候重新构造出来的。Datanode则是存取文件实际内容的节点,Datanodes会定时地将block的列表汇报给Namenode。
由于Namenode是元数据存放的节点,如果Namenode挂了那么HDFS就没法正常运行,因此一般使用将元数据持久存储在本地或远程的机器上,或者使用secondary namenode来定期同步Namenode的元数据信息,secondary namenode有点类似于MySQL的Master/Salves中的Slave,"edit log"就类似"bin log"。如果Namenode出现了故障,一般会将原Namenode中持久化的元数据拷贝到secondary namenode中,使secondary namenode作为新的Namenode运行起来。
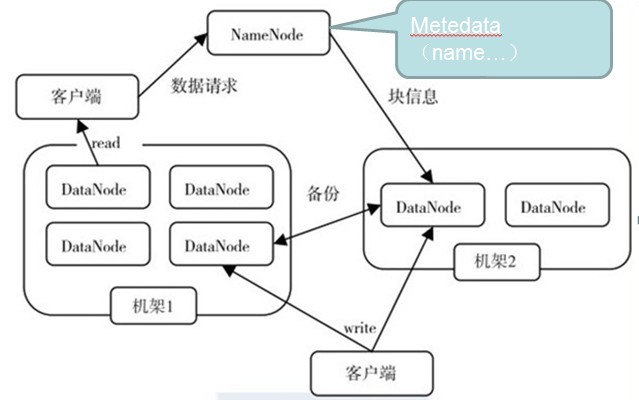
三、读写流程
GFS论文提到的文件读取简单流程:
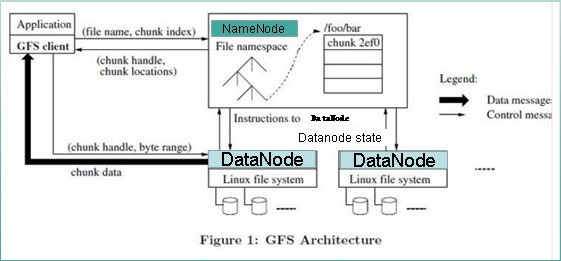
详细流程:
文件读取的过程如下:
- 使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求;
- Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namenode都会返回有该block拷贝的DataNode地址;
- 客户端开发库Client会选取离客户端最接近的DataNode来读取block;如果客户端本身就是DataNode,那么将从本地直接获取数据.
- 读取完当前block的数据后,关闭与当前的DataNode连接,并为读取下一个block寻找最佳的DataNode;
- 当读完列表的block后,且文件读取还没有结束,客户端开发库会继续向Namenode获取下一批的block列表。
- 读取完一个block都会进行checksum验证,如果读取datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷贝的datanode继续读。
GFS论文提到的写入文件简单流程:
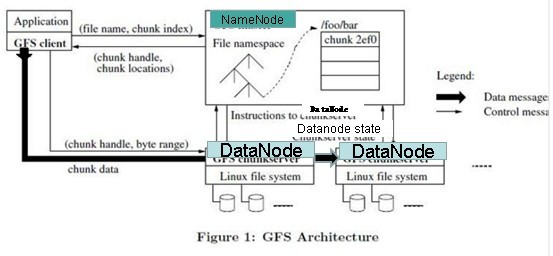
详细流程:
写入文件的过程比读取较为复杂:
- 使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求;
- Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录,否则会让客户端抛出异常;
- 当客户端开始写入文件的时候,开发库会将文件切分成多个packets,并在内部以数据队列"data queue"的形式管理这些packets,并向Namenode申请新的blocks,获取用来存储replicas的合适的datanodes列表,列表的大小根据在Namenode中对replication的设置而定。
- 开始以pipeline(管道)的形式将packet写入所有的replicas中。开发库把packet以流的方式写入第一个datanode,该datanode把该packet存储之后,再将其传递给在此pipeline中的下一个datanode,直到最后一个datanode,这种写数据的方式呈流水线的形式。
- 最后一个datanode成功存储之后会返回一个ack packet,在pipeline里传递至客户端,在客户端的开发库内部维护着"ack queue",成功收到datanode返回的ack packet后会从"ack queue"移除相应的packet。
- 如果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的pipeline中移除,剩余的block会继续剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的datanode,保持replicas设定的数量。
HDFS文件读写流程的更多相关文章
- 【Hadoop】二、HDFS文件读写流程
(二)HDFS数据流 作为一个文件系统,文件的读和写是最基本的需求,这一部分我们来了解客户端是如何与HDFS进行交互的,也就是客户端与HDFS,以及构成HDFS的两类节点(namenode和dat ...
- HDFS文件读写流程 (转)
文件读取的过程如下: 使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求: Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namen ...
- HDFS04 HDFS的读写流程
HDFS的读写流程(面试重点) 目录 HDFS的读写流程(面试重点) HDFS写数据流程 网络拓扑-节点距离计算 机架感知(副本存储节点的选择) HDFS的读数据流程 HDFS写数据流程 客服端把D: ...
- HDFS的读写流程——宏观与微观
HDFS的读写流程--宏观与微观 HDFS:分布式文件系统,负责存放数据 分布式文件系统:就是将我们的数据放到多台电脑上存储. 写数据:就是将客户端上的数据上传到HDFS 宏观过程 客户端向HDFS发 ...
- HDFS 文件读写过程
HDFS 文件读写过程 HDFS 文件读取剖析 客户端通过调用FileSystem对象的open()来读取希望打开的文件.对于HDFS来说,这个对象是分布式文件系统的一个实例. Distributed ...
- HDFS文件读写操作(基础基础超基础)
环境 OS: Ubuntu 16.04 64-Bit JDK: 1.7.0_80 64-Bit Hadoop: 2.6.5 原理 <权威指南>有两张图,下次po上来好好聊一下 实测 读操作 ...
- HDFS的读写流程
1.2. 客户端向NameNode发起创建文件的请求,在NameNode上创建一个文件名,并且返回一个输出流 3.客户端向输出流发起写入数据的请求 4.输出流向NameNode请求写数据,NameNo ...
- hadoop笔记-hdfs文件读写
概念 文件系统 磁盘进行读写的最小单位:数据块,文件系统构建于磁盘之上,文件系统的块大小是磁盘块的整数倍. 文件系统块一般为几千字节,磁盘块一般512字节. hdfs的block.pocket.chu ...
- Hadoop之HDFS文件读写过程
一.HDFS读过程 1.1 HDFS API 读文件 Configuration conf = new Configuration(); FileSystem fs = FileSystem.get( ...
随机推荐
- SGU 194 【带上下界的无源汇的可行流】
题意: 给点数n和边数m. 接下来m条有向边. a b c d 一次代表起点终点,下界上界. 求: 判断是否存在可行流,若存在则输出某可行流.否则输出IMPOSSIBLE 思路: <一种简易的方 ...
- poj 3080 Blue Jeans
点击打开链接 Blue Jeans Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 10243 Accepted: 434 ...
- (easy)LeetCode 217.Contains Duplicate
Given an array of integers, find if the array contains any duplicates. Your function should return t ...
- maven skip tests
DskipTests=true is short form of -Dmaven.test.skip=true
- 为什么要使用Spark?
现有的hadoop生态系统中存在的问题 1)使用mapreduce进行批量离线分析: 2)使用hive进行历史数据的分析: 3)使用hbase进行实时数据的查询: 4)使用storm进行实时的流处理: ...
- 欧拉路径Hrbust1351
http://acm.hrbust.edu.cn/index.php?m=ProblemSet&a=showProblem&problem_id=1351 这道题先利用并查集的知识点, ...
- [ CodeVS冲杯之路 ] P3955
不充钱,你怎么AC? 题目:http://codevs.cn/problem/3955/ 最长上升子序列的加强版,n 有1000000,n 方的 DP 肯定会 TLE,那么用二分栈维护 二分栈我讲不好 ...
- Solum入门知识(编辑中)
概要 参考:https://wiki.openstack.org/wiki/Solum An OpenStack project designed to make cloud services eas ...
- JS 随机数
function GetRandomNum(Min,Max){ var Range = Max - Min; var Rand = Math.random(); return(Min + Math.r ...
- iOS 平台开发OpenGL ES程序注意事项
本人最近从Android平台的OpenGL ES开发转到iOS平台的OpenGL ES开发,由于平台不同,所以开发中会有一些区别,再次列出需要注意的几点. 1.首先需要了解iOS主要开发框架,再次仅介 ...