图的遍历(搜索)算法(深度优先算法DFS和广度优先算法BFS)
深度优先遍历(DFS);
1、访问指定的起始顶点;
2、若当前访问的顶点的邻接顶点有未被访问的,则任选一个访问之;反之,退回到最近访问过的顶点;直到与起始顶点相通的全部顶点都访问完毕;
3、若此时图中尚有顶点未被访问,则再选其中一个顶点作为起始顶点并访问之,转 2; 反之,遍历结束。
连通图的深度优先遍历类似于树的先根遍历
如何判别V的邻接点是否被访问?
解决办法:为每个顶点设立一个“访问标志”。首先将图中每个顶点的访问标志设为 FALSE, 之后搜索图中每个顶点,如果未被访问,则以该顶点为起始点,进行深度
优先遍历,否则继续检查下一顶点。


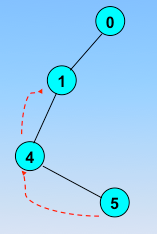
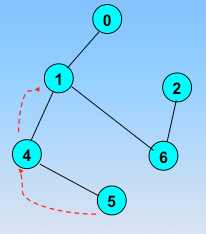

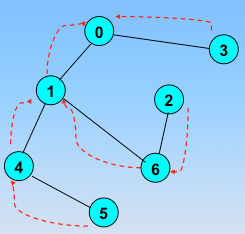
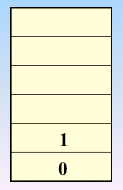
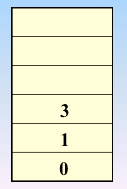
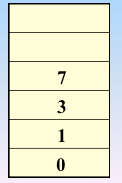
顶点的访问序列为: v0 , v1 , v4 , v5 , v6 , v2 , v3(不唯一)
实现过程:依靠栈,一维数组和图的邻接矩阵存储方式
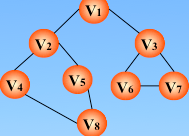






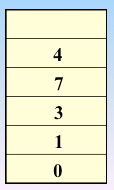


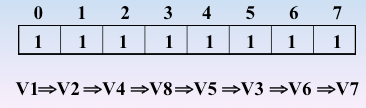

遍历图的过程实质上是对每个顶点查找其邻接点的过程,所耗费的时间取决于所采用的存储结构。
对图中的每个顶点至多调用1次DFS算法,因为一旦某个顶点已访问过,则不再从它出发进行搜索。
邻接链表表示:查找每个顶点的邻接点所需时间为O(e),e为边(弧)数,算法时间复杂度为O(n+e)
数组表示:查找每个顶点的邻接点所需时间为O(n2),n为顶点数,算法时间复杂度为O(n2)
代码如下
//访问标志数组
int visited[MAX] = {}; //用邻接表方式实现深度优先搜索(递归方式)
//v 传入的是第一个需要访问的顶点
void DFS(MGraph G, int v)
{
//图的顶点的搜索指针
ArcNode *p;
//置已访问标记
visited[v] = ;
//输出被访问顶点的编号
printf("%d ", v);
//p指向顶点v的第一条弧的弧头结点
p = G.vertices[v].firstarc;
while (p != NULL)
{
//若p->adjvex顶点未访问,递归访问它
if (visited[p->adjvex] == )
{
DFS(G, p->adjvex);
}
//p指向顶点v的下一条弧的弧头结点
p = p->nextarc;
}
}
广度优先搜索(BFS)
方法:从图的某一结点出发,首先依次访问该结点的所有邻接顶点 Vi1, Vi2, …, Vin 再按这些顶点被访问的先后次序依次访问与它们相邻接的所有未被访问的顶点,重复此过程,直至所有顶点均被访问为止。
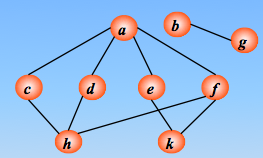
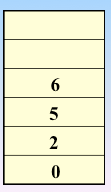
顶点的访问次序
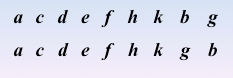
实现过程:依靠队列和一维数组来实现
#include <iostream>
#include<queue>
using namespace std; const int MAX = ;
//辅助队列的初始化,置空的辅助队列Q,类似二叉树的层序遍历过程
queue<int> q;
//访问标记数组
bool visited[MAX];
//图的广度优先搜索算法
void BFSTraverse(Graph G, void (*visit)(int v))
{
int v = ;
//初始化访问标记的数组
for (v = ; v < G.vexnum; v++)
{
visited[v] = false;
}
//依次遍历整个图的结点
for (v = ; v < G.vexnum; v++)
{
//如果v尚未访问,则访问 v
if (!visited[v])
{
//把 v 顶点对应的数组下标处的元素置为真,代表已经访问了
visited[v] = true;
//然后v入队列,利用了队列的先进先出的性质
q.push(v);
//访问 v,打印处理
cout << q.back() << " ";
//队不为空时
while (!q.empty())
{
//队头元素出队,并把这个出队的元素置为 u,类似层序遍历
Graph *u = q.front();
q.pop();
//w为u的邻接顶点
for (int w = FirstAdjVex(G, u); w >= ; w = NextAdjVex(G,u,w))
{
//w为u的尚未访问的邻接顶点
if (!visited[w])
{
visited[w] = true;
//然后 w 入队列,利用了队列的先进先出的性质
q.push(w);
//访问 w,打印处理
cout << q.back() << " ";
}//end of if
}//end of for
}//end of while
}//end of if
}// end of for
}
欢迎关注
dashuai的博客是终身学习践行者,大厂程序员,且专注于工作经验、学习笔记的分享和日常吐槽,包括但不限于互联网行业,附带分享一些PDF电子书,资料,帮忙内推,欢迎拍砖!

图的遍历(搜索)算法(深度优先算法DFS和广度优先算法BFS)的更多相关文章
- 图的 储存 深度优先(DFS)广度优先(BFS)遍历
图遍历的概念: 从图中某顶点出发访遍图中每个顶点,且每个顶点仅访问一次,此过程称为图的遍历(Traversing Graph).图的遍历算法是求解图的连通性问题.拓扑排序和求关键路径等算法的基础.图的 ...
- 洛谷 P3916 【图的遍历】反向加边+dfs
前言: 对于这类带环的图,一般记忆化搜索不能很好的对所有遍历的边进行更新取值.因为环上的点可以相互到达,所以他们的答案因当是同步更新的,而dfs一旦你回溯完环上某个点就不会在更新这个点的答案了,做不到 ...
- [ACM训练] 算法初级 之 搜索算法 之 广度优先算法BFS (POJ 3278+1426+3126+3087+3414)
BFS算法与树的层次遍历很像,具有明显的层次性,一般都是使用队列来实现的!!! 常用步骤: 1.设置访问标记int visited[N],要覆盖所有的可能访问数据个数,这里设置成int而不是bool, ...
- C++编程练习(9)----“图的存储结构以及图的遍历“(邻接矩阵、深度优先遍历、广度优先遍历)
图的存储结构 1)邻接矩阵 用两个数组来表示图,一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中边或弧的信息. 2)邻接表 3)十字链表 4)邻接多重表 5)边集数组 本文只用代码实现用 ...
- C# 遍历文件夹非递归实现(采用队列的广度优先算法)(转)
一.实现思路: 1. 创建一个队列(使用C# 队列类 Queue,需要使用命名空间 System.Collections.Generic): 2. 把起始文件夹名称排入队中: 3. 检查队列中是否有文 ...
- 图的深度优先搜索(DFS)和广度优先搜索(BFS)算法
深度优先(DFS) 深度优先遍历,从初始访问结点出发,我们知道初始访问结点可能有多个邻接结点,深度优先遍历的策略就是首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接 ...
- 图的存储,搜索,遍历,广度优先算法和深度优先算法,最小生成树-Java实现
1)用邻接矩阵方式进行图的存储.如果一个图有n个节点,则可以用n*n的二维数组来存储图中的各个节点关系. 对上面图中各个节点分别编号,ABCDEF分别设置为012345.那么AB AC AD 关系可以 ...
- 图的遍历算法:DFS、BFS
在图的基本算法中,最初需要接触的就是图的遍历算法,根据访问节点的顺序,可分为深度优先搜索(DFS)和广度优先搜索(BFS). DFS(深度优先搜索)算法 Depth-First-Search 深度优先 ...
- 算法学习笔记(六) 二叉树和图遍历—深搜 DFS 与广搜 BFS
图的深搜与广搜 复习下二叉树.图的深搜与广搜. 从图的遍历说起.图的遍历方法有两种:深度优先遍历(Depth First Search), 广度优先遍历(Breadth First Search),其 ...
随机推荐
- 微软Azure 经典模式下创建内部负载均衡(ILB)
微软Azure 经典模式下创建内部负载均衡(ILB) 使用之前一定要注意自己的Azure的模式,老版的为cloud service模式,新版为ARM模式(资源组模式) 本文适用于cloud servi ...
- C#多线程之线程同步篇2
在上一篇C#多线程之线程同步篇1中,我们主要学习了执行基本的原子操作.使用Mutex构造以及SemaphoreSlim构造,在这一篇中我们主要学习如何使用AutoResetEvent构造.Manual ...
- nodejs利用http模块实现银行卡所属银行查询和骚扰电话验证
http模块内部封装了http服务器和客户端,因此Node.js不需要借助Apache.IIS.Nginx.Tomcat等传统HTTP服务器,就可以构建http服务器,亦可以用来做一些爬虫.下面简单介 ...
- 从啥也不会到可以胜任最基本的JavaWeb工作,推荐给新人的学习路线(二)
在上一节中,主要阐述了JavaScript方面的学习路线.先列举一下我朋友的经历,他去过培训机构,说是4个月后月薪过万,虽然他现在还未达到这个指标. 培训机构一般的套路是这样:先教JavaSE,什么都 ...
- ObserverPattern(观察者模式)
import java.util.ArrayList; import java.util.List; /** * 观察者模式 * @author TMAC-J * 牵一发而动全身来形容观察者模式在合适 ...
- BPM配置故事之案例6-条件可见与条件必填
小明兴奋的告诉大毛自己独立解决了必填和水印问题,腹黑的大毛决定给小明出一个进阶问题刷一下存在感. 大毛:我再考考你,我把表单改成了这样(下图).怎么做到,预算状态为"预算内"时,不 ...
- ADFS3.0与SharePoint2013安装配置(原创)
现在越来越多的企业使用ADFS作为单点登录,我希望今天的内容能帮助大家了解如何配置ADFS和SharePoint 2013.安装配置SharePoint2013这块就不做具体描述了,今天主要讲一下怎么 ...
- Android 中的mvvm
我们来了解一下MVVM模式与Databinding ,MVVM是一种模式,Databinding 是一种框架.DataBinding是一个实现数据和UI绑定的框架.而ViewModel和View可以通 ...
- Create a bridge using a tagged vlan (8021.q) interface
SOLUTION VERIFIED April 27 2013 KB26727 Environment Red Hat Enterprise Linux 5 Red Hat Enterprise Li ...
- 让ASP.NET5在Jexus上飞呀飞
就在最近一段时间,“Visual Studio 2015 CTP 5”(以下简称CTP5)发布了,CTP5的发布不仅标志着新一代的VisualStudio正式发布又向前迈出了一步,还标志着距离ASP. ...