python爬虫实现原理
前言
简单来说互联网是由一个个站点和网络设备组成的大网,我们通过浏览器访问站点,站点把HTML、JS、CSS代码返回给浏览器,这些代码经过浏览器解析、渲染,将丰富多彩的网页呈现我们眼前;
一、爬虫是什么?
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,
沿着网络抓取自己的猎物(数据)爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序;
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用;
二、爬虫的基本流程
用户获取网络数据的方式:
方式1:浏览器提交请求--->下载网页代码--->解析成页面
方式2:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中
爬虫要做的就是方式2;
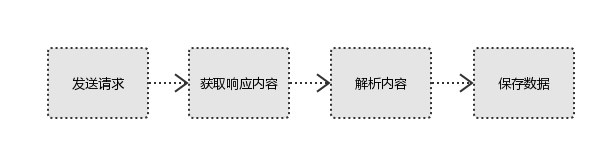
1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
数据库(MySQL,Mongdb、Redis)
文件
三、http协议 请求与响应
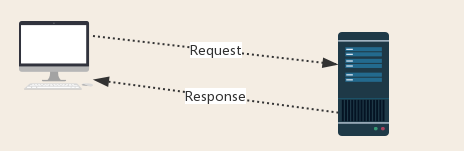
Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
ps:浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
四、 request
1、请求方式:
常见的请求方式:GET / POST
2、请求的URL
url全球统一资源定位符,用来定义互联网上一个唯一的资源 例如:一张图片、一个文件、一段视频都可以用url唯一确定
url编码
图片会被编码(看示例代码)
网页的加载过程是:
加载一个网页,通常都是先加载document文档,
在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
3、请求头
User-agent:请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户host;
cookies:cookie用来保存登录信息
注意: 一般做爬虫都会加上请求头
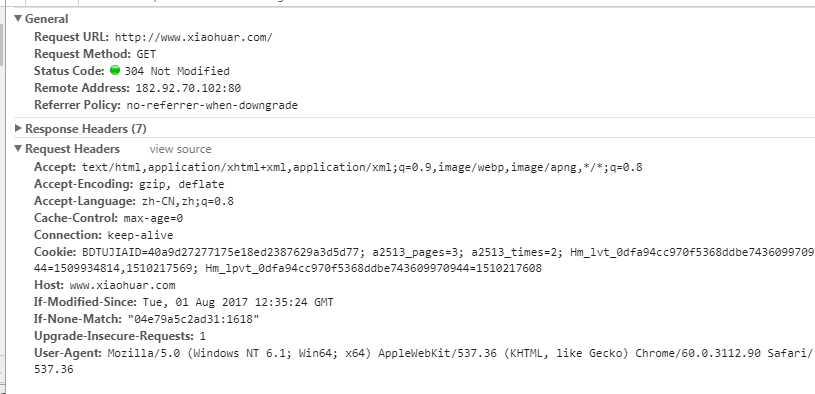
请求头需要注意的参数:
(1)Referrer:访问源至哪里来(一些大型网站,会通过Referrer 做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent:访问的浏览器(要加上否则会被当成爬虫程序)
(3)cookie:请求头注意携带
4、请求体
请求体
如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
五、 响应Response
1、响应状态码
200:代表成功
301:代表跳转
404:文件不存在
403:无权限访问
502:服务器错误
2、respone header
响应头需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/:可能有多个,是来告诉浏览器,把cookie保存下来
(2)Content-Location:服务端响应头中包含Location返回浏览器之后,浏览器就会重新访问另一个页面
3、preview就是网页源代码
JSON数据,如网页html,图片二进制数据等
六、总结
1、总结爬虫流程:
爬取--->解析--->存储
2、爬虫所需工具:
请求库:requests,selenium(可以驱动浏览器解析渲染CSS和JS,但有性能劣势(有用没用的网页都会加载);
解析库:正则,beautifulsoup,pyquery
存储库:文件,MySQL,Mongodb,Redis
python爬虫实现原理的更多相关文章
- Python爬虫的原理
简单来说互联网是由一个个站点和网络设备组成的大网,我们通过浏览器访问站点,站点把HTML.JS.CSS代码返回给浏览器,这些代码经过浏览器解析.渲染,将丰富多彩的网页呈现我们眼前: 一.爬虫是什么? ...
- Python爬虫总结
Python爬虫的原理:1通过URLopen()来获取到url页面, 这个过程可以加代理 2这个页面上都是字符串,所以我们而通过字符串查找的方法来获取到目标字符串,用到了正则来匹配目标re.finda ...
- python爬虫步骤 (新手备学 )爬虫编程。
Python爬虫是用Python编程语言实现的网络爬虫,主要用于网络数据的抓取和处理,相比于其他语言,Python是一门非常适合开发网络爬虫的编程语言,大量内置包,可以C Python爬虫可以做的事情 ...
- python爬虫(一)_爬虫原理和数据抓取
本篇将开始介绍Python原理,更多内容请参考:Python学习指南 为什么要做爬虫 著名的革命家.思想家.政治家.战略家.社会改革的主要领导人物马云曾经在2015年提到由IT转到DT,何谓DT,DT ...
- python爬虫之认识爬虫和爬虫原理
python爬虫之基础学习(一) 网络爬虫 网络爬虫也叫网络蜘蛛.网络机器人.如今属于数据的时代,信息采集变得尤为重要,可以想象单单依靠人力去采集,是一件无比艰辛和困难的事情.网络爬虫的产生就是代替人 ...
- 《Python爬虫技术:深入理解原理、技术与开发》已经出版,送Python基础视频课程
好消息,<Python爬虫技术:深入理解原理.技术与开发>已经出版!!! JetBrains官方推荐图书!JetBrains官大中华区市场部经理赵磊作序!送Python基础视频课程!J ...
- 开源磁力搜索爬虫dhtspider原理解析
开源地址:https://github.com/callmelanmao/dhtspider. 开源的dht爬虫已经有很多了,有php版本的,python版本的和nodejs版本.经过一些测试,发现还 ...
- [Python爬虫] Selenium实现自动登录163邮箱和Locating Elements介绍
前三篇文章介绍了安装过程和通过Selenium实现访问Firefox浏览器并自动搜索"Eastmount"关键字及截图的功能.而这篇文章主要简单介绍如何实现自动登录163邮箱,同时 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
随机推荐
- bootstrap基本布局
中文API bootstrap.cn HTML5文档 类型 移动设备优先 width 属性控制设备的宽度.设置为 device-width 确保它能正确呈现在不同设备上. initial-sc ...
- linux下mysql开启可访问
修改mysql配置连接信息 将bind-address注释 vim /etc/my.cnf 修改mysql用户授权 mysql>GRANT ALL PRIVILEGES ON *.* TO ' ...
- 修改vim注释字体颜色
vim /etc/vimrc#最后一行新增代码块hi comment ctermfg=6 注:注释用 " 标注 PS:默认的注释颜色是4 然后有0,1,2,3,4,5,6,7来选择.可以除 ...
- WordPress更改固定链接出现404
新浪SAE的前端采用的是nginx,nginx是不识别.htaccess的. 最后学习了新浪SAE官方教程——应用配置模块 – AppConfig终于把问题解决! 1.修改你SAE SDK站点目录下的 ...
- [小记]Android缓存问题
今天晚上,产品经理打电话说我们的Android App除了问题,问题很简单就是一个缓存问题,由于这个程序是前同事写的,我也只能呵呵一笑,有些事你就得扛.还是回到正题吧,这个缓存问题,实在有点奇葩,所以 ...
- PMP项目管理学习笔记(2)——组织、约束和干系人
(一)组织 这里所说的组织,就是我们所说的团队组织架构. 1.组织的类型 职能型: 在这种组织中,项目团队成员总是向职能经理报告,所有事务都有职能经理全权负责. 项目经理的决策需要与职能经理确认. 项 ...
- c#中out参数的作用
给你个简单的解释说法吧.虽然不完全对.但是我可以让你理解OUT有什么作用.呵呵 举个例子.每个方法只能有一个返回值.但是你想有多个返回值,呵呵.OUT就起作用了啊.比如分页,不光返回数据,还要返回总记 ...
- Matlab中size、numel、length、fix函数的使用
size():获取矩阵的行数和列数 (1)s=size(A), 当只有一个输出参数时,返回一个行向量,该行向量的第一个元素时矩阵的行数,第二个元素是矩阵的列数. (2)[r,c]=size ...
- java线程池 多线程搜索文件包含关键字所在的文件路径
文件读取和操作类 import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; publi ...
- spring的设计思想
在学习Spring框架的时候, 第一件事情就是分析Spring的设计思想 在学习Spring的时候, 需要先了解耦合和解耦的概念 耦合: 简单来说, 在软件工程当中, 耦合是指对象之间的相互依赖 耦合 ...