Kafka的3节点集群详细启动步骤(Zookeeper是外装)
首先,声明,kafka集群是搭建在hadoop1、hadoop2和hadoop3机器上。
kafka_2.10-0.8.1.1.tgz的1或3节点集群的下载、安装和配置(图文详细教程)绝对干货
如下分别是各自的配置信息。(网上说,还需要配置zookeeper.properties,其实不需要,因为,zookeeper集群那边已经配置好了。)

[hadoop@hadoop1 config]$ pwd
/home/hadoop/kafka/config
[hadoop@hadoop1 config]$ ll
total
-rw-r--r-- hadoop hadoop Sep consumer.properties
-rw-r--r-- hadoop hadoop Sep log4j.properties
-rw-r--r-- hadoop hadoop Sep producer.properties
-rw-r--r-- hadoop hadoop May : server.properties
-rw-r--r-- hadoop hadoop Sep test-log4j.properties
-rw-r--r-- hadoop hadoop Sep tools-log4j.properties
-rw-r--r-- hadoop hadoop Sep zookeeper.properties
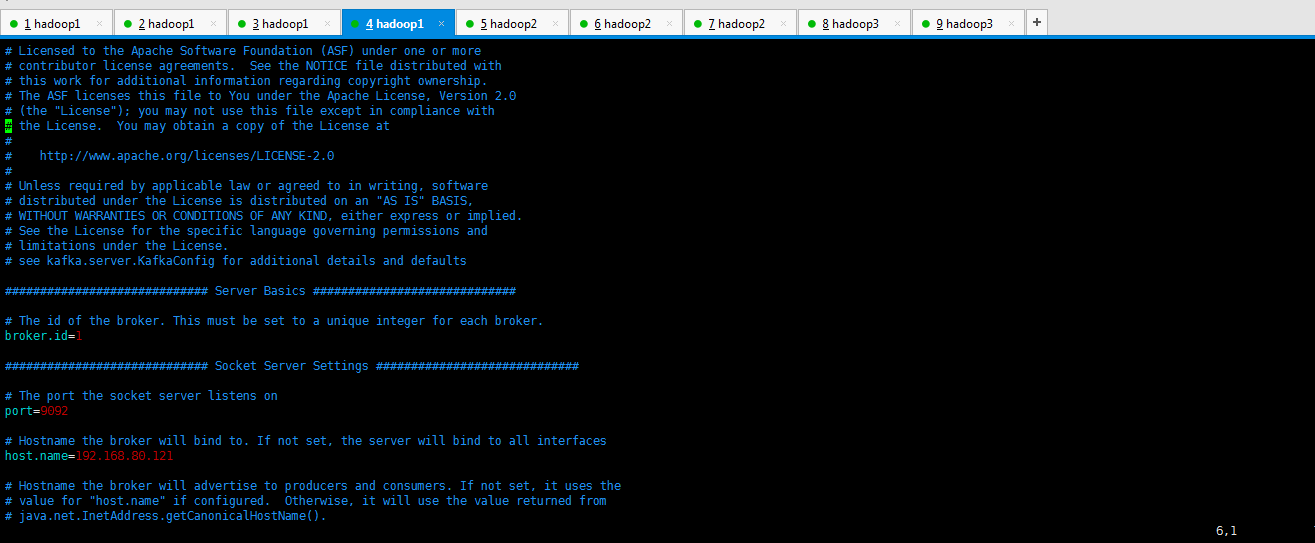
[hadoop@hadoop1 config]$ vim server.properties
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see kafka.server.KafkaConfig for additional details and defaults ############################# Server Basics ############################# # The id of the broker. This must be set to a unique integer for each broker.
broker.id= ############################# Socket Server Settings ############################# # The port the socket server listens on
port= # Hostname the broker will bind to. If not set, the server will bind to all interfaces
host.name=192.168.80.121 # Hostname the broker will advertise to producers and consumers. If not set, it uses the
# value for "host.name" if configured. Otherwise, it will use the value returned from
# java.net.InetAddress.getCanonicalHostName().
#advertised.host.name=<hostname routable by clients> # The port to publish to ZooKeeper for clients to use. If this is not set,
# it will publish the same port that the broker binds to.
#advertised.port=<port accessible by clients> # The number of threads handling network requests
num.network.threads= # The number of threads doing disk I/O
num.io.threads= # The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes= # The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes= # The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes= ############################# Log Basics ############################# # A comma seperated list of directories under which to store log files
log.dirs=/home/kafka-logs # The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions= # The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir= ############################# Log Flush Policy ############################# # Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# . Durability: Unflushed data may be lost if you are not using replication.
# . Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# . Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to exceessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis. # The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages= # The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms= ############################# Log Retention Policy ############################# # The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log. # The minimum age of a log file to be eligible for deletion
log.retention.hours= # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining
# segments don't drop below log.retention.bytes.
#log.retention.bytes= # The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes= # The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms= # By default the log cleaner is disabled and the log retention policy will default to just delete segments after their retention expires.
# If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction.
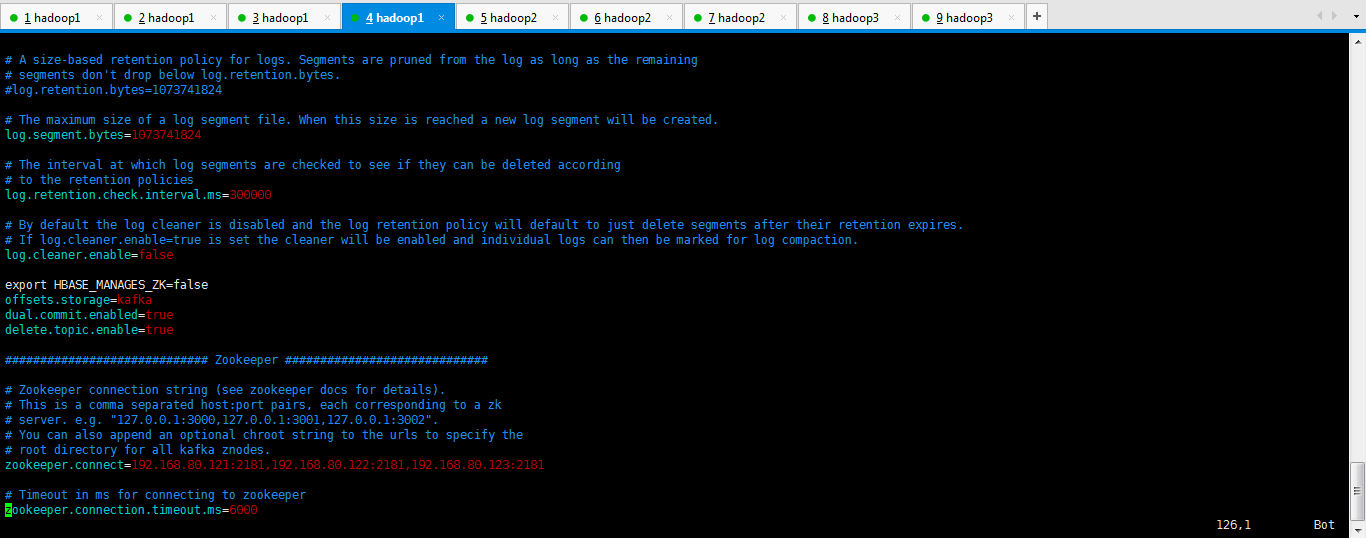
log.cleaner.enable=false export HBASE_MANAGES_ZK=false
offsets.storage=kafka
dual.commit.enabled=true
delete.topic.enable=true ############################# Zookeeper ############################# # Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=192.168.80.121:,192.168.80.122:,192.168.80.123: # Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=


# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see kafka.server.KafkaConfig for additional details and defaults ############################# Server Basics ############################# # The id of the broker. This must be set to a unique integer for each broker.
broker.id= ############################# Socket Server Settings ############################# # The port the socket server listens on
port= # Hostname the broker will bind to. If not set, the server will bind to all interfaces
host.name=192.168.80.122 # Hostname the broker will advertise to producers and consumers. If not set, it uses the
# value for "host.name" if configured. Otherwise, it will use the value returned from
# java.net.InetAddress.getCanonicalHostName().
#advertised.host.name=<hostname routable by clients> # The port to publish to ZooKeeper for clients to use. If this is not set,
# it will publish the same port that the broker binds to.
#advertised.port=<port accessible by clients> # The number of threads handling network requests
num.network.threads= # The number of threads doing disk I/O
num.io.threads= # The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes= # The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes= # The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes= ############################# Log Basics ############################# # A comma seperated list of directories under which to store log files
log.dirs=/home/kafka-logs # The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions= # The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir= ############################# Log Flush Policy ############################# # Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# . Durability: Unflushed data may be lost if you are not using replication.
# . Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# . Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to exceessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis. # The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages= # The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms= ############################# Log Retention Policy ############################# # The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log. # The minimum age of a log file to be eligible for deletion
log.retention.hours= # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining
# segments don't drop below log.retention.bytes.
#log.retention.bytes= # The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes= # The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms= # By default the log cleaner is disabled and the log retention policy will default to just delete segments after their retention expires.
# If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction.
log.cleaner.enable=false export HBASE_MANAGES_ZK=false
offsets.storage=kafka
dual.commit.enabled=true
delete.topic.enable=true ############################# Zookeeper ############################# # Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=192.168.80.121:,192.168.80.122:,192.168.80.123: # Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=

# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see kafka.server.KafkaConfig for additional details and defaults ############################# Server Basics ############################# # The id of the broker. This must be set to a unique integer for each broker.
broker.id= ############################# Socket Server Settings ############################# # The port the socket server listens on
port= # Hostname the broker will bind to. If not set, the server will bind to all interfaces
host.name=192.168.80.123 # Hostname the broker will advertise to producers and consumers. If not set, it uses the
# value for "host.name" if configured. Otherwise, it will use the value returned from
# java.net.InetAddress.getCanonicalHostName().
#advertised.host.name=<hostname routable by clients> # The port to publish to ZooKeeper for clients to use. If this is not set,
# it will publish the same port that the broker binds to.
#advertised.port=<port accessible by clients> # The number of threads handling network requests
num.network.threads= # The number of threads doing disk I/O
num.io.threads= # The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes= # The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes= # The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes= ############################# Log Basics ############################# # A comma seperated list of directories under which to store log files
log.dirs=/home/kafka-logs # The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions= # The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir= ############################# Log Flush Policy ############################# # Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# . Durability: Unflushed data may be lost if you are not using replication.
# . Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# . Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to exceessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis. # The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages= # The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms= ############################# Log Retention Policy ############################# # The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log. # The minimum age of a log file to be eligible for deletion
log.retention.hours= # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining
# segments don't drop below log.retention.bytes.
#log.retention.bytes= # The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes= # The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms= # By default the log cleaner is disabled and the log retention policy will default to just delete segments after their retention expires.
# If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction.
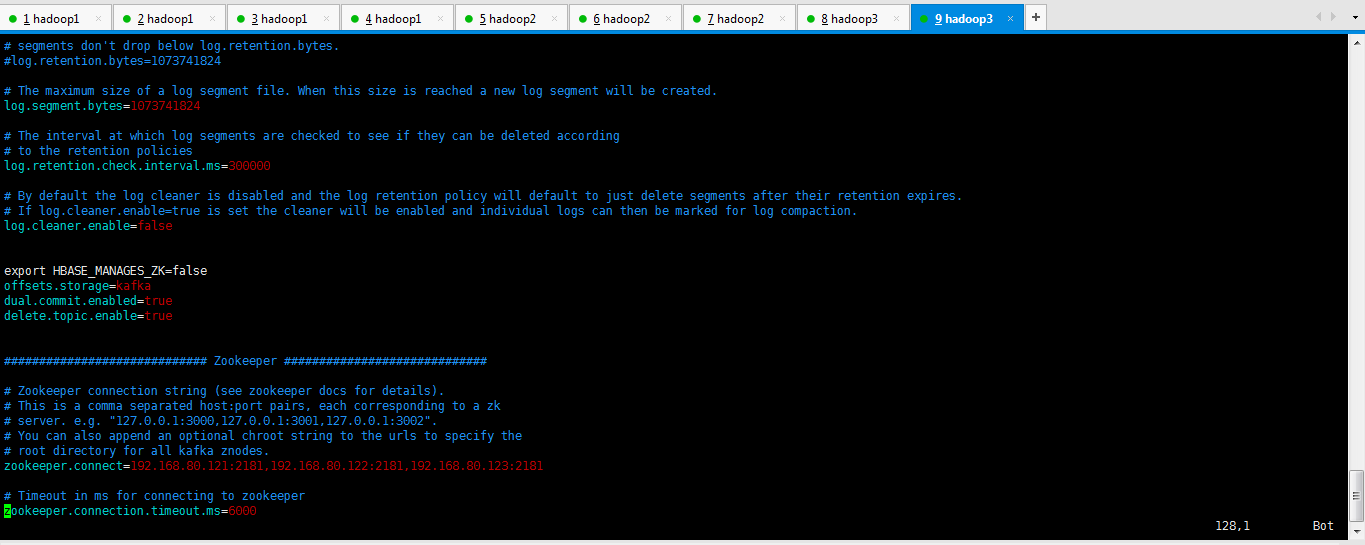
log.cleaner.enable=false export HBASE_MANAGES_ZK=false
offsets.storage=kafka
dual.commit.enabled=true
delete.topic.enable=true ############################# Zookeeper ############################# # Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=192.168.80.121:,192.168.80.122:,192.168.80.123: # Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=
Kafka的3节点集群详细启动步骤
第一步、首先启动kafka进程
[hadoop@hadoop1 kafka]$ nohup bin/kafka-server-start.sh config/server.properties > kafka.log >& &
[2] 4609
[hadoop@hadoop2 kafka]$ nohup bin/kafka-server-start.sh config/server.properties > kafka.log >& &
[2] 10077
[hadoop@hadoop3 kafka]$ nohup bin/kafka-server-start.sh config/server.properties > kafka.log >& &
[1] 8079
第二步、创建topics
[hadoop@hadoop1 bin]$ ./kafka-topics.sh --zookeeper hadoop1:,hadoop2:,hadoop3: --create --topic t-behavior --replication-factor --partitions
或者
[hadoop@hadoop1 bin]$ ./kafka-topics.sh --zookeeper hadoop1: --create --topic t-behavior --replication-factor --partitions
第三步:查看topic 和 topic详情
[hadoop@hadoop1 bin]$ ./kafka-topics.sh --zookeeper hadoop1:,hadoop2:,hadoop3: --list
t-behavior
[hadoop@hadoop1 bin]$ ./kafka-topics.sh --zookeeper hadoop1:,hadoop2:,hadoop3: --describe --topic t-behavior
或者
[hadoop@hadoop1 bin]$
./kafka-topics.sh --zookeeper hadoop1: --list
t-behavior
[hadoop@hadoop1 bin]$ ./kafka-topics.sh --zookeeper hadoop1: --describe --topic t-behavior
Topic:t-behavior PartitionCount:1 ReplicationFactor:3 Configs:
Topic: t-behavior Partition: 0 Leader: 3 Replicas: 3,2,1 Isr: 3,1,2
第四步:开启Kafka producer生产者(在hadoop1和hadoop2和hadoop3都可以)
模拟producer发送消息
用命令行的方式手动的往kafka的topic里面发送消息:
[hadoop@hadoop2 bin]$ ./kafka-console-producer.sh --broker-list hadoop1:,hadoop1:,hadoop1: --topic t-behavior
[2015-09-24 14:03:24,616] WARN Property topic is not valid (kafka.utils.VerifiableProperties)
This is Kafka producer.
Hello
或者
[hadoop@hadoop2 bin]$ ./kafka-console-producer.sh --broker-list hadoop1: --topic t-behavior
第五步:开启Kafka consumer消费者(在hadoop1和hadoop2和hadoop3都可以)
[hadoop@hadoop3 bin]$./kafka-console-consumer.sh --zookeeper hadoop1:,hadoop2:,hadoop3: --topic t-behavior --from-beginning
This is Kafka producer.
Hello
或者
[hadoop@hadoop3 bin]$./kafka-console-consumer.sh --zookeeper hadoop1: --topic t-behavior
第六步:停止kafka
cd $KAFKA_HOME/bin
./kafka-server-stop.sh
或者找到kafka的进程,直接kill掉即可。
彻底删除topic:
1、删除kafka存储目录(server.properties文件log.dirs配置,默认为"/tmp/kafka-logs")相关topic目录
2、如果配置了delete.topic.enable=true直接通过命令删除,如果命令删除不掉,直接通过zookeeper-client 删除掉broker下的topic即可。
[hadoop@hadoop1 bin]$ ./kafka-topics.sh --delete --zookeeper hadoop1:2181,hadoop2:2181,hadoop3:2181 --topic t-behavior
其实啊,现在越来越多的优秀插件出来了。
可以不需这么命令行去做了,直接界面化多么的好!
基于Web的Kafka管理器工具之Kafka-manager安装之后第一次进入web UI的初步配置(图文详解)
Kafka的3节点集群详细启动步骤(Zookeeper是外装)的更多相关文章
- HBase的多节点集群详细启动步骤(3或5节点)(分为Zookeeper自带还是外装)
HBase的多节点集群详细启动步骤(3或5节点)分为: 1.HBASE_MANAGES_ZK的默认值是false(zookeeper外装)(推荐) 2.HBASE_MANAGES_ZK的默认值是tru ...
- Hadoop的多节点集群详细启动步骤(3或5节点)
版本1 利用自己写的脚本来启动,见如下博客 hadoop-2.6.0-cdh5.4.5.tar.gz(CDH)的3节点集群搭建 hadoop-2.6.0.tar.gz的集群搭建(3节点) hadoop ...
- Zookeeper的多节点集群详细启动步骤(3或5节点)
分为 (1)分别去3或5节点上去启动Zookeeper进程 (2)自己写个脚本,直接在主节点上去启动Zookeeper进程. (1)分别去3或5节点上去启动Zookeeper进程 第一步: [hado ...
- storm的3节点集群详细启动步骤(非HA和HA)(图文详解)
前期博客 apache-storm-1.0.2.tar.gz的集群搭建(3节点)(图文详解)(非HA和HA) 启动storm集群(HA) 本博文情况是 master(主) nimbus slave1( ...
- HBase的单节点集群详细启动步骤(分为Zookeeper自带还是外装)
伪分布模式下,如(weekend110)hbase-env.sh配置文档中的HBASE_MANAGES_ZK的默认值是true,它表示HBase使用自身自带的Zookeeper实例.但是,该实例只能为 ...
- Hive的单节点集群详细启动步骤
说在前面的话, 在这里,推荐大家,一定要先去看这篇博客,如下 再谈hive-1.0.0与hive-1.2.1到JDBC编程忽略细节问题 Hadoop Hive概念学习系列之hive三种方式区别和搭建. ...
- Hadoop的单节点集群详细启动步骤
见,如下博客 hadoop-2.2.0.tar.gz的伪分布集群环境搭建(单节点) 很简单,不多赘述.
- Zookeeper的单节点集群详细启动步骤
这个很简单,见如下博客. 1 week110的zookeeper的安装 + zookeeper提供少量数据的存储 [hadoop@weekend110 zookeeper-3.4.6]$ pwd/ho ...
- Hyperledger Fabric 1.0 从零开始(九)——Fabric多节点集群生产启动
7:Fabric多节点集群生产启动 7.1.多节点服务器配置 在生产环境上,我们沿用4.1.配置说明中的服务器各节点配置方案. 我们申请了五台生产服务器,其中四台服务器运行peer节点,另外一台服务器 ...
随机推荐
- 08.C语言:特殊函数
C语言:特殊函数 1.递归函数: 与普通函数比较,执行过程不同,该函数内部调用它自己,它的执行必须要经过两个阶段:递推阶段,回归阶段: 当不满足回归条件,不再递推: #include <stdi ...
- Divide Groups 二分图的判定
Divide Groups Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Tot ...
- Spring AOP 学习(五)
1. 使用动态代理实现AOP package com.atguigu.spring.aop; import java.lang.reflect.InvocationHandler; import ja ...
- vim配置说明20170819
一.修改-/.vim/colors/guodesert.vim " Vim color file " Maintainer: Hans Fugal <hans@fugal.n ...
- IT领域的罗马帝国——微软公司
微软公司从做软件开始,起步很小.但是盖茨确是一直深耕于战略布局,像一个棋局高手,每一步棋都是看了后面几步. 盖茨居然用9年的时间憋出一个win3.0,成功击败了apple. 而这9年拖住apple的居 ...
- $inject的用法
controller后面的$inject是用来注入函数的变量名称的
- hihoCoder #27
A QvQ B 题目:http://hihocoder.com/problemset/problem/1470 分析:dfs序+栈+数学 可以发现,对于每组询问,树上是有很多点都只能等于0的 对于每个 ...
- Spring/Maven/MyBatis配置文件结合properties文件使用
使用properties文件也叫注入,比如把一些常用的配置项写入到这个文件,然后在Spring的XML配置文件中使用EL表达式去获取. 这种方式不只Spring可以使用,同样MyBatis也可以使用, ...
- ci output
ci output类可以将数据存起来,下面这个方法 a 代表的就是存起来的数据 public function(){ $data = array( 'name'=>'alice', ); $th ...
- python 元组不变 列表可变
python 元组不变 列表可变 1, --元组,注意要有逗号: [1] --列表 竟然才开始写python blog: