关于Lucene全文检索相关技术
Lucene技术专门解决海量数据下的模糊搜索问题。
Lucene主要完成的是数据预处理、建立倒排索引,及搜索、排名、高亮显示等功能
全文检索相关词语概要:
单词和文档矩阵:
文档(Document):就是索引库中的一条原始数据,比如一个网页,一件商品
文档编号(DocID):索引库存储文档时,会根据文档创建时间,进行编号,称为文档编号
单词(term):就是对原始数据中的文本进行分词,得到的每一个词条
文档列表:把原始数据,及其编号形成一个列表,称为文档列表

倒排索引列表:以单词及单词编号为索引,保存包含该单词的所有文档的文档编号,形成的列表。
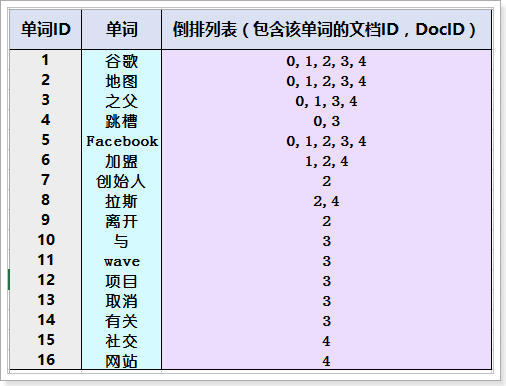
倒排索引的流程:
1. 创建索引的过程:
A:创建文档列表:给所有的文档形成编号,然后以编号为索引保存所有的文档数据
B:创建倒排索引列表:以所有的词条为索引,然后保存包含该词条的所有文档的编号信息。形成的列表
2. 搜索的过程:
当用户输入一个词条,我们会先去倒排索引列表快速定位到这个词条,然后就能知道包含该词条的所有文档的编号。然后就能快速根据编号找到文档
1、Lucene的概述
1.1、什么是Lucene?
1. Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供
2. Lucene提供了一个简单却强大的应用程序接口(API),能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开放源代码工具
3. Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品
1.2、什么是全文检索?

1.3、Lucene和Solr的关系
1. Lucene:一套实现了全文检索的底层API
2. Solr:基于Lucene开发的企业级搜索应用服务器
1.4、Lucene的基本使用
使用Lucene实现索引库的增(创建索引)、删(删除索引)、改(修改索引)、查(搜索数据)。
2.1、使用Lucene创建索引
2.1.1、添加依赖
<!-- Junit单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- lucene核心库 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>4.10.2</version>
</dependency>
<!-- Lucene的查询解析器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>4.10.2</version>
</dependency>
<!-- lucene的默认分词器库 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>4.10.2</version>
</dependency>
<!-- lucene的高亮显示 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>4.10.2</version>
</dependency> <build>
<plugins>
<!-- java编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
2.1.2、创建索引的流程分析
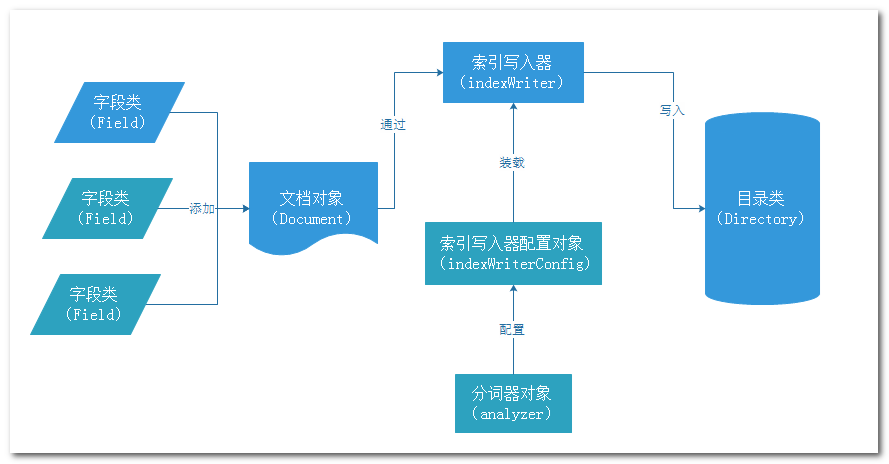
2.1.3、创建索引的代码实现
/**
* 创建索引
* @throws Exception
*/
@Test
public void testCreateIndex() throws Exception{
// 创建文档对象
Document document = new Document();
// 添加字段,这里字段的参数:字段的名称、字段的值、是否存储。Store.YES存储,Store.NO是不存储
document.add(new StringField("id", "1", Store.YES));
// StringField会创建索引,但是不做分词,而TextField会创建索引并且分词
document.add(new TextField("title", "谷歌地图之父跳槽FaceBook", Store.YES)); // 创建索引目录对象
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建分词器对象
Analyzer analyzer = new StandardAnalyzer();
// 创建索引写出工具的配置类
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, analyzer);
// 创建索引写出工具
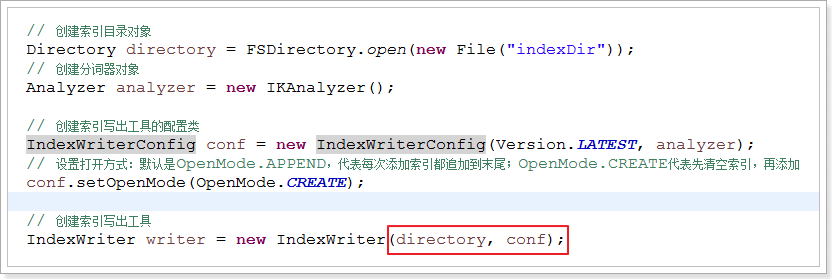
IndexWriter writer = new IndexWriter(directory, conf); // 添加文档到索引写出工具
writer.addDocument(document);
// 提交
writer.commit();
// 关闭
writer.close();
}
2.2、使用工具查看创建好的索引


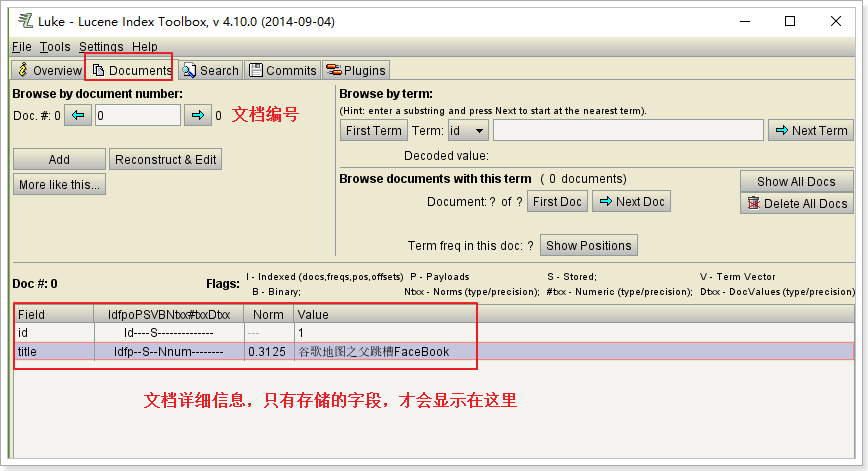
2.3、创建索引的核心API
2.3.1、Document(文档类)
Document:代表的是文档列表中的一条原始数据。
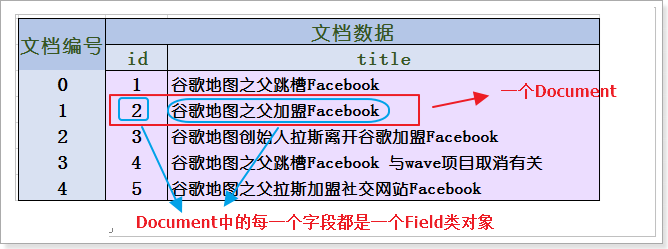
2.3.2、Field(字段类)
Field:一个文档中可以有很多的字段,每一个字段都是一个Field类的对象。Field类有很多的子类,这些子类有不同的特性,分别对应文档中具备不同特性的字段。
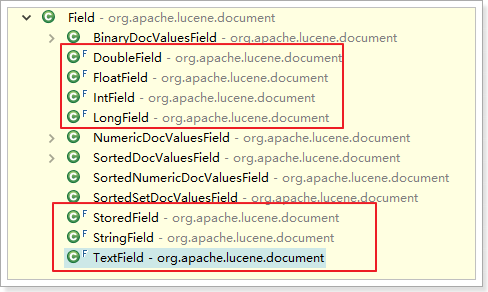
Field子类特点:
A:IntField、DoubleField、LongField、FloatField、StringField、TextField这几个子类他们一定会被创建索引。但是不一定会被存储。需要通过创建字段时的参数来指定:Stroe.YES代表存储,Store.NO代表不存储

B:StringField和TextField都会被创建索引,但是StringField不会被分词,而TextField会被分词

C:StoredField 一定会被存储,但是一定不会创建索引。

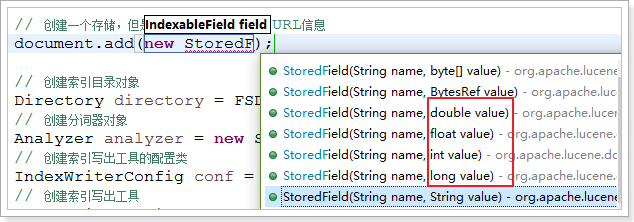
问题1:如何判断是否需要创建索引?
如果需要根据某个字段进行搜索,那么这个字段就必须创建索引。不能用StoreField
问题2:如何判断是否需要存储呢?
如果一个字段最终需要返回给用户看,那么就必须存储,如果不需要,你就不存储。
问题3:是否需要分词?
是否需要分词的前提,就是字段要先需要创建索引。
但是如果这个字段的内容是不可分割的整体,那么就不需要分词。比如:id
2.3.3、Directory(目录类)
Directory:代表的是索引库所在的目录
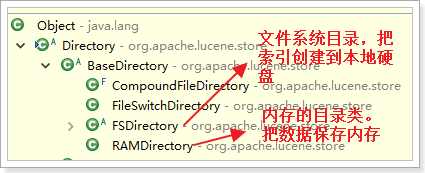
FSDirectory:把数据存储在硬盘,好处:数据比较安全。弊端:查询速度略慢
RAMDirectory:把数据存在内存:查询速度快,数据不安全

2.3.4、Analyzer(分词器类)
2.3.4.1、分词器的种类:
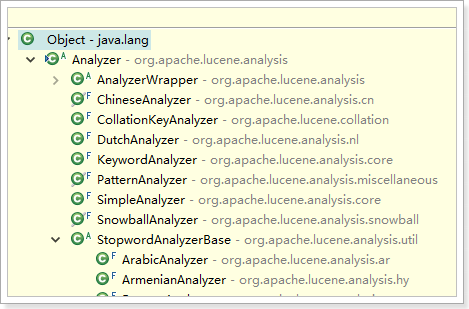
Analyzer有非常多的子类,支持大部分国家的语言,但是对中文的支持非常差。
所以,我们一旦要做中文分词,就要用中文分词器。
专业的中文分词器,有以下这些:
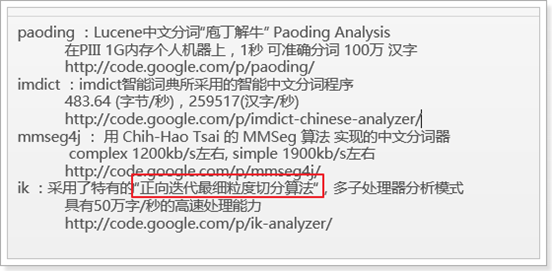
2.3.4.2、IKAnalyzer分词器使用:
IKAnalyzer(中文分词器)
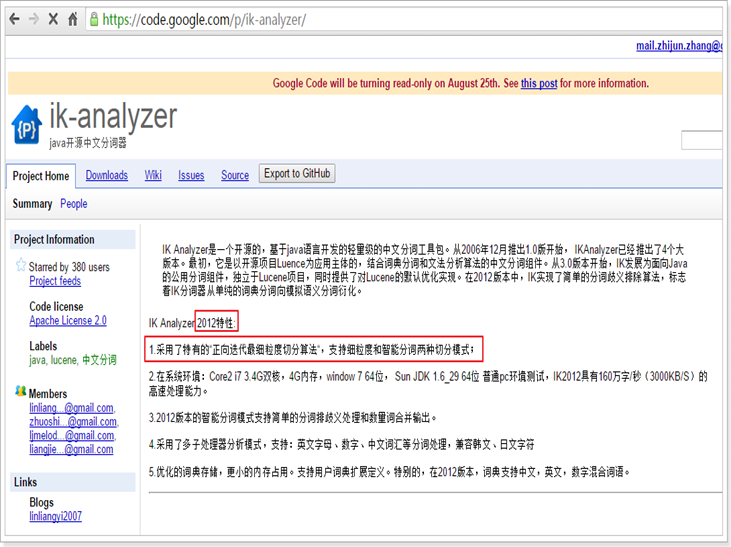
IK分词器官方版本是不支持Lucene4.X的,有人基于IK的源码做了改造,支持了Lucene4.X
2.3.4.3、IKAnalyzer的使用
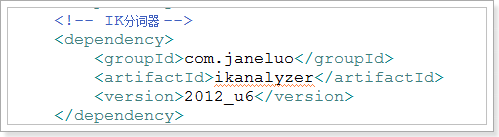
添加依赖

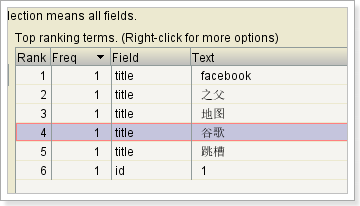
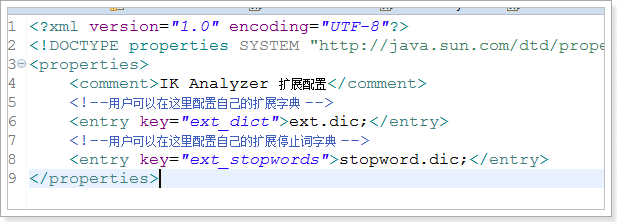
一些后来出现的新词,在IK分词器中,是没有的。因此IK分词器提供了扩展词库和停止词库
扩展词库:我们自己指定一些自定义的词条。
停止词库:某些不需要做分词的内容。啊、哦、的、额


2.3.4.4、IndexWriterConfig(写出配置类)
IndexWriterConfig:用来设置写出工具的配置信息。在构造函数中,指定版本号和分词器对象

设置创建索引时是追加还是覆盖:

2.3.4.5、IndexWriter(索引写出类)
1)一次创建一个索引
IndexWriter的作用:就是实现对索引库的更新操作:增(创建索引)、删(删除索引)、改(修改索引)
2)一次创建多个索引
/**
* 批量创建索引
* @throws Exception
*/
@Test
public void testCreateIndexes() throws Exception{
// 创建文档的集合
Collection<Document> docs = new ArrayList<>();
// 创建文档对象
Document document1 = new Document();
document1.add(new StringField("id", "1", Store.YES));
document1.add(new TextField("title", "谷歌地图之父跳槽FaceBook", Store.YES));
docs.add(document1);
Document document2 = new Document();
document2.add(new StringField("id", "2", Store.YES));
document2.add(new TextField("title", "谷歌地图之父加盟FaceBook", Store.YES));
docs.add(document2);
Document document3 = new Document();
document3.add(new StringField("id", "3", Store.YES));
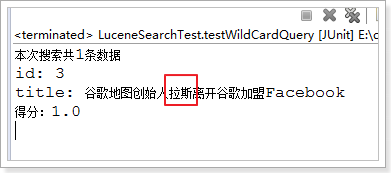
document3.add(new TextField("title", "谷歌地图创始人拉斯离开谷歌加盟Facebook", Store.YES));
docs.add(document3);
Document document4 = new Document();
document4.add(new StringField("id", "4", Store.YES));
document4.add(new TextField("title", "谷歌地图之父跳槽Facebook与Wave项目取消有关", Store.YES));
docs.add(document4);
Document document5 = new Document();
document5.add(new StringField("id", "5", Store.YES));
document5.add(new TextField("title", "谷歌地图之父跳槽Facebook与Wave项目取消有关", Store.YES));
docs.add(document5); // 创建索引目录对象
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建分词器对象
Analyzer analyzer = new IKAnalyzer(); // 创建索引写出工具的配置类
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, analyzer);
// 设置打开方式:默认是OpenMode.APPEND,代表每次添加索引都追加到末尾;OpenMode.CREATE代表先清空索引,再添加
conf.setOpenMode(OpenMode.CREATE);
// 创建索引写出工具
IndexWriter writer = new IndexWriter(directory, conf); // 添加文档集合 到索引写出工具
writer.addDocuments(docs);
// 提交
writer.commit();
// 关闭
writer.close();
}
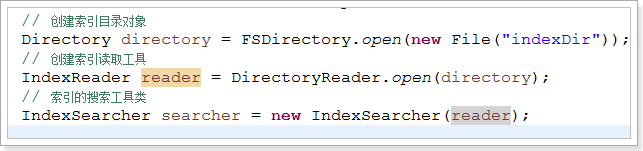
2.4、使用Lucene搜索索引库数据
@Test
public void testSearch() throws Exception{
// 创建索引目录对象
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引的搜索工具类
IndexSearcher searcher = new IndexSearcher(reader); // 创建查询解析器对象。参数:默认查询的字段名称,分词器对象
QueryParser parser = new QueryParser("title", new IKAnalyzer());
// 创建查询对象
Query query = parser.parse("跳槽");
// 执行Query对象,搜索数据。参数:查询对象Query,查询结果的前N条数据
// 返回的是:相关度最高的前N名的文档信息(包含文档的编号以及查询到的总数量)
TopDocs topDocs = searcher.search(query, 10); System.out.println("本次共搜索到"+topDocs.totalHits+"条数据");
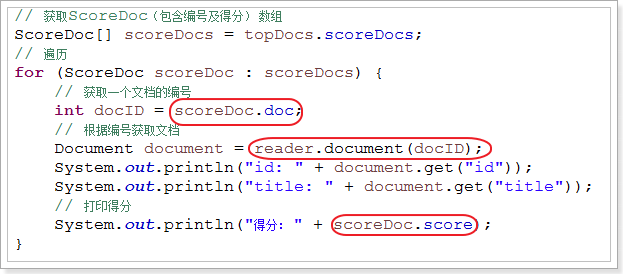
// 获取ScoreDoc(包含编号及得分) 数组
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
// 遍历
for (ScoreDoc scoreDoc : scoreDocs) {
// 获取一个文档的编号
int docID = scoreDoc.doc;
// 根据编号获取文档
Document document = reader.document(docID);
System.out.println("id: " + document.get("id"));
System.out.println("title: " + document.get("title"));
// 打印得分
System.out.println("得分: " + scoreDoc.score);
}
}
2.5、搜索索引库的核心API
2.5.1、QueryParser(查询解析器)
QueryParser:可以解析用户输入的字段,获取查询对象(单一字段的查询解析器)

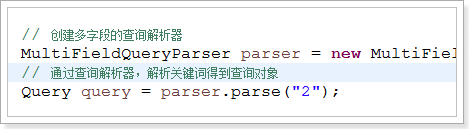
MultiFieldQueryParser(多字段组合查询解析器)

2.5.2、Query(查询类)
1)解析关键词,获取查询对象
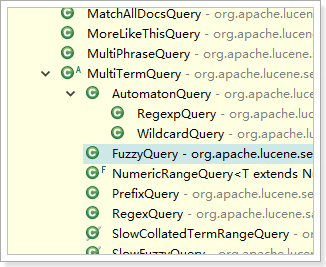
2)通过Query子类创建特殊查询对象
2.5.3、IndexSearch(索引搜索类)
IndexSearch:可以帮我们实现 搜索索引库,获取数据。还可以实现很多高级搜索功能

2.5.4、TopDocs(搜索结果的信息集合)
TopDocs:相关度最高的前N名的文档信息,N可以通过搜索时的参数指定
这个文档信息包含两部分:
int totalHits:查询到的总数量
ScoreDoc[] scoreDocs:ScoreDoc的数组,ScoreDoc里就有文档的编号

2.5.5、ScoreDoc(搜索到的某个文档信息)
ScoreDoc:包含了文档的编号和得分信息
int doc:文档的编号,我们还需要根据文档编号获取具体的文档
int score:文档的得分
2.6、抽取公共的搜索方法
// 公共的搜索方法。
public void search(Query query) throws Exception {
// 创建索引目录对象、
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 创建搜索工具
IndexSearcher searcher = new IndexSearcher(reader); // 执行查询,获取前N名的 文档信息
TopDocs topDocs = searcher.search(query, 10); // 获取总条数
int totalHits = topDocs.totalHits;
System.out.println("本次搜索共" + totalHits + "条数据"); // 获取ScoreDoc(文档的得分及编号)的数组
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 获取编号
int docID = scoreDoc.doc;
// 根据编号找文档
Document document = reader.document(docID);
System.out.println("id: " + document.get("id"));
System.out.println("title: " + document.get("title"));
// 获取得分
System.out.println("得分:" + scoreDoc.score);
}
}
2.7、特殊查询
2.7.1、TermQuery(词条查询)

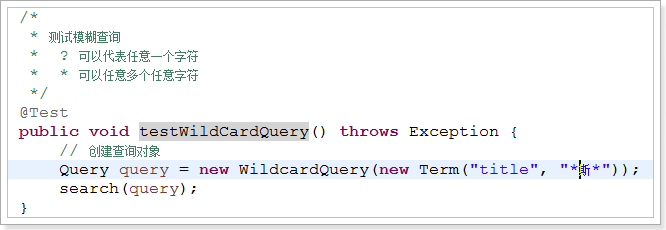
2.7.2、WildcardQuery(模糊查询)
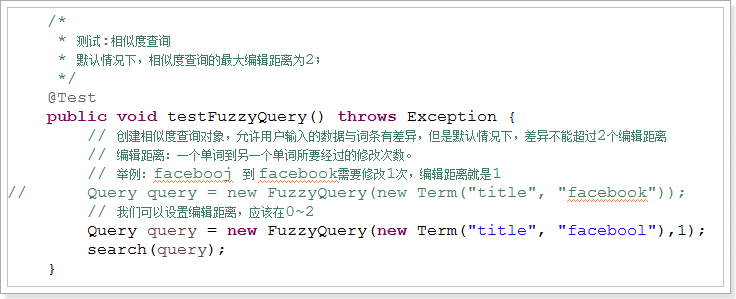
2.7.3、FuzzyQuery(相似度查询)
2.7.4、NumericRangeQuery(数字边界查询)

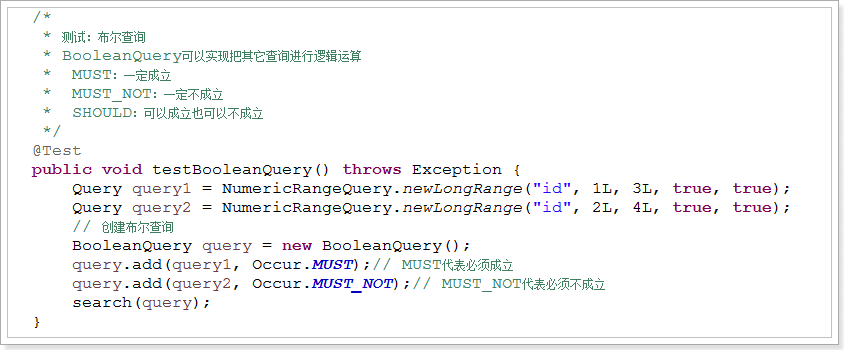
2.7.8、BooleanQuery(组合查询)
2.8、使用Lucene修改索引
/*
* 演示:修改索引。
* 一般情况下,我们修改索引,一定是要精确修改某一个,因此一般会根据ID字段进行修改。
* 但是在Lucene中,词条查询要求字段必须是字符串类型,所以,我们的ID也必须是字符串
* 如果ID为数值类型,要修改一个指定ID的文档。我们可以先删除,再添加。
*/
@Test
public void testUpdate() throws Exception{
// 创建目录
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建配置对象
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, new IKAnalyzer());
// 创建索引写出类
IndexWriter writer = new IndexWriter(directory, conf); // 创建新的文档对象
Document doc = new Document();
doc.add(new StringField("id","1",Store.YES));
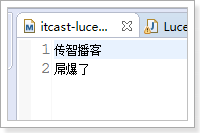
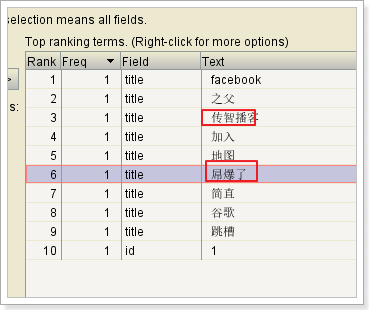
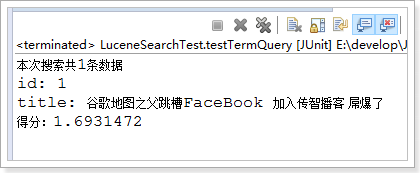
doc.add(new TextField("title", "谷歌地图之父跳槽FaceBook 加入传智播客 屌爆了", Store.YES)); // 修改文档,两个参数:一个词条,通过词条精确匹配一个要修改的文档;要修改的新的文档数据
writer.updateDocument(new Term("id","1"), doc);
// 提交
writer.commit();
// 关闭
writer.close();
}
数据已经改变:
2.9、使用Lucene删除索引
/*
* 演示:删除索引。
* 1)一次删除一个:
* 一般情况下,我们删除索引,一定是要精确删除某一个,因此一般会根据ID字段进行删除。
* 但是在Lucene中,词条查询要求字段必须是字符串类型,所以,我们的ID也必须是字符串
* 2)删除所有
* deleteAll()
*/
@Test
public void testDelete() throws Exception{
// 创建目录
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建配置对象
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, new IKAnalyzer());
// 创建索引写出类
IndexWriter writer = new IndexWriter(directory, conf); // 根据词条删除索引,一次删1条,要求ID必须是字符串
// writer.deleteDocuments(new Term("id", "1")); // 如果ID为数值类型,那么无法根据Term删除,那么怎么办? // 根据Query删除索引,我们用NumericRangeQuery精确锁定一条 指定ID的文档
Query query = NumericRangeQuery.newLongRange("id", 2L, 2L, true, true);
writer.deleteDocuments(query); // 删除所有
writer.deleteAll(); // 提交
writer.commit();
// 关闭
writer.close();
}
3、Lucene高级使用
3.1、Lucene实现关键词高亮显示
高亮显示的原理:
1)在返回的结果中,给所有关键字前后,添加一个自定义的HTML标签
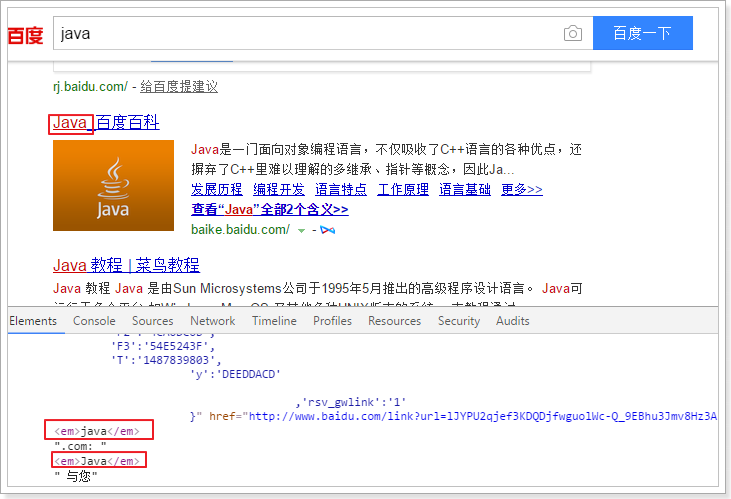
2)给这个标签设置CSS样式
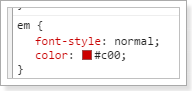
/*
* 演示:Lucene实现高亮
*/
@Test
public void testHighlighter() throws Exception {
// 创建索引目录对象、
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 创建搜索工具
IndexSearcher searcher = new IndexSearcher(reader); // 查询解析器
QueryParser parser = new QueryParser("title", new IKAnalyzer());
Query query = parser.parse("谷歌地图"); // 创建格式化工具
Formatter formatter = new SimpleHTMLFormatter("<em>", "</em>");
Scorer scorer = new QueryScorer(query);
// 创建高亮显示的工具
Highlighter highlighter = new Highlighter(formatter, scorer); // 执行查询,获取前N名的 文档信息
TopDocs topDocs = searcher.search(query, 10);
// 获取总条数
int totalHits = topDocs.totalHits;
System.out.println("本次搜索共" + totalHits + "条数据");
// 获取ScoreDoc(文档的得分及编号)的数组
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 获取编号
int docID = scoreDoc.doc;
// 根据编号找文档
Document document = reader.document(docID);
System.out.println("id: " + document.get("id")); // 获取原始结果
String title = document.get("title");
// 使用高亮工具把原始结果变成高亮结果:三个参数:分词器,要高亮的字段名称,原始结果
String highTitle = highlighter.getBestFragment(new IKAnalyzer(), "title", title); System.out.println("title: " + highTitle);
// 获取得分
System.out.println("得分:" + scoreDoc.score);
}
}
3.2、使用Lucene实现排序
/*
* 演示:Lucene实现排序
*/
@Test
public void testSort() throws Exception {
// 创建索引目录对象、
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 创建搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 查询解析器
QueryParser parser = new QueryParser("title", new IKAnalyzer());
Query query = parser.parse("谷歌地图"); // 创建排序的对象,然后接收排序的字段。参数:字段名称,字段类型,是否反转。false升序,true降序
Sort sort = new Sort(new SortField("id", Type.LONG, true));
// 执行查询,获取前N名的 文档信息
TopDocs topDocs = searcher.search(query, 10, sort); // 获取总条数
int totalHits = topDocs.totalHits;
System.out.println("本次搜索共" + totalHits + "条数据");
// 获取ScoreDoc(文档的得分及编号)的数组
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 获取编号
int docID = scoreDoc.doc;
// 根据编号找文档
Document document = reader.document(docID);
System.out.println("id: " + document.get("id"));
System.out.println("title: " + document.get("title"));
}
}
3.3、使用Lucene实现分页查询
/*
* 演示:Lucene实现分页查询 Lucene本身不提供分页功能。因此,要实现分页,我们必须自己来完成。也就是逻辑分页
* 先查询全部,然后返回需要的那一页数据。
*/
@Test
public void testPageQuery() throws Exception {
// 准备分页参数:
int pageSize = 5;// 每页条数
int pageNum = 2;// 当前页
int start = (pageNum - 1) * pageSize;// 起始角标
int end = start + pageSize;// 结束角标 // 创建索引目录对象、
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 创建搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 查询解析器
QueryParser parser = new QueryParser("title", new IKAnalyzer());
Query query = parser.parse("谷歌");
// 创建排序的对象,然后接收排序的字段。参数:字段名称,字段类型,是否反转。false升序,true降序
Sort sort = new Sort(new SortField("id", Type.LONG, false));
// 执行查询,获取的是0~end之间的数据
TopDocs topDocs = searcher.search(query, end, sort); // 获取总条数
int totalHits = topDocs.totalHits;
// 获取总页数
int totalPages = (totalHits + pageSize - 1) / pageSize; System.out.println("本次搜索共" + totalHits + "条数据,共" + totalPages + "页,当前是第" + pageNum + "页");
// 获取ScoreDoc(文档的得分及编号)的数组
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (int i = start; i < end; i++) {
ScoreDoc scoreDoc = scoreDocs[i];
// 获取编号
int docID = scoreDoc.doc;
// 根据编号找文档
Document document = reader.document(docID);
System.out.println("id: " + document.get("id"));
System.out.println("title: " + document.get("title"));
}
}
3.4、使用Lucene得分计算
Lucene会对搜索结果打分,用来表示文档数据与词条关联性的强弱,得分越高,表示查询的匹配度就越高,排名就越靠前!其算法公式是:



关于Lucene全文检索相关技术的更多相关文章
- Lucene全文检索技术
Lucene全文检索技术 今日大纲 ● 搜索的概念.搜索引擎原理.倒排索引 ● 全文索引的概念 ● 使用Lucene对索引进行CRUD操作 ● Lucene常用API详解 ● ...
- lucene全文检索基础
全文检索是一种将文件中所有文本与检索项匹配的文字资料检索方法.比如用户在n个小说文档中检索某个关键词,那么所有包含该关键词的文档都返回给用户.那么应该从哪里入手去实现一个全文检索系统?相信大家都听说过 ...
- Apache Lucene(全文检索引擎)—创建索引
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
- RDS MySQL 全文检索相关问题的处理
RDS MySQL 全文检索相关问题 1. RDS MySQL 对全文检索的支持 2. RDS MySQL 全文检索相关参数 3. RDS MySQL 全文检索中文支持 3.1 MyISAM 引擎表 ...
- lucene 全文检索工具的介绍
Lucene:全文检索工具:这是一种思想,使用的是C语言写出来的 1.Lucene就是apache下的一个全文检索工具,一堆的jar包,我们可以使用lucene做一个谷歌和百度一样的搜索引擎系统 2. ...
- Lucene全文检索_分词_复杂搜索_中文分词器
1 Lucene简介 Lucene是apache下的一个开源的全文检索引擎工具包. 1.1 全文检索(Full-text Search) 1.1.1 定义 全文检索就是先分词创建索引,再执行搜索的过 ...
- 关于Web开发里并发、同步、异步以及事件驱动编程的相关技术
一.开篇语 我的上篇文章<关于如何提供Web服务端并发效率的异步编程技术>又成为了博客园里“编辑推荐”的文章,这是对我写博客很大的鼓励,也许是被推荐的原因很多童鞋在这篇文章里发表了评论,有 ...
- 【原】http缓存与cdn相关技术
摘要:最近要做这个主题的组内分享,所以准备了一个星期,查了比较多的资料.准备的过程虽然很烦很耗时间,不过因为需要查很多的资料,因此整个过程下来,对这方面的知识影响更加深刻.来来来,接下来总结总结 一 ...
- Storm分布式实时流计算框架相关技术总结
Storm分布式实时流计算框架相关技术总结 Storm作为一个开源的分布式实时流计算框架,其内部实现使用了一些常用的技术,这里是对这些技术及其在Storm中作用的概括介绍.以此为基础,后续再深入了解S ...
随机推荐
- hdu4514(非连通图的环判断与图中最长链)(树的直径)
湫湫系列故事——设计风景线 随着杭州西湖的知名度的进一步提升,园林规划专家湫湫希望设计出一条新的经典观光线路,根据老板马小腾的指示,新的风景线最好能建成环形,如果没有条件建成环形,那就建的越长越好. ...
- 洛谷P3406 海底高铁
题目背景 大东亚海底隧道连接着厦门.新北.博艾.那霸.鹿儿岛等城市,横穿东海,耗资1000亿博艾元,历时15年,于公元2058年建成.凭借该隧道,从厦门可以乘坐火车直达台湾.博艾和日本,全程只需要4个 ...
- 利用开源工具实现轻量级上网行为审计(来源ispublic.com)
https://blog.csdn.net/cnbird2008/article/details/5875781
- python学习之-- RabbitMQ 消息队列
记录:异步网络框架:twisted学习参考:www.cnblogs.com/alex3714/articles/5248247.html RabbitMQ 模块 <消息队列> 先说明:py ...
- Intersection--poj1410(判断线段与矩形的关系)
http://poj.org/problem?id=1410 题目大意:给你一个线段和矩形的对角两点 如果相交就输出'T' 不想交就是'F' 注意: 1,给的矩形有可能不是左上 右下 所以要先判 ...
- [Bzoj2733][Hnoi2012] 永无乡(BST)(Pb_ds tree)
2733: [HNOI2012]永无乡 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 4108 Solved: 2195[Submit][Statu ...
- 105. Construct Binary Tree from Inorder and preorder Traversal
/* * 105. Construct Binary Tree from Inorder and preorder Traversal * 11.20 By Mingyang * 千万不要以为root ...
- hybird app 用 xcode ios打包 ipa 测试包并且安装真机测试
1.创建 ios 项目 1.用 cordova 创建一个 ios 项目 npm install -g cordova cordova create hello com.mydomain.hello H ...
- VS2012关于hash_map的使用简略
VS关于hash_map使用的一些经常使用构造方法汇总,包含基本类型和结构体,相信够一般模仿使用: # include<hash_map> #include<iostream> ...
- B+树在NTFS文件系统中的应用
B+树在NTFS文件系统中的应用 flyfish 2015-7-6 卷(volume) NTFS的结构首先从卷開始. 卷相应于磁盘上的一个逻辑分区,当你将一个磁盘或者磁盘的一部分格式化成NTFS,卷将 ...