Python Pandas库的学习(二)
今天我们继续讲下Python中一款数据分析很好的库。Pandas的学习
接着上回讲到的,如果有人听不懂,麻烦去翻阅一下我前面讲到的Pandas学习(一)
如果我们在数据中,想去3,4,5这几行数据,那么我们怎么取呢?
food.loc[3:6]
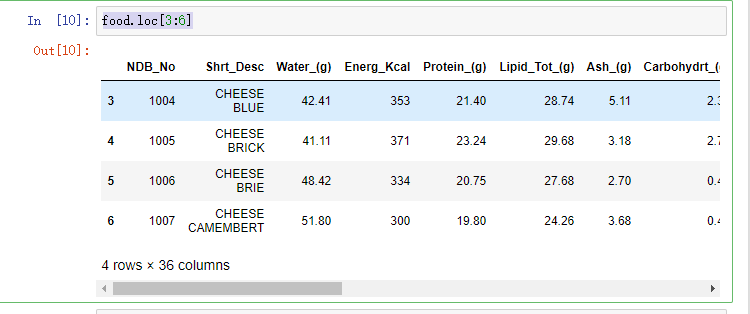
可以看到,这种取法跟Python中,切片操作一样。
如果我想去单独某几条数据,只需要传入index值即可
food.loc[[2,5,10]]
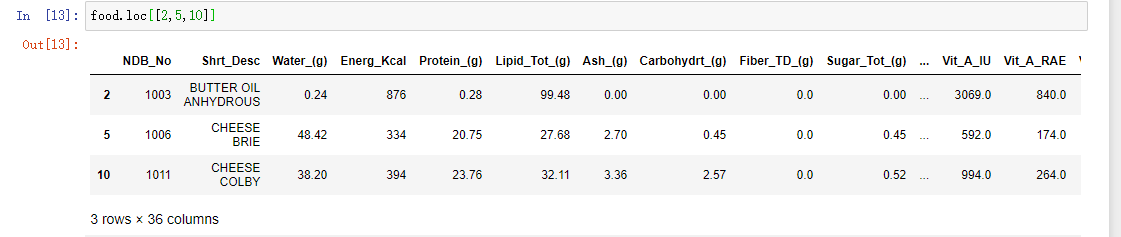
如果我先想不通过行去取数据,想通过列去取数据的话,我们该怎么做呢??
我们可以通过列名去拿取数据
col_NB = food["NDB_No"]
print(col_NB)

可以看到,我们取到了第一列的数据出来。
那么我们想取两列数据出来,我们应该怎么操作呢?
方法跟上面一样,将列名加到里面,组成一个list列表。
col_2 = ["Zinc_(mg)","Copper_(mg)"]
col_2_all = food[col_2]
print(col_2_all)

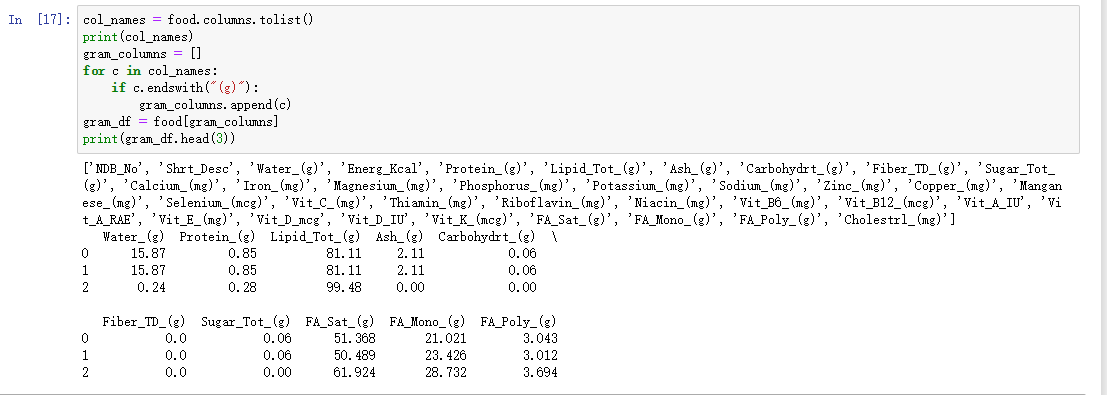
来我们看下数据上面,有些列名是带了单位的,那么我们怎么选择其中某几个一样单位的列呢?

我们先要取到全部的列名,然后将列名中带有单位(g)的列名取出,并单独放到一个列表中,最后在取这个列表中的列的数据即可
col_names = food.columns.tolist()
print(col_names)
gram_columns = []
for c in col_names:
if c.endswith("(g)"):
gram_columns.append(c)
gram_df = food[gram_columns]
print(gram_df.head(3))
这些都是些简单的操作,
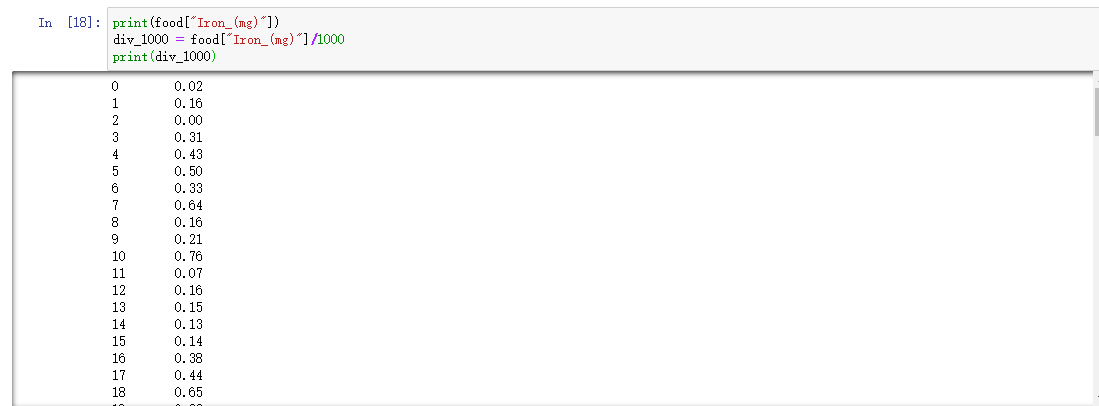
再比如说,我们想进行一些加减乘除的操作。
我想把单位为mg的数据,转换成g的数据,这里的做法,就跟Numpy是类似的。
print(food["Iron_(mg)"])
div_1000 = food["Iron_(mg)"]/1000
print(div_1000)
我们在对某个数据上进行操作,即可得到我们想要的结果。
water_energy = food["Water_(g)"]*food["Energ_Kcal"]
对应位置的乘法操作,需要保证的是,维度要相同才可以!
water_energy = food["Water_(g)"]*food["Energ_Kcal"]
water_energy = food["Water_(g)"]*food["Energ_Kcal"]
iron_grams = food["Iron_(mg)"]/1000
print(food.shape)
food["Iron_(g)"]=iron_grams
print(food.shape)

上一段代码可以看到,我们把一列名称的值,进行单位转换,把mg转换为g,然后新建了一列数据
将这列数据放到数据集中,之前打印出来的数据维度,8618个样本,和36个属性值。后面打印的
是37个属性值,也就是我们将新的属性值,放入到原来的数据值中了!前提是,其中的维度要对应上才可以。
weighted_protein = food["Protein_(g)"]*2
weighted_fat =-0.75* food["Lipid_Tot_(g)"]
initial_rating = weighted_protein + weighted_fat
比如说这些运算操作, 维度一样,相当于对应位置进行运算。
跟Numpy一样,我们也有一些别方法,求最大值,最小值,平均值等等

方式基本上跟Numpy类似。
今天就先讲到这里。感谢大家的阅读!感谢~~
Python Pandas库的学习(二)的更多相关文章
- Python Pandas库的学习(三)
今天我们来继续讲解Python中的Pandas库的基本用法 那么我们如何使用pandas对数据进行排序操作呢? food.sort_values("Sodium_(mg)",inp ...
- Python Pandas库的学习(一)
今天我们来学习一下Pandas库,前面我们讲了Numpy库的学习 接下来我们学习一下比较重要的库Pandas库,这个库比Numpy库还重要 Pandas库是在Numpy库上进行了封装,相当于高级Num ...
- python pandas库——pivot使用心得
python pandas库——pivot使用心得 2017年12月14日 17:07:06 阅读数:364 最近在做基于python的数据分析工作,引用第三方数据分析库——pandas(versio ...
- Python pandas库159个常用方法使用说明
Pandas库专为数据分析而设计,它是使Python成为强大而高效的数据分析环境的重要因素. 一.Pandas数据结构 1.import pandas as pd import numpy as np ...
- Python——Pandas库入门
一.Pandas库介绍 Pandas是Python第三方库,提供高性能易用数据类型和分析工具 import pandas as pd Pandas基于NumPy实现,常与NumPy和Matplotli ...
- Python Pandas库 初步使用
用pandas+numpy读取UCI iris数据集中鸢尾花的萼片.花瓣长度数据,进行数据清理,去重,排序,并求出和.累积和.均值.标准差.方差.最大值.最小值
- Python asyncio库的学习和使用
因为要找工作,把之前自己搞的爬虫整理一下,没有项目经验真蛋疼,只能做这种水的不行的东西...T T,希望找工作能有好结果. 之前爬虫使用的是requests+多线程/多进程,后来随着前几天的深入了解 ...
- python 标准库基础学习之开发工具部分1学习
#2个标准库模块放一起学习,这样减少占用地方和空间#标准库之compileall字节编译源文件import compileall,re,sys#作用是查找到python文件,并把它们编译成字节码表示, ...
- 使用Python的库qrcode生成二维码
现在有很多二维码的生成工具,在线的,或者安装的软件,都可以进行生成二维码.今天我用Python的qrcode库生成二维码.需要预先安装 Image 库 安装 用pip安装 # pip install ...
随机推荐
- 洛谷 P3732 [HAOI2017]供给侧改革【trie树】
参考:http://blog.csdn.net/di4covery/article/details/73065684 我以为是后缀数组+某某数据结构,结果居然是01trie!!题解说"因为是 ...
- thinkphp5.0常遇到的错误
call a member xxxx on null 1.一般是没有继承controller: 2.对象和数组使用错误.
- 购买阿里云ECS+安装宝塔面板+Mac下怎么连接阿里云ECS服务器
1.购买阿里云ECS 2.重置实例密码 这个有点对用户不友好,实际意思就是设置服务器的root登录密码 3.配置安全组放行端口 因为服务器需要从宝塔网站download安装包,包括一些常用的服务比如S ...
- ubuntu下进入xampp mysql命令行
在命令行下进入到/opt/lampp/bin目录,使用命令:sudo ./mysql,回车即可. 注意:运行这个命令需要加上sudo,以root权限来运行,不然有些数据库没有权限查看.
- redis问题集结
redis和memcached比较? redis中数据库默认是多少个db 及作用? python操作redis的模块? 如果redis中的某个列表中的数据量非常大,如果实现循环显示每一个值? redi ...
- [CQOI 2006]线段树之简单题
Description 有一个n个元素的数组,每个元素初始均为0.有m条指令,要么让其中一段连续序列数字反转--0变1,1变0(操作1),要么询问某个元素的值(操作2).例如当n=20时,10条指令如 ...
- ACM_Encoding
Encoding Time Limit: 2000/1000ms (Java/Others) Problem Description: 给定一个只包含'A' - 'Z'的字符串,我们可以使用以下方法对 ...
- rabbitmq实践笔记(一):安装、配置与使用初探
引言: 对于一个大型的软件系统来说,会有很多的组件.模块及不同的子系统一起协同工作,模块之间的通信需要一个可靠的通信管道来保证 ,通信管道需要解决解决很多问题,比如: 1)信息的发送者和接收者如何维持 ...
- VS2010的一个错误,无法加载类型
一个解决方案中的一个项目X,启动时总是报错,无法加载一个同一个解决方案中另一个项目A生成EXE中的数据类型. 做了如下的步骤解决问题. 1:检查项目A,未发现错误,调试启动A,一切正常. 2:检查项目 ...
- paint之Graphics
在paint方法里面,这个Graphics类就相当于一支画笔.而且就画在那个component里面,比如frame. 看例子代码: import java.awt.*; public class Te ...