20180710使用gh
转自:http://www.ywnds.com/?p=14265
一、背景
GitHub正式宣布以开源的方式发布gh-ost:GitHub的MySQL无触发器在线更改表定义工具!下面是官方给出gh-ost产生的背景。
gh-ost是GitHub在2016年5月份开源的,目的是解决一个经常碰到的问题:不断变化的产品需求会不断要求更改MySQL表结构。gh-ost通过一种影响小、可控制、可审计、操作简单的方案来改变线上表结构。
在介绍gh-ost之前,我们先了解一下各种现有方案,以及为什么要自己开发一个新工具。
已有的在线修改表定义方案?
目前,在线修改表定义的任务主要是通过这三种途径完成的:
- 在从库上修改表定义,修改之后再提升为新的主库。
- 通过MySQL的InnoDB在线DDL功能。
- 使用修改表定义工具。现在最流行的是Percona公司的pt-online-schema-change和Facebook的OSC,也有人使用LHM或最早的oak-online-alter-table。
还有其它的比如Galera Cluster的Rolling Schema Upgrade,或者非InnoDB引擎的表等。GitHub的MySQL数据库用的都是主从复制架构,使用可靠的InnoDB引擎。
为什么我们决定去设计一个新解决方案,而不是直接从上面的几种方案中选一个用?现有的解决方案都有着自身的局限性,下面就对它们的不足之处做个简单分析。我们会主要深入地分析基于触发器的在线修改表定义工具的不足之处。
- 在从库上修改表定义的方案需要付出许多运维代价,这需要更多的服务器、更长的完成时间和更复杂的管理工作。修改操作是直接应用在具体的某个从库或者整个拓扑架构的一些子树上。服务器宕机、从库数据不够新、新部署的服务器等各种问题都需要有非常严密的跟踪系统来跟进单个数据库上的操作。一个改变操作可能会需要多次反复,也就需要更长时间。而把一个从库升为主库也会导致短暂的停服。如果同时需要做多个更改就更难协调。我们每天都要改好几张表,所以在考虑解决方案时,我们不希望有这样的管理开销。
- MySQL的InnoDB在线DDL只能是在你敲命令的那个MySQL上才是“在线”修改的。二进制文件中的日志把修改操作序列化了,从库应用日志时会导致复制延迟。但如果尝试在每个从库上挨个去改的话又会导致上面分析的管理代价。而且DDL还是不可中断的,要是在修改时把操作杀掉的话还需要更长的时间去回滚,甚至导致数据字典崩溃。这种方案也不“友好”,在系统负载高时也不能限速或者暂停。这样的操作还有可能会耗尽你的系统资源。
- 我们用了pt-online-schema-change好几年了。可是,当我们的数据增多、业务压力增大之后,我们就碰到了越来越多的问题,甚至到了许多修改操作都被认为是“危险操作”的地步。有一些操作只敢在非业务高峰期或者周末才敢执行,其它的总是会导致MySQL停止服务。所有现有的在线修改表定义工具都是用MySQL触发器来迁移数据的,因此本身就存在着一些问题。
基于触发器的解决方案有什么不好?
所有在线修改表定义的工具运行原理都是相似的:创建一张与原始表定义相同的临时表,趁上面没有数据时先改好表定义,然后慢慢地、用增量方式把数据从原始表拷到临时表,同时不断的把进行中的原始表上的数据操作(所有应用在原始表上的插入、删除、更新操作)也应用过来。当工具把所有数据都拷贝完毕,两边数据同步了之后,它就用这张临时表来替代原始表。修改过程就结束了。
像pt-online-schema-change、LHM和oak-online-alter-table这些工具用的都是同步复制的方式,对表的每一条数据修改都会立刻在同一个事务里就应用到临时表上。Facebook的工具用的则是异步模式,先把修改操作都记在一张修改日志表里,然后再取出来执行,把修改操作应用到临时表上。这些工具全都使用触发器来提取那些应用在目标表上的操作。
触发器都是存储过程,在表上有插入、删除、修改操作时就会被触发。触发器可能包括好多条语句,这些语句都是和引发触发器的那条操作在相同的事务空间内运行的,因此保证了这些操作的原子性。
一般意义上的触发器,尤其是基于触发器的表定义修改操作,都有如下问题:
- 触发器就是存储过程,都是解释型代码,MySQL不会做预编译。把它们硬嵌入到业务操作的事务空间中,会给你要修改的表上执行的每条操作都增加命令分析和解释的开销。
- 锁:触发器与操作语句分享相同的事务空间,当操作语句释放了原始表上的锁之后,触发器再去释放另一张表上的锁。在同步模式下这样行为的后果尤其严重。主库上的锁竞争与写并发有直接关系。我们在生产环境中曾经遇到过锁竞争导致的几乎乃至完全锁住的情况,完全无法访问表或者整个数据库。触发器导致的另一种锁是在创建或销毁触发器时对元数据的锁。在完成修改表定义之后从比较忙的表上删除触发器时,我们曾经碰到几十秒甚至几分钟无法提供服务的情况。
- 无法暂停:当主库业务负载开始增高时,你可能会想要暂停或者取消还没完成的修改表定义的任务。可是基于触发器的方案没办法这么做。也许你可以暂停行拷贝的操作,但却不能暂停触发器,因为把触发器停掉会导致临时表中丢数据。所以,在整个过程中触发器都必须一直处于工作状态。在一些繁忙的服务器上,我们曾经见过即使把在线操作全停掉,最后主库还是被触发器给拖死的情况。
- 并发修改:大家都希望能同时修改多张表的定义。考虑到上面分析的触发器的代价,我们并不敢以触发器的模式同时修改多张表的定义,我们也没听说有哪家公司真的在线上这么干。
- 测试:大家也许想测试一下修改方案是否可行,评估一下负载。基于触发器的方案只能在从库上通过基于语句的复制来模拟一下,由于从库上的复制操作是单线程的(即使用了多线程复制的方案,大部分情况下也还是这样的),这样远不能模拟出在主库上修改过程中的真实情况。
二、gh-ost介绍
gh-ost是gitHub’s Online Schema Transmogrifier/Transfigurator/Transformer/Thingy的缩写,意思是GitHub的在线表定义转换器。抛弃了pt-online-schema-change使用trigger来同步增量数据的方法,而通过模拟slave获取row格式的binlog的方式来获取增量数据。思路也很新颖,作者很厉害,也是是openark kit工具集的作者(主要是用python写的一套工具集)。具体的数据流图可以看下图。
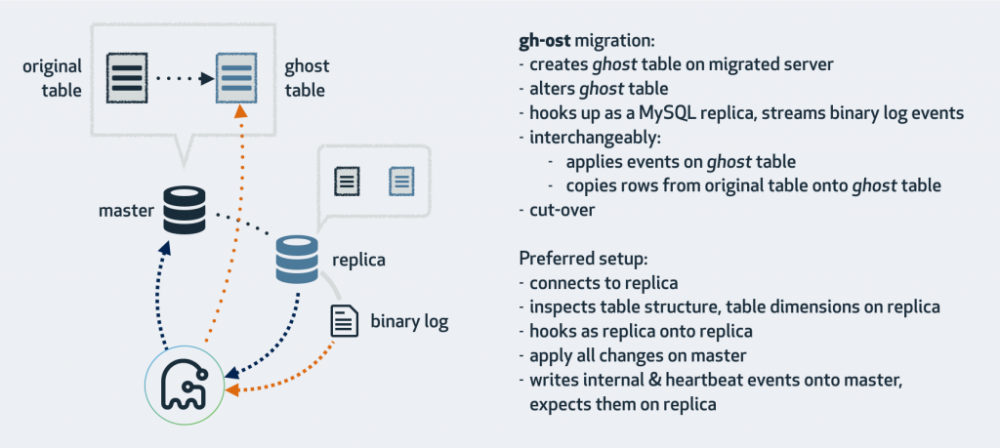
因为binlog中记录的是full image,所以binlog中的数据是最权威的,而且读取的binlog在应用的时候做了如下转化,而且copy old data是insert ignore,因此会以binlog的优先级为最高,因此不会有问题。
|
源类型
|
目标类型
|
|
insert
|
replace
|
|
update
|
update
|
|
delete
|
delete
|
对与insert和update是没有问题的,因为无论copy old row和apply binlog的先后顺序,如果apply binlog在后,会覆盖掉copy old row,如果apply binlog在前面,copy old row因为使用insert ignore,因此会被ignore掉;
对与delete数据,我们可以演算一下,abc三个操作,可能存在三种情况(b肯定在a的后面):
a. delete old row
b. delete binlog apply
c. copy old row
1. cab,c会将数据copy到ghost表,最后b会把ghost表中的数据delete掉;
2. acb,c空操作,b也是空操作;
3. abc,b空操作,c也是空操作;
大概看完了gh-ost工作原理后,既然牵扯到了replace语句,自然表就必须要有一个主键或唯一键。如果没有的情况下执行gh-ost,自然会得到gh-ost的一个错误提供:FATAL No PRIMARY nor UNIQUE key found in table! Bailing out.
gh-ost有以下特点:
- 无触发器
gh-ost不使用触发器,它跟踪二进制日志文件,在对原始表的修改提交之后,用异步方式把这修改内容应用到临时表中去。
gh-ost希望二进制文件使用基于行的日志格式,但这并不表示如果主库上使用的是基于语句的日志格式,就不能用它来在线修改表定义了。事实上,我们常用的方式是用一个从库把日志的语句模式转成行模式,再从这个从库上去读日志。搭一个这样的从库并不复杂。
- 轻量级
因为不需要使用触发器,gh-ost把修改表定义的负载和正常的业务负载解耦开了。它不需要考虑被修改的表上的并发操作和竞争等,这些在二进制日志中都被序列化了,gh-ost只操作临时表,完全与原始表不相干。事实上,gh-ost也把行拷贝的写操作与二进制日志的写操作序列化了,这样,对主库来说只是有一条连接在顺序的向临时表中不断写入数据,这样的行为与常见的ETL相当不同。
- 可暂停
因为所有写操作都是gh-ost生成的,而读取二进制文件本身就是一个异步操作,所以在暂停时,gh-ost是完全可以把所有对主库的写操作全都暂停的。暂停就意味着对主库没有写入和更新。不过gh-ost也有一张内部状态跟踪表,即使在暂停状态下也会向那张表中不断写入心跳信息,写入量可以忽略不计。
gh-ost提供了比简单的暂停更多的功能,除了暂停之外还可以做:
负载:与pt-online-schema-change相近的一个功能,用户可以设置MySQL指标的阈值,比如设置Threads_running=30。
复制延迟:gh-ost内置了心跳功能来检查复制延迟。用户可以指定查看哪个从库的延迟,gh-ost默认是直接查看它连上的那个从库。
命令:用户可以写一些命令,根据输出结果来决定要不要开始操作。比如:SELECT HOUR(NOW()) BETWEEN 8 and 17.
上述所有指标即使在修改表定义的过程中也可以动态修改。
标志位文件:生成一个标志位文件,gh-ost就会立刻暂停。删除文件,gh-ost又会恢复工作。
用户命令:通过网络连上gh-ost,通过命令让它暂停。
- 动态可控
如果别的工具在修改过程中产生了比较高的负载,DBA只好把它停掉再修改配置,比如把一次拷贝的数据量改小些,然后再从头开始修改过程。这样的反复操作代价非常大。
gh-ost通过监听TCP或者unix socket文件来获取命令。即使有正在进行中的修改工作,用户也可以向gh-ost发出命令修改配置,比如可以这样做:
echo throttle | nc -U /tmp/gh-ost.sock:这是暂停令, 也可以输入no-throttle取消暂停。
修改运行参数,gh-ost可以接受这样的修改方式来改变它的行为:chunk-size=1500, max-lag-millis=2000, max-load=Thread_running=30。
- 可审计
用上面所说的相同接口也可以查看gh-ost的状态,查看当前任务进度、主要配置参数、相关MySQL实例的情况等。这些信息通过网络发送命令就可以得到,因此就给了运维人员极大的灵活性,如果是使用别的工具的话一般只能是通过共享屏幕或者不断跟踪日志文件最新内容。
- 可测试
读取二进制文件内容的操作完全不会增加主库的负载,在从库上做修改表结构的操作也和在主库上做是非常相象的(当然并不完全一样,但主要来说还是差不多的)。
gh-ost自带了–test-on-replica选项来支持测试功能,它允许你在从库上运行起修改表结构操作,在操作结束时会暂停主从复制,让两张表都处于同步、就绪状态,然后切换表、再切换回来。这样就可以让用户从容不迫地对两张表进行检查和对比。
我们在GitHub是这样在生产环境测试gh-ost的:我们有许多个指定的生产从库,在上面不提供服务,只是周而复始地不断地把所有表定义都改来改去。对于我们生产环境地每一张表,小到空表,大到几百GB,都会通过修改存储引擎的方式来进行修改(engine=innodb),这样并不会真正修改表结构。在每一次这样的修改操作最后我们都会停掉主从复制,再把原始表和临时表的全量数据都各做一次校验和,然后比较两个校验和,要求它们是一致的。然后我们恢复主从复制,再继续测试下一张表。我们生产环境的每一张表都这样用gh-ost在从库上做过好多次修改测试。
- 可靠的
所有上述讲到的和没讲到的内容,都是为了让你对gh-ost的能力建立信任。毕竟,大家在做这件事的时候已经使用类似工具做了好多年,而gh-ost只是一个新工具。
我们在从库上对gh-ost进行测试,在去主库上做第一次真正改动之前我们在从库上成功地试了几千次。所以,请你也在从库上开始测试,验证数据是完好无损的,然后再把它用到生产环境。我们希望你可以放手去试。
当你执行了gh-ost之后,也许你会看见主库的负载变高了,那你可以发出暂停命令。用echo throttle命令生成一个文件,看看主库的负载会不会又变得正常。试一下这些命令,你就可以知道你可以怎样控制它的行为,你的心里就会安定许多。
你发起了一次修改操作,然后估计完成时间是凌晨2点钟,可是你又非常关心最后的切换操作,非常想看着它切换,这可怎么办?只需要一个标志位文件就可以告诉gh-ost推迟切换了,这样gh-ost会只做完拷贝数据的操作,但不会切换表。它还会仍然继续同步数据,保持临时表的数据处于同步状态。等第二天早上你回到办公室之后,删除标志位文件或者向gh-ost发送命令echo unpostpone,它就会做切换了。我们不希望软件强迫我们看着它做事情,它应该把我们解放出来,让人去做人该做的事。
谈到估计完成时间,–exact-rowcount选项非常有用。在最开始时要在目标表上做个代价比较大的SELECT COUNT(*)操作查出具体要拷多少行数据,gh-ost就会对它要做多少工作有了一个比较准确的估计。接下来在拷贝的过程中,它会不断地尝试更新这个估计值。因为预计完成的时间点总是会不断变化,所以已经完成的百分比就反而比较精确。如果你也曾经有过非常痛苦的经历,看着已经完成99%了可是剩下的一点操作却继续了一个小时也没完,你就会非常喜欢我们提供的这个功能。
三、gh-ost工作模式
gh-ost工作时可以连上多个MySQL实例,同时也把自己以从库的方式连上其中一个实例来获取二进制日志事件。根据你的配置、数据库集群架构和你想在哪里执行修改操作,可以有许多种不同的工作模式。
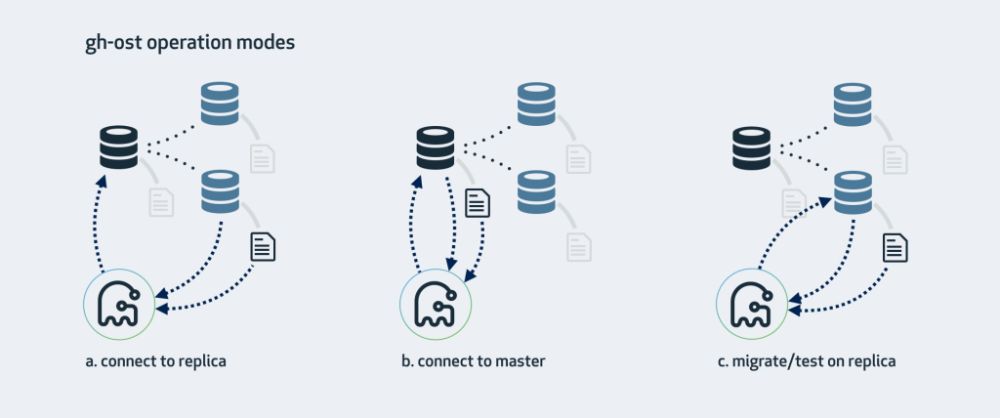
1、连上从库,在主库上修改
这是gh-ost默认的工作模式,它会查看从库情况,找到集群的主库并且连接上去。修改操作的具体步骤是:
A. 在主库上读写行数据;
B. 在从库上读取二进制日志事件,将变更应用到主库上;
C. 在从库上查看表格式、字段、主键、总行数等;
D. 在从库上读取gh-ost内部事件日志(比如心跳);
E. 在主库上完成表切换;
如果主库的二进制日志格式是Statement,就可以使用这种模式。但从库就必须配成启用二进制日志(log_bin, log_slave_updates),还要设成Row格式(binlog_format=ROW),实际上gh-ost会在从库上帮你做这些设置。
事实上,即使把从库改成Row格式,这仍然是对主库侵入最少的工作模式。
2、连上主库
如果没有从库,或者不想在从库上操作,那直接用主库也是可以的。gh-ost就会在主库上直接做所有的操作。仍然可以在上面查看主从复制延迟。
A. 主库必须产生Row格式的二进制日志;
B. 启动gh-ost时必须用–allow-on-master选项来开启这种模式;
3、在从库上修改和测试
这种模式会在从库上做修改。gh-ost仍然会连上主库,但所有操作都是在从库上做的,不会对主库产生任何影响。在操作过程中,gh-ost也会不时地暂停,以便从库的数据可以保持最新。
A. –migrate-on-replica选项让gh-ost直接在从库上修改表。最终的切换过程也是在从库正常复制的状态下完成的。
B. –test-on-replica表明操作只是为了测试目的。在进行最终的切换操作之前,复制会被停止。原始表和临时表会相互切换,再切换回来,最终相当于原始表没被动过。主从复制暂停的状态下,你可以检查和对比这两张表中的数据。
三种方法各有优缺点,这里只说缺点,先说第一种的缺点,由于会在从上面读取binlog,但有可能主库的binlog没有完全在从库执行,所以个人感觉第一种方法有丢失数据的风险。第二种方法任何操作都会再主库操作,或多或少会对主库负载造成影响,但是可以通过调整一些参数降低和时刻关注这些影响,所以个人推荐使用第二种方法。至于第三种方法是偏向测试用的,这里不做过多介绍,但是第三种方法里有一个细节,cut-over阶段有会stop slave一个操作,其实这个操作风险特别高,有时stop slave时间会很长,务必会对线上数据库使用造成影响,所以如果使用第三种方法做测试也要在线下数据库。
- 将需要一台服务器提供基于行式复制(RBR)格式的二进制日志。现在仅支持FULL镜像,MINIMAL镜像将来会获得支持。
- gh-ost用户需要具有这些权限在你迁移的数据库上:ALTER, CREATE, DELETE, DROP, INDEX, INSERT, LOCK TABLES, SELECT, TRIGGER, UPDATE。或SUPER, REPLICATION SLAVE on *.*,或REPLICATION CLIENT, REPLICATION SLAVE on *.*。SUPER权限是STOP SLAVE,START SLAVE操作所必需的,这些用于将你的binlog_format切换到ROW格式(如果它不是ROW格式,并且你明确指定了–switch-to-rbr选项)。如果你的复制从库已经是RBR(binlog_format = ROW)模式,你可以指定–assume-rbr以避免STOP SLAVE/ START SLAVE操作,因此不需要SUPER。
- 运行–test-on-replica模式时,在切换阶段之前,gh-ost会停止复制,以便你可以比较这两个表并确保迁移是正确的(仅测试使用)。
限制
- 不支持外键,在未来可能会得到支持。
- 触发器不受支持,在未来可能会得到支持。
- MySQL 5.7 JSON列受支持,但不能作为PRIMARY KEY的一部分。
- 表必须有一个PRIMARY KEY或其他UNIQUE KEY。
- Amazon RDS可以工作,但有其自身的局限性(阿里云已经支持)。
- 通过从库迁移时不支持多源复制。
- 主 – 主模式下,设置仅在主动 – 被动中受支持。在主动 – 主动(表中同时写入两个主动实例的表)不受支持。它可能在未来得到支持。
- 如果将enum字段作为迁移Key(通常是PRIMARY KEY)的一部分,则迁移性能会降低并且可能出现不好的情况。
- ALTER TABLE … RENAME to some_other_name不受支持(并且不应该使用gh-ost来执行这样的小操作)。
五、gh-ost参数介绍
常用参数介绍
--host
--port
--user
--password
--database
--table
--alter
--allow-on-master
--max-load
迁移过程中,gh-ost会时刻关注负载情况,负载阀值是使用者自己定义,比如数据库的最大连接数,如果超过阀值,gh-ost不会退出,会等待到负载在阀值以下继续执行。
--critical-load
这个指的是gh-ost退出阀值,当负载超过这个阀值,gh-ost会停止并退出。
--max-lag-millis
会监控从库的主从延迟情况,如果延迟秒数超过这个阀值,迁移不会退出,等待延迟秒数低于这个阀值继续迁移。这个是迁移中很大的一个问题,特别是在从库迁移时。
gh-ost监控复制延迟是通过检查gh-ost本身在实用程序更新日志表中注入的心跳事件来衡量的。也就是说,为了测量这个复制延迟,gh-ost不需要发出show slave status命令,也没有任何外部心跳机制。
当提供–throttle-control-replicas时,限流还会考虑指定主机上的延迟。通过查询gh-ost的更新日志表(其中gh-ost注入心跳)完成列出的主机上的延迟时间测量。
gh-ost能够利用毫秒测量复制延迟,当–max-lag-millis小于1000,即小于1秒时,gh-ost将进行限流。
--throttle-control-replicas
和–max-lag-millis参数相结合,这个参数指定主从延迟的数据库实例。
--initially-drop-ghost-table
gh-ost执行前会创建两张_xx_ghc和_xx_gho表,如果这两张表存在,且加上了这个参数,那么会自动删除原gh表,重新创建,否则退出。_xx_gho表相当于老表的全量备份,_xx_ghc表数据是数据更改日志,理解成增量备份。
--initially-drop-ghost-table
gh-ost操作之前,检查并删除已经存在的ghost表。该参数不建议使用,请手动处理原来存在的ghost表。默认不启用该参数,gh-ost直接退出操作。
--initially-drop-socket-file
gh-ost执行时会创建socket文件,退出时不会删除,下次执行gh-ost时会报错,加上这个参数,gh-ost会强制删除已经存在的socket文件。该参数不建议使用,可能会删除一个正在运行的gh-ost程序,导致DDL失败。
--initially-drop-old-table
gh-ost操作之前,检查并删除已经存在的旧表。该参数不建议使用,请手动处理原来存在的ghost表。默认不启用该参数,gh-ost直接退出操作。
--ok-to-drop-table
gh-ost执行完以后是否删除老表,加上此参数会自动删除老表。
--cut-over
自动执行rename操作,选择cut-over类型:atomic/two-step,atomic(默认)类型的cut-over是github的算法,two-step采用的是facebook-OSC的算法。
--cut-over-lock-timeout-seconds
gh-ost在cut-over阶段最大的锁等待时间,当锁超时时,gh-ost的cut-over将重试。(默认值:3)
--switch-to-rbr
让gh-ost自动将从库的binlog_format转换为ROW格式。
--assume-rbr
确认gh-ost连接的数据库实例的binlog_format=ROW的情况下,可以指定–assume-rbr,这样可以禁止从库上运行stop slave,start slae,执行gh-ost用户也不需要SUPER权限。
--panic-flag-file
这个文件被创建,迁移操作会被立即终止退出。
--throttle-flag-file
此文件存在时操作暂停,删除文件操作会继续。
--postpone-cut-over-flag-file
当这个文件存在的时候,gh-ost的cut-over阶段将会被推迟,直到该文件被删除。
--concurrent-rowcount
该参数如果为True(默认值),则进行row-copy之后,估算统计行数(使用explain select count(*)方式),并调整ETA时间,否则,gh-ost首先预估统计行数,然后开始row-copy。
--exact-rowcount
准确统计表行数(使用select count(*)的方式),得到更准确的预估时间。
--execute
如果确定执行,加上这个参数。
可选参数介绍
--default-retries
各种操作在panick前重试次数。(默认为60)
--chunk-size
迁移过程是一步步分批次完成的,这个参数是指事务每次提交的行数,默认是1000。
--timestamp-old-table
使旧表包含时间戳值,旧表是在成功迁移结束时将原始表重新命名的内容。例如,如果表是gh_ost_test,那么旧表通常是_gh_ost_test_del。使用–timestamp-old-table后,它将是_gh_ost_test_20170221103147_del。
--throttle-http
提供一个HTTP端点,gh-ost将在给定的URL上发出HEAD请求,并在响应状态码不是200时进行限流。URL可以通过交互式命令动态查询和更新,空的URL表示禁用HTTP检查。
--approve-renamed-columns
当做(change old_name new_name …)动作时,gh-ost分析语句以尝试将旧列名称与新列名称相关联,如果它检测到确实是重命名操作,默认情况下将会打印出信息并退出。但除非你提供–approve-renamed-columns,强制发出迁移操作。
如果你认为gh-ost解析错误,并且实际上并且没有重命名,你可以改为传入–skip-renamed-columns,这将导致gh-ost取消关联列值,数据将不会在这些列之间复制。
--skip-foreign-key-checks
默认情况下,gh-ost会验证迁移表中存不存在外键,如果存在就会报错并退出;在具有大量表的服务器上,此检查可能需要很长时间。如果你确定没有外键存在(表没有引用其他表,也没有被其他表引用)并希望保存检查时间,可以使用–skip-foreign-key-checks。但如果表上有外键,使用这个参数则会清除外键,千万注意。
--discard-foreign-keys
该操作很危险,意味着将默默丢弃表上存在的任何外键。目前,gh-ost不支持迁移表上的外键(当它在迁移表上注意到外键时,它会保留)。但是,它能够支持通过此标志删除外键,如果你想这么干,这是一个有用的选项。使用下来感觉跟–skip-foreign-key-checks参数作用一样。
--replica-server-id
gh-ost原理是通过模拟slave从而获得binlog,其默认server-id为99999,如果你运行多个迁移,那么你必须为每个gh-ost进程提供一个不同的,唯一的server-id。也可以使用进程ID当做server-id,例如:–replica-server-id = $((1000000000 + ))。
--migrate-on-replica
通常,gh-ost用于在主服务器上迁移表。如果你只希望在从库上执行全部迁移,使用–migrate-on-replica参数将gh-ost连接到从库进行迁移。
--assume-master-host
默认情况下,gh-ost更倾向连接从库来进行迁移。gh-ost通过爬取复制拓扑来推断主服务器的身份,你可以通过–assume-master-host = the.master.com明确告诉gh-ost主服务器的身份。这在以下方面很有用:
主 – 主拓扑结构(与–allow-master-master一起使用),其中gh-ost可以随意选择其中一个主协同者,这种情况你可以选择一个特定的主库。
tungsten复制器拓扑结构(与–tungsten一起使用),其中gh-ost无法抓取并检测主节点。
--dml-batch-size
gh-ost从二进制日志读取事件,并将它们应用到ghost表上。它采用的方式是将多个事件分组应用于单个事务中。这可以提供更好的写入吞吐量,因为我们不需要将每个事务日志同步到的磁盘。
此选项就是控制批量写入的大小,允许的值是1 – 100,其中1表示不分组处理(二进制日志中的每个事件在其自己的事务中应用到ghost表上)。默认值是10。
--heartbeat-interval-millis
用来控制注入心跳事件的频率(就是_xx_ghc表),用来测量主从延迟。你应该设置heartbeat-interval-millis <= max-lag-millis。否则,将失去粒度和效果。默认值100。其–max-lag-millis值应该在300-500之间。
--conf
指定gh-ost凭据的文件,如下格式。
[client]
user=gromit
password=123456
--debug
输出详细日志。
--verbose
执行过程输出日志。
六、安装使用gh-ost
直接使用二进制安装即可
|
1
2
3
|
$ tar xvf /tmp/gh-ost-release/gh-ost-binary-linux-20180601054532.tar.gz -C /tmp
$ mv /tmp/gh-ost /usr/bin
$ gh-ost -version
|
如果你安装有什么问题直接借助搜索引擎应该就可以解决。
然后在使用上,下面是一些通用的配置(采取在主库进行DDL操作模式),你也可以尝试不同的配置根据上面配置的介绍来使用。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
$ gh-ost \
--max-load=Threads_running=25 \
--critical-load=Threads_running=64 \
--chunk-size=1000 \
--throttle-control-replicas="10.10.0.110:3306" \
--max-lag-millis=1000 \
--initially-drop-old-table \
--initially-drop-ghost-table \
--initially-drop-socket-file \
--ok-to-drop-table \
--host="10.10.0.109" \
--port=3306 \
--user="root" \
--password="123456" \
--database="test" \
--table="test" \
--verbose \
--alter="add index idx1_k(k)" \
--switch-to-rbr \
--allow-on-master \
--cut-over=default \
--default-retries=120 \
--execute
|
实际上变更的表如果有超长事务,依然存在mdl锁问题导致失败,因为在最后的新表旧表交替阶段,会有一个短暂的加锁操作,而长事务会阻塞这个加锁操作,所以还得在ddl前确认无长事务。
七、gh-ost交互式命令
gh-ost被设计为操作友好。为此,它允许用户即使在运行时也可以控制其行为。gh-ost提供两种方式来进行动态控制。
Unix套接字文件:通过–serve-socket-file提供或由gh-ost默认设置,该接口总是处于启动状态。当gh-ost自我设定时,gh-ost将在启动时和整个迁移过程中公布套接字文件的标识文件。默认在/tmp下面,由gh-ost.库名.表明.sock组成。
TCP:由–serve-tcp-port选项提供,默认没有。
两个接口可以同时使用,两者都响应简单的文本命令,这使得通过shell进行交互变得容易。
命令介绍:
help:显示可用命令的简要列表。
status:返回迁移进度和配置的详细状态摘要。
sup:返回迁移进度的简要状态摘要。
coordinates:返回检查服务器的最近(尽管不是最新的)二进制日志位置。
chunk-size=<newsize>:修改chunk大小,适用于下一刻数据复制。
dml-batch-size=<newsize>:适用于下一次应用二进制日志事件数量。
max-lag-millis=<max-lag>:修改最大复制延迟阈值(毫秒,最小值是100,即0.1秒)。
max-load=<max-load-thresholds>:修改最大负载配置,适用于下一刻数据复制。如“max-load=Threads_running=50,threads_connected=1000”。
critical-load=<critical-load-thresholds>:修改临界负载配置(超过这些阈值会中止操作)。
nice-ratio=<ratio>:修改nice比例,0表示不设置nice就是不睡眠线程。如果为1则表示gh-ost检测到复制行花费了1ms后将进行1*1ms睡眠;如果花费100ms,nice值为0.5,则会睡眠50ms,以此类推。默认为0。
throttle-http:改变HTTP端点。
throttle-query:改变查询。
throttle-control-replicas=’replica1,replica2’:更改副本的列表,这些副本是gh-ost会检查的,这需要用逗号分隔的副本列表来检查并替换先前的列表。
throttle:强制迁移暂停。
no-throttle:取消强制迁移暂停。
unpostpone:在gh-ost推迟cut-over阶段,指示gh-ost停止推迟并立即进行切换。
panic:理解放弃操作,意味着gh-ost将中断所有操作。
下面给一些样例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
$ echo "status" | nc -U /tmp/gh-ost.sbtest.sbtest1.sock
# Migrating `sbtest`.`sbtest1`; Ghost table is `sbtest`.`_sbtest1_gho`
# Migrating localhost.localdomain:3306; inspecting localhost.localdomain:3306; executing on localhost.localdomain
# Migration started at Thu Jun 07 03:37:12 -0400 2018
# chunk-size: 250; max-lag-millis: 1500ms; dml-batch-size: 10; max-load: Threads_running=25; critical-load: Threads_running=64; nice-ratio: 0.000000
# throttle-additional-flag-file: /tmp/gh-ost.throttle
# throttle-control-replicas count: 1
# Serving on unix socket: /tmp/gh-ost.sbtest.sbtest1.sock
Copy: 1612500/2607971 61.8%; Applied: 0; Backlog: 0/1000; Time: 4m24s(total), 4m24s(copy); streamer: mysql-bin.000033:180729376; State: migrating; ETA: 2m43s
$ echo "sup" | nc -U /tmp/gh-ost.sbtest.sbtest1.sock
Copy: 1655750/2607971 63.5%; Applied: 0; Backlog: 0/1000; Time: 4m36s(total), 4m36s(copy); streamer: mysql-bin.000033:189291849; State: migrating; ETA: 2m38s
$ echo "coordinates" | nc -U /tmp/gh-ost.sbtest.sbtest1.sock
mysql-bin.000033:140582919
$ echo "chunk-size=500" | nc -U /tmp/gh-ost.sbtest.sbtest1.sock
$ echo "chunk-size=?" | nc -U /tmp/gh-ost.sbtest.sbtest1.sock
500
$ echo "dml-batch-size=?" | nc -U /tmp/gh-ost.sbtest.sbtest1.sock
10
$ echo "max-lag-millis=?" | nc -U /tmp/gh-ost.sbtest.sbtest1.sock
1000
|
20180710使用gh的更多相关文章
- QGIS+GH + MapServer
拒绝描图,如何利用GH+QGIS完爆场地底图?http://www.sohu.com/a/251004986_657084 拒绝描图--爬取OSM数据绘制底图 所用软件 RHINO+GH\QGIS\G ...
- 英语发音规则---gh
英语发音规则---gh 一.总结 一句话总结:gh字母组合的读音在中学英语课本中归纳起来主要有"发音"和"不发音"两种情况. gh字词首是发/g/,因为需要开头 ...
- 【pic+js+gh】免费高速图床方案
本文用到的工具或网站 PicGo jsdelivr github 速度对比 Github的速度: jsdelivrCDN的速度: 下载PicGo 首先进入PicGo的下载地址 选择最新版本下载,根据自 ...
- 2018-07-10 为Chrome和火狐浏览器编写扩展
由于扩展标准的逐渐一致, 现在同一扩展代码库已经有可能同时用于Chrome和火狐. 下面是一个简单的工具栏按钮和弹窗(尚无任何实际功能): 代码库地址: nobodxbodon/suan1 所有代码: ...
- 《SQL Server 2008从入门到精通》--20180710
目录 1.使用Transact-SQL语言编程 1.1.数据定义语言DDL 1.2.数据操纵语言DML 1.3.数据控制语言DCL 1.4.Transact-SQL语言基础 2.运算符 2.1.算数运 ...
- PCBA 生产需要什么文件? (2018-07-10)
PCBA 生产需要什么文件? 生产需要资料 工单套料单 生产说明文件 生产贴片图 正面含元件号 背面含元件号 钢网资料(可以是 Gerber) 元件坐标图
- 逆天通用水印支持Winform,WPF,Web,WP,Win10。支持位置选择(9个位置 ==》[X])
常用技能:http://www.cnblogs.com/dunitian/p/4822808.html#skill 逆天博客:http://dnt.dkil.net 逆天通用水印扩展篇~新增剪贴板系列 ...
- 【原】实时渲染中常用的几种Rendering Path
[原]实时渲染中常用的几种Rendering Path 本文转载请注明出处 —— polobymulberry-博客园 本文为我的图形学大作业的论文部分,介绍了一些Rendering Path,比较简 ...
- 算法与数据结构(八) AOV网的关键路径
上篇博客我们介绍了AOV网的拓扑序列,请参考<数据结构(七) AOV网的拓扑排序(Swift面向对象版)>.拓扑序列中包括项目的每个结点,沿着拓扑序列将项目进行下去是肯定可以将项目完成的, ...
随机推荐
- post和get区别,其他答案真的太坑
原理: get和post都是http定义与服务器交互的方法,还有put,delete url是网络上的资源,那么http中的get,post,put,delete对应的就是对这个资源的查,改,增,删四 ...
- Hdu 4612 Warm up (双连通分支+树的直径)
题目链接: Hdu 4612 Warm up 题目描述: 给一个无向连通图,问加上一条边后,桥的数目最少会有几个? 解题思路: 题目描述很清楚,题目也很裸,就是一眼看穿怎么做的,先求出来双连通分量,然 ...
- linux C编程 Makefile的使用
Makefile的作用就是"自动化编译" 一.Makefile基本规则 下面给出几个简单实例: 第一步:分别用vim创建prog.c code.c code.h三个文件 prog. ...
- map Codeforces Round #Pi (Div. 2) C. Geometric Progression
题目传送门 /* 题意:问选出3个数成等比数列有多少种选法 map:c1记录是第二个数或第三个数的选法,c2表示所有数字出现的次数.别人的代码很短,思维巧妙 */ /***************** ...
- 贪心 UVA 11729 Commando War
题目传送门 /* 贪心:按照执行时间长的优先来排序 */ #include <cstdio> #include <algorithm> #include <iostrea ...
- 程序 从存储卡 内存卡 迁移到 SD卡
程序 从存储卡 内存卡 迁移到 SD卡 如果你想移动其他软件,在应用市场界面,点击“管理 > 应用搬家”,点击需要转移的应用旁边的“移至SD卡”即可.
- Meta标签 h5
一 PC端meta标签 1 页面关键词 <meta name="keywords" content="your tags"> 2 页面描述 < ...
- select count(1) 和 select count(*)的区别
统计一个表T有多少行数据,通常写法是: 查询A:select count(*) from T 但也可以采用下面语句来查: 查询B:select count(1) from T 结果通常是一样的.那么二 ...
- windows server 2008 如何查看异常重启日志
下面蓝队网络为大家介绍下windows server 2008 如何查看异常重启日志 开始->管理工具->时间查看器 windows日志->系统 筛选当前日志 选择Kernel-Po ...
- redis的安装和使用【2】redis的java操作
修改redis.conf# 配置绑定ip,作者机子为192.168.100.192,请读者根据实际情况设置bind 192.168.100.192#非保护模式protected-mode no保存重启 ...