Python机器学习2.2
使用Python实现感知器学习算法
在《Python机器学习》中的2.2节中,创建了罗森布拉特感知器的类,通过fit方法初始化权重self.w_,再fit方法循环迭代样本,更新权重,使用predict方法计算类标,将每轮迭代中错误分类样本的数量存放于列表self.errors_中。罗森布拉特感知器可以参考这个网址或自行百度。https://www.jb51.net/article/130970.htm
import numpy as np
class Perceptron(object):
"""感知器分类器. 参数
----------
eta(学习速率) : float
学习率(介于0和1之间)
n_iter(迭代次数) : int
通过训练数据集. 属性
----------
w_ : id-array
fit方法后的权重.
errors_ : list
每轮迭代错误分类样本的数量存放列表. """
def __init__(self, eta=0.01, n_iter=10):
self.eta = eta
self.n_iter = n_iter def fit(self, X, y):
"""拟合训练数据. 参数
----------
X : {array-like}, shape = {n_samples, n_features}
训练向量, 其中n_samples是样本的数目,
n_features是特征的数目(维数).
y : array-like, shape = {n_samples}
目标值. 返回
----------
self : object """
self.w_ = np.zeros(1 + X.shape[1])
self.errors_ = [] for _ in range(self.n_iter):
errors = 0
for xi, target in zip(X, y):
update = self.eta * (target - self.predict(xi))
self.w_[1:] += update * xi
self.w_[0] += update
errors += int(update != 0.0)
self.errors_.append(errors)
return self def net_input(self, X):
"""Calculate net input"""
return np.dot(X, self.w_[1:]) + self.w_[0] def predict(self, X):
"""每一步后返回类标签"""
return np.where(self.net_input(X) >= 0.0, 1, -1)
Perceptron类
书中选用了鸢尾花数据集中的山鸢尾(Setosa)和变色鸢尾(Versicolor)俩种信息作为测试数据。出于可视化,选取了萼片长度(sepal length)和花瓣长度(petal-length)两个特征。
使用pandas库直接从UCI机器学习库中获取鸢尾花数据集(iris.data)并转换为DataFrame对象加载到内存中,使用tail方法显示数据确保正确加载。
import pandas as pd
df = pd.read_csv('https://archive.ics.uci.edu/ml/'
'machine-learning-databases/iris/iris.data', header=None)
df.tail()
获取iris.data

提取前100个类标,其中山鸢尾(Setosa)和变色鸢尾(Versicolor)各50个,并将类标用两个整数表示:1表示变色鸢尾,-1表示山鸢尾,赋给NumPy的向量y。类似的,提取前100个训练样本的第一个特征列()和第三个特征列(),赋给X。用二位散点图进行可视化。
import matplotlib.pyplot as plt
import numpy as np
#jupyter notebook显示图片
%matplotlib inline
#中文字体显示
plt.rc('font', family='SimHei', size=13) y = df.iloc[0:100, 4].values
y = np.where(y == 'Iris-setosa', -1, 1)
X = df.iloc[0:100, [0,2]].values
plt.scatter(X[:50, 0], X[:50, 1],
color='red', marker='o', label='setosa')
plt.scatter(X[50:100, 0], X[50:100, 1],
color='blue', marker='x', label='versicolor')
plt.xlabel('花瓣长度(cm)')
plt.ylabel('萼片长度(cm)')
plt.legend(loc='upper left')
plt.show()
可视化

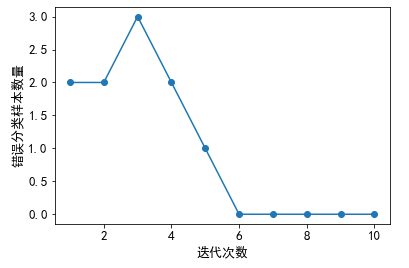
利用抽取的鸢尾花数据子集训练感知器。绘制每次迭代错误分类数量的折线图。
ppn = Perceptron(eta=0.1, n_iter=10)
ppn.fit(X, y)
plt.plot(range(1, len(ppn.errors_) + 1), ppn.errors_,
marker='o')
plt.xlabel('迭代次数')
plt.ylabel('错误分类样本数量')
plt.show()
检验算法
待续。。。
Python机器学习2.2的更多相关文章
- 常用python机器学习库总结
开始学习Python,之后渐渐成为我学习工作中的第一辅助脚本语言,虽然开发语言是Java,但平时的很多文本数据处理任务都交给了Python.这些年来,接触和使用了很多Python工具包,特别是在文本处 ...
- [Python] 机器学习库资料汇总
声明:以下内容转载自平行宇宙. Python在科学计算领域,有两个重要的扩展模块:Numpy和Scipy.其中Numpy是一个用python实现的科学计算包.包括: 一个强大的N维数组对象Array: ...
- 【转】常见的python机器学习工具包比较
http://algosolo.com/ 分析对比了常见的python机器学习工具包,包括: scikit-learn mlpy Modular toolkit for Data Processing ...
- python机器学习《回归 一》
唠嗑唠嗑 依旧是每一次随便讲两句生活小事.表示最近有点懒,可能是快要考试的原因,外加这两天都有笔试和各种面试,让心情变得没那么安静的敲代码,没那么安静的学习算法.搞得第一次和技术总监聊天的时候都不太懂 ...
- 2016年GitHub排名前20的Python机器学习开源项目(转)
当今时代,开源是创新和技术快速发展的核心.本文来自 KDnuggets 的年度盘点,介绍了 2016 年排名前 20 的 Python 机器学习开源项目,在介绍的同时也会做一些有趣的分析以及谈一谈它们 ...
- [resource]Python机器学习库
reference: http://qxde01.blog.163.com/blog/static/67335744201368101922991/ Python在科学计算领域,有两个重要的扩展模块: ...
- Python机器学习包
常用Python机器学习包 Numpy:用于科学计算的包 Pandas:提供高性能,易于使用的数据结构和数据分析工具 Scipy:用于数学,科学工程的软件 StatsModels:用于探索数据.估计统 ...
- python机器学习实战(一)
python机器学习实战(一) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7140974.html 前言 这篇notebook是关于机器 ...
- python机器学习实战(二)
python机器学习实战(二) 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7159775.html 前言 这篇noteboo ...
- python机器学习实战(三)
python机器学习实战(三) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7277205.html 前言 这篇notebook是关于机器 ...
随机推荐
- bzoj 3238: [Ahoi2013]差异【SAM+树形dp】
首先只有lcp(i,j)需要考虑 因为SAM的parent树是后缀的前缀的最长公共后缀(--),所以把这个串倒过来建SAM,这样就变成了求两个前缀的最长公共后缀,长度就是这两个前缀在parent树上的 ...
- PJzhang:贷款逾期与失信被执行人
猫宁!!! 最近看到一家网贷机构在APP上的温馨提示,提到了网贷逾期与个人征信的关系以及向客户发放贷款的7项基本原则. 如下: 贷款申请及逾期告知 尊敬的客户,感谢您选择####股份有限公司为您提供贷 ...
- 51Nod 1174 区间中最大的数(RMQ)
#include <iostream> #include <algorithm> #include <cstring> using namespace std; + ...
- Selenium | 基础入门 | 利用Xpath寻找用户框
以微信公众号登陆界面为例, 找到相对应的Xpath的方法, 核心代码: System.setProperty(“webdriver.chrome.driver”,“ C:\\Program Files ...
- PopupWindow(1)简介
PopupWindow有点类似于Dialog,相同点在于都是弹出窗口,并且都可以对其进行自定义显示,并且里面的监听组件,进行相应的操作,但它与Dialog又有很大的区别,PopupWindow只是弹出 ...
- 496 Next Greater Element I 下一个更大元素 I
给定两个没有重复元素的数组 nums1 和 nums2 ,其中nums1 是 nums2 的子集.找到 nums1 中每个元素在 nums2 中的下一个比其大的值.nums1 中数字 x 的下一个更大 ...
- Super Mario 树状数组离线 || 线段树
Super Mario Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total ...
- rhel6.5--http练习
包名 简介 httpd-2.2.15-29.el6_4.x86_64.rpm http服务的主程序包 httpd-devel-2.2.15-29.el6_4.x86_64.rpm ap ...
- Python 版本对比
python2 与 python3可认为代码不通用,你也可以点击Python2.x与3.x版本区别来查看两者的不同 python3.6以上支持f-string,一种很方便的变量替换方式 高版本可能 ...
- websocket 加layim实现在线聊天系统
实现流程: 1.浏览器连接服务器时保存所有用户id以及对应的唯一session(session用户用户消息推送). 1.1:判断登录用户是否有离线消息(个人消息以及群消息),有则将离线消息进行推送给登 ...