Noisy Channel模型纠正单词拼写错误
本文介绍 Stanford《From Languages to Information》课程中讲到的 单词拼写错误 纠正。背后的数学原理主要是贝叶斯公式。单词拼写错误纠正主要涉及到两个模型:一个是Nosiy Channel模型,它是贝叶斯公式中的似然函数;另一个模型是Language Model,它是贝叶斯公式中的先验概率。
一,问题描述
在这句话中“. . . was called a “stellar and versatile acress whose combination of sass and glamour has defined her. . .”,有一个错误的单词:acress
这个错误单词 acress 对应的 正确单词是哪个呢?是 actress? 还是cress?还是 caress?……
二,出现单词拼写错误的情形
一种是 Non-word spelling errors,它是指:错误的单词 不存在 于词典中。也就说,你键盘输入了一个单词,而这个单词根本没有被英文词典收录,在字典中查不到。比如你将 正确的单词graffe,多打了一个字符 i ,变成了 giraffe,而 英文字典中根本没有 giraffe这个单词。
另一种是 real-word errors,比如:想输入 there are,结果输入成了 three are。而错误单词 three 是存在于字典中的,关键问题是:怎么知道将 three 改成 there 呢?
三,单词拼写错误的纠正步骤
①首先检测出 是哪个单词发生了拼写错误。
这可以通过查字典来实现,比如依次扫描每个单词,若该单词不在词典中(未被词典收录),则认为它是一个拼写错误的单词。显然,词典越大,词典收录的单词越多,我们就越能正确检测出错误的单词。
②其次,是要从一组候选的 正确单词中,选择一个“最准确”的单词,而这个“最准确”的单词,就是要找的结果(错误单词 对应的 正确单词)。
这里有个问题就是:如何找出一组候选的正确单词呢?这就需要根据实际情况进行分析了。以上面提到的错误单词 acress 为例:
本来想输入“across”,但是一不小心将 'o',输入成了'e',结果变成了 "acress", 这是substition 操作:将 'o' 替换成了 'e'
本来想输入 "actress",但是打字太快,漏打了 't',结果变成了"acress",这是deletion操作:删除了 't'
.....
或者说:键盘上字符'm' 和 'n' 很近,打字时,很容易将 'm'替换成了'n';又或者说:'m' 和 'n'发音相似,也导致经常将 'm' 替换成 'n'
而寻找一组候选单词,就可以通过“编辑距离算法”来实现。关于编辑距离,可参考“Damerau-Levenshtein Edit Distance”或者:最短编辑距离算法实现
四,贝叶斯推断 纠正 单词拼写错误
①Noisy Channel Model
Noisy Channel Model的示意图如下:
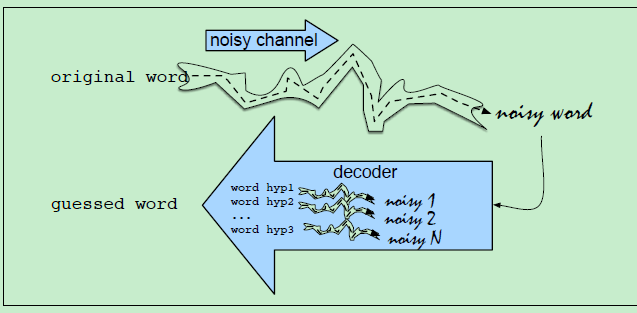
原来的一个正确的单词:经过 noisy channel ,结果变成了一个 noisy word。而这个noisy channel,其实就是前面讲的“两个词发音相近,容易拼错它们",或者"两个字符在键盘上相邻,输入时就会错误地将一个词 输入成了(type) 另一个词。(其实niosy channel就是对现实世界存在的问题的一个建模)
而要想得出错误单词(noisy word) 对应的 正确单词,就需要用到贝叶斯推断。具体原理如下:
既然 noisy word (或者说错误单词,记为 x )已经出现了,那么我们在词典中找一个单词w,在 x 已经出现的条件下,最有可能是由 哪个单词w 造成的?
- We see an observation x (a misspelled word) and our job is to find the word w that generated this misspelled word
- Out of all possible words in the vocabulary V we want to find the
- word w such that P(w|x) is highest. We use the hat notation ˆ to mean “our estimate
- of the correct word”.
用公式(1)表示如下:
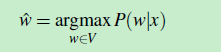 (公式1)
(公式1)
V是词典(Vocabulary),p(w|x)表示:从V中选出一个w,计算概率 P(w|x),概率最大的那个 w,就是 错误单词x 对应的正确单词,将该正确单词记为: wˆ
根据贝叶斯公式法则(公式2):
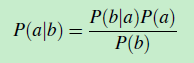
将公式(1)变成如下形式:
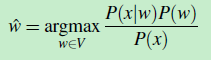 (公式3)
(公式3)
从公式3 可以看出:就是对于 词典V 中的每个单词w,计算 [p(x|w)*p(w)]/p(x),找出 计算结果最大(概率最大) 的那个 w,该 w 就是最优解 wˆ
而在这个计算过程中,可以不需要计算分母p(x),因为这不影响我们 找出 概率最大的那个 w 。因此将 p(x) 视为一个常量值。(这里关于贝叶斯的理解,可参考后面给出的参考文献)
于是我们的公式就变成了:
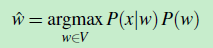 (公式4)
(公式4)
可以看出,公式4 由两部分组成,一部分是 p(x|w),我们称之为 channel model 或者 称为 error model,它就是似然函数
另一部分是 p(w) 我们称之为先验概率(prior)。
另外,值得一提的是这个Vocabulary V,由于Vocabulary中单词个数是很多的,只有在发生某种”条件“的情况下,一个单词才会被误拼写成了另一个单词。换句话说,Vocabulary中的某些词与错误单词 x 之间是”八杆子打不着“的关系,因此我们只在某些Candidate words 中 寻找 [p(x|w)*p(w)] 的那个 w
而这些Candidate words 就是由前面提到的”编辑距离算法“生成。因此,公式可继续变成(注意 argmax 的下标的变化。V变成了C,而C就是 Candidate words的集合)
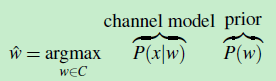
因此,现在的问题变成了:如何求出channel model 和 prior呢?
首先介绍下先验概率p(w)的求解(Prior)
我们使用 unigram language model 来作为 p(w)。这里解释一下 unigram language model:
选择一个语料库(词库),这个语料库里面总共有 404253213个单词,然后”编辑距离“算法 根据 错误的单词 acress 生成了一系列的候选词(Candidate words),每一个候选词在语料库中出现的次数count(candidate word) 除以 404253213 就是每个Candidate word的先验概率。如下图所示,第一列是错误单词acress的 候选词,第二列是这些候选词在语料库中出现的次数,第三列是这些候选词在语料库中出现的概率(频率)
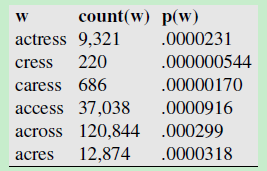
- For this example let’s start in the following table by assuming a unigram language model. We computed the language model from the
- 404,253,213 words in the Corpus of Contemporary English (COCA).
接下来是求解 channel model
个人理解就是:求解channel model需要用到日常生活中用到的知识经验,或者行业应用中累积下来的数据(经验)。
从公式:p(x|w)理解上来看,给定一个正确的候选单词 w 的条件下,导致错误单词x 的概率有多大?
如果我们收集了足够多的数据,比如观察了很多用户一共输入了(打字)1万次 w,其中有10次 输入成了x(打字打成了 x),那么 p(x|w)=0.0001
我们考虑四种出错情况:

del[x,y] 表示,输入 xy 时,少打了字符 'y',结果变成了 x,那么最终得到的单词是一个错误的单词,记录下这种情况下出错的总次数 count(xy typed as x)
trans[x,y]表示,输入 xy 时,输入反了,变成了 yx,那么最终得到的单词是一个错误的单词,记录下这种情况下出错的总次数 count(xy typed as yx)
把这些数据统计起来,放在一个表里面,这个表称为:confusion matrix
比如这个网站(Corpora of misspellings for download)就有一系列的”错误单词的统计数据“。
 ("错误单词" 示意图)
("错误单词" 示意图)
那么根据 confusion matrix,就能计算 似然函数的概率了(也即能求解 channel model 了)

解释一下 if transposition情况:
count[wi wi+1]表示:含有 wi wi+1 字符的所有单词w 的个数;trans[wi ,wi+1 ] 表示,将 wi 与 wi+1 交换的次数。(将wi 与 wi+1 交换后,就变成了一个错误的单词了)
另一种计算 confusion matrix 的方法是 EM算法,这个我也没学,不懂,就不说了。
对于错误的单词 acress,根据下面的7个候选单词计算出来的似然概率如下图:
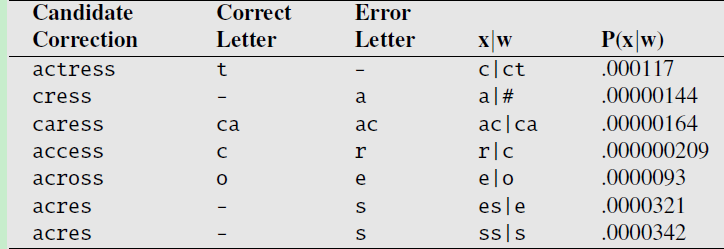
上图中,第一行表示,其中一个正确的候选单词是 actress,正确的单词是 t,由于某种原因(键盘输入太快了,漏打了t,本来是输入ct 的,结果输入成了c ),统计到的这种情形出现的概率是0.000117 。这种原因,其实就是一个deleteion操作而导致的错误。
现在计算出了 似然概率,也计算出了先验概率,二者相乘:p(x|w)*p(w),就得出了正确的候选单词 actress 由于deletion 操作导致 得到错误单词 acress 的概率是 0.000117
同理,计算其它的候选单词 cress、caress、access……的 p(x|w)*p(w)概率,比较一下,哪个概率最大,从上图中看出:across 对应的概率最大,也就是说:应该将 acress 纠正为:across
但是,事实上,从句子”“的意思来看,acress 应该纠正为 actress 更为合理。那上而的channel model 为什么没有给出正确的纠正结果呢?
主要原因是:先验概率是由 unigram language model 得出的,如果采用 bigram language model,那么就能够正确地找出”actress“,从而将acress纠正为actress
下面是使用Contemporary American English语料库训练得到的二元Language Model。对于单词w:actress 和 across,它给出的先验概率p(w)如下:


actress对应的先验概率:p(actress)=p("versatile actress whose")=0.000021*0.0010
across对应的先验概率:p(across)=1*10-10
这样,再将先验概率和似然概率相乘,就能得到正确的单词应该是”actress“,而不是”across“了。
参考文章:
Natural Language Corpus Data: Beautiful Data
Corpora of misspellings for download
理解贝叶斯公式的一系列文章 或者 推荐《A first course in machine learning 》这本书
机器学习中的贝叶斯方法---先验概率、似然函数、后验概率的理解及如何使用贝叶斯进行模型预测(1)
机器学习中的贝叶斯方法---先验概率、似然函数、后验概率的理解及如何使用贝叶斯进行模型预测(2)
使用最大似然法来求解线性模型(2)-为什么是最大化似然函数?
使用最大似然法来求解线性模型(4)-最大化似然函数背后的数学原理
原文:http://www.cnblogs.com/hapjin/p/8012069.html
Noisy Channel模型纠正单词拼写错误的更多相关文章
- 基于Noisy Channel Model和Viterbi算法的词性标注问题
给定一个英文语料库,里面有很多句子,已经做好了分词,/前面的是词,后面的表示该词的词性并且每句话由句号分隔,如下图所示 对于一个句子S,句子中每个词语\(w_i\)标注了对应的词性\(z_i\).现在 ...
- 论文笔记 - Noisy Channel Language Model Prompting for Few-Shot Text Classification
Direct && Noise Channel 进一步把语言模型推理的模式分为了: 直推模式(Direct): 噪声通道模式(Noise channel). 直观来看: Direct ...
- WPF 4 单词拼写检查(SpellCheck)
原文:WPF 4 单词拼写检查(SpellCheck) 在WPF中 Textbox 和RichTextBox 控件都内置了拼写检查属性,但该属性目前默认仅支持English.Spanish. ...
- Actor模型和CSP模型的区别
引用至:http://www.jdon.com/concurrent/actor-csp.html Akka/Erlang的actor模型与Go语言的协程Goroutine与通道Channel代表的C ...
- 12月7日,几个错误,拼写错误,遗漏符号:,记忆有误,max-width的作用。gem mini_magick, simple_form
❌: 1. /Users/chentianwei/jdstore3/jdstore/config/routes.rb:6:in `block in <top (required)>': u ...
- 手把手教你用 Keras 实现 LSTM 预测英语单词发音
1. 动机 我近期在研究一个 NLP 项目,根据项目的要求,需要能够通过设计算法和模型处理单词的音节 (Syllables),并对那些没有在词典中出现的单词找到其在词典中对应的押韵词(注:这类单词类似 ...
- HAN模型理解2
Hierarchical Attention Networks for Document Classification 论文的理解 在论文的摘要中,它提出了论文的两个特点.第一个就是对应文章所有具有的 ...
- Java并发模型(一)
学习资料来自http://ifeve.com/java-concurrency-thread-directory/ 一.多线程 进程和线程的区别: 一个程序运行至少一个进程,一个进程至少包含一个线程. ...
- 4、Java并发性和多线程-并发编程模型
以下内容转自http://ifeve.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B%E6%A8%A1%E5%9E%8B/: 并发系统可以采用多种并发编程模型来实现. ...
随机推荐
- android 通过修改图片像素实现CircleImageView
CircleImageView实现方法有很多种,各有优缺点,因此需要按照不同的场景使用.我们今天使用修改图片像素的方法实现CircleImageView,主要知识点无非是勾股定理和点到圆形的距离. 素 ...
- 「ZJOI2015」地震后的幻想乡 解题报告
「ZJOI2015」地震后的幻想乡 想了半天,打开洛谷题解一看,最高票是_rqy的,一堆密密麻麻的积分差点把我吓跑. 据说有三种解法,然而我只学会了一种最辣鸡的凡人解法. 题意:给一个无向图\(G\) ...
- BZOJ5093图的价值(斯特林数)
题目描述 “简单无向图”是指无重边.无自环的无向图(不一定连通). 一个带标号的图的价值定义为每个点度数的k次方的和. 给定n和k,请计算所有n个点的带标号的简单无向图的价值之和. 因为答案很大,请对 ...
- 随机总数字里面选取随机数字进行随机排序案例(JAVA实现)
随机总数字里面选取随机数字进行随机排序案例,案例如下: 代码code: package com.sec; import java.util.Arrays; import java.util.Scann ...
- User Agent 用户代理
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本.CPU 类型.浏览器及版本.浏览器渲染引擎.浏览器语言.浏览器插件等. User A ...
- Manjaro更新出现冲突
➜ ~ sudo pacman -Syyu :: Synchronizing package databases... core 147.5 KiB 1378K/s 00:00 [########## ...
- 软件补丁问题(SPFA+位运算)
洛谷P2761 1.考虑到所有的错误只有“修复,未修复”两种情况,所以可以用0,1标记压缩状态,采用位运算减少时空浪费. 又考虑到有修复时间的关系,将时间抽象成边,将状态抽象为点(设修复为0,未修复为 ...
- snmpwalk
什么是snmpwalk?snmpwalk是一个SNMP小程序,它使用SNMP的GETNEXT请求查询指定OID(SNMP协议中的对象标识)入口的所有OID树信息,并显示给用户. snmpwalk的作用 ...
- 收藏:win32 控件之 sysLink控件(超链接)
来源:https://blog.csdn.net/dai_jing/article/details/8683487 手动创建syslink(msdn): CreateWindowEx(, WC_LIN ...
- 数据库之sql语句汇总20180616
/*******************************************************************************************/ 一.SQL简 ...