python爬虫慕课基础2
实战演练:爬取百度百科1000个页面的数据

对于新手来说,可以把spider_main.py代码中的try和except去掉,运行报错就会在控制台出现,根据错误去调试自己的程序
发现以下错误:
requests.exceptions.TooManyRedirects: Exceeded 30 redirects
错误提示是requests库有太多的重定向:超过了30个重定向。
查找别人的解决方式:
我是通过steam的appid来进行遍历的,但是steam不是所有appid都对应一个游戏,也就是说有一些是空的。这种情况下steam会重定向至steam主页,就会产生这个问题。
所以,我最终的解决方案就是仅请求不允许重新定向,因为重新定向中没有我需要的信息。在requests请求中添加一个对应的字段就ok了:
req=requests.get(url,headers=header,allow_redirects=False)这样就不会弹出上面的错误提示了,但是也关闭了重定向的功能。
发现以下错误:
Traceback (most recent call last):
File "D:/PycharmProjects/test/baike_spider/spider_main.py", line 39, in <module>
obj_spider.craw(root_url)
File "D:/PycharmProjects/test/baike_spider/spider_main.py", line 20, in craw
new_urls, new_data = self.parser.parse(new_url, html_cont)
TypeError: 'NoneType' object is not iterable
在20行上加入输出
html_cont = self.downloader.download(new_url) # content存放下载的url
print(html_cont)
new_urls, new_data = self.parser.parse(new_url, html_cont)
输出为空None,说明错误在downloader中 使用第三方包requests会导致302重定向问题,原因不明
改为使用urllib的request
成功爬取 生成的html文件直接打开是乱码,用txt打开则正常
加入语句fout.write('<meta charset="utf-8">')后输出正常
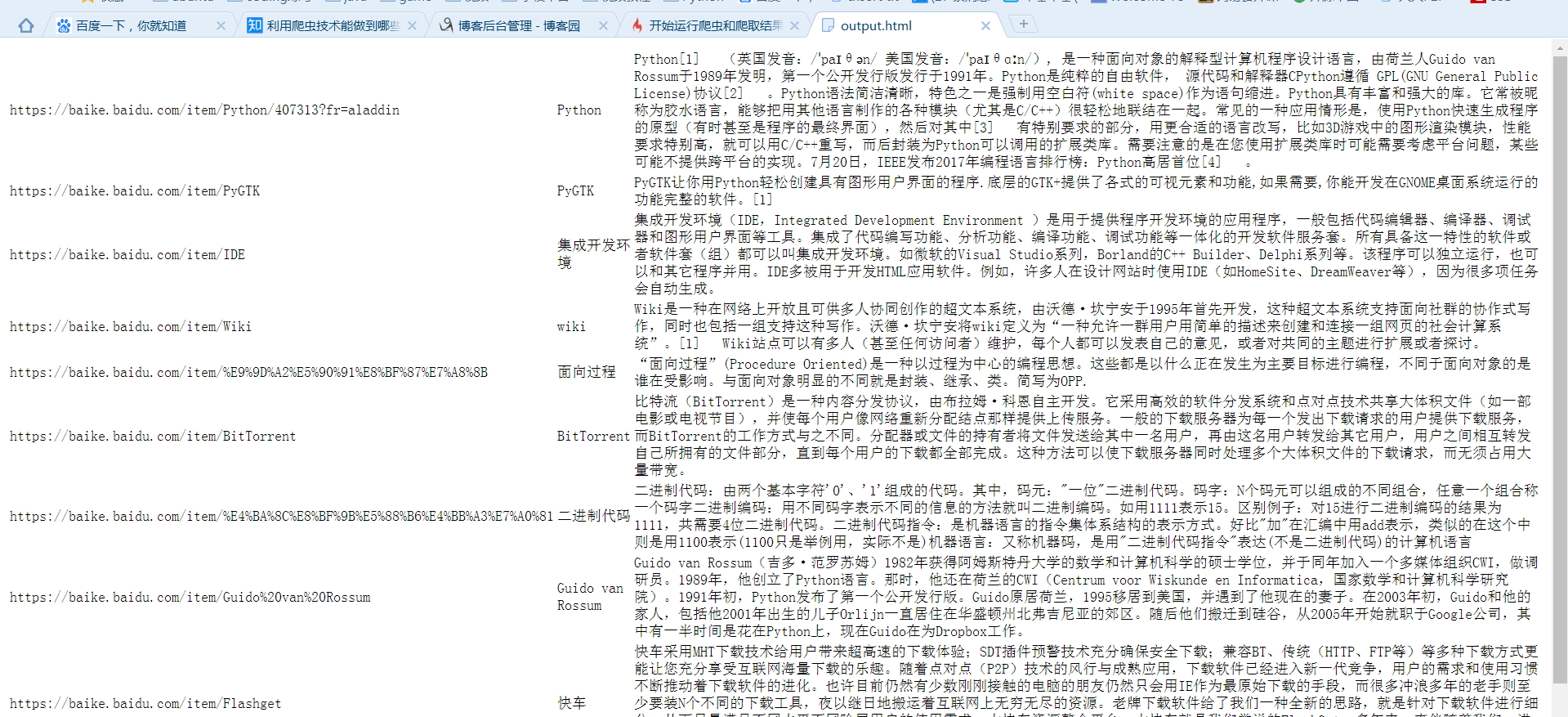
爬取时会遇到两个问题中止程序。a:网址中含有中文,b:有些百科词条中'summary'节点是空的,程序没判断导致get_text出错
a:网址中含有中文使用
url_ = quote(url, safe=string.printable)
解决问题
b:有些百科词条中'summary'节点是空的,程序没判断导致get_text出错添加判断语句解决:
if summary_node is not None:
res_data['summary'] = summary_node.get_text()
查看拼接url:
print('url拼接:', page_url, new_url, new_full_url) # 查看如何拼接
输出为:
url拼接: https://baike.baidu.com/item/Python/407313?fr=aladdin /item/史记·2016?fr=navbar https://baike.baidu.com/item/史记·2016?fr=navbar
可知:
通过正则表达式
links = soup.find_all('a', href=re.compile(r"/item/"))
获得的是/item/及后面部分如/item/史记·2016?fr=navbar
python爬虫慕课基础2的更多相关文章
- python爬虫慕课基础1
test_urllib2.py import http.cookiejar from urllib import request url = "http://www.baidu.com&qu ...
- Python 爬虫四 基础案例-自动登陆github
GET&POST请求一般格式 爬取Github数据 GET&POST请求一般格式 很久之前在讲web框架的时候,曾经提到过一句话,在网络编程中“万物皆socket”.任何的网络通信归根 ...
- python爬虫相关基础概念
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.但是php在实现爬虫中支持多线程和多进程方面做得不好. 2.java ...
- Python爬虫零基础入门(系列)
一.前言上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据.这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据. update ...
- Python爬虫-正则表达式基础
import re #常规匹配 content = 'Hello 1234567 World_This is a Regex Demo' #result = re.match('^Hello\s\d\ ...
- python爬虫之认识爬虫和爬虫原理
python爬虫之基础学习(一) 网络爬虫 网络爬虫也叫网络蜘蛛.网络机器人.如今属于数据的时代,信息采集变得尤为重要,可以想象单单依靠人力去采集,是一件无比艰辛和困难的事情.网络爬虫的产生就是代替人 ...
- Python爬虫入门(1-2):综述、爬虫基础了解
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- Python实战:爬虫的基础
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕 ...
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
随机推荐
- 【BZOJ3771】Triple 生成函数 FFT 容斥原理
题目大意 有\(n\)把斧头,不同斧头的价值都不同且都是\([0,m]\)的整数.你可以选\(1\)~\(3\)把斧头,总价值为这三把斧头的价值之和.请你对于每种可能的总价值,求出有多少种选择方案. ...
- 安装PHP 类库PEAR
PHP扩展与应用库常识 当php项目里没有pear时: 单独安装解决方案 下载下面连接的文件至go-pear.phar.http://pear.php.net/go-pear.phar该文件最好放到P ...
- 【题解】 bzoj2982: combination (Lucas定理)
题面戳我 Solution 板子题 Code //It is coded by ning_mew on 7.25 #include<bits/stdc++.h> #define LL lo ...
- [SPOJ375]QTREE - Query on a tree【树链剖分】
题目描述 给你一棵树,两种操作. 修改边权,查找边权的最大值. 分析 我们都知道,树链剖分能够维护点权. 而且每一条边只有一个,且唯一对应一个儿子节点,那么就把信息放到这个儿子节点上. 注意,lca的 ...
- HR_Hash Tables: Ransom Note
1 题目重点:whole words | case-sensitive #!/bin/python3 import math import os import random import re imp ...
- 牛客练习赛43 Tachibana Kanade Loves Game (简单容斥)
链接:https://ac.nowcoder.com/acm/contest/548/F来源:牛客网 题目描述 立华奏是一个天天打比赛的萌新. 省选将至,萌新立华奏深知自己没有希望进入省队,因此开始颓 ...
- 绝对音乐No.1
最近儿子在练天空之城钢琴曲.为了方便他听久石让的原版,绝对做张cd.另外加入了自己比较喜欢的几首乐曲.在家音响上聆听时发现,不管是中国乐曲,还是西洋乐,都很美,耳朵都出油了.放到网盘供喜爱之人欣赏,喜 ...
- tyvj/joyoi 1336 火车进栈
比原题水了很多(因为原题要高精度) 输出字典序前20种出栈序列. 其实是贪心题:我们每次确定一个出栈的数. 当栈里有数时,字典序显然比从后面拿数要小,所以先搜这个. 之后依次搜后面队列里的数,因为字典 ...
- zabbix监控URL
选在相应主机,并添加Web监控 按照方式新建Web场景 注意: 名称统一规则:web_check_相应的域名 应用集:新建一个,名称为“web状态” 更新间隔:改为30s,默认为1m 尝试次数:改为2 ...
- flask 连接MogoDB数据库
# -*- encoding: utf-8 -*- from flask import Flask,request,jsonify,render_template #导入pymongo来连接mongo ...