hadoop分布式系统架构详解
hadoop 简单来说就是用 java写的分布式 ,处理大数据的框架,主要思想是 “分组合并” 思想。
分组:比如 有一个大型数据,那么他就会将这个数据按照算法分成多份,每份存储在 从属主机上,并且在从属主机上进行计算,主节点主要负责Hadoop两个关键功能模块HDFS、Map Reduce的监督。
合并:将每个机器上的计算结果合并起来 再在一台机器上计算,得到最终结果。这就是mapreduce 算法。
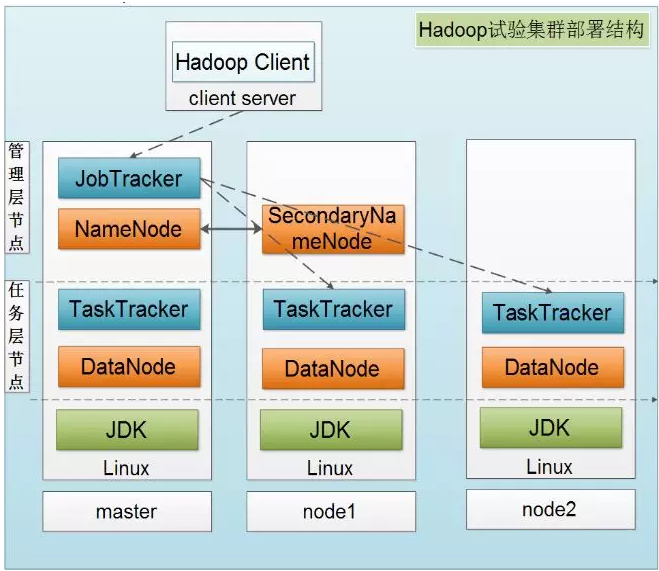
Hadoop主要的任务部署分为3个部分,分别是:Client机器,主节点和从节点。主节点主要负责Hadoop两个关键功能模块HDFS、Map Reduce的监督。当Job Tracker使用Map Reduce进行监控和调度数据的并行处理时,名称节点则负责HDFS监视和调度。从节点负责了机器运行的绝大部分,担当所有数据储存和指令计算的苦差。每个从节点既扮演者数据节点的角色又冲当与他们主节点通信的守护进程。守护进程隶属于Job Tracker,数据节点在归属于名称节点。
1、Hadoop的整体框架
Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等成员组成,其中最基础最重要元素为底层用于存储集群中所有存储节点文件的文件系统HDFS(Hadoop Distributed File System)来执行MapReduce程序的MapReduce引擎。
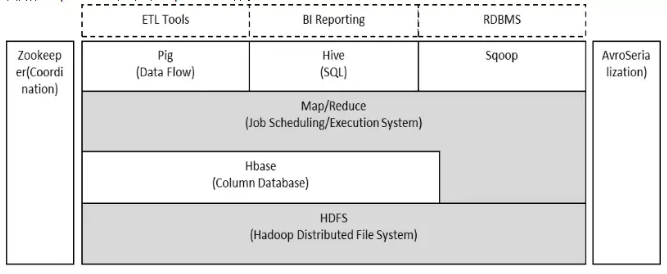
(1)Pig是一个基于Hadoop的大规模数据分析平台,Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口;
(2)Hive是基于Hadoop的一个工具,提供完整的SQL查询,可以将sql语句转换为MapReduce任务进行运行;
(3)ZooKeeper:高效的,可拓展的协调系统,存储和协调关键共享状态;
(4)HBase是一个开源的,基于列存储模型的分布式数据库;
(5)HDFS是一个分布式文件系统,有着高容错性的特点,适合那些超大数据集的应用程序;
(6)MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
下图是一个典型的Hadoop集群的部署结构:
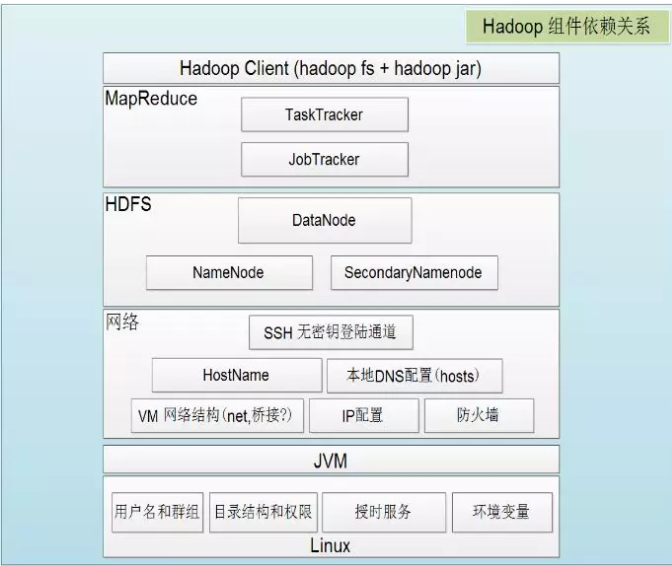
接着给出Hadoop各组件依赖共存关系:
2、Hadoop的核心设计
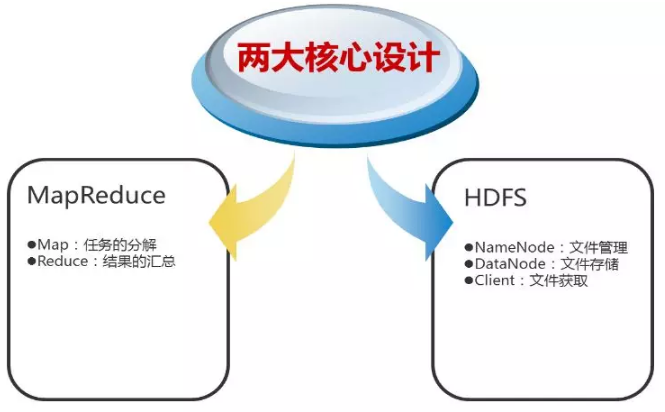
(1)HDFS
HDFS是一个高度容错性的分布式文件系统,可以被广泛的部署于廉价的PC上。它以流式访问模式访问应用程序的数据,这大大提高了整个系统的数据吞吐量,因而非常适合用于具有超大数据集的应用程序中。
HDFS的架构如图所示。HDFS架构采用主从架构(master/slave)。一个典型的HDFS集群包含一个NameNode节点和多个DataNode节点。NameNode节点负责整个HDFS文件系统中的文件的元数据的保管和管理,集群中通常只有一台机器上运行NameNode实例,DataNode节点保存文件中的数据,集群中的机器分别运行一个DataNode实例。在HDFS中,NameNode节点被称为名称节点,DataNode节点被称为数据节点。DataNode节点通过心跳机制与NameNode节点进行定时的通信。
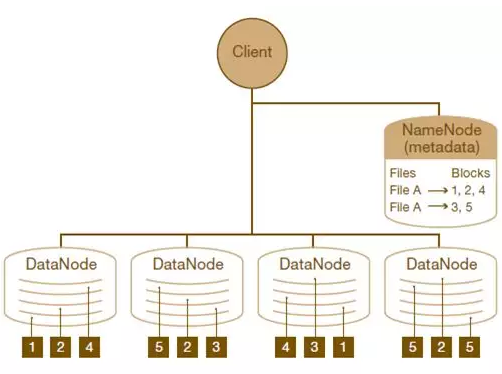
•NameNode
可以看作是分布式文件系统中的管理者,存储文件系统的meta-data,主要负责管理文件系统的命名空间,集群配置信息,存储块的复制。
•DataNode
是文件存储的基本单元。它存储文件块在本地文件系统中,保存了文件块的meta-data,同时周期性的发送所有存在的文件块的报告给NameNode。
•Client
就是需要获取分布式文件系统文件的应用程序。
以下来说明HDFS如何进行文件的读写操作:
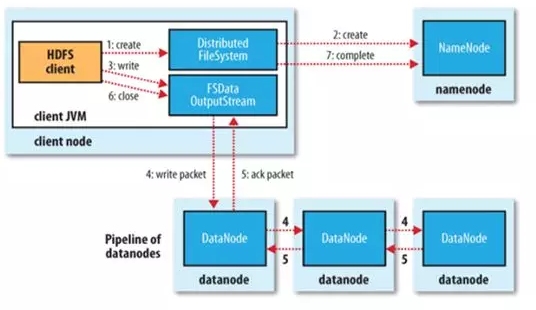
文件写入:
1. Client向NameNode发起文件写入的请求
2. NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
3. Client将文件划分为多个文件块,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
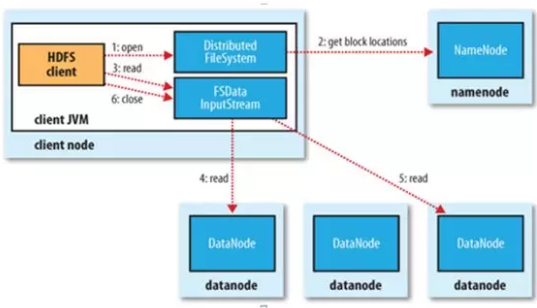
文件读取:
1. Client向NameNode发起文件读取的请求
2. NameNode返回文件存储的DataNode的信息。
3. Client读取文件信息。
(2)MapReduce
MapReduce是一种编程模型,用于大规模数据集的并行运算。Map(映射)和Reduce(化简),采用分而治之思想,先把任务分发到集群多个节点上,并行计算,然后再把计算结果合并,从而得到最终计算结果。多节点计算,所涉及的任务调度、负载均衡、容错处理等,都由MapReduce框架完成,不需要编程人员关心这些内容。
下图是MapReduce的处理过程:
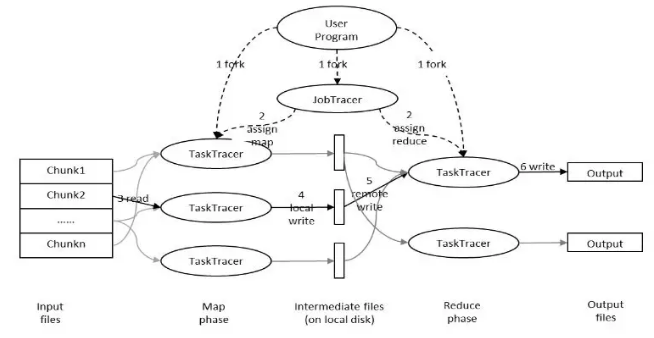
用户提交任务给JobTracer,JobTracer把对应的用户程序中的Map操作和Reduce操作映射至TaskTracer节点中;输入模块负责把输入数据分成小数据块,然后把它们传给Map节点;Map节点得到每一个key/value对,处理后产生一个或多个key/value对,然后写入文件;Reduce节点获取临时文件中的数据,对带有相同key的数据进行迭代计算,然后把终结果写入文件。
如果这样解释还是太抽象,可以通过下面一个具体的处理过程来理解:(WordCount实例)
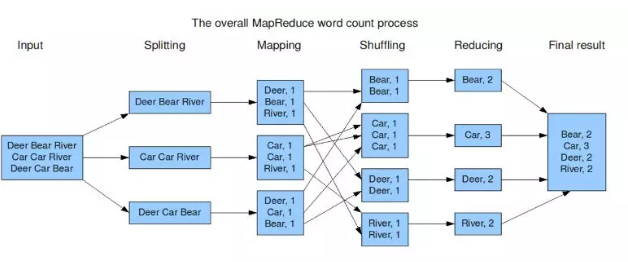
Hadoop的核心是MapReduce,而MapReduce的核心又在于map和reduce函数。它们是交给用户实现的,这两个函数定义了任务本身。
map函数:接受一个键值对(key-value pair)(例如上图中的Splitting结果),产生一组中间键值对(例如上图中Mapping后的结果)。Map/Reduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。
reduce函数:接受一个键,以及相关的一组值(例如上图中Shuffling后的结果),将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)(例如上图中Reduce后的结果)
但是,Map/Reduce并不是万能的,适用于Map/Reduce计算有先提条件:
(1)待处理的数据集可以分解成许多小的数据集;
(2)而且每一个小数据集都可以完全并行地进行处理;
若不满足以上两条中的任意一条,则不适合适用Map/Reduce模式。
hadoop分布式系统架构详解的更多相关文章
- Hadoop RPC机制详解
网络通信模块是分布式系统中最底层的模块,他直接支撑了上层分布式环境下复杂的进程间通信逻辑,是所有分布式系统的基础.远程过程调用(RPC)是一种常用的分布式网络通信协议,他允许运行于一台计算机的程序调用 ...
- hdfs文件系统架构详解
hdfs文件系统架构详解 官方hdfs分布式介绍 NameNode *Namenode负责文件系统的namespace以及客户端文件访问 *NameNode负责文件元数据操作,DataNode负责文件 ...
- Zookeeper系列二:分布式架构详解、分布式技术详解、分布式事务
一.分布式架构详解 1.分布式发展历程 1.1 单点集中式 特点:App.DB.FileServer都部署在一台机器上.并且访问请求量较少 1.2 应用服务和数据服务拆分 特点:App.DB.Fi ...
- Hyperledger Fabric架构详解
区块链开源实现HYPERLEDGER FABRIC架构详解 区块链开源实现HYPERLEDGER FABRIC架构详解 2018年5月26日 陶辉 Comments 10 Comments hyper ...
- hadoop之mapreduce详解(进阶篇)
上篇文章hadoop之mapreduce详解(基础篇)我们了解了mapreduce的执行过程和shuffle过程,本篇文章主要从mapreduce的组件和输入输出方面进行阐述. 一.mapreduce ...
- hadoop之yarn详解(框架进阶篇)
前面在hadoop之yarn详解(基础架构篇)这篇文章提到了yarn的重要组件有ResourceManager,NodeManager,ApplicationMaster等,以及yarn调度作业的运行 ...
- 【转载】Hadoop历史服务器详解
免责声明: 本文转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除. 原文作者:过往记忆(http://www.iteblog.com/) 原文地址: ...
- NopCommerce源码架构详解--初识高性能的开源商城系统cms
很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从中学习很多企业系统.软件开发的规范和一些新的技术.技巧,可以快速地提高我们 ...
- 领域驱动设计(Domain Driven Design)参考架构详解
摘要 本文将介绍领域驱动设计(Domain Driven Design)的官方参考架构,该架构分成了Interfaces.Applications和Domain三层以及包含各类基础设施的Infrast ...
随机推荐
- AJAX问题 XMLHttpRequest.status = 0是什么含义
在调用AJAX的时候遇到了XMLHttpRequest. status为0 的情况,http协议里可是没这个状态码的,众所周知,XMLHttpRequest. Status为HTTP请求状态码,一般为 ...
- WIN10 企业版 LTSC 激活
Windows10 企业版长期服务支持分支版本: Windows 10 LTSC 2019 WIN+X 选POWERSHELL 管理员版本 输入以下 slmgr -ipk M7XTQ-FN8P6-TT ...
- PHP操作Redis常用技巧总结
一.Redis连接与认证 //连接参数:ip.端口.连接超时时间,连接成功返回true,否则返回false $ret = $redis->connect('127.0.0.1', 6379, 3 ...
- Python:Day43 抽屉
1.关于inline-block和float的理解 inline-block和float都可以实现块级标签放在同一行上,inline不好设置左右对齐,只能通过margin和padding调节.而flo ...
- PHP交互数据库
教程 图形化界面访问自己的服务器上数据库 http://ip/phpmyadmin php文件 运行 <?php $servername = "localhost"; $us ...
- Python框架学习之Flask中的常用扩展包
Flask框架是一个扩展性非常强的框架,所以导致它有非常多的扩展包.这些扩展包的功能都很强大.本节主要汇总一些常用的扩展包. 一. Flask-Script pip install flask-scr ...
- 使用BBED跳过归档进行恢复
https: 使用BBED跳过归档进行恢复 数据库启动异常,提示6号文件丢失 SQL> startup ORACLE instance started. Total System Global ...
- IDEA+TestNG
1.常用注解 2.手把手教你掌握必备测试框架testNG:http://www.51testing.com/zhuanti/TestNG.htm [testNG常用注解] 1 @Test:标记一个类或 ...
- 无线智联-程序篇:让python与matlab牵手
python和matlab本来是青梅竹马的好基友,奈何相爱相杀,经常放在一起做对比,就好比经常听到的,“你看看隔壁xx家的孩子”,其实每个孩子都有每个孩子的优点,如果能发挥每个孩子的优点,岂不是更好. ...
- [MicroPython]TurniBit开发板旋转按钮控制脱机摆动
一.实验目的: ?学习在PC机系统中扩展简单I/O 接口的方法 ?学习TurnipBit拼插编程 ?了解舵机工作原理 ?学习TurnipBit扩展板舵机和旋转按钮接线方式 二.所需原器件: ?Turn ...