068 mapWithState函数的讲解
1.问题
主要是updateStateByKey的问题
有的值不需要变化的时候,还会再打印出来。
每个批次的数据都会出现,如果向redis保存更新的时候,会把不需要变化的值也更新,这个不是我们需要的,我们只需要更新有变化的那部分值。
2.mapWithState
有一个注解,说明是实验性质的。
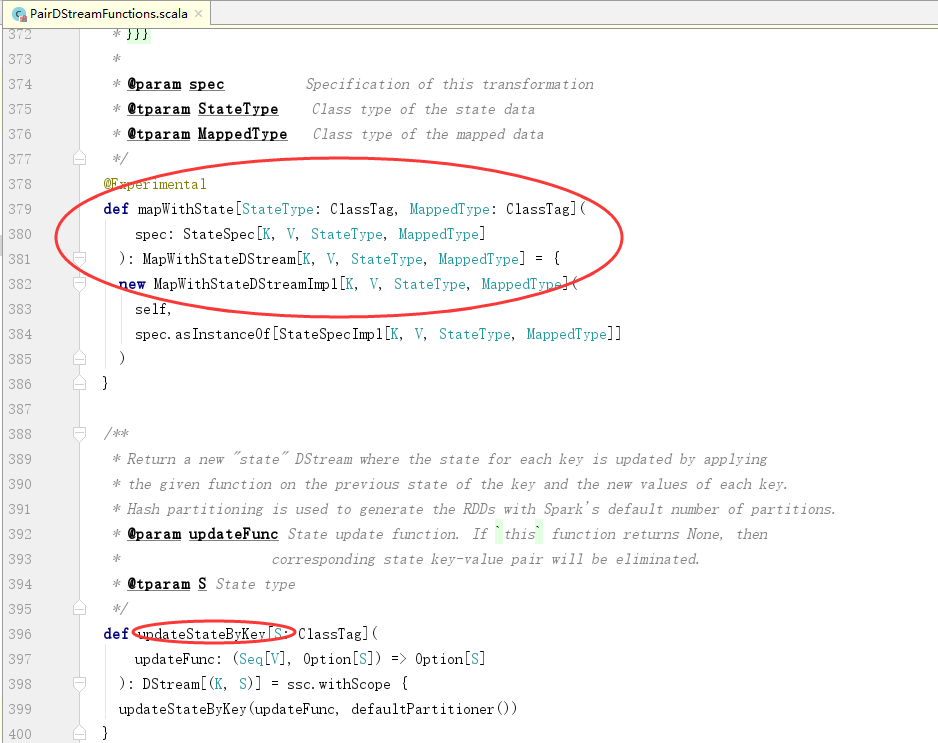
3.程序
package com.stream.it
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, State, StateSpec, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object MapWithState {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("StreamingMapWithState")
.setMaster("local[*]")
val sc = SparkContext.getOrCreate(conf)
val ssc = new StreamingContext(sc, Seconds(1))
// 当调用updateStateByKey函数API的时候,必须给定checkpoint dir
// 路径对应的文件夹不能存在
ssc.checkpoint("hdfs://linux-hadoop01.ibeifeng.com:8020/beifeng/spark/streaming/chkdir45254") /**
*
* @param key DStream的key数据类型
* @param values DStream的value数据类型
* @param state 是StreamingContext中之前该key的状态值
* @return
*/
def mappingFunction(key: String, values: Option[Int], state: State[Long]): (String, Long) = {
// 获取之前状态的值
val preStateValue = state.getOption().getOrElse(0L)
// 计算出当前值
val currentStateValue = preStateValue + values.getOrElse(0) // 更新状态值
state.update(currentStateValue) // 返回结果
(key, currentStateValue)
}
val spec = StateSpec.function[String, Int, Long, (String, Long)](mappingFunction _) val kafkaParams = Map(
"group.id" -> "streaming-kafka-001231",
"zookeeper.connect" -> "linux-hadoop01.ibeifeng.com:2181/kafka",
"auto.offset.reset" -> "smallest"
)
val topics = Map("beifeng" -> 4) // topics中value是读取数据的线程数量,所以必须大于等于1
val dstream = KafkaUtils.createStream[String, String, kafka.serializer.StringDecoder, kafka.serializer.StringDecoder](
ssc, // 给定SparkStreaming上下文
kafkaParams, // 给定连接kafka的参数信息 ===> 通过Kafka HighLevelConsumerAPI连接
topics, // 给定读取对应topic的名称以及读取数据的线程数量
StorageLevel.MEMORY_AND_DISK_2 // 指定数据接收器接收到kafka的数据后保存的存储级别
).map(_._2) val resultWordCount: DStream[(String, Long)] = dstream
.filter(line => line.nonEmpty)
.flatMap(line => line.split(" ").map((_, 1)))
.reduceByKey(_ + _)
.mapWithState(spec) resultWordCount.print() // 这个也是打印数据 // 启动开始处理
ssc.start()
ssc.awaitTermination() // 等等结束,监控一个线程的中断操作
}
}
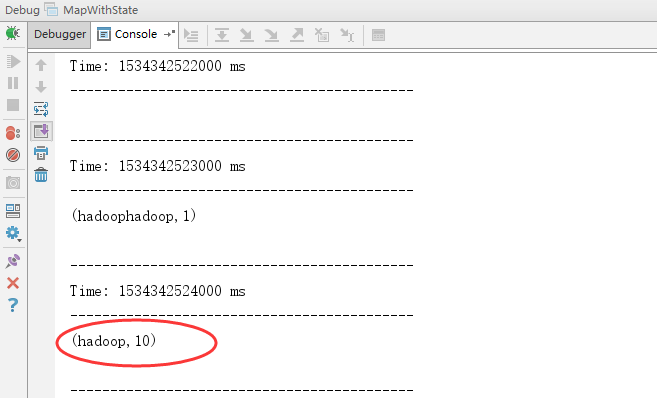
4.效果

在控制台上再写入一个hadoop:
说明了,在新写入的时候,才会出现,但是以前的数据还在。
5.说明
因为存在checkpoint,在重新后,以前的数据还在,新加入数据后,会在原有的基础上进行更新,上面的第二幅图就是这样产生的。
068 mapWithState函数的讲解的更多相关文章
- sparkStreaming的mapWithState函数【案例二】
sparkStreaming是以连续bathinterval为单位,进行bath计算,在流式计算中,如果我们想维护一段数据的状态,就需要持久化上一段的数据,sparkStreaming提供的Mapwi ...
- python format函数/print 函数详细讲解(4)
在python开发过程中,print函数和format函数使用场景特别多,下面分别详细讲解两个函数的用法. 一.print函数 print翻译为中文指打印,在python中能直接输出到控制台,我们可以 ...
- (转)浅析epoll – epoll函数深入讲解
原文地址:http://www.cppfans.org/1418.html 浅析epoll – epoll函数深入讲解 前一篇大致讲了一下epoll是个什么东西,优点等内容,这篇延续上一篇的内容,主要 ...
- Mysql学习总结(5)——MySql常用函数大全讲解
MySQL数据库中提供了很丰富的函数.MySQL函数包括数学函数.字符串函数.日期和时间函数.条件判断函数.系统信息函数.加密函数.格式化函数等.通过这些函数,可以简化用户的操作.例如,字符串连接函数 ...
- MySQL常用函数大全讲解
MySQL数据库中提供了很丰富的函数.MySQL函数包括数学函数.字符串函数.日期和时间函数.条件判断函数.系统信息函数.加密函数.格式化函数等.通过这些函数,可以简化用户的操作.例如,字符串连接函数 ...
- PHP 函数实例讲解
PHP 函数 PHP 的真正威力源自于它的函数. 在 PHP 中,提供了超过 1000 个内建的函数. PHP 内建函数 如需查看所有数组函数的完整参考手册和实例,请访问我们的 PHP 参考手册. P ...
- NULLIF()函数使用讲解
NULLIF()函数接受两个参数.如果它们相等,那么返回空值:否则,返回第一个参数. 等价于下面的表达式: case when expression1=expression2 then null el ...
- C++ string类及其函数的讲解
文章来源于:http://www.cnblogs.com/hailexuexi/archive/2012/02/01/2334183.html C++中string是标准库中一种容器,相当于保存元素类 ...
- c/c++中main函数参数讲解
参考地址: http://blog.csdn.net/cnctloveyu/article/details/3905720 我们经常用的main函数都是不带参数的.因此main 后的括号都是空括号.实 ...
随机推荐
- [转]GitHub上优秀的Go开源项目
转载于GitHub上优秀的Go开源项目 正文 近一年来,学习和研究Go语言,断断续续的收集了一些比较优秀的开源项目,这些项目都非常不错,可以供我们学习和研究Go用,从中可以学到很多关于Go的使用.技巧 ...
- [转]Java微服务框架选型(Dubbo 和 Spring Cloud?)
转载于 http://www.cnblogs.com/xishuai/p/dubbo-and-spring-cloud.html 微服务(Microservices)是一种架构风格,一个大型复杂软件应 ...
- ubuntu18.04安装xmind8
1.先去官网下载:https://www.xmind.net/download/xmind8/ 2.默认下载到/home/guojihai/下载/目录下然后把xmind-8-update8-linux ...
- 浅谈深度优先和广度优先(scrapy-redis)
首先先谈谈深度优先和广度优先的定义 深度优先搜索算法(英语:Depth-First-Search,DFS)是一种用于遍历或搜索树或图的算法.沿着树的深度遍历树的节点,尽可能深的搜索树的分支.当节点v的 ...
- django的内置信号
Model singnalspre_init 在model执行构造方法之前自动触发post_init django的model在执行构造方法之后,自动触发pre_save django的对象保存之前, ...
- JAVA 语言如何进行异常处理,关键字: throws,throw,try,catch,finally分别代表什么意义? 在try块中可以抛 出异常吗?
Java通过面向对象的方法进行异常处理,把各种不同的异常进行分类, 并提供了良好的接口. 在 Java中,每个异常都是一个对象,它是 Throwable 类或其它子类的实例.当一个方法出 ...
- 使用open live writer客户端写博客
注:Windows Live Writer 已经停止更新,建议安装 Open Live Writer,下载地址: http://openlivewriter.org/ 使用open live writ ...
- Confluence 6 后台中的默认空间模板设置
Confluence 6 后台中的默认空间模板设置界面的布局. https://www.cwiki.us/display/CONFLUENCEWIKI/Customizing+Default+Spac ...
- Ribbon服务消费者
springcloud使用到两种消费工具,ribbon和feign ribbon实现了服务的负载均衡 feign默认集成了ribbon,一般情况下使用feign作为消费端 搭建消费者项目(Ribbon ...
- mysql 安装问题一:由于找不到MSVCR120.dll,无法继续执行代码.重新安装程序可能会解决此问题。
这种错误是由于未安装 vcredist 引起的 下载 vcredist 地址:https://www.microsoft.com/zh-CN/download/details.aspx?id= ...