pytorch学习-AUTOGRAD: AUTOMATIC DIFFERENTIATION自动微分
参考:https://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html#sphx-glr-beginner-blitz-autograd-tutorial-py
AUTOGRAD: AUTOMATIC DIFFERENTIATION
PyTorch中所有神经网络的核心是autograd包。让我们先简单地看一下这个,然后我们来训练我们的第一个神经网络。
autograd包为张量上的所有操作提供自动微分。它是一个按运行定义的框架,这意味着的、该支持是由代码的运行方式定义的,并且每个迭代都可以是不同的。
让我们用更简单的术语和一些例子来看看。
Tensor
torch.Tensor是包的中心类。如果将其属性.requires_grad设置为True,它将开始跟踪其上的所有操作。当你完成计算时,你可以调用 .backward()函数并自动计算所有的梯度。这个张量的梯度将累积为.grad属性。
要阻止张量跟踪历史,可以调用.detach()将其从计算历史中分离出来,并防止跟踪未来的计算。
为了防止跟踪历史(和使用内存),还可以使用torch.no_grad():将代码块封装起来。这在评估模型时特别有用,因为模型可能有requires_grad=True的可训练参数,但我们不需要梯度。
还有一个类对autograd实现非常重要—— 即函数。
张量和函数是相互联系的,并建立一个无环图,它编码了一个完整的计算历史。每个张量都有一个.grad_fn属性,该属性引用一个创建了张量的函数(用户创建的张量除外 —— 它们的grad_fn为None)。
如果你想计算导数,你可以在一个张量上调用 .backward() 。如果张量是一个标量(即它包含一个元素数据),你不需要指定任何参数给 .backward() ,但是如果它有更多的元素,你需要指定一个梯度参数,这是一个匹配形状的张量。
- import torch
创建一个tensor x并设置requires_grad=True去追踪其计算;然后进行加法操作得到y, 这时候就能够查看y的.grad_fn属性去得到其计算的说明:
- #-*- coding: utf- -*-
- from __future__ import print_function
- import torch
- x = torch.ones(, , requires_grad=True)
- print(x)
- y = x +
- print(y)
- print(y.grad_fn)
返回:
- (deeplearning) userdeMBP:pytorch user$ python test.py
- tensor([[., .],
- [., .]], requires_grad=True)
- tensor([[., .],
- [., .]], grad_fn=<AddBackward0>)
- <AddBackward0 object at 0x101816358>
上面的最后的返回结果AddBackward0说明了该y是经过加法操作获得的
还可以进行更多的操作:
- #-*- coding: utf- -*-
- from __future__ import print_function
- import torch
- x = torch.ones(, , requires_grad=True)
- y = x +
- z = y * y *
- out = z.mean()
- print(z)
- print(out)
返回:
- (deeplearning) userdeMBP:pytorch user$ python test.py
- tensor([[., .],
- [., .]], grad_fn=<MulBackward0>)
- tensor(., grad_fn=<MeanBackward1>)
可以看出来z是乘法操作得出的,out是求平均值操作得出的
.requires_grad_( ... )函数会改变现存的Tensor的内置requires_grad标签。如果没设置,这个标签默认为False,即不计算梯度
- #-*- coding: utf- -*-
- from __future__ import print_function
- import torch
- a = torch.randn(, )
- a = ((a * ) / (a - ))
- print(a)
- print(a.requires_grad)
- a.requires_grad_(True)
- print(a)
- print(a.requires_grad)
- b = (a * a).sum()
- print(b)
- print(b.grad_fn)
返回:
- (deeplearning) userdeMBP:pytorch user$ python test.py
- tensor([[20.8490, -1.7316],
- [ 1.4831, -2.8223]])
- False
- tensor([[20.8490, -1.7316],
- [ 1.4831, -2.8223]], requires_grad=True)
- True
- tensor(447.8450, grad_fn=<SumBackward0>)
- <SumBackward0 object at 0x10c381400>
Gradients梯度
因为out中只包含了一个标量,out.backward()和out.backward(torch.tensor(1.))的值是相同的
- #-*- coding: utf- -*-
- from __future__ import print_function
- import torch
- x = torch.ones(, , requires_grad=True)
- y = x +
- z = y * y *
- out = z.mean()
- print(out)
- out.backward()
- print(x.grad) # 得到out相对于x的梯度d(out)/dx
返回:
- (deeplearning) userdeMBP:pytorch user$ python test.py
- tensor(., grad_fn=<MeanBackward1>)
- tensor([[4.5000, 4.5000],
- [4.5000, 4.5000]])
省略计算步骤
你应该得到值为4.5的矩阵。让我们将out称为Tensor "o"。o的计算公式为o=1/4 ∑izi,zi=3(xi+2)2且 zi∣xi=1=27。因此o对xi求导为 ∂o/∂xi=3/2(xi+2), 带入xi=1,则得到值4.5.
数学上,如果你有一个向量值函数 y⃗ =f(x⃗),那么 y⃗相对于 x⃗的梯度就是一个Jacobian矩阵:
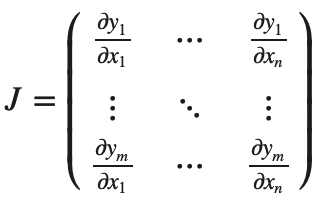
一般来说,torch.autograd是一个计算vector-Jacobian矩阵乘积的引擎。也就是说,给定任意向量v=(v1v2⋯vm)T,计算vT⋅J。
如果v是一个标量函数 l=g(y⃗)的梯度,那么v为 v=(∂l/∂y1⋯∂l/∂ym)T,根据链式法则,vector-Jacobian矩阵乘积就是l相对与x的梯度: 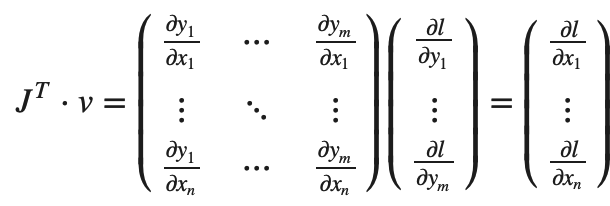
⚠️vT⋅J给出一个行向量,通过 JT⋅v该行向量可以被视为列向量
vector-Jacobian矩阵乘积的这种特性使得将外部梯度输入具有非标量输出的模型变得非常方便。
现在让我们看一个vector-Jacobian矩阵乘积的例子:
- #-*- coding: utf- -*-
- from __future__ import print_function
- import torch
- x = torch.randn(, requires_grad=True)
- print(x)
- y = x *
- print(y)
- while y.data.norm() < : #归一化
- y = y *
- print(y)
返回:
- (deeplearning) userdeMBP:pytorch user$ python test.py
- tensor([0.6542, 0.1118, 0.1979], requires_grad=True)
- tensor([1.3084, 0.2236, 0.3958], grad_fn=<MulBackward0>)
- tensor([1339.8406, 229.0077, 405.2867], grad_fn=<MulBackward0>)
在这种情况下,y不再是标量。 torch.autograd不能直接计算出整个Jacobian矩阵,但是如果我们只想要vector-Jacobian矩阵乘积,只需将向量作为参数向后传递:
- #-*- coding: utf- -*-
- from __future__ import print_function
- import torch
- x = torch.randn(, requires_grad=True)
- print(x)
- y = x *
- print(y)
- while y.data.norm() < : #归一化
- y = y *
- v = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
- y.backward(v)
- print(x.grad)
返回:
- (deeplearning) userdeMBP:pytorch user$ python test.py
- tensor([-0.7163, 1.6850, -0.0286], requires_grad=True)
- tensor([-1.4325, 3.3700, -0.0572], grad_fn=<MulBackward0>)
- tensor([1.0240e+02, 1.0240e+03, 1.0240e-01])
你可以通过使用with torch.no_grad():来封装代码块去阻止带有.requires_grad=True配置的Tensors的autograd去追踪历史:
- #-*- coding: utf- -*-
- from __future__ import print_function
- import torch
- x = torch.randn(, requires_grad=True)
- print(x.requires_grad)
- print((x ** ).requires_grad)
- with torch.no_grad():
- print((x ** ).requires_grad)
返回:
- (deeplearning) userdeMBP:pytorch user$ python test.py
- True
- True
- False
有关autograd和Function的文档可见https://pytorch.org/docs/autograd
pytorch学习-AUTOGRAD: AUTOMATIC DIFFERENTIATION自动微分的更多相关文章
- Pytorch学习(一)—— 自动求导机制
现在对 CNN 有了一定的了解,同时在 GitHub 上找了几个 examples 来学习,对网络的搭建有了笼统地认识,但是发现有好多基础 pytorch 的知识需要补习,所以慢慢从官网 API进行学 ...
- PyTorch Tutorials 2 AUTOGRAD: AUTOMATIC DIFFERENTIATION
%matplotlib inline Autograd: 自动求导机制 PyTorch 中所有神经网络的核心是 autograd 包. 我们先简单介绍一下这个包,然后训练第一个简单的神经网络. aut ...
- 【pytorch】pytorch学习笔记(一)
原文地址:https://pytorch.org/tutorials/beginner/deep_learning_60min_blitz.html 什么是pytorch? pytorch是一个基于p ...
- (转)自动微分(Automatic Differentiation)简介——tensorflow核心原理
现代深度学习系统中(比如MXNet, TensorFlow等)都用到了一种技术——自动微分.在此之前,机器学习社区中很少发挥这个利器,一般都是用Backpropagation进行梯度求解,然后进行SG ...
- Autograd:自动微分
Autograd 1.深度学习的算法本质上是通过反向传播求导数,Pytorch的Autograd模块实现了此功能:在Tensor上的所有操作,Autograd都能为他们自动提供微分,避免手动计算导数的 ...
- PyTorch自动微分基本原理
序言:在训练一个神经网络时,梯度的计算是一个关键的步骤,它为神经网络的优化提供了关键数据.但是在面临复杂神经网络的时候导数的计算就成为一个难题,要求人们解出复杂.高维的方程是不现实的.这就是自动微分出 ...
- 自动微分(AD)学习笔记
1.自动微分(AD) 作者:李济深链接:https://www.zhihu.com/question/48356514/answer/125175491来源:知乎著作权归作者所有.商业转载请联系作者获 ...
- 理解PyTorch的自动微分机制
参考Getting Started with PyTorch Part 1: Understanding how Automatic Differentiation works 非常好的文章,讲解的非 ...
- PyTorch 自动微分示例
PyTorch 自动微分示例 autograd 包是 PyTorch 中所有神经网络的核心.首先简要地介绍,然后训练第一个神经网络.autograd 软件包为 Tensors 上的所有算子提供自动微分 ...
随机推荐
- call,apply,bind的用法与区别
1.call/apply/bind方法的来源 首先,在使用call,apply,bind方法时,我们有必要知道这三个方法究竟是来自哪里?为什么可以使用的到这三个方法? call,apply,bind这 ...
- JS对url进行编码和解码(三种方式区别)
Javascript语言用于编码的函数,一共有三个,最古老的一个就是escape().虽然这个函数现在已经不提倡使用了,但是由于历史原因,很多地方还在使用它,所以有必要先从它讲起. escape 和 ...
- 小tips:JS语法之标签(label)
JavaScript语言允许,语句的前面有标签(label),相当于定位符,用于跳转到程序的任意位置,标签的格式如下. label: statement 标签可以是任意的标识符,但是不能是保留字,语句 ...
- docker swarm 集群进入某节点容器失败的原因及解决方法
今日在自己的docker swarm 测试环境中,想进入某个节点的容器去查看下,结果进入容器失败,并且报了如下错误信息: [root@worker1 ~]# docker exec -it 9a6f6 ...
- 生产者、消费者模型---Queue类
Queue队列在几乎每种编程语言都会有,python的列表隐藏的一个特点就是一个后进先出(LIFO)队列.而本文所讨论的Queue是python标准库queue中的一个类.它的原理与列表相似,但是先进 ...
- (后端)mybatis中使用Java8的日期LocalDate、LocalDateTime
原文地址:https://blog.csdn.net/weixin_38553453/article/details/75050632 MyBatis的型处理器是属性“createdtime参数映射为 ...
- HDU 1212 Big Number(C++ 大数取模)(java 大数类运用)
Big Number 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1212 ——每天在线,欢迎留言谈论. 题目大意: 给你两个数 n1,n2.其中n1 ...
- 2步安装1个hive docker运行环境[centos7]
1 构建基础容器 基于centos环境docker环境快速搭建,执行步骤 docker build -t cenosbase7 . 执行此步骤就可以构建1个基础的centos基础运行环境 相关的文件如 ...
- Eclipse启动时发生An internal error occurred duri ng: "Initializing Java Tooling ----网上的坑爹的一个方法
补充一下: 上面的方法不行. 我的个人解决方法 出现这种问题的原因,我的是eclipse换了,工作目录还是用之前的那个 把build Automatically的钩去掉 假设我们是用之前的worksp ...
- 解决ubuntu下,QQ重启后出现个人文件夹已被占用的问题
首先,是wine QQ的安转教程:Wine安装最新版QQ(8.9.2)的简单教程 - Powered by Discuz! 里面作者也提到了关于重启后出现个人文件夹被占用的情况. 如下: 这里,如果不 ...