scrapy入门与进阶
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
- Scrapy 使用了 Twisted异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
scrapy流程图
旧版
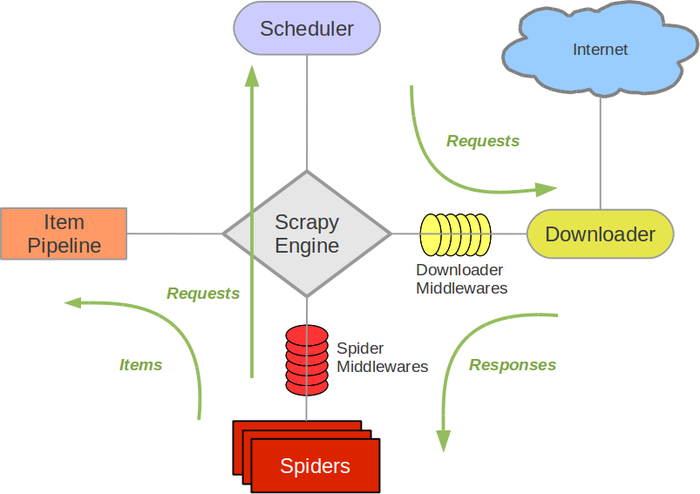
新版
组件及调用流程(数据流)
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
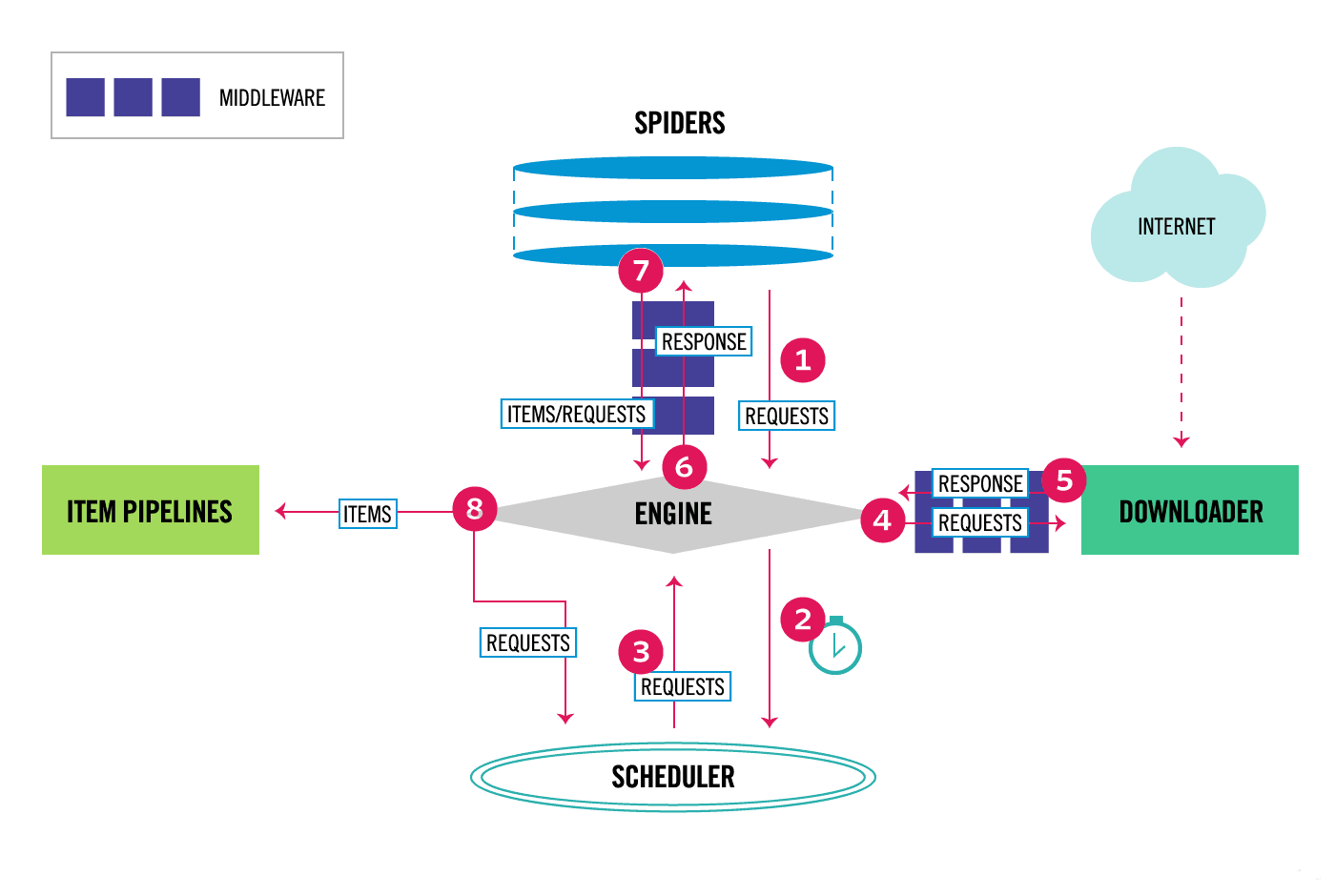
数据流(Data flow)
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
引擎获取起始url并发起请求,将获取的响应内容返回给spider,
在spider中进行数据的提取和下一个url的链接,
数据交给item和pipeline进行处理,
url继续发起请求,
编写spider
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
命令行输入
scrapy startproject tutorial
目录结构
scrapy.cfg: 项目的配置文件;(用于发布到服务器)
tutorial/: 该项目文件夹。之后将在此编写Python代码。
tutorial/items.py: 项目中的item文件;(定义结构化数据字段field).
tutorial/pipelines.py: 项目中的pipelines文件;(用于存放执行后期数据处理的功能,定义如何存储结构化数据)
tutorial/settings.py: 项目的设置文件;(如何修改User-Agent,设置爬取时间间隔,设置代理,配置中间件等等)
tutorial/spiders/: 放置spider代码的目录;(编写爬取网站规则)
定义item,在items.py文件中编写item
类似与django
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
编写spider
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
为了创建一个Spider,您必须继承 scrapy.Spider 类, 且定义一些属性:
name: 用于区别Spider。 该名字必须是唯一的。start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。parse()是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
scrapy genspider name "example.com"
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2] + '.html'
with open(filename, 'wb') as f:
f.write(response.body)
启动爬虫
scrapy crawl dmoz
提取Item
Selectors选择器简介
https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/selectors.html
Scrapy Selectors 内置XPath 和 CSS Selector 表达式机制
Selector有四个基本的方法:
- xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表
- extract(): 序列化该节点为Unicode字符串并返回list
- css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表,语法同 BeautifulSoup4
- re(): 根据传入的正则表达式对数据进行提取,返回Unicode字符串list列表
通过shell可以很方便的提取出需要的数据
Item Pipelines
当Item在Spider中被收集之后,它将会被传递到Item Pipeline
每个Item Pipeline组件接收到Item,定义一些操作行为,比如决定此Item是丢弃而存储。
以下是item pipeline的一些典型应用:
- 验证爬取的数据(检查item包含某些字段,比如说name字段)
- 查重(并丢弃)
- 将爬取结果保存到文件或者数据库中
编写item pipeline
编写item pipeline很简单,item pipiline组件是一个独立的Python类,其中process_item()方法必须实现:
import something
class SomethingPipeline(object):
def __init__(self):
# 可选实现,做参数初始化等
# doing something
def process_item(self, item, spider):
# item (Item 对象) – 被爬取的item
# spider (Spider 对象) – 爬取该item的spider
# 这个方法必须实现,每个item pipeline组件都需要调用该方法,
# 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。
return item
def open_spider(self, spider):
# spider (Spider 对象) – 被开启的spider
# 可选实现,当spider被开启时,这个方法被调用。
def close_spider(self, spider):
# spider (Spider 对象) – 被关闭的spider
# 可选实现,当spider被关闭时,这个方法被调用
将item写入json文件
import json
class JsonWriterPipeline(object):
def __init__(self):
self.file = open('items.json', 'wb')
def process_item(self, item, spider):
line = json.dumps(dict(item),ensure_ascii=False) + "\n"
self.file.write(line)
return item
启用一个Item Pipeline组件
为了启用Item Pipeline组件,必须将它的类添加到 settings.py文件ITEM_PIPELINES 配置,就像下面这个例子:
ITEM_PIPELINES = {
#'tutorial.pipelines.PricePipeline': 300,
'tutorial.pipelines.JsonWriterPipeline': 800,
}
分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。数值越低,越先运行
将item写入MongoDB
pipeline中还有一个from_crawler(cls, crawler)类方法
如果使用,这个类方法被调用创建爬虫管道实例。必须返回管道的一个新实例。crawler提供存取所有Scrapy核心组件配置和信号管理器; 对于pipelines这是一种访问配置和信号管理器 的方式。
在这个例子中,我们将使用pymongo将Item写到MongoDB。MongoDB的地址和数据库名称在Scrapy setttings.py配置文件中;
这个例子主要是说明如何使用from_crawler()方法
import pymongo
class MongoPipeline(object):
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert(dict(item))
return item
Spiders
https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/spiders.html
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是定义爬取的动作及分析某个网页(或者是有些网页)的地方。
Spider
class scrapy.spider.Spider
Spider是最简单的spider。每个spider必须继承自该类。Spider并没有提供什么特殊的功能。其仅仅请求给定的 start_urls/start_requests,并根据返回的结果调用spider的parse方法。
源码参考
#所有爬虫的基类,用户定义的爬虫必须从这个类继承
class Spider(object_ref):
#定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。
#name是spider最重要的属性,而且是必须的。
#一般做法是以该网站(domain)(加或不加 后缀 )来命名spider。 例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite
name = None
#初始化,提取爬虫名字,start_ruls
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
# 如果爬虫没有名字,中断后续操作则报错
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
# python 对象或类型通过内置成员__dict__来存储成员信息
self.__dict__.update(kwargs)
#URL列表。当没有指定的URL时,spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
if not hasattr(self, 'start_urls'):
self.start_urls = []
# 打印Scrapy执行后的log信息
def log(self, message, level=log.DEBUG, **kw):
log.msg(message, spider=self, level=level, **kw)
# 判断对象object的属性是否存在,不存在做断言处理
def set_crawler(self, crawler):
assert not hasattr(self, '_crawler'), "Spider already bounded to %s" % crawler
self._crawler = crawler
@property
def crawler(self):
assert hasattr(self, '_crawler'), "Spider not bounded to any crawler"
return self._crawler
@property
def settings(self):
return self.crawler.settings
#该方法将读取start_urls内的地址,并为每一个地址生成一个Request对象,交给Scrapy下载并返回Response
#该方法仅调用一次
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
#start_requests()中调用,实际生成Request的函数。
#Request对象默认的回调函数为parse(),提交的方式为get
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
#默认的Request对象回调函数,处理返回的response。
#生成Item或者Request对象。用户必须实现这个类
def parse(self, response):
raise NotImplementedError
@classmethod
def handles_request(cls, request):
return url_is_from_spider(request.url, cls)
def __str__(self):
return "<%s %r at 0x%0x>" % (type(self).__name__, self.name, id(self))
__repr__ = __str__
主要属性和方法
name
定义spider名字的字符串。
例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite
allowed_domains
包含了spider允许爬取的域名(domain)的列表,可选。
start_urls
初始URL元祖/列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。
start_requests(self)
该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取(默认实现是使用start_urls 的url)的第一个Request。
当spider启动爬取并且未指定start_urls时,该方法被调用。
parse(self, response)
当请求url返回网页没有指定回调函数时,默认的Request对象回调函数。用来处理网页返回的response,以及生成Item或者Request对象。
log(self, message[, level, component])
使用 scrapy.log.msg() 方法记录(log)message。 更多数据请参见 logging
腾讯招聘网自动翻页
(代码采集自互联网)
from mySpider.items import TencentItem
import scrapy
import re
class TencentSpider(scrapy.Spider):
name = "tencent"
allowed_domains = ["hr.tencent.com"]
start_urls = [
"http://hr.tencent.com/position.php?&start=0#a"
]
def parse(self, response):
for each in response.xpath('//*[@class="even"]'):
item = TencentItem()
name = each.xpath('./td[1]/a/text()').extract()[0]
detailLink = each.xpath('./td[1]/a/@href').extract()[0]
positionInfo = each.xpath('./td[2]/text()').extract()[0]
peopleNumber = each.xpath('./td[3]/text()').extract()[0]
workLocation = each.xpath('./td[4]/text()').extract()[0]
publishTime = each.xpath('./td[5]/text()').extract()[0]
#print name, detailLink, catalog, peopleNumber, workLocation,publishTime
item['name'] = name.encode('utf-8')
item['detailLink'] = detailLink.encode('utf-8')
item['positionInfo'] = positionInfo.encode('utf-8')
item['peopleNumber'] = peopleNumber.encode('utf-8')
item['workLocation'] = workLocation.encode('utf-8')
item['publishTime'] = publishTime.encode('utf-8')
curpage = re.search('(\d+)',response.url).group(1)
page = int(curpage) + 10
url = re.sub('\d+', str(page), response.url)
# 发送新的url请求加入待爬队列,并调用回调函数 self.parse
yield scrapy.Request(url, callback = self.parse)
# 将获取的数据交给pipeline
yield item
CrawlSpider
通过下面的命令可以快速创建 CrawlSpider模板 的代码:
scrapy genspider -t crawl tencent tencent.com
class scrapy.spiders.CrawlSpider
它是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类定义了一些规则(rule)来提供跟进link的方便的机制,从爬取的网页中获取link并继续爬取的工作更适合。
源码解析参考
class CrawlSpider(Spider):
rules = ()
def __init__(self, *a, **kw):
super(CrawlSpider, self).__init__(*a, **kw)
self._compile_rules()
#首先调用parse()来处理start_urls中返回的response对象
#parse()则将这些response对象传递给了_parse_response()函数处理,并设置回调函数为parse_start_url()
#设置了跟进标志位True
#parse将返回item和跟进了的Request对象
def parse(self, response):
return self._parse_response(response, self.parse_start_url, cb_kwargs={}, follow=True)
#处理start_url中返回的response,需要重写
def parse_start_url(self, response):
return []
def process_results(self, response, results):
return results
#从response中抽取符合任一用户定义'规则'的链接,并构造成Resquest对象返回
def _requests_to_follow(self, response):
if not isinstance(response, HtmlResponse):
return
seen = set()
#抽取之内的所有链接,只要通过任意一个'规则',即表示合法
for n, rule in enumerate(self._rules):
links = [l for l in rule.link_extractor.extract_links(response) if l not in seen]
#使用用户指定的process_links处理每个连接
if links and rule.process_links:
links = rule.process_links(links)
#将链接加入seen集合,为每个链接生成Request对象,并设置回调函数为_repsonse_downloaded()
for link in links:
seen.add(link)
#构造Request对象,并将Rule规则中定义的回调函数作为这个Request对象的回调函数
r = Request(url=link.url, callback=self._response_downloaded)
r.meta.update(rule=n, link_text=link.text)
#对每个Request调用process_request()函数。该函数默认为indentify,即不做任何处理,直接返回该Request.
yield rule.process_request(r)
#处理通过rule提取出的连接,并返回item以及request
def _response_downloaded(self, response):
rule = self._rules[response.meta['rule']]
return self._parse_response(response, rule.callback, rule.cb_kwargs, rule.follow)
#解析response对象,会用callback解析处理他,并返回request或Item对象
def _parse_response(self, response, callback, cb_kwargs, follow=True):
#首先判断是否设置了回调函数。(该回调函数可能是rule中的解析函数,也可能是 parse_start_url函数)
#如果设置了回调函数(parse_start_url()),那么首先用parse_start_url()处理response对象,
#然后再交给process_results处理。返回cb_res的一个列表
if callback:
#如果是parse调用的,则会解析成Request对象
#如果是rule callback,则会解析成Item
cb_res = callback(response, **cb_kwargs) or ()
cb_res = self.process_results(response, cb_res)
for requests_or_item in iterate_spider_output(cb_res):
yield requests_or_item
#如果需要跟进,那么使用定义的Rule规则提取并返回这些Request对象
if follow and self._follow_links:
#返回每个Request对象
for request_or_item in self._requests_to_follow(response):
yield request_or_item
def _compile_rules(self):
def get_method(method):
if callable(method):
return method
elif isinstance(method, basestring):
return getattr(self, method, None)
self._rules = [copy.copy(r) for r in self.rules]
for rule in self._rules:
rule.callback = get_method(rule.callback)
rule.process_links = get_method(rule.process_links)
rule.process_request = get_method(rule.process_request)
def set_crawler(self, crawler):
super(CrawlSpider, self).set_crawler(crawler)
self._follow_links = crawler.settings.getbool('CRAWLSPIDER_FOLLOW_LINKS', True)
CrawlSpider继承于Spider类,除了继承过来的属性外(name、allow_domains),还提供了新的属性和方法:
LinkExtractors
class scrapy.linkextractors.LinkExtractor
Link Extractors 的目的很简单: 提取链接。
每个LinkExtractor有唯一的公共方法是 extract_links(),它接收一个 Response 对象,并返回一个 scrapy.link.Link 对象。
Link Extractors要实例化一次,并且 extract_links 方法会根据不同的response调用多次提取链接。
class scrapy.linkextractors.LinkExtractor(
allow = (),
deny = (),
allow_domains = (),
deny_domains = (),
deny_extensions = None,
restrict_xpaths = (),
tags = ('a','area'),
attrs = ('href'),
canonicalize = True,
unique = True,
process_value = None
)
主要参数:
allow:满足括号中“正则表达式”的值会被提取,如果为空,则全部匹配。deny:与这个正则表达式(或正则表达式列表)不匹配的URL一定不提取。allow_domains:会被提取的链接的domains。deny_domains:一定不会被提取链接的domains。restrict_xpaths:使用xpath表达式,和allow共同作用过滤链接。
rules
在rules中包含一个或多个Rule对象,每个Rule对爬取网站的动作定义了特定操作。如果多个rule匹配了相同的链接,则根据规则在本集合中被定义的顺序,第一个会被使用。
class scrapy.spiders.Rule(
link_extractor,
callback = None,
cb_kwargs = None,
follow = None,
process_links = None,
process_request = None
)
link_extractor:是一个Link Extractor对象,用于定义需要提取的链接。callback: 从link_extractor中每获取到链接时,参数所指定的值作为回调函数,该回调函数接受一个response作为其第一个参数。
注意:当编写爬虫规则时,避免使用parse作为回调函数。由于CrawlSpider使用parse方法来实现其逻辑,如果覆盖了 parse方法,crawl spider将会运行失败。
follow:是一个布尔(boolean)值,指定了根据该规则从response提取的链接是否需要跟进。 如果callback为None,follow 默认设置为True ,否则默认为False。process_links:指定该spider中哪个的函数将会被调用,从link_extractor中获取到链接列表时将会调用该函数。该方法主要用来过滤。process_request:指定该spider中哪个的函数将会被调用, 该规则提取到每个request时都会调用该函数。 (用来过滤request)
翻页
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from mySpider.items import TencentItem
class TencentSpider(CrawlSpider):
name = "tencent"
allowed_domains = ["hr.tencent.com"]
start_urls = [
"http://hr.tencent.com/position.php?&start=0#a"
]
page_lx = LinkExtractor(allow=("start=\d+"))
rules = [
Rule(page_lx, callback = "parseContent", follow = True)
]
def parseContent(self, response):
for each in response.xpath('//*[@class="even"]'):
name = each.xpath('./td[1]/a/text()').extract()[0]
detailLink = each.xpath('./td[1]/a/@href').extract()[0]
positionInfo = each.xpath('./td[2]/text()').extract()[0]
peopleNumber = each.xpath('./td[3]/text()').extract()[0]
workLocation = each.xpath('./td[4]/text()').extract()[0]
publishTime = each.xpath('./td[5]/text()').extract()[0]
#print name, detailLink, catalog,recruitNumber,workLocation,publishTime
item = TencentItem()
item['name']=name.encode('utf-8')
item['detailLink']=detailLink.encode('utf-8')
item['positionInfo']=positionInfo.encode('utf-8')
item['peopleNumber']=peopleNumber.encode('utf-8')
item['workLocation']=workLocation.encode('utf-8')
item['publishTime']=publishTime.encode('utf-8')
yield item
process_links参数:动态网页爬取,动态url的处理
某些网站会为每一个url增加一个sessionid属性,可能是为了标记用户访问历史,而且这个seesionid随着每次访问都会动态变化,这就为爬虫的去重处理(即标记已经爬取过的网站)和提取规则增加了难度。
https://bitsharestalk.org/index.php?board=5.0会变成https://bitsharestalk.org/index.phpPHPSESSID=9771d42640ab3c89eb77e8bd9e220b53&board=5.0,下面介绍集中处理方法
仅适用你的爬虫使用的是 scrapy.contrib.spiders.CrawlSpider, 在这个内置爬虫中,你提取url要通过Rule类来进行提取,其自带了对提取后的url进行加工的函数。
rules = (
Rule(LinkExtractor(allow = ( "https://bitsharestalk\.org/index\.php\?PHPSESSID\S*board=\d+\.\d+$", "https://bitsharestalk\.org/index\.php\?board=\d+\.\d+$" )), process_links = 'link_filtering' ), #默认函数process_links
Rule(LinkExtractor(allow = ( " https://bitsharestalk\.org/index\.php\?PHPSESSID\S*topic=\d+\.\d+$" , "https://bitsharestalk\.org/index\.php\?topic=\d+\.\d+$", ),),
callback = "extractPost" ,
follow = True, process_links = 'link_filtering' ),
Rule(LinkExtractor(allow = ( "https://bitsharestalk\.org/index\.php\?PHPSESSID\S*action=profile;u=\d+$" , "https://bitsharestalk\.org/index\.php\?action=profile;u=\d+$" , ),),
callback = "extractUser", process_links = 'link_filtering' )
)
def link_filtering(self, links):
ret = []
for link in links:
url = link.url
# print "This is the yuanlai ", link.url
urlfirst, urllast = url.split( " ? " )
if urllast:
link.url = urlfirst + " ? " + urllast.split( " & " , 1)[1]
# print link.url
return links
process_request参数:修改请求参数
class WeiboSpider(CrawlSpider):
name = 'weibo'
allowed_domains = ['weibo.com']
start_urls = ['http://www.weibo.com/u/1876296184'] # 不加www,则匹配不到cookie, get_login_cookie()方法正则代完善
rules = (
Rule(LinkExtractor(allow=r'^http:\/\/(www\.)?weibo.com/[a-z]/.*'), # 微博个人页面的规则,或/u/或/n/后面跟一串数字
process_request='process_request',
callback='parse_item', follow=True), )
cookies = None
def process_request(self, request):
link=request.url
page = re.search('page=\d*', link).group()
type = re.search('type=\d+', link).group()
newrequest = request.replace(cookies =self.cookies, url='.../questionType?' + page + "&" + type)
return newrequest
Logging
Scrapy提供了log功能,可以通过 logging 模块使用。
Log levels
Scrapy提供5层logging级别:
- CRITICAL - 严重错误(critical)
- ERROR - 一般错误(regular errors)
- WARNING - 警告信息(warning messages)
- INFO - 一般信息(informational messages)
- DEBUG - 调试信息(debugging messages)
默认情况下python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG,默认的日志格式为DEBUG级别
logging设置
通过在setting.py中进行以下设置可以被用来配置logging:
- LOG_ENABLED 默认: True,启用logging
- LOG_ENCODING 默认: 'utf-8',logging使用的编码
- LOG_FILE 默认: None,在当前目录里创建logging输出文件的文件名
- LOG_LEVEL 默认: 'DEBUG',log的最低级别
- LOG_STDOUT 默认: False 如果为 True,进程所有的标准输出(及错误)将会被重定向到log中。例如,执行
print("hello"),其将会在Scrapy log中显示。
#coding:utf-8
######################
##Logging的使用
######################
import logging
'''
1. logging.CRITICAL - for critical errors (highest severity) 致命错误
2. logging.ERROR - for regular errors 一般错误
3. logging.WARNING - for warning messages 警告+错误
4. logging.INFO - for informational messages 消息+警告+错误
5. logging.DEBUG - for debugging messages (lowest severity) 低级别
'''
logging.warning("This is a warning")
logging.log(logging.WARNING,"This is a warning")
#获取实例对象
logger=logging.getLogger()
logger.warning("这是警告消息")
#指定消息发出者
logger = logging.getLogger('SimilarFace')
logger.warning("This is a warning")
#在爬虫中使用log
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://scrapinghub.com']
def parse(self, response):
#方法1 自带的logger
self.logger.info('Parse function called on %s', response.url)
#方法2 自己定义个logger
logger.info('Parse function called on %s', response.url)
'''
Logging 设置
• LOG_FILE
• LOG_ENABLED
• LOG_ENCODING
• LOG_LEVEL
• LOG_FORMAT
• LOG_DATEFORMAT
• LOG_STDOUT
命令行中使用
--logfile FILE
Overrides LOG_FILE
--loglevel/-L LEVEL
Overrides LOG_LEVEL
--nolog
Sets LOG_ENABLED to False
'''
import logging
from scrapy.utils.log import configure_logging
configure_logging(install_root_handler=False)
#定义了logging的些属性
logging.basicConfig(
filename='log.txt',
format='%(levelname)s: %(levelname)s: %(message)s',
level=logging.INFO
)
#运行时追加模式
logging.info('进入Log文件')
logger = logging.getLogger('SimilarFace')
logger.warning("也要进入Log文件")
Settings
https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/settings.html
Scrapy设置(settings)提供了定制Scrapy组件的方法。可以控制包括核心(core),插件(extension),pipeline及spider组件。比如 设置Json Pipeliine、LOG_LEVEL
内置设置参考手册
BOT_NAME
默认:scrapybot
当您使用startproject命令创建项目时其也被自动赋值。CONCURRENT_ITEMS
默认: 100
Item Processor(即Item Pipeline) 同时处理(每个response的)item的最大值。CONCURRENT_REQUESTS
默认: 16
Scrapy downloader并发请求(concurrent requests)的最大值。DEFAULT_REQUEST_HEADERS 默认:
{
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
Scrapy HTTP Request使用的默认header。
DEPTH_LIMIT
默认: 0
爬取网站最大允许的深度(depth)值。如果为0,则没有限制。DOWNLOAD_DELAY
默认: 0
下载器在下载同一个网站下一个页面前需要等待的时间。该选项可以用来限制爬取速度, 减轻服务器压力。同时也支持小数:DOWNLOAD_DELAY = 0.25 # 250 ms of delay
该设置影响(默认启用的)RANDOMIZE_DOWNLOAD_DELAY设置。 默认情况下,Scrapy在两个请求间不等待一个固定的值, 而是使用0.5到1.5之间的一个随机值DOWNLOAD_DELAY的结果作为等待间隔。DOWNLOAD_TIMEOUT
默认: 180
下载器超时时间(单位: 秒)。ITEM_PIPELINES
默认: {}
保存项目中启用的pipeline及其顺序的字典。该字典默认为空,值(value)任意。 不过值(value)习惯设置在0-1000范围内。
样例:
ITEM_PIPELINES = {
'mybot.pipelines.validate.ValidateMyItem': 300,
'mybot.pipelines.validate.StoreMyItem': 800,
}
LOG_ENABLED
默认: True
是否启用logging。LOG_ENCODING
默认: 'utf-8'
logging使用的编码。LOG_LEVEL
默认: 'DEBUG'
log的最低级别。可选的级别有:CRITICAL、 ERROR、WARNING、INFO、DEBUG。USER_AGENT
默认:Scrapy/VERSION (+http://scrapy.org)
爬取的默认User-Agent,除非被覆盖。
Request/Response
https://docs.scrapy.org/en/latest/topics/request-response.html
Request 部分源码:
# 部分代码
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None):
self._encoding = encoding # this one has to be set first
self.method = str(method).upper()
self._set_url(url)
self._set_body(body)
assert isinstance(priority, int), "Request priority not an integer: %r" % priority
self.priority = priority
assert callback or not errback, "Cannot use errback without a callback"
self.callback = callback
self.errback = errback
self.cookies = cookies or {}
self.headers = Headers(headers or {}, encoding=encoding)
self.dont_filter = dont_filter
self._meta = dict(meta) if meta else None
@property
def meta(self):
if self._meta is None:
self._meta = {}
return self._meta
常用参数
url: 就是需要请求,并进行下一步处理的url
callback: 指定该请求返回的Response,由那个函数来处理。
method: 请求一般不需要指定,默认GET方法,可设置为"GET", "POST", "PUT"等,且保证字符串大写
headers: 请求时,包含的头文件。一般不需要。内容一般如下:
# 自己写过爬虫的肯定知道
Host: media.readthedocs.org
User-Agent: Mozilla/5.0 (Windows NT 6.2; WOW64; rv:33.0) Gecko/20100101 Firefox/33.0
Accept: text/css,*/*;q=0.1
Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Referer: http://scrapy-chs.readthedocs.org/zh_CN/0.24/
Cookie: _ga=GA1.2.1612165614.1415584110;
Connection: keep-alive
If-Modified-Since: Mon, 25 Aug 2014 21:59:35 GMT
Cache-Control: max-age=0
meta: 比较常用,在不同的请求之间传递数据使用的。字典dict型
request_with_cookies = Request(
url="http://www.example.com",
cookies={'currency': 'USD', 'country': 'UY'},
meta={'dont_merge_cookies': True}
)
encoding: 使用默认的 'utf-8' 就行。
dont_filter: 表明该请求不由调度器过滤。这是当你想使用多次执行相同的请求,忽略重复的过滤器。默认为False。
errback: 指定错误处理函数
Response
# 部分代码
class Response(object_ref):
def __init__(self, url, status=200, headers=None, body='', flags=None, request=None):
self.headers = Headers(headers or {})
self.status = int(status)
self._set_body(body)
self._set_url(url)
self.request = request
self.flags = [] if flags is None else list(flags)
@property
def meta(self):
try:
return self.request.meta
except AttributeError:
raise AttributeError("Response.meta not available, this response " \
"is not tied to any request")
大部分参数和上面的差不多:
status: 响应码
_set_body(body): 响应体
_set_url(url):响应url
self.request = request
Downloader Middlewares
https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
下载中间件是处于引擎(crawler.engine)和下载器(crawler.engine.download())之间的一层组件,可以有多个下载中间件被加载运行。
当引擎传递请求给下载器的过程中,下载中间件可以对请求进行处理 (例如增加http header信息,增加proxy信息等);
在下载器完成http请求,传递响应给引擎的过程中, 下载中间件可以对响应进行处理(例如进行gzip的解压等)
要激活下载器中间件组件,将其加入到 DOWNLOADER_MIDDLEWARES 设置中。 该设置是一个字典(dict),键为中间件类的路径,值为其中间件的顺序(order)。
这里是一个例子:
DOWNLOADER_MIDDLEWARES = {
'mySpider.middlewares.MyDownloaderMiddleware': 543,
}
编写下载器中间件十分简单。每个中间件组件是一个定义了以下一个或多个方法的Python类:
class scrapy.contrib.downloadermiddleware.DownloaderMiddleware
process_request(self, request, spider)
当每个request通过下载中间件时,该方法被调用。
process_request()必须返回以下其中之一:一个 None 、一个 Response 对象、一个 Request 对象或 raise IgnoreRequest:如果其返回 None ,Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用, 该request被执行(其response被下载)。
如果其返回 Response 对象,Scrapy将不会调用 任何 其他的 process_request() 或 process_exception() 方法,或相应地下载函数; 其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
如果其返回 Request 对象,Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。
如果其raise一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)。
参数:
request (Request 对象) – 处理的request
spider (Spider 对象) – 该request对应的spider
process_response(self, request, response, spider)
当下载器完成http请求,传递响应给引擎的时候调用
process_request()必须返回以下其中之一: 返回一个 Response 对象、 返回一个 Request 对象或raise一个 IgnoreRequest 异常。如果其返回一个 Response (可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的 process_response() 方法处理。
如果其返回一个 Request 对象,则中间件链停止, 返回的request会被重新调度下载。处理类似于 process_request() 返回request所做的那样。
如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
参数:
request (Request 对象) – response所对应的request
response (Response 对象) – 被处理的response
spider (Spider 对象) – response所对应的spider
暂停和重启
https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/jobs.html
要启用持久化支持,你只需要通过 JOBDIR 设置 job directory 选项。这个路径将会存储 所有的请求数据来保持一个单独任务的状态(例如:一次spider爬取(a spider run))。必须要注意的是,这个目录不允许被不同的spider 共享,甚至是同一个spider的不同jobs/runs也不行。也就是说,这个目录就是存储一个 单独 job的状态信息。
scrapy crawl somespider -s JOBDIR=crawls/somespider-1
然后,你就能在任何时候安全地停止爬虫(按Ctrl-C或者发送一个信号)。恢复这个爬虫也是同样的命令:
scrapy crawl somespider -s JOBDIR=crawls/somespider-1
去重原理
在scrapy源码中找到scrapy/dupefilters.py文件,部分源码
class RFPDupeFilter(BaseDupeFilter):
"""Request Fingerprint duplicates filter"""
def __init__(self, path=None, debug=False):
self.file = None
self.fingerprints = set()
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)
@classmethod
def from_settings(cls, settings):
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(job_dir(settings), debug)
def request_seen(self, request):
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
def request_fingerprint(self, request):
return request_fingerprint(request)
def close(self, reason):
if self.file:
self.file.close()
def log(self, request, spider):
if self.debug:
msg = "Filtered duplicate request: %(request)s"
self.logger.debug(msg, {'request': request}, extra={'spider': spider})
elif self.logdupes:
msg = ("Filtered duplicate request: %(request)s"
" - no more duplicates will be shown"
" (see DUPEFILTER_DEBUG to show all duplicates)")
self.logger.debug(msg, {'request': request}, extra={'spider': spider})
self.logdupes = False
spider.crawler.stats.inc_value('dupefilter/filtered', spider=spider)
里面有一个request_seen方法,这个方法在scrapy/core/scheduler.py中被调用
class Scheduler(object):
...
def enqueue_request(self, request):
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
dqok = self._dqpush(request)
if dqok:
self.stats.inc_value('scheduler/enqueued/disk', spider=self.spider)
else:
self._mqpush(request)
self.stats.inc_value('scheduler/enqueued/memory', spider=self.spider)
self.stats.inc_value('scheduler/enqueued', spider=self.spider)
return True
...
回到request_seen方法继续查看
def request_seen(self, request):
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
# 返回的`request_fingerprint`是`from scrapy.utils.request import request_fingerprint`
def request_fingerprint(self, request):
return request_fingerprint(request)
scrapy\utils\request.py 这个函数将request进行hash,最后生成摘要(fp.hexdigest())
def request_fingerprint(request, include_headers=None):
"""
Return the request fingerprint.
The request fingerprint is a hash that uniquely identifies the resource the
request points to. For example, take the following two urls:
http://www.example.com/query?id=111&cat=222
http://www.example.com/query?cat=222&id=111
Even though those are two different URLs both point to the same resource
and are equivalent (ie. they should return the same response).
Another example are cookies used to store session ids. Suppose the
following page is only accesible to authenticated users:
http://www.example.com/members/offers.html
Lot of sites use a cookie to store the session id, which adds a random
component to the HTTP Request and thus should be ignored when calculating
the fingerprint.
For this reason, request headers are ignored by default when calculating
the fingeprint. If you want to include specific headers use the
include_headers argument, which is a list of Request headers to include.
"""
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]
我们可以看到,去重指纹是sha1(method + url + body + header)
所以,实际能够去掉重复的比例并不大。
如果我们需要自己提取去重的finger,需要自己实现Filter,并配置上它。
下面这个Filter只根据url去重:
from scrapy.dupefilter import RFPDupeFilter
class SeenURLFilter(RFPDupeFilter):
"""A dupe filter that considers the URL"""
def __init__(self, path=None):
self.urls_seen = set()
RFPDupeFilter.__init__(self, path)
def request_seen(self, request):
if request.url in self.urls_seen:
return True
else:
self.urls_seen.add(request.url)
不要忘记配置上:
DUPEFILTER_CLASS ='scraper.custom_filters.SeenURLFilter'
Telnet
https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/telnetconsole.html
Scrapy运行的有telnet服务,我们可以通过这个功能来得到一些性能指标。通过telnet命令连接到6023端口,然后就会得到一个在爬虫内部环境的Python命令行。要小心的是,如果你在这里运行了一些阻塞的操作,比如time.sleep(),正在运行的爬虫就会被中止。通过内建的est()函数可以打印出一些性能指标。
打开第一个命令行,运行以下代码:
$ telnet localhost 6023
est()
...
len(engine.downloader.active) : 16
...
len(engine.slot.scheduler.mqs) : 4475
...
len(engine.scraper.slot.active) : 115
engine.scraper.slot.active_size : 117760
engine.scraper.slot.itemproc_size : 105
> 在这里我们忽略了dqs指标,如果你启用了持久化支持的功能,亦即设置了JOBDIR设置项,你也
> 会得到非零的dqs(len(engine.slot.scheduler.dqs)
> )值,这时候就应当把dqs加到mqs上去,以便后续的分析。
* `mqs`
意味着在调度器中有很多请求等待处理(4475个请求)。这是没问题的。
* `len(engine.downloader.active)`
表示着现在有16个请求正被下载器下载。这和我们设置的`CONCURRENT_REQUESTS`值是一样的,所以也没问题。
* `len(engine.scraper.slot.active)`
告诉我们现在正有115个响应在`scraper`中处理,这些响应的总的大小可以从`engine.scraper.slot.active_size`指标得到,共是115kb。除了这些响应,`pipeline`中正有105个
* `Item`
被处理——从`engine.scraper.slot.itemproc_size`中得知,也就是说,还有10个正在爬虫中进行处理。总的来说,可以确定下载器就是系统的瓶颈,因为在下载器之前有很多请求(mqs)在队列中等待处理,下载器已经被充分地利用了;在下载器之后,我们有一个或多或少比较很稳定的工作量(可以通过多次调用`est()`函数来证实这一点)。
另一个信息来源是`stats`对象,它一般情况下会在爬虫运行结束后打印出来。而在`telnet`中,我们可以随时通过`stats.get_stats()`得到一个`dict`
对象,并用p()函数打印出来:
> ```
> $ p(stats.get_stats())
> {'downloader/request_bytes': 558330,
> ...
> 'item_scraped_count': 2485,
> ...}
> ```
### 数据收集
[https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/stats.html](https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/stats.html)
`scrapy/statscollectors.py`
```py
"""
Scrapy extension for collecting scraping stats
"""
import pprint
import logging
logger = logging.getLogger(__name__)
class StatsCollector(object):
def __init__(self, crawler):
self._dump = crawler.settings.getbool('STATS_DUMP')
self._stats = {}
def get_value(self, key, default=None, spider=None):
return self._stats.get(key, default)
def get_stats(self, spider=None):
return self._stats
def set_value(self, key, value, spider=None):
self._stats[key] = value
def set_stats(self, stats, spider=None):
self._stats = stats
def inc_value(self, key, count=1, start=0, spider=None):
d = self._stats
d[key] = d.setdefault(key, start) + count
def max_value(self, key, value, spider=None):
self._stats[key] = max(self._stats.setdefault(key, value), value)
def min_value(self, key, value, spider=None):
self._stats[key] = min(self._stats.setdefault(key, value), value)
def clear_stats(self, spider=None):
self._stats.clear()
def open_spider(self, spider):
pass
def close_spider(self, spider, reason):
if self._dump:
logger.info("Dumping Scrapy stats:\n" + pprint.pformat(self._stats),
extra={'spider': spider})
self._persist_stats(self._stats, spider)
def _persist_stats(self, stats, spider):
pass
class MemoryStatsCollector(StatsCollector):
def __init__(self, crawler):
super(MemoryStatsCollector, self).__init__(crawler)
self.spider_stats = {}
def _persist_stats(self, stats, spider):
self.spider_stats[spider.name] = stats
class DummyStatsCollector(StatsCollector):
def get_value(self, key, default=None, spider=None):
return default
def set_value(self, key, value, spider=None):
pass
def set_stats(self, stats, spider=None):
pass
def inc_value(self, key, count=1, start=0, spider=None):
pass
def max_value(self, key, value, spider=None):
pass
def min_value(self, key, value, spider=None):
pass
404页面收集
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/']
# 收集404的url和数量
handle_httpstatus_list = [404,]
def __init__(self):
self.fail_urls = []
super(JobboleSpider, self).__init__()
def parse(self, response):
if response.status == 404:
self.fail_urls.append(response.url)
self.crawler.stats.inc_value('failed_url')
...
信号
https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/signals.html
在spider关闭时对fail_urls进行处理
def __init__(self):
self.fail_urls = []
super(JobboleSpider, self).__init__()
dispatcher.connect(self.handle_spider_closed, signal=signals.spider_closed)
def handle_spider_closed(self, spider, response):
self.crawler.stats.set_value('failed_urls', ','.join(self.fail_urls))
...
扩展
https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/extensions.html
scrapy/extensions包里有一些扩展实例
分布式爬虫
http://doc.scrapy.org/en/master/topics/practices.html#distributed-crawls
Scrapy并没有提供内置的机制支持分布式(多服务器)爬取。不过还是有办法进行分布式爬取, 取决于您要怎么分布了。
如果您有很多spider,那分布负载最简单的办法就是启动多个Scrapyd,并分配到不同机器上。
如果想要在多个机器上运行一个单独的spider,那您可以将要爬取的url进行分块,并发送给spider。 例如:
首先,准备要爬取的url列表,并分配到不同的文件url里:
http://somedomain.com/urls-to-crawl/spider1/part1.list
http://somedomain.com/urls-to-crawl/spider1/part2.list
http://somedomain.com/urls-to-crawl/spider1/part3.list
接着在3个不同的Scrapd服务器中启动spider。spider会接收一个(spider)参数 part , 该参数表示要爬取的分块:
curl http://scrapy1.mycompany.com:6800/schedule.json -d project=myproject -d spider=spider1 -d part=1
curl http://scrapy2.mycompany.com:6800/schedule.json -d project=myproject -d spider=spider1 -d part=2
curl http://scrapy3.mycompany.com:6800/schedule.json -d project=myproject -d spider=spider1 -d part=3
scrapy-redis分布式爬虫
https://github.com/rmax/scrapy-redis
Redis 命令参考
http://redisdoc.com/
pip install scrapy-redis
Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件)。
Scrapy-redis提供了下面四种组件(components):(四种组件意味着这四个模块都要做相应的修改)
- Scheduler
- Duplication Filter
- Item Pipeline
- Base Spider
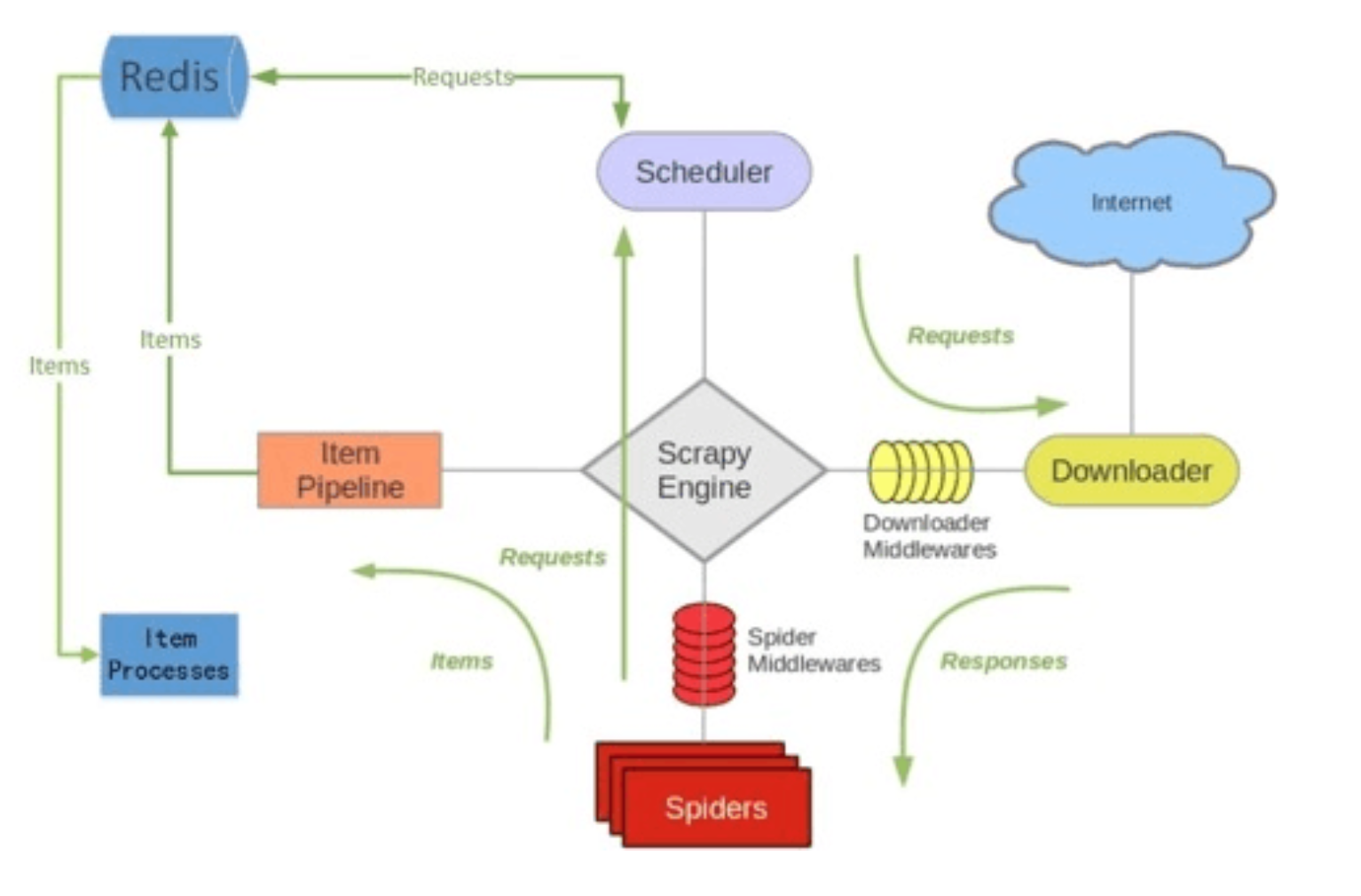
如上图所⽰示,scrapy-redis在scrapy的架构上增加了redis,基于redis的特性拓展了如下组件:
Scheduler
Scrapy改造了python本来的collection.deque(双向队列)形成了自己的Scrapy queue(https://github.com/scrapy/queuelib/blob/master/queuelib/queue.py)),但是Scrapy多个spider不能共享待爬取队列Scrapy queue, 即Scrapy本身不支持爬虫分布式,scrapy-redis的解决是把这个Scrapy queue换成redis数据库(也是指redis队列),从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取。
Scrapy中跟“待爬队列”直接相关的就是调度器Scheduler,它负责对新的request进行入列操作(加入Scrapy queue),取出下一个要爬取的request(从Scrapy queue中取出)等操作。它把待爬队列按照优先级建立了一个字典结构,比如:
{
优先级0 : 队列0
优先级1 : 队列1
优先级2 : 队列2
}
然后根据request中的优先级,来决定该入哪个队列,出列时则按优先级较小的优先出列。为了管理这个比较高级的队列字典,Scheduler需要提供一系列的方法。但是原来的Scheduler已经无法使用,所以使用Scrapy-redis的scheduler组件。
Duplication Filter
Scrapy中用集合实现这个request去重功能,Scrapy中把已经发送的request指纹放入到一个集合中,把下一个request的指纹拿到集合中比对,如果该指纹存在于集合中,说明这个request发送过了,如果没有则继续操作。这个核心的判重功能是这样实现的:
def request_seen(self, request):
# self.request_figerprints就是一个指纹集合
fp = self.request_fingerprint(request)
# 这就是判重的核心操作
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
在scrapy-redis中去重是由Duplication Filter组件来实现的,它通过redis的set 不重复的特性,巧妙的实现了Duplication Filter去重。scrapy-redis调度器从引擎接受request,将request的指纹存⼊redis的set检查是否重复,并将不重复的request push写⼊redis的 request queue。
引擎请求request(Spider发出的)时,调度器从redis的request queue队列⾥里根据优先级pop 出⼀个request 返回给引擎,引擎将此request发给spider处理。
Item Pipeline
引擎将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis的Item Pipeline将爬取到的Item存⼊redis的items queue。
修改后的Item Pipeline可以很方便的根据key从items queue提取item,从⽽实现items processes集群。Base Spider
不在使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。
当我们生成一个Spider继承RedisSpider时,调用setup_redis函数,这个函数会去连接redis数据库,然后会设置signals(信号):
一个是当spider空闲时候的signal,会调用
spider_idle函数,这个函数调用schedule_next_request函数,保证spider是一直活着的状态,并且抛出DontCloseSpider异常。一个是当抓到一个item时的signal,会调用
item_scraped函数,这个函数会调用schedule_next_request函数,获取下一个request。
scrapy-redis源码分析参考
scrapy-redis的源码并不多,工程的主体还是是redis和scrapy两个库,工程本身实现的东西不是很多,这个工程就像胶水一样,把这两个插件粘结了起来。下面我们来看看,scrapy-redis的每一个源代码文件都实现了什么功能,最后如何实现分布式的爬虫系统
connection.py
负责根据setting中配置实例化redis连接。被dupefilter和scheduler调用,总之涉及到redis存取的都要使用到这个模块。
import six
from scrapy.utils.misc import load_object
from . import defaults
# 连接redis数据库
# Shortcut maps 'setting name' -> 'parmater name'.
SETTINGS_PARAMS_MAP = {
'REDIS_URL': 'url',
'REDIS_HOST': 'host',
'REDIS_PORT': 'port',
'REDIS_ENCODING': 'encoding',
}
def get_redis_from_settings(settings):
"""Returns a redis client instance from given Scrapy settings object.
This function uses ``get_client`` to instantiate the client and uses
``defaults.REDIS_PARAMS`` global as defaults values for the parameters. You
can override them using the ``REDIS_PARAMS`` setting.
Parameters
----------
settings : Settings
A scrapy settings object. See the supported settings below.
Returns
-------
server
Redis client instance.
Other Parameters
----------------
REDIS_URL : str, optional
Server connection URL.
REDIS_HOST : str, optional
Server host.
REDIS_PORT : str, optional
Server port.
REDIS_ENCODING : str, optional
Data encoding.
REDIS_PARAMS : dict, optional
Additional client parameters.
"""
params = defaults.REDIS_PARAMS.copy()
params.update(settings.getdict('REDIS_PARAMS'))
# XXX: Deprecate REDIS_* settings.
for source, dest in SETTINGS_PARAMS_MAP.items():
val = settings.get(source)
if val:
params[dest] = val
# Allow ``redis_cls`` to be a path to a class.
if isinstance(params.get('redis_cls'), six.string_types):
params['redis_cls'] = load_object(params['redis_cls'])
return get_redis(**params)
# Backwards compatible alias.
from_settings = get_redis_from_settings
def get_redis(**kwargs):
"""Returns a redis client instance.
Parameters
----------
redis_cls : class, optional
Defaults to ``redis.StrictRedis``.
url : str, optional
If given, ``redis_cls.from_url`` is used to instantiate the class.
**kwargs
Extra parameters to be passed to the ``redis_cls`` class.
Returns
-------
server
Redis client instance.
"""
redis_cls = kwargs.pop('redis_cls', defaults.REDIS_CLS)
url = kwargs.pop('url', None)
if url:
return redis_cls.from_url(url, **kwargs)
else:
return redis_cls(**kwargs)
defaults.py
scrapy-redis默认配置
import redis
# For standalone use.
DUPEFILTER_KEY = 'dupefilter:%(timestamp)s'
PIPELINE_KEY = '%(spider)s:items'
REDIS_CLS = redis.StrictRedis
REDIS_ENCODING = 'utf-8'
# Sane connection defaults.
# 套接字的超时时间、等待时间等
REDIS_PARAMS = {
'socket_timeout': 30,
'socket_connect_timeout': 30,
'retry_on_timeout': True,
'encoding': REDIS_ENCODING,
}
SCHEDULER_QUEUE_KEY = '%(spider)s:requests'
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter'
SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
START_URLS_KEY = '%(name)s:start_urls'
START_URLS_AS_SET = False
dupefilter.py
负责执行requst的去重,实现的很有技巧性,使用redis的set数据结构。但是注意scheduler并不使用其中用于在这个模块中实现的dupefilter键做request的调度,而是使用queue.py模块中实现的queue。
当request不重复时,将其存入到queue中,调度时将其弹出。
import logging
import time
from scrapy.dupefilters import BaseDupeFilter
from scrapy.utils.request import request_fingerprint
from . import defaults
from .connection import get_redis_from_settings
logger = logging.getLogger(__name__)
# TODO: Rename class to RedisDupeFilter.
class RFPDupeFilter(BaseDupeFilter):
"""Redis-based request duplicates filter.
This class can also be used with default Scrapy's scheduler.
"""
logger = logger
def __init__(self, server, key, debug=False):
"""Initialize the duplicates filter.
Parameters
----------
server : redis.StrictRedis
The redis server instance.
key : str
Redis key Where to store fingerprints.
debug : bool, optional
Whether to log filtered requests.
"""
self.server = server
self.key = key
self.debug = debug
self.logdupes = True
@classmethod
def from_settings(cls, settings):
"""Returns an instance from given settings.
This uses by default the key ``dupefilter:<timestamp>``. When using the
``scrapy_redis.scheduler.Scheduler`` class, this method is not used as
it needs to pass the spider name in the key.
Parameters
----------
settings : scrapy.settings.Settings
Returns
-------
RFPDupeFilter
A RFPDupeFilter instance.
"""
server = get_redis_from_settings(settings)
# XXX: This creates one-time key. needed to support to use this
# class as standalone dupefilter with scrapy's default scheduler
# if scrapy passes spider on open() method this wouldn't be needed
# TODO: Use SCRAPY_JOB env as default and fallback to timestamp.
key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())}
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(server, key=key, debug=debug)
@classmethod
def from_crawler(cls, crawler):
"""Returns instance from crawler.
Parameters
----------
crawler : scrapy.crawler.Crawler
Returns
-------
RFPDupeFilter
Instance of RFPDupeFilter.
"""
return cls.from_settings(crawler.settings)
def request_seen(self, request):
"""Returns True if request was already seen.
Parameters
----------
request : scrapy.http.Request
Returns
-------
bool
"""
fp = self.request_fingerprint(request)
# This returns the number of values added, zero if already exists.
added = self.server.sadd(self.key, fp)
return added == 0
def request_fingerprint(self, request):
"""Returns a fingerprint for a given request.
Parameters
----------
request : scrapy.http.Request
Returns
-------
str
"""
return request_fingerprint(request)
@classmethod
def from_spider(cls, spider):
settings = spider.settings
server = get_redis_from_settings(settings)
dupefilter_key = settings.get("SCHEDULER_DUPEFILTER_KEY", defaults.SCHEDULER_DUPEFILTER_KEY)
key = dupefilter_key % {'spider': spider.name}
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(server, key=key, debug=debug)
def close(self, reason=''):
"""Delete data on close. Called by Scrapy's scheduler.
Parameters
----------
reason : str, optional
"""
self.clear()
def clear(self):
"""Clears fingerprints data."""
self.server.delete(self.key)
def log(self, request, spider):
"""Logs given request.
Parameters
----------
request : scrapy.http.Request
spider : scrapy.spiders.Spider
"""
if self.debug:
msg = "Filtered duplicate request: %(request)s"
self.logger.debug(msg, {'request': request}, extra={'spider': spider})
elif self.logdupes:
msg = ("Filtered duplicate request %(request)s"
" - no more duplicates will be shown"
" (see DUPEFILTER_DEBUG to show all duplicates)")
self.logger.debug(msg, {'request': request}, extra={'spider': spider})
self.logdupes = False
这个文件看起来比较复杂,重写了scrapy本身已经实现的request判重功能。因为本身scrapy单机跑的话,只需要读取内存中的request队列或者持久化的request队列,就能判断这次要发出的request url是否已经请求过或者正在调度(本地读就行了)。而分布式跑的话,就需要各个主机上的scheduler都连接同一个数据库的同一个request池来判断这次的请求是否是重复的了。
在这个文件中,通过继承BaseDupeFilter重写他的方法,实现了基于redis的判重。根据源代码来看,scrapy-redis使用了scrapy本身的一个fingerprint即request_fingerprint,这个函数在前面去重原理中已经说过了.
这个类通过连接redis,使用一个key来向redis的一个set中插入fingerprint(这个key对于同一种spider是相同的,redis是一个key-value的数据库,如果key是相同的,访问到的值就是相同的,这里使用spider名字+DupeFilter的key就是为了在不同主机上的不同爬虫实例,只要属于同一种spider,就会访问到同一个set,而这个set就是他们的url判重池),如果返回值为0,说明该set中该fingerprint已经存在(因为集合是没有重复值的),则返回False,如果返回值为1,说明添加了一个fingerprint到set中,则说明这个request没有重复,于是返回True,还顺便把新fingerprint加入到数据库中了。 DupeFilter判重会在scheduler类中用到,每一个request在进入调度之前都要进行判重,如果重复就不需要参加调度,直接舍弃就好了,不然就是白白浪费资源。
picklecompat.py
"""A pickle wrapper module with protocol=-1 by default."""
try:
import cPickle as pickle # PY2
except ImportError:
import pickle
def loads(s):
return pickle.loads(s)
def dumps(obj):
return pickle.dumps(obj, protocol=-1)
这里实现了loads和dumps两个函数,其实就是实现了一个序列化器。
因为redis数据库不能存储复杂对象(key部分只能是字符串,value部分只能是字符串,字符串列表,字符串集合和hash),所以我们存啥都要先串行化成文本才行。
这里使用的就是python的pickle模块,一个兼容py2和py3的串行化工具。这个serializer主要用于一会的scheduler存reuqest对象。
pipelines.py
这是是用来实现分布式处理的作用。它将Item存储在redis中以实现分布式处理。由于在这里需要读取配置,所以就用到了from_crawler()函数。
from scrapy.utils.misc import load_object
from scrapy.utils.serialize import ScrapyJSONEncoder
from twisted.internet.threads import deferToThread
from . import connection, defaults
default_serialize = ScrapyJSONEncoder().encode
class RedisPipeline(object):
"""Pushes serialized item into a redis list/queue
Settings
--------
REDIS_ITEMS_KEY : str
Redis key where to store items.
REDIS_ITEMS_SERIALIZER : str
Object path to serializer function.
"""
def __init__(self, server,
key=defaults.PIPELINE_KEY,
serialize_func=default_serialize):
"""Initialize pipeline.
Parameters
----------
server : StrictRedis
Redis client instance.
key : str
Redis key where to store items.
serialize_func : callable
Items serializer function.
"""
self.server = server
self.key = key
self.serialize = serialize_func
@classmethod
def from_settings(cls, settings):
params = {
'server': connection.from_settings(settings),
}
if settings.get('REDIS_ITEMS_KEY'):
params['key'] = settings['REDIS_ITEMS_KEY']
if settings.get('REDIS_ITEMS_SERIALIZER'):
params['serialize_func'] = load_object(
settings['REDIS_ITEMS_SERIALIZER']
)
return cls(**params)
@classmethod
def from_crawler(cls, crawler):
return cls.from_settings(crawler.settings)
def process_item(self, item, spider):
return deferToThread(self._process_item, item, spider)
def _process_item(self, item, spider):
key = self.item_key(item, spider)
data = self.serialize(item)
self.server.rpush(key, data)
return item
def item_key(self, item, spider):
"""Returns redis key based on given spider.
Override this function to use a different key depending on the item
and/or spider.
"""
return self.key % {'spider': spider.name}
pipelines文件实现了一个item pipieline类,和scrapy的item pipeline是同一个对象,通过从settings中拿到我们配置的REDIS_ITEMS_KEY作为key,把item串行化之后存入redis数据库对应的value中(这个value可以看出出是个list,我们的每个item是这个list中的一个结点),这个pipeline把提取出的item存起来,主要是为了方便我们后续处理数据。(集中处理放在同一台服务器,还是各自保存各自的)
queue.py
该文件实现了几个容器类,这些容器与redis进行交互,在交互时,会对request请求进行编码和解码操作(序列化和反序列化)
from scrapy.utils.reqser import request_to_dict, request_from_dict
from . import picklecompat
class Base(object):
"""Per-spider base queue class"""
def __init__(self, server, spider, key, serializer=None):
"""Initialize per-spider redis queue.
Parameters
----------
server : StrictRedis
Redis client instance.
spider : Spider
Scrapy spider instance.
key: str
Redis key where to put and get messages.
serializer : object
Serializer object with ``loads`` and ``dumps`` methods.
"""
if serializer is None:
# Backward compatibility.
# TODO: deprecate pickle.
serializer = picklecompat
if not hasattr(serializer, 'loads'):
raise TypeError("serializer does not implement 'loads' function: %r"
% serializer)
if not hasattr(serializer, 'dumps'):
raise TypeError("serializer '%s' does not implement 'dumps' function: %r"
% serializer)
self.server = server
self.spider = spider
self.key = key % {'spider': spider.name}
self.serializer = serializer
def _encode_request(self, request):
"""Encode a request object"""
obj = request_to_dict(request, self.spider)
return self.serializer.dumps(obj)
def _decode_request(self, encoded_request):
"""Decode an request previously encoded"""
obj = self.serializer.loads(encoded_request)
return request_from_dict(obj, self.spider)
def __len__(self):
"""Return the length of the queue"""
raise NotImplementedError
def push(self, request):
"""Push a request"""
raise NotImplementedError
def pop(self, timeout=0):
"""Pop a request"""
raise NotImplementedError
def clear(self):
"""Clear queue/stack"""
self.server.delete(self.key)
# 先进先出, 队列
class FifoQueue(Base):
"""Per-spider FIFO queue"""
def __len__(self):
"""Return the length of the queue"""
return self.server.llen(self.key)
# 压头, 出尾
def push(self, request):
"""Push a request"""
self.server.lpush(self.key, self._encode_request(request))
def pop(self, timeout=0):
"""Pop a request"""
if timeout > 0:
data = self.server.brpop(self.key, timeout)
if isinstance(data, tuple):
data = data[1]
else:
data = self.server.rpop(self.key)
if data:
return self._decode_request(data)
# 有序队列
class PriorityQueue(Base):
"""Per-spider priority queue abstraction using redis' sorted set"""
def __len__(self):
"""Return the length of the queue"""
return self.server.zcard(self.key)
def push(self, request):
"""Push a request"""
data = self._encode_request(request)
score = -request.priority
# We don't use zadd method as the order of arguments change depending on
# whether the class is Redis or StrictRedis, and the option of using
# kwargs only accepts strings, not bytes.
self.server.execute_command('ZADD', self.key, score, data)
def pop(self, timeout=0):
"""
Pop a request
timeout not support in this queue class
"""
# use atomic range/remove using multi/exec
pipe = self.server.pipeline()
pipe.multi()
pipe.zrange(self.key, 0, 0).zremrangebyrank(self.key, 0, 0)
results, count = pipe.execute()
if results:
return self._decode_request(results[0])
# 后进先出 栈
class LifoQueue(Base):
"""Per-spider LIFO queue."""
def __len__(self):
"""Return the length of the stack"""
return self.server.llen(self.key)
# 压头, 出头
def push(self, request):
"""Push a request"""
self.server.lpush(self.key, self._encode_request(request))
def pop(self, timeout=0):
"""Pop a request"""
if timeout > 0:
data = self.server.blpop(self.key, timeout)
if isinstance(data, tuple):
data = data[1]
else:
data = self.server.lpop(self.key)
if data:
return self._decode_request(data)
# TODO: Deprecate the use of these names.
SpiderQueue = FifoQueue
SpiderStack = LifoQueue
SpiderPriorityQueue = PriorityQueue
scheduler.py
此扩展是对scrapy中自带的scheduler的替代(在settings的SCHEDULER变量中指出),正是利用此扩展实现crawler的分布式调度。其利用的数据结构来自于queue中实现的数据结构。
scrapy-redis所实现的两种分布式:爬虫分布式以及item处理分布式就是由模块scheduler和模块pipelines实现。上述其它模块作为为二者辅助的功能模块
import importlib
import six
from scrapy.utils.misc import load_object
from . import connection, defaults
# TODO: add SCRAPY_JOB support.
class Scheduler(object):
"""Redis-based scheduler
Settings
--------
SCHEDULER_PERSIST : bool (default: False)
Whether to persist or clear redis queue.
SCHEDULER_FLUSH_ON_START : bool (default: False)
Whether to flush redis queue on start.
SCHEDULER_IDLE_BEFORE_CLOSE : int (default: 0)
How many seconds to wait before closing if no message is received.
SCHEDULER_QUEUE_KEY : str
Scheduler redis key.
SCHEDULER_QUEUE_CLASS : str
Scheduler queue class.
SCHEDULER_DUPEFILTER_KEY : str
Scheduler dupefilter redis key.
SCHEDULER_DUPEFILTER_CLASS : str
Scheduler dupefilter class.
SCHEDULER_SERIALIZER : str
Scheduler serializer.
"""
def __init__(self, server,
persist=False,
flush_on_start=False,
queue_key=defaults.SCHEDULER_QUEUE_KEY,
queue_cls=defaults.SCHEDULER_QUEUE_CLASS,
dupefilter_key=defaults.SCHEDULER_DUPEFILTER_KEY,
dupefilter_cls=defaults.SCHEDULER_DUPEFILTER_CLASS,
idle_before_close=0,
serializer=None):
"""Initialize scheduler.
Parameters
----------
server : Redis
The redis server instance.
persist : bool
Whether to flush requests when closing. Default is False.
flush_on_start : bool
Whether to flush requests on start. Default is False.
queue_key : str
Requests queue key.
queue_cls : str
Importable path to the queue class.
dupefilter_key : str
Duplicates filter key.
dupefilter_cls : str
Importable path to the dupefilter class.
idle_before_close : int
Timeout before giving up.
"""
if idle_before_close < 0:
raise TypeError("idle_before_close cannot be negative")
self.server = server
self.persist = persist
self.flush_on_start = flush_on_start
self.queue_key = queue_key
self.queue_cls = queue_cls
self.dupefilter_cls = dupefilter_cls
self.dupefilter_key = dupefilter_key
self.idle_before_close = idle_before_close
self.serializer = serializer
self.stats = None
def __len__(self):
return len(self.queue)
@classmethod
def from_settings(cls, settings):
kwargs = {
'persist': settings.getbool('SCHEDULER_PERSIST'),
'flush_on_start': settings.getbool('SCHEDULER_FLUSH_ON_START'),
'idle_before_close': settings.getint('SCHEDULER_IDLE_BEFORE_CLOSE'),
}
# If these values are missing, it means we want to use the defaults.
optional = {
# TODO: Use custom prefixes for this settings to note that are
# specific to scrapy-redis.
'queue_key': 'SCHEDULER_QUEUE_KEY',
'queue_cls': 'SCHEDULER_QUEUE_CLASS',
'dupefilter_key': 'SCHEDULER_DUPEFILTER_KEY',
# We use the default setting name to keep compatibility.
'dupefilter_cls': 'DUPEFILTER_CLASS',
'serializer': 'SCHEDULER_SERIALIZER',
}
for name, setting_name in optional.items():
val = settings.get(setting_name)
if val:
kwargs[name] = val
# Support serializer as a path to a module.
if isinstance(kwargs.get('serializer'), six.string_types):
kwargs['serializer'] = importlib.import_module(kwargs['serializer'])
server = connection.from_settings(settings)
# Ensure the connection is working.
server.ping()
return cls(server=server, **kwargs)
@classmethod
def from_crawler(cls, crawler):
instance = cls.from_settings(crawler.settings)
# FIXME: for now, stats are only supported from this constructor
instance.stats = crawler.stats
return instance
def open(self, spider):
self.spider = spider
try:
self.queue = load_object(self.queue_cls)(
server=self.server,
spider=spider,
key=self.queue_key % {'spider': spider.name},
serializer=self.serializer,
)
except TypeError as e:
raise ValueError("Failed to instantiate queue class '%s': %s",
self.queue_cls, e)
self.df = load_object(self.dupefilter_cls).from_spider(spider)
if self.flush_on_start:
self.flush()
# notice if there are requests already in the queue to resume the crawl
if len(self.queue):
spider.log("Resuming crawl (%d requests scheduled)" % len(self.queue))
def close(self, reason):
if not self.persist:
self.flush()
def flush(self):
self.df.clear()
self.queue.clear()
def enqueue_request(self, request):
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
if self.stats:
self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider)
self.queue.push(request)
return True
def next_request(self):
block_pop_timeout = self.idle_before_close
request = self.queue.pop(block_pop_timeout)
if request and self.stats:
self.stats.inc_value('scheduler/dequeued/redis', spider=self.spider)
return request
def has_pending_requests(self):
return len(self) > 0
这个文件重写了scheduler类,用来代替scrapy.core.scheduler的原有调度器。其实对原有调度器的逻辑没有很大的改变,主要是使用了redis作为数据存储的媒介,以达到各个爬虫之间的统一调度。 scheduler负责调度各个spider的request请求,scheduler初始化时,通过settings文件读取queue和dupefilters的类型(一般就用上边默认的),配置queue和dupefilters使用的key(一般就是spider name加上queue或者dupefilters,这样对于同一种spider的不同实例,就会使用相同的数据块了)。每当一个request要被调度时,enqueue_request被调用,scheduler使用dupefilters来判断这个url是否重复,如果不重复,就添加到queue的容器中(先进先出,先进后出和优先级都可以,可以在settings中配置)。当调度完成时,next_request被调用,scheduler就通过queue容器的接口,取出一个request,把他发送给相应的spider,让spider进行爬取工作。
spiders.py
设计的这个spider从redis中读取要爬的url,然后执行爬取,若爬取过程中返回更多的url,那么继续进行直至所有的request完成。之后继续从redis中读取url,循环这个过程。
分析:在这个spider中通过signals.spider_idle(空闲)信号实现对crawler状态的监视。当idle时,返回新的make_requests_from_url(url)给引擎,进而交给调度器调度。
from scrapy import signals
from scrapy.exceptions import DontCloseSpider
from scrapy.spiders import Spider, CrawlSpider
from . import connection, defaults
from .utils import bytes_to_str
class RedisMixin(object):
"""Mixin class to implement reading urls from a redis queue."""
redis_key = None
redis_batch_size = None
redis_encoding = None
# Redis client placeholder.
server = None
def start_requests(self):
"""Returns a batch of start requests from redis."""
return self.next_requests()
def setup_redis(self, crawler=None):
"""Setup redis connection and idle signal.
This should be called after the spider has set its crawler object.
"""
if self.server is not None:
return
if crawler is None:
# We allow optional crawler argument to keep backwards
# compatibility.
# XXX: Raise a deprecation warning.
crawler = getattr(self, 'crawler', None)
if crawler is None:
raise ValueError("crawler is required")
settings = crawler.settings
if self.redis_key is None:
self.redis_key = settings.get(
'REDIS_START_URLS_KEY', defaults.START_URLS_KEY,
)
self.redis_key = self.redis_key % {'name': self.name}
if not self.redis_key.strip():
raise ValueError("redis_key must not be empty")
if self.redis_batch_size is None:
# TODO: Deprecate this setting (REDIS_START_URLS_BATCH_SIZE).
self.redis_batch_size = settings.getint(
'REDIS_START_URLS_BATCH_SIZE',
settings.getint('CONCURRENT_REQUESTS'),
)
try:
self.redis_batch_size = int(self.redis_batch_size)
except (TypeError, ValueError):
raise ValueError("redis_batch_size must be an integer")
if self.redis_encoding is None:
self.redis_encoding = settings.get('REDIS_ENCODING', defaults.REDIS_ENCODING)
self.logger.info("Reading start URLs from redis key '%(redis_key)s' "
"(batch size: %(redis_batch_size)s, encoding: %(redis_encoding)s",
self.__dict__)
self.server = connection.from_settings(crawler.settings)
# The idle signal is called when the spider has no requests left,
# that's when we will schedule new requests from redis queue
crawler.signals.connect(self.spider_idle, signal=signals.spider_idle)
def next_requests(self):
"""Returns a request to be scheduled or none."""
use_set = self.settings.getbool('REDIS_START_URLS_AS_SET', defaults.START_URLS_AS_SET)
fetch_one = self.server.spop if use_set else self.server.lpop
# XXX: Do we need to use a timeout here?
found = 0
# TODO: Use redis pipeline execution.
while found < self.redis_batch_size:
data = fetch_one(self.redis_key)
if not data:
# Queue empty.
break
req = self.make_request_from_data(data)
if req:
yield req
found += 1
else:
self.logger.debug("Request not made from data: %r", data)
if found:
self.logger.debug("Read %s requests from '%s'", found, self.redis_key)
def make_request_from_data(self, data):
"""Returns a Request instance from data coming from Redis.
By default, ``data`` is an encoded URL. You can override this method to
provide your own message decoding.
Parameters
----------
data : bytes
Message from redis.
"""
url = bytes_to_str(data, self.redis_encoding)
return self.make_requests_from_url(url)
def schedule_next_requests(self):
"""Schedules a request if available"""
# TODO: While there is capacity, schedule a batch of redis requests.
for req in self.next_requests():
self.crawler.engine.crawl(req, spider=self)
def spider_idle(self):
"""Schedules a request if available, otherwise waits."""
# XXX: Handle a sentinel to close the spider.
self.schedule_next_requests()
raise DontCloseSpider
class RedisSpider(RedisMixin, Spider):
"""Spider that reads urls from redis queue when idle.
Attributes
----------
redis_key : str (default: REDIS_START_URLS_KEY)
Redis key where to fetch start URLs from..
redis_batch_size : int (default: CONCURRENT_REQUESTS)
Number of messages to fetch from redis on each attempt.
redis_encoding : str (default: REDIS_ENCODING)
Encoding to use when decoding messages from redis queue.
Settings
--------
REDIS_START_URLS_KEY : str (default: "<spider.name>:start_urls")
Default Redis key where to fetch start URLs from..
REDIS_START_URLS_BATCH_SIZE : int (deprecated by CONCURRENT_REQUESTS)
Default number of messages to fetch from redis on each attempt.
REDIS_START_URLS_AS_SET : bool (default: False)
Use SET operations to retrieve messages from the redis queue. If False,
the messages are retrieve using the LPOP command.
REDIS_ENCODING : str (default: "utf-8")
Default encoding to use when decoding messages from redis queue.
"""
@classmethod
def from_crawler(self, crawler, *args, **kwargs):
obj = super(RedisSpider, self).from_crawler(crawler, *args, **kwargs)
obj.setup_redis(crawler)
return obj
class RedisCrawlSpider(RedisMixin, CrawlSpider):
"""Spider that reads urls from redis queue when idle.
Attributes
----------
redis_key : str (default: REDIS_START_URLS_KEY)
Redis key where to fetch start URLs from..
redis_batch_size : int (default: CONCURRENT_REQUESTS)
Number of messages to fetch from redis on each attempt.
redis_encoding : str (default: REDIS_ENCODING)
Encoding to use when decoding messages from redis queue.
Settings
--------
REDIS_START_URLS_KEY : str (default: "<spider.name>:start_urls")
Default Redis key where to fetch start URLs from..
REDIS_START_URLS_BATCH_SIZE : int (deprecated by CONCURRENT_REQUESTS)
Default number of messages to fetch from redis on each attempt.
REDIS_START_URLS_AS_SET : bool (default: True)
Use SET operations to retrieve messages from the redis queue.
REDIS_ENCODING : str (default: "utf-8")
Default encoding to use when decoding messages from redis queue.
"""
@classmethod
def from_crawler(self, crawler, *args, **kwargs):
obj = super(RedisCrawlSpider, self).from_crawler(crawler, *args, **kwargs)
obj.setup_redis(crawler)
return obj
spider的改动也不是很大,主要是通过connect接口,给spider绑定了spider_idle信号,spider初始化时,通过setup_redis函数初始化和redis的连接,之后通过next_requests函数从redis中取出strat url,使用的key是settings中REDIS_START_URLS_AS_SET定义的(注意了这里的初始化url池和我们上边的queue的url池不是一个东西,queue的池是用于调度的,初始化url池是存放入口url的,他们都存在redis中,但是使用不同的key来区分,就当成是不同的表吧),spider使用少量的start url,可以发展出很多新的url,这些url会进入scheduler进行判重和调度。直到spider跑到调度池内没有url的时候,会触发spider_idle信号,从而触发spider的next_requests函数,再次从redis的start url池中读取一些url。
utils.py
py2和py3字符串兼容
import six
def bytes_to_str(s, encoding='utf-8'):
"""Returns a str if a bytes object is given."""
if six.PY3 and isinstance(s, bytes):
return s.decode(encoding)
return s
总结
这个工程通过重写scheduler和spider类,实现了调度、spider启动和redis的交互。实现新的dupefilter和queue类,达到了判重和调度容器和redis的交互,因为每个主机上的爬虫进程都访问同一个redis数据库,所以调度和判重都统一进行统一管理,达到了分布式爬虫的目的。 当spider被初始化时,同时会初始化一个对应的scheduler对象,这个调度器对象通过读取settings,配置好自己的调度容器queue和判重工具dupefilter。每当一个spider产出一个request的时候,scrapy内核会把这个reuqest递交给这个spider对应的scheduler对象进行调度,scheduler对象通过访问redis对request进行判重,如果不重复就把他添加进redis中的调度池。当调度条件满足时,scheduler对象就从redis的调度池中取出一个request发送给spider,让他爬取。当spider爬取的所有暂时可用url之后,scheduler发现这个spider对应的redis的调度池空了,于是触发信号spider_idle,spider收到这个信号之后,直接连接redis读取strart url池,拿去新的一批url入口,然后再次重复上边的工作。
Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平,尤其是主机。
Bloom Filter
https://piaosanlang.gitbooks.io/spiders/09day/section9.1.html
https://pypi.org/project/pybloomfiltermmap3/#description
https://pypi.org/project/pybloom_live
scrapy-redis去重
scrapy_redis是利用set数据结构来去重的,去重的对象是request的fingerprint。
去重原理说过了.
def request_seen(self, request):
fp = self.request_fingerprint(request)
# This returns the number of values added, zero if already exists.
added = self.server.sadd(self.key, fp)
return added == 0
如果要使用Bloomfilter优化,可以修改去重函数request_seen
def request_seen(self, request):
fp = self.request_fingerprint(request)
if self.bf.isContains(fp): # 如果已经存在
return True
else:
self.bf.insert(fp)
return False
self.bf是类Bloomfilter()的实例化
# encoding=utf-8
import redis
from hashlib import md5
class SimpleHash(object):
def __init__(self, cap, seed):
self.cap = cap
self.seed = seed
def hash(self, value):
ret = 0
for i in range(len(value)):
ret += self.seed * ret + ord(value[i])
return (self.cap - 1) & ret
class BloomFilter(object):
def __init__(self, host='localhost', port=6379, db=0, blockNum=1, key='bloomfilter'):
"""
:param host: the host of Redis
:param port: the port of Redis
:param db: witch db in Redis
:param blockNum: one blockNum for about 90,000,000; if you have more strings for filtering, increase it.
:param key: the key's name in Redis
"""
self.server = redis.Redis(host=host, port=port, db=db)
self.bit_size = 1 << 31 # Redis的String类型最大容量为512M,现使用256M= 2^8 *2^20 字节 = 2^28 * 2^3bit
self.seeds = [5, 7, 11, 13, 31, 37, 61]
self.key = key
self.blockNum = blockNum
self.hashfunc = []
for seed in self.seeds:
self.hashfunc.append(SimpleHash(self.bit_size, seed))
def isContains(self, str_input):
if not str_input:
return False
m5 = md5()
m5.update(str_input)
str_input = m5.hexdigest()
ret = True
name = self.key + str(int(str_input[0:2], 16) % self.blockNum)
for f in self.hashfunc:
loc = f.hash(str_input)
ret = ret & self.server.getbit(name, loc)
return ret
def insert(self, str_input):
m5 = md5()
m5.update(str_input)
str_input = m5.hexdigest()
name = self.key + str(int(str_input[0:2], 16) % self.blockNum)
for f in self.hashfunc:
loc = f.hash(str_input)
self.server.setbit(name, loc, 1)
if __name__ == '__main__':
""" 第一次运行时会显示 not exists!,之后再运行会显示 exists! """
bf = BloomFilter()
if bf.isContains('http://www.baidu.com'): # 判断字符串是否存在
print 'exists!'
else:
print 'not exists!'
bf.insert('http://www.baidu.com')
基于Redis的Bloomfilter去重,既用上了Bloomfilter的海量去重能力,又用上了Redis的可持久化能力,基于Redis也方便分布式机器的去重
scrapyd部署scrapy
https://github.com/scrapy/scrapyd
扩展
如何防止死循环
在Scrapy的默认配置中,是根据url进行去重的。这个对付一般网站是够的。但是有一些网站的SEO做的很变态:为了让爬虫多抓,会根据request,动态的生成一些链接,导致爬虫 在网站上抓取大量的随机页面,甚至是死循环。。
为了解决这个问题,有2个方案:
(1) 在setting.py中,设定爬虫的嵌套次数上限(全局设定,实际是通过DepthMiddleware实现的):
DEPTH_LIMIT = 20
(2) 在parse中通过读取response来自行判断(spider级别设定) :
def parse(self, response):
if response.meta['depth'] > 100:
print ('Loop?')
scrapy入门与进阶的更多相关文章
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(38):爬虫框架 Scrapy 入门基础(六) Item Pipeline
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- [转]Scrapy入门教程
关键字:scrapy 入门教程 爬虫 Spider 作者:http://www.cnblogs.com/txw1958/ 出处:http://www.cnblogs.com/txw1958/archi ...
- Scrapy入门教程
关键字:scrapy 入门教程 爬虫 Spider作者:http://www.cnblogs.com/txw1958/出处:http://www.cnblogs.com/txw1958/archive ...
随机推荐
- 朱晔的互联网架构实践心得S1E10:数据的权衡和折腾【系列完】
朱晔的互联网架构实践心得S1E10:数据的权衡和折腾[系列完] [下载本文PDF进行阅读] 本文站在数据的维度谈一下在架构设计中的一些方案对数据的权衡以及数据流转过程中的折腾这两个事情.最后进行系列文 ...
- 2019年DNS服务器速度排行榜
第一名:DNSPod 不得不说腾讯自从收购了DNSPod后,无论是服务还是速度都有显著的提升,无论是访问速度还是解析速度都在国内是处于龙头大哥的地位,昔日的老大114的地位已经不保,作为腾讯旗下的公司 ...
- rabbitmq集群运维一点总结
说明:以下操作都以三节点集群为例,机器名标记为机器A.机器B.机器C,如果为双节点忽略机器C,如果为各多节点则与机器C操作相同 一.rabbitmq集群必要条件 1.1.绑定实体ip,即ip a所能查 ...
- Day9 Python基础之函数基础(七)
参考链接:https://www.cnblogs.com/yuanchenqi/articles/5828233.html 1.函数的定义 定义: 函数是指将一组语句的集合通过一个函数名封装起来,要想 ...
- apply和call方法
真伪数组转换 /* apply和call方法的作用: 专门用于修改方法内部的this 格式: call(对象, 参数1, 参数2, ...); apply(对象, [数组]); */ function ...
- tomcat one connection one thread one request one thread
java - What is the difference between thread per connection vs thread per request? - Stack Overflow ...
- centos yum install oracle java
How to install Java on CentOS 7 | Linuxizehttps://linuxize.com/post/install-java-on-centos-7/ CentOS ...
- Python3练习题 026:求100以内的素数
p = [i for i in range(2,100)] #建立2-99的列表 for i in range(3,100): #1和2都不用判断,从3开始 for j in range(2, ...
- 使用fetch代替ajax请求 post传递方式
let postData = {a:'b'}; fetch('http://data.xxx.com/Admin/Login/login', { method: 'POST', mode: 'cors ...
- checkbox保存和赋值
//货物信息中的表格内容 $.each(trG.find('td input,td select'),function(i,inp){ if($(inp).attr('type')=='checkbo ...